1. 介绍
Auto-GPT是一个基于ChatGPT的工具,他能帮你自动完成各种任务,比如写代码、写报告、做调研等等。使用它时,你只需要告诉他要扮演的角色和要实现的目标,然后他就会利用ChatGPT和谷歌搜索等工具,不断“思考”如何接近目标并执行,你甚至可以看到他的思考过程。
2. 准备工作
无论是windows还是mac都可以看这个教程。
这里需要先安装Python,教程在这里:Python和pip安装教程(https://zjf2vk07yt.feishu.cn/docx/QbJSd6h0poQKumxljCScMHqxnJc) ,现在我就不这里讲Python和pip的安装使用,大家自己去百度。
2.1 下载AutoGPT代码
第1步就是下载AutoGPT项目代码到本地文件夹,有以下两种方式:
1.通过git克隆AutoGPT项目,git clone https://github.com/Torantulino/Auto-GPT.git
2.如果没有安装git的同学就直接点击这个链接下载https://github.com/Torantulino/Auto-GPT/archive/refs/heads/master.zip,然后解压就行。
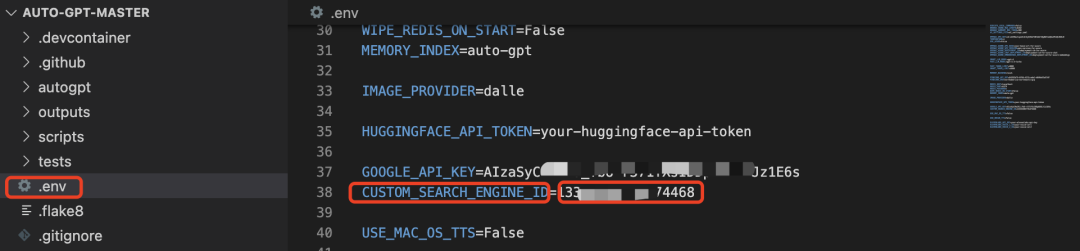
用代码编辑器打开文件,我这里用的是vs code,找到env.template文件,删掉后缀修改文件名为“.env(我删除里面的注释信息是为了方便阅读):
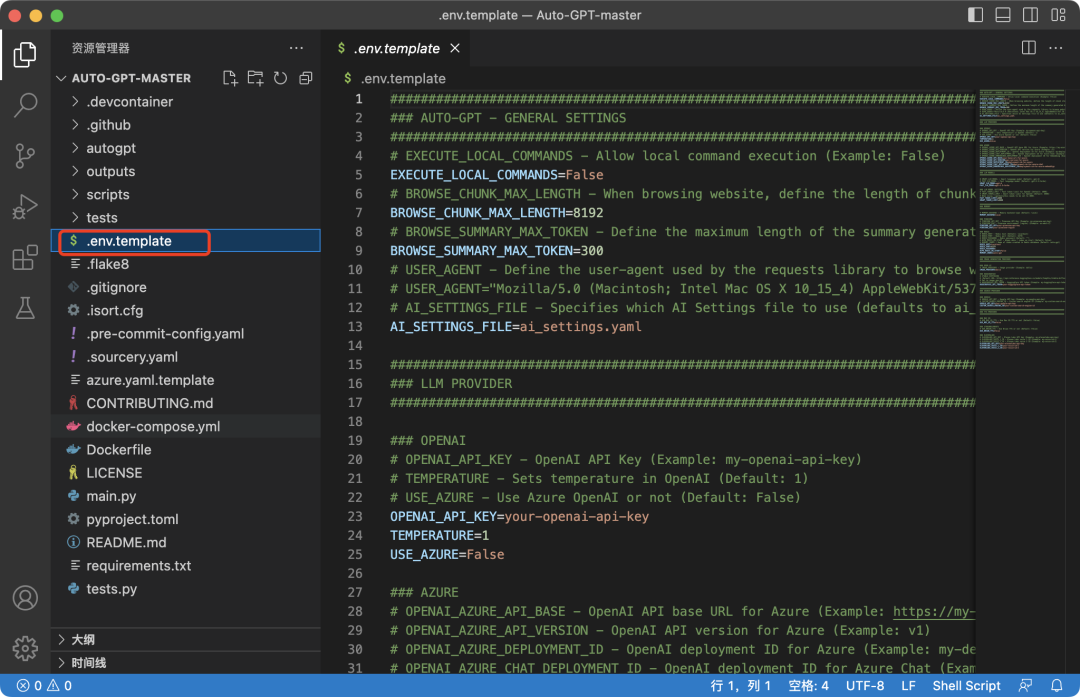
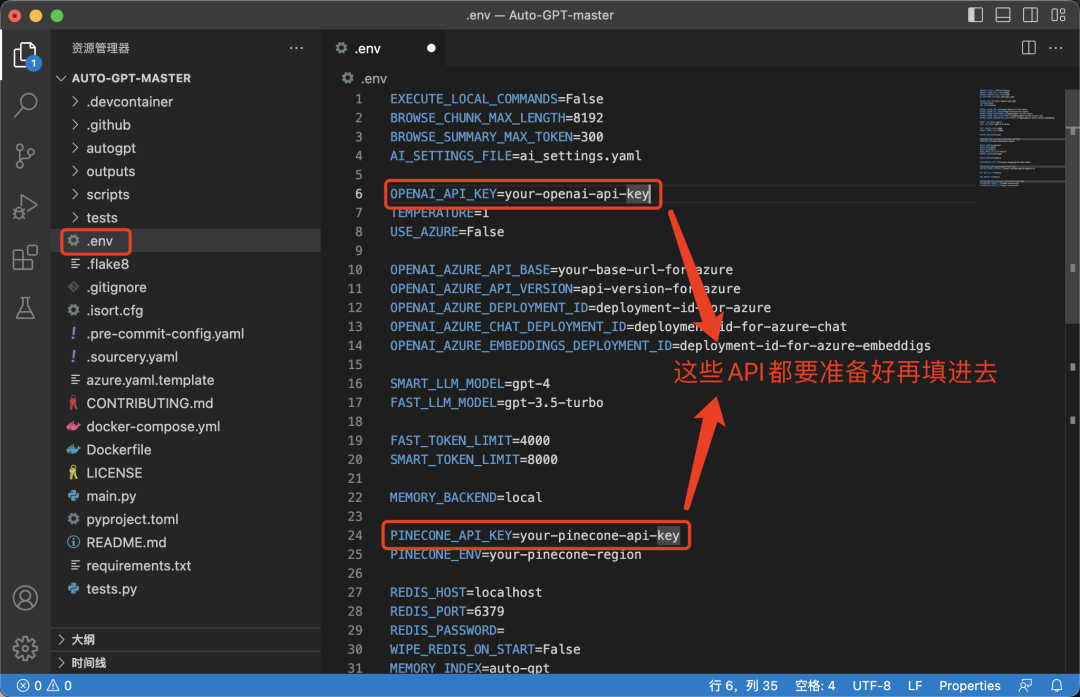
