作者:郑刚,美团点评高级技术专家。2010年毕业于中科院计算所,2011年加入美团,参与美团早期数据平台搭建,先后负责平台、酒旅数据仓库和数据产品建设,目前在酒旅事业群数据研发中心,重点负责酒店旅游场景下的搜索排序推荐、数据挖掘工作,致力于用大数据和机器学习技术解决业务痛点,提升用户体验。
责编:钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件qianshg@csdn.net,另有「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qianshuguangarch申请入群,备注姓名+公司+职位。
背景
度假业务在整个在线旅游市场中占据着非常重要的位置,如何做好做大这块蛋糕是行业内的焦点。与美食或酒店的用户兴趣点明确(比如找某个确定的餐厅或者找某个目的地附近的酒店)不同,旅游场景中的用户兴趣点(比如周末去哪儿好玩)很难确定,而且会随着季节、天气、用户属性等变化而变化。这些特点导致传统的信息检索并不能很好的满足用户需求,我们迫切需要建设旅游推荐系统(本文中度假=旅游)。
旅游推荐系统主要面临以下几点挑战:
- 本异地差异大。在本地生活场景中用户需求绝大部分集中在本地,而在旅游场景中超过30%的订单来自于异地请求,即常驻城市为A的用户购买了城市B的旅游订单。外地人浏览北京时推荐故宫、长城没有问题,北京人浏览时推荐北京欢乐谷、野生动物园更为合适。
- 推荐形式多样。除了景点推荐外,还有跟团游、景酒套餐的推荐。景点下有大量重复相似的门票,不适合按Deal(团购单)样式展示;跟团游、景酒套餐一般会绑定多个景点,又不适合按POI(门店)样式展现。
- 季节性明显。比如,冬季温泉、滑雪比较热销,夏季更多人选择水上乐园。
- 需求个性化。比如,亲子类用户和情侣类用户的需求会不太一样,进一步细分,1~4岁、6岁以上亲子类用户的需求也会有所差别。
针对上述问题我们定制了一套完整的推荐系统框架,包括基于机器学习的召回排序策略,以及从海量大数据的离线计算到高并发在线服务的推荐引擎。
策略迭代
推荐系统的策略主要分为召回和排序两类,召回负责生成推荐的候选集,排序负责将多个召回策略的结果进行个性化排序。下文会分别对召回和排序策略的迭代演进过程进行阐述。
召回策略迭代
我们从2015年底启动了旅游推荐系统的建设,此时度假业务有独立的周边游频道首页,其中猜你喜欢展位的推荐策略由平台统一负责,不能很好的解决旅游场景中的诸多问题。下文会按时间顺序来阐述如何利用多种召回策略解决这些问题。
热销策略1.0
旅游推荐第一版的策略主要基于城市热销,不同于基于Deal所在城市统计分城市热销,这一版策略基于用户常驻城市来统计,原因是不同城市的旅游资源分布各异,存在资源缺乏(客源地)、旅游资源丰富(供给地)以及本地人到周边城市游玩的需求。即对于每个城市,都有其对应的“城市圈”Deal库,比如:廊坊没有滑雪场,但常驻城市为廊坊的用户经常购买北京的滑雪场,因此当廊坊用户在当地浏览周边游频道时会推荐出北京的滑雪场。
在具体实现时考虑旅游产品随季节性变化的特性,销量随时间逐渐衰减,假定4周为1个变化周期,Deal得分公式为:deal_score = ∑((count(payorder) * α ^ i),其中count(payorder)指该Deal相应日期的支付订单数,i指该日期距今的天数,取从1到28的整数,α为衰减系数(<1),Deal得分为一定周期内每日销量得分的总和。
根据上述公式对每个城市都能统计Top N热销Deal,再根据Deal关联POI过滤离当前浏览城市200km以外的Deal,比如:在浏览北京时推荐上海迪士尼门票不太好,不符合周边游的定位。
这一阶段还尝试了热门单、低价单、新单策略。新单和低价单比较好理解,就是给这些Deal一定的曝光机会。热门单跟热销单类似,统计的是Deal浏览数据,热门单召回的Deal跟热销策略差异不大。但由于推荐的评估指标是访购率(支付UV/推荐UV),这些策略的效果不及热销,都没有上线。
另外还初步尝试了分时间上下文的推荐,比如:区分工作日/非工作日, 周一至周四过滤周末票、周五至周日过滤平日票,不过随着推荐POI化而下线了。
这一阶段的策略主要有两个创新点:
- 基于用户常驻城市统计热销,突破了Deal所在城市的限制,在本地能推荐出周边城市的旅游产品。
- 通过销量衰减,基本解决了季节性问题。
推荐POI化
每个景点下通常会有多个票种,每个票种下通常会有多个Deal,比如:故宫门票的票种有成人票、学生票和老人票,成人票下由于Deal供应商不同会有多个Deal,这些Deal的价格、购买限制可能会有所区别。如果按Deal样式展示,可能故宫成人票、学生票都会被推荐出来,一方面大量重复相似Deal占据了推荐展位,另一方面Deal摘要信息较长,不利于用户决策。因此2016年初启动了推荐POI化,第一版的POI化方案基于Deal关联的POI做推荐,即故宫成人票是热销单,实际推荐展示的故宫POI。 这个方案有两个问题:
- 推荐的Deal有可能来自同一个POI,POI化需要去重。如果推荐展位有30个,候选推荐Deal的数量肯定要>=30,但也可能出现POI化后不足30个情况。
- 由Deal反推的POI销量并不准确,POI实际销量需要更精确的统计方法。
