论文信息
name_en: Masked Autoencoders Are Scalable Vision Learners
name_ch: 带遮蔽的自编码器是大规模的视觉学习者
paper_addr: https://ieeexplore.ieee.org/document/9879206/
doi: 10.1109/CVPR52688.2022.01553
date_read: 2023-04-08
date_publish: 2022-06-01
tags: [‘深度学习’,‘计算机视觉’]
journal: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
author: Kaiming He,Facebook AI Research
citation: 1601
others: MAE 论文逐段精读 https://www.bilibili.com/video/BV1sq4y1q77t/?spm_id_from=333.337.search-card.all.click&vd_source=eef058f284e51ad4598d556801a9fc84
读后感
图像领域的无监督学习,延续ViT使用Transformer结构,学习BERT遮蔽图片块,然后预测被遮蔽的块实现自我学习autoencoder。
ViT论文最后也做过类似实验,但效果并不好,MAE对此做了一些修改:遮住更多的图片块,这是由于相对于文本,图像中存在更多冗余信息;编码时只处理没遮住的部分,从而节约了算力;另外,使用与Encoder不对称的轻量级Decoder来预测遮住的块。
介绍
MAE是Masked Autoencoders的缩写,是一种用于计算机视觉的自监督学习方法。在MAE方法中,会随机mask输入图片的部分patches,然后重构这些缺失的像素。其主要技术基于ViT和BERT。
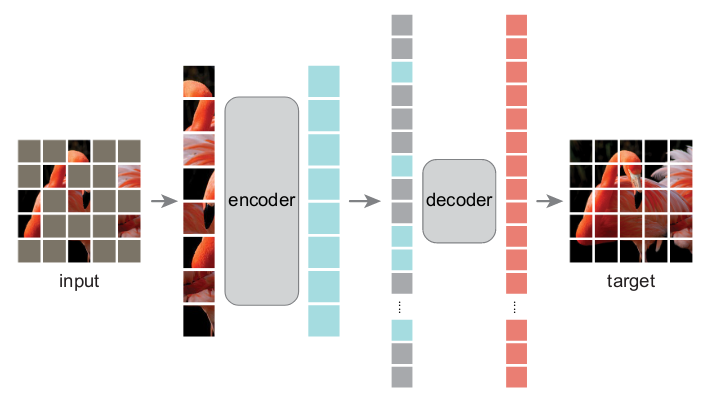
和ViT一样,先将图片切分成大小一致(一般是16x16)的Patch,遮住其中75%(图中灰色部分);然后对没遮住的块进行编码,生成隐空间表示(蓝色列,下游应用使用的就是这一步的结果),然后用隐空间预测被遮住的块,以还原图像,逐步调优使模型更好地预测遮住的块,以实现不需要标注的自我学习。
模型结构
效果展示
第一列是被部分遮蔽的图,第二列是MAE恢复的图,第三列是原图(人都脑补不成这样)。

面临问题
之前BERT方法应用到视觉所面临的问题如下:
- 之前一直使用卷积神经网络处理图像,直至最近ViT解决了这一问题。
- 图像数据中存在大量冗余,不像文本信息一样密集,图像中mask掉一部分可通过邻近信息插补,因此无法学习到复杂关系,文中提出mask掉高比例数据,以解决这一问题。
- 去掉图像区域再还原像素比较困难,文中提出设计解码器解决这个问题。
核心设计
MAE基于两个核心设计:
- 不对称的编码解码结构,编码器仅仅对可见的patches进行编码,而解码器则对所有patches进行解码,但结构更简单;
- 使用随机掩码来遮盖输入图像的部分区域,以此来训练模型。出人意料的是,图像的大部分都遮住了,还能还原出来。
MAE方法简单且可扩展性强(scalable),因此在计算机视觉领域得到了广泛应用。只使用ImageNet-1K来精调ViT-Huge模型,就能达到87.8%的准确率,且在其它下游任务中也表现良好。
方法
MAE使用autoencoder自编码器,由不对称的编码和解码器构造。
Mask
在不放回的情况下按照均匀分布对随机Patch抽样。简称为“随机抽样”。
- 高掩蔽率(一般遮住75%)很大程度上消除了冗余,创建了无法通过从可见的相邻插补轻松解决的任务。
- 均匀分布可防止潜在的中心偏差。
- 高度稀疏的输入为设计接下来介绍的高效编码器提供可能。
Mask具体实现同Vit,详见:备2_论文阅读_ViT
编码器
编码器是 ViT,通过添加位置嵌入的线性投影嵌入Patch,然后通过一系列 Transformer 块处理结果集。
与ViT不同的是:MAE只对整个集合的一小部分(例如 25%)进行操作,不考虑Mask掉的Patch,从而节约了计算量和内存。
解码器
如架构图所示,解码器的输入是所有Patch,并对所有块加入了位置信息,与编码器相比,默认解码器更窄而浅,每个token的计算量仅编码器的 10%,通过这种不对称设计,显著减少了预训练时间。
解码器只在预训练时使用,其下游任务只使用图-1中全蓝色的隐空间表示。
重构目标
解码器输出中的每个元素代表一个Patch的像素值向量。解码器的最后一层是线性投影,其输出通道数等于补丁中的像素值数,另外,还使用归一化方法提升重构质量。损失函数计算像素空间中重建图像和原始图像之间的均方误差 (MSE)。
简单实现
先随机打乱token顺序,删除token列表的后面一部分(相当于采样),然后送入编码器,后进行随机打乱的逆操作对齐对原来顺序加入位置信息后再送入解码器。这样简单操作开销可以忽略不计,且不用使用稀疏操作。