下面开始准备修改该配置文件信息。
2.2 API配置
AutoGPT需要用到以下几个API:
ChatGPT:AutoGPT工具的本质还是利用ChatGPT工作,所以需要接入ChatGPT
Google API及Google Search engine ID:让AutoGPT能够利用谷歌搜索,提高信息准确程度
Pinecone:Pinecone是一个矢量数据库,用于保存AutoGPT运行时生成的数据
ElevenLabs(可选):提供语音功能
可以创建一个文件记录各个API备用,下面分别讲解各个API如何获取。
2.2.1 ChatGPT API获取
网址:https://platform.openai.com
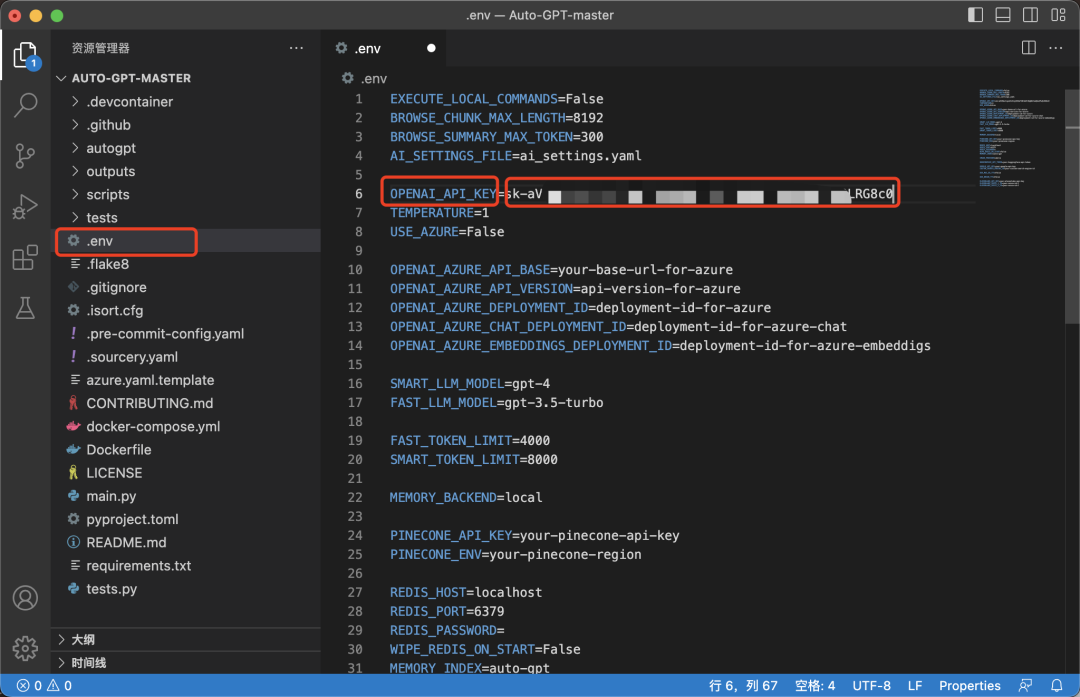