因此在2016年Q2上线了基于F值的POI热销策略,F值是美团点评内部的一种埋点追踪方法,可以简单理解为:用户在浏览POI详情页时会在埋点日志的F值记录POI ID,然后这个标记会一直带到订单中,这样就能相对准确计算每个订单的POI归属。
热销策略2.0
1.0版热销策略的主要问题是只考虑常驻城市的用户在当地的购买偏好,简而言之,只解决了上海人在浏览上海时的推荐问题,北京人在浏览上海时推荐的结果跟上海人推荐的一样。放大看是本异地场景的问题,本异地场景的定义见下表。2.0版热销策略对本异地订单分别统计,当某个用户访问美团时先判断该用户是本地还是异地用户,再分别召回对应的POI,对于取不到常驻城市的用户默认看做是本地请求。从推荐结果看北京本地人爱去欢乐谷,外地人到北京更爱去长城、故宫。
| 分类 | 场景 | 召回策略 |
|---|---|---|
| 本地需求 | 浏览城市=常驻城市(示例:北京人浏览北京) | 当地用户购买的热销POI(POI所在城市不一定等于浏览城市) |
| 异地需求 | 浏览城市!=常驻城市(示例:重庆人浏览北京) | 异地用户购买的热销POI(所有非北京人购买的热销POI) |
这一版本中继续尝试了分时间上下文的细分推荐,统计一段时间内每天各小时的订单分布,其中有3个鞍点,对应将一天分为早、中、晚3个时间段,分时间段统计POI热销。从召回层面看POI排序对比之前变化比较大,但由于下文中Rerank的作用,对推荐整体的影响并不大。
用户历史行为强相关策略
热销策略虽然能区分本异地用户的差异,但对具体单个用户缺少个性化推荐,因此引入用户历史行为强相关的推荐策略。取用户最近一个月内浏览、收藏未购买的POI,按城市分组,按POI ID去重,越实时权重越高。
基于地理位置的推荐策略
上文的策略要么是有大量POI数据,要么是有用户数据,如果用户或POI没有历史行为数据或比较稀疏,上述策略就不能奏效,即所谓的“冷启动”问题。在移动场景下通过设备能实时获取到用户的地理位置,然后根据地理位置做推荐。具体推荐策略分为两类:
- 查找用户实时位置几公里范围内的POI按近期销量衰减排序,取Top POI列表。
- 查找用户实时位置几公里范围内的用户群,基于其近期发生的购买行为推荐Top POI。比如用户定位在回龙观,回龙观附近没有POI,但回龙观的用户会购买一些应季热门POI。
地理位置推荐策略需要过滤用户定位城市跟客户端选择城市不一致的情况,比如:定位北京的用户在浏览上海时推荐北京周边POI不太合适。
协同过滤策略
协同过滤是推荐系统中最经典的算法,相对于历史行为强相关策略,对用户兴趣、POI属性相当于是做了抽象和泛化。协同过滤算法主要分为ItemCF和UserCF两类,我们首先实现了ItemCF,主要原因是:
- 性能:美团旅游POI数量远小于用户数,协同过滤算法核心的地方是需要维护一个相似度矩阵(Item/User相似度),维护POI相似度矩阵比维护用户相似度矩阵代价小得多;
- 实时性:用户有新行为,一定会导致推荐结果的实时变化;
- 冷启动:新用户只要对一个POI产生行为,就可以给他推荐和该POI相关的其他POI;
- 可解释性:利用用户的历史行为给用户做推荐解释,可以令用户比较信服。
基于POI浏览行为的协同过滤
根据UUID维度的浏览数据来计算POI之间的相似度,浏览行为比下单、支付行为更为稠密。时间窗口取一个月的数据,理论上只要计算计算能力不是瓶颈,时间窗口应该尽可能的长。相似度公式定义如下:
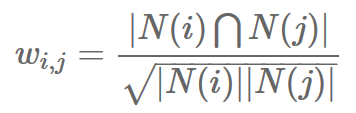
分母|N(i)|是浏览POI i的用户数,分子|N(i)⋂N(j)|是一个月内同时浏览过POI i和j的用户数。在计算完POI相似度后,再通过如下公式计算用户u对POI j的兴趣:
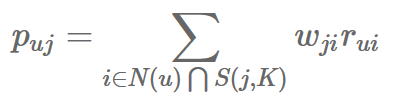

用户对POI的行为表每天离线生产好后更新,相当于只有当天之前的数据,缺少对用户当天实时行为的反馈,因此增加基于用户实时POI行为的协同过滤推荐,复用上文中的POI相似度计算结果。
基于用户搜索行为的协同过滤
搜索行为是一种强意图行为,旅游较多订单来源于搜索入口,相当比例的搜索用户没有点击任何POI,基于用户搜索行为的推荐可以作为POI浏览推荐的一种补充。首先构造Query和POI的相似度矩阵,利用用户搜索Query后10分钟内浏览的POI构造对,相似度算法跟POI相似度公式一致。
具体实现时以Query+City为Key,原因是旅游场景中存在部分全国连锁POI,如:欢乐谷、方特,如果只以Query为Key,则跟“欢乐谷”Query最相关的POI可能是“北京欢乐谷”,那用户在深圳搜索“欢乐谷”后会推荐出北京欢乐谷,不符合用户需求。
相似度改进
上述相似度计算公式有两个改进点:一是未考虑用户行为的先后顺序,比如用户先后浏览了POI ,之前会两两计算相似度,实际只用计算A和以及B和C的相似度即可,因为用户是先浏览了A再浏览了B,所以浏览A时可以推荐B,但浏览B时推荐A不一定合适。二是未考虑POI之间的时间序列跨度,理论上A和B的相似度应该高于A和C的相似度。
改进后的相似度公式如下,其中l
表示POI i和j的序列跨度长度,Nijl是POI i和j序列长度为的次数,α
是序列跨度的衰减