获取后粘贴到.env文件相应位置。
2.2.2 Google API及Google Search engine ID获取
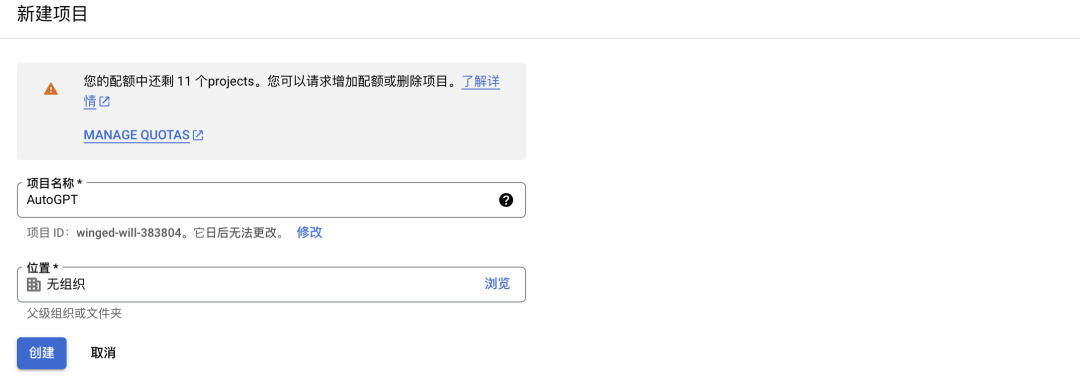
网址链接:https://console.cloud.google.com
创建一个无组织的项目:
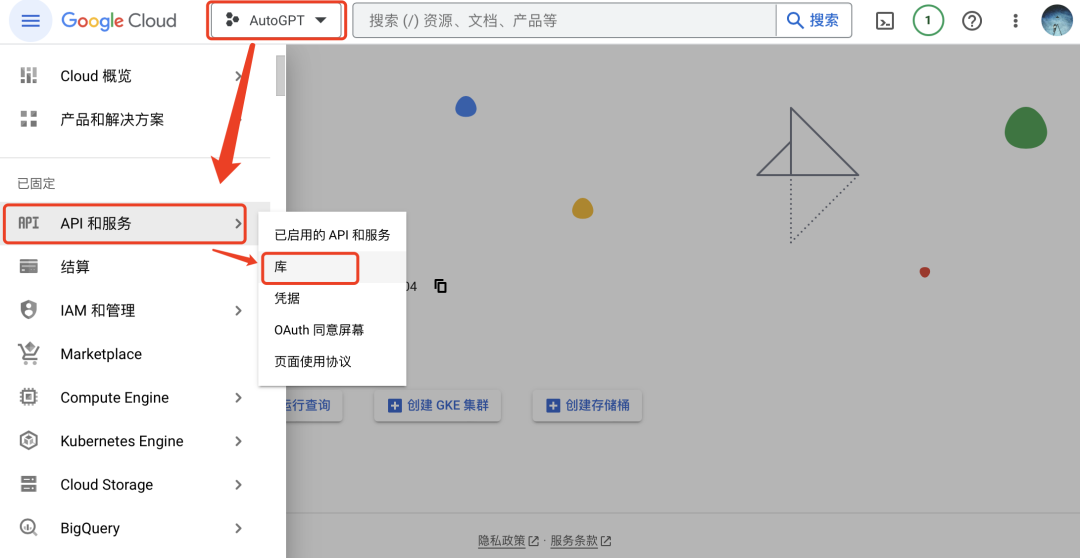
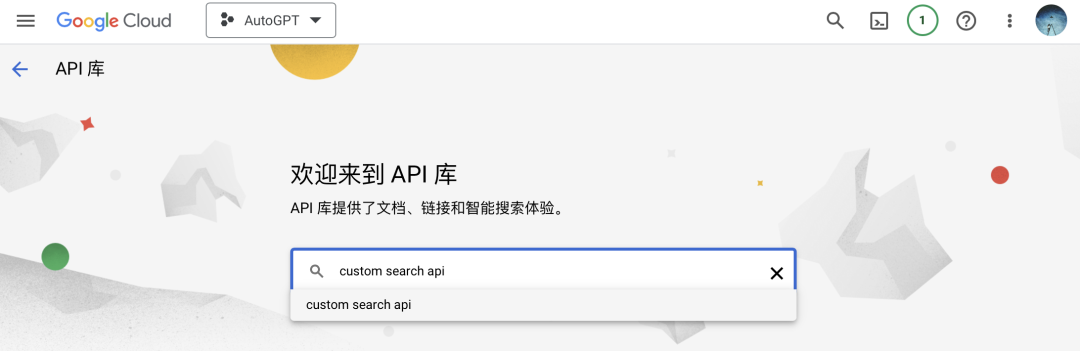
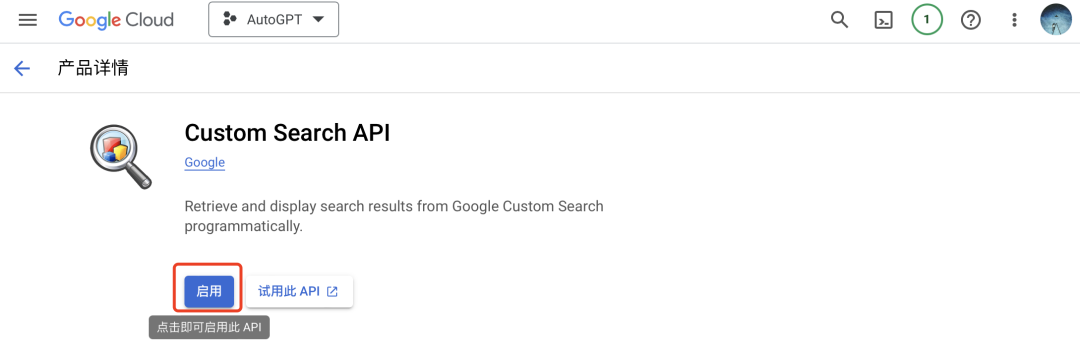
创建好项目后,进入你创建的项目-API和服务-库,搜索custom search api,启用。
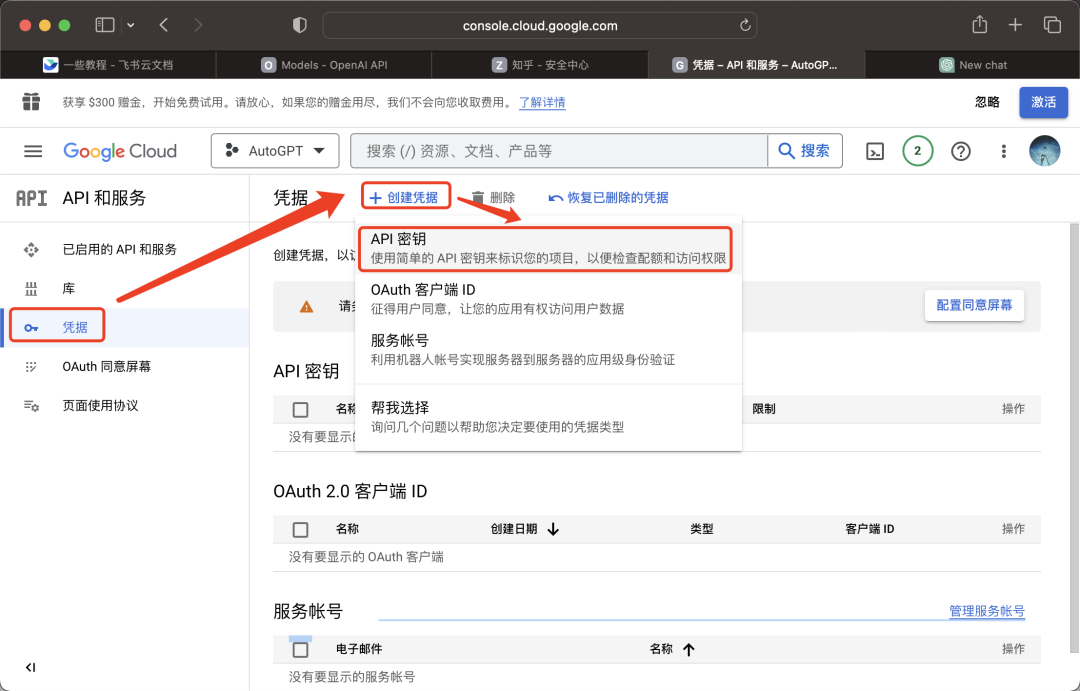
点击凭据-创建凭据- API密钥-复制密钥-粘贴到.env的“GOOGLE_API_KEY=”后面:
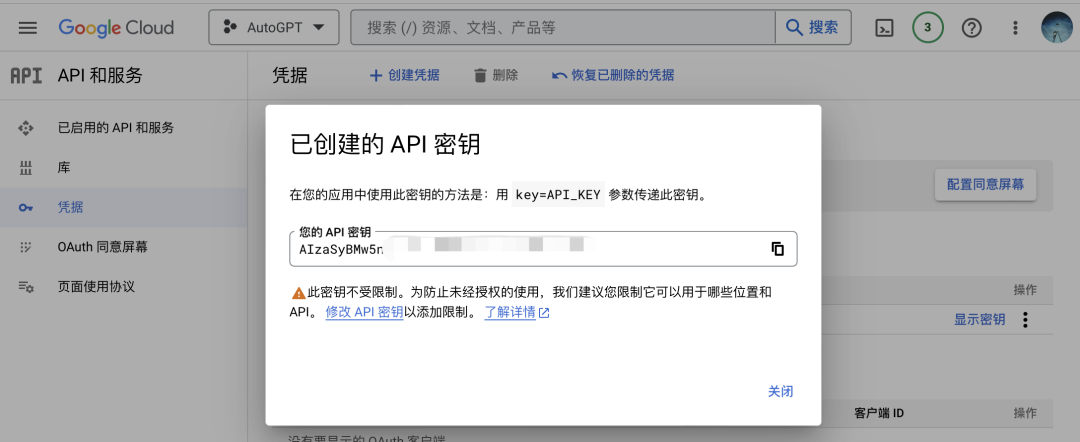
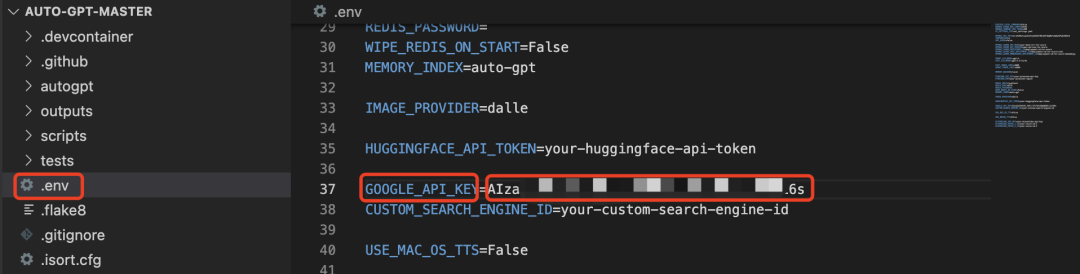
之后同理添加CUSTOM_SEARCH_ENGINE_ID 的ID
网址:https://programmablesearchengine.google.com/about/
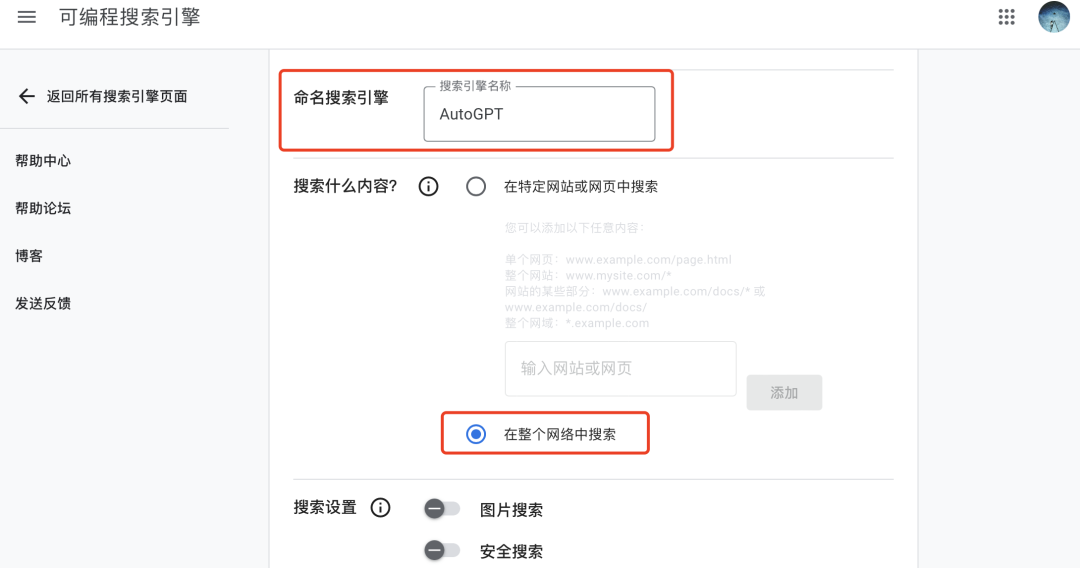
创建搜索引擎,设置为整个网络中搜索:
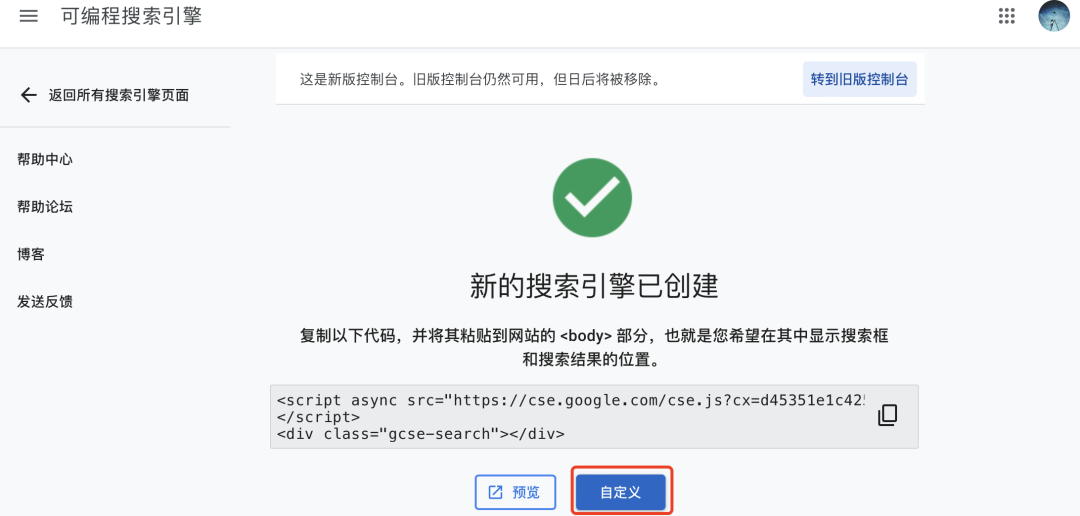
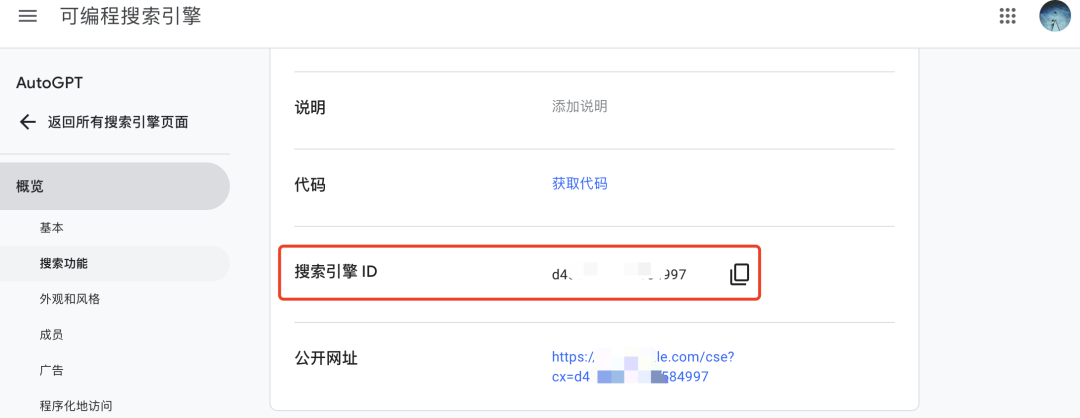
2.2.3 Pinecone API获取
网址:https://www.pinecone.io
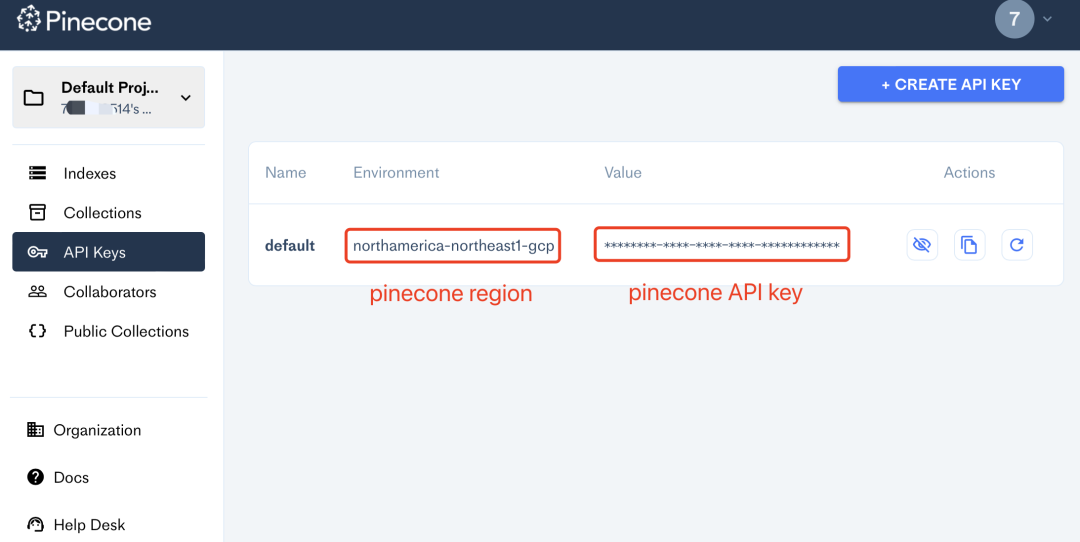
注册账号,获取API和pinecone region,填入.env文件中相应位置:
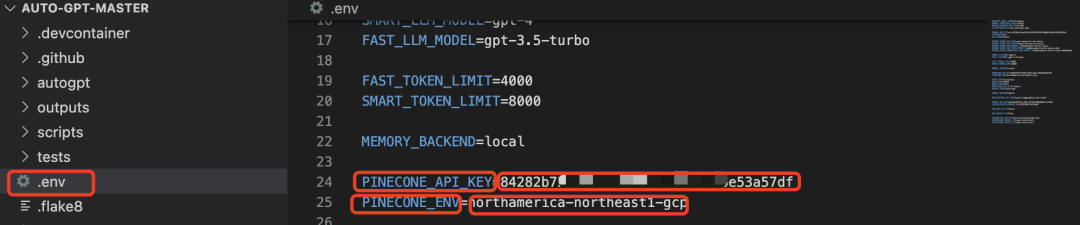
大部份需要的配置信息都填好了,其他的Elevenlabs API、Huggingface API我暂时用不上,有需要自行搜索。保存.env文件。
3. 运行AutoGPT
3.1 安装依赖库
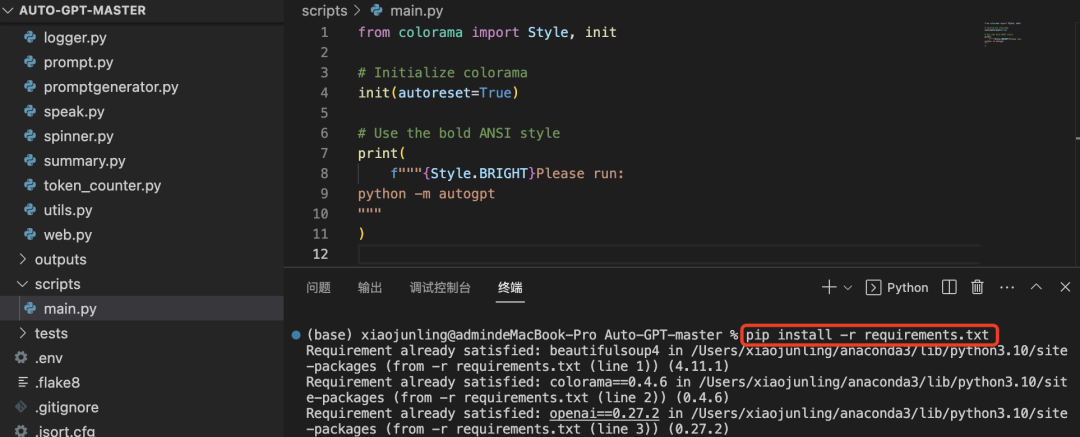
安装运行所需依赖库pip install -r requirements.txt:
3.2 实现你的目标
运行python scripts/main.py,并按照他的要求输入python -m autogpt -- continuous --gpt3only运行(其中-- continuous参数表示自动确认命令,不需要你手动去确认,--gpt3only参数表示只用gpt3模型,因为我没有申请到gpt4的API):
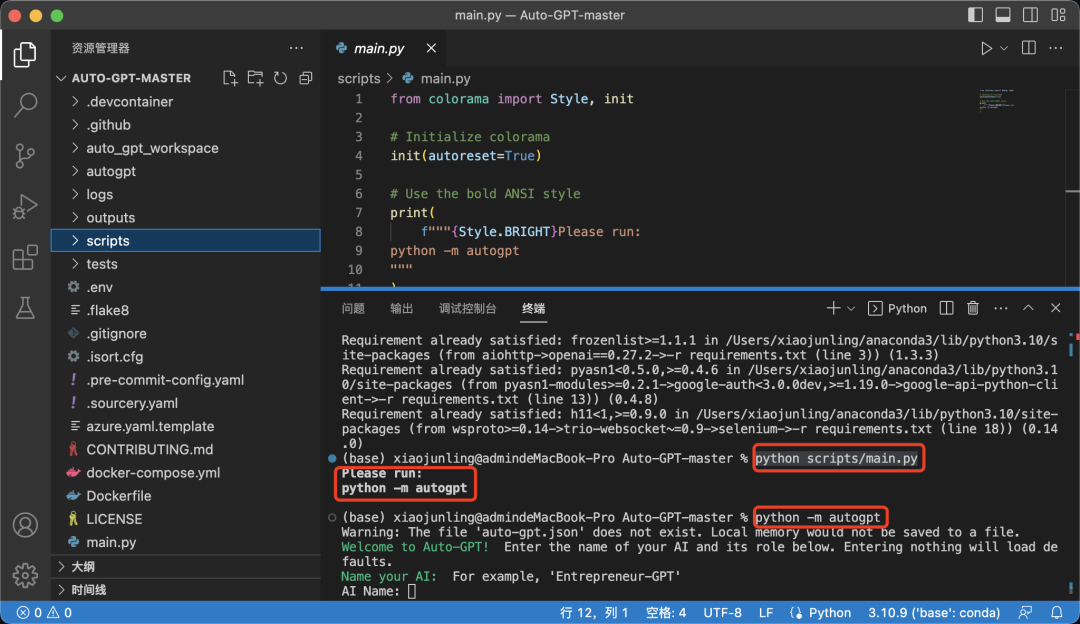
开始给AI设定角色和目标(需要将目标分解成几个小目标,这里最多分解为五个):
AI name:professor(这个名字随便取) |
到这里,你的AI就开始自动思考如何去实现你的目标了,我上面举的这个例子算是非常复杂了,且没有用到gpt4,跑了两个多小时,大家尝试时可以设定一些简单点的目标,看看效果。
3.3 效果展示
AutoGPT甚至能操控我的电脑自动打开网页去读文献:
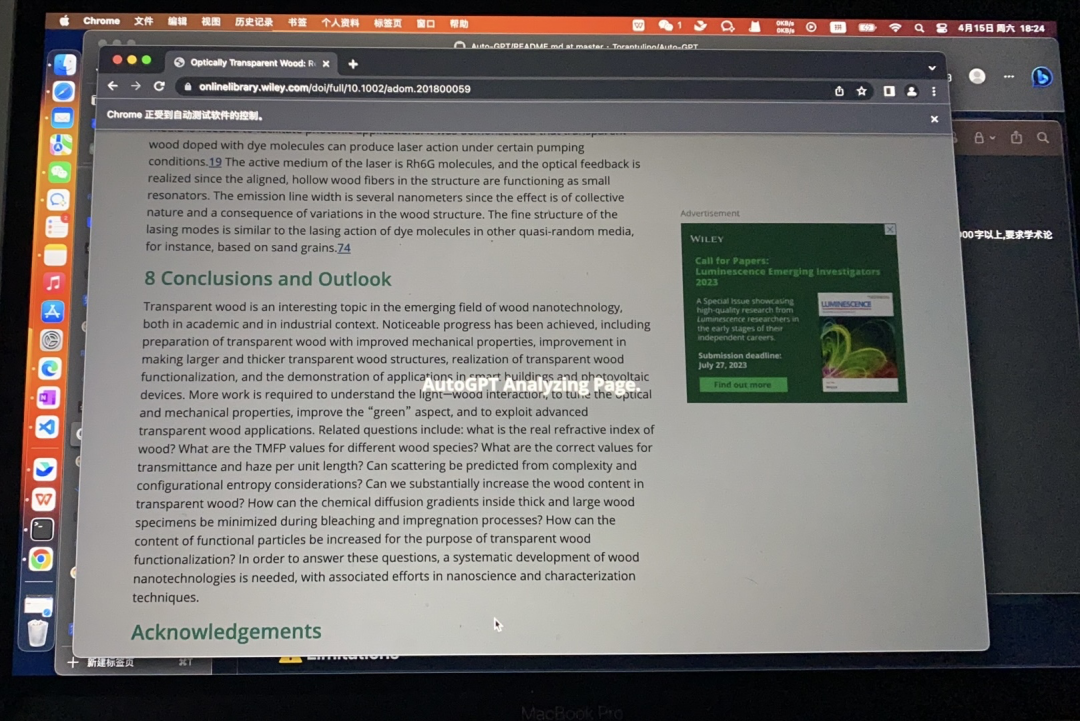
跑了快两小时,终于开始写大纲,左边的auto_gpt_workplace里面是他运行过程中生成保存的一些文件:
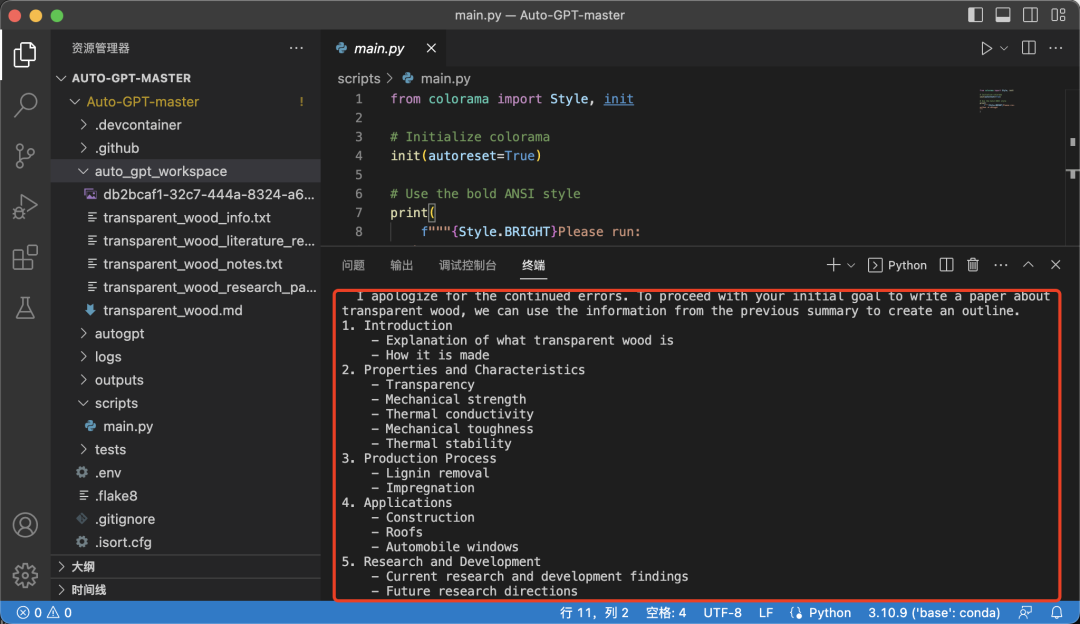
最后遇到各种bug,他还是屈服了,没有写那么复杂的论文,最后生成的文件和真正的论文还是有一定差距的。。。:
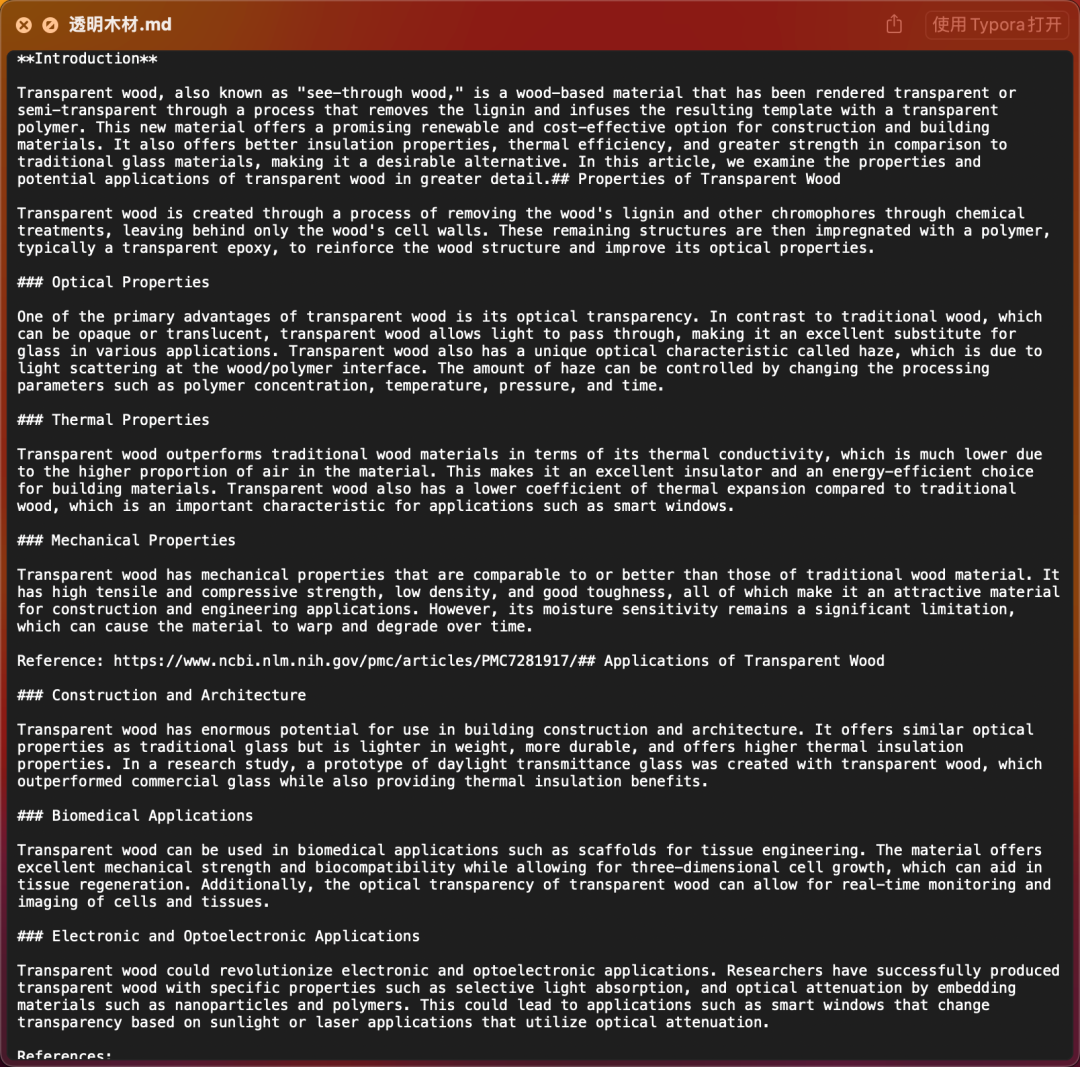
看来可能需要换成gpt4模型,并等待他完善,减少一些运行过程中的bug,不过这种效果已经很令人惊讶,从3月份ChatGPT刚火起来到现在,进化速度太快,必须要跟上时代的脚步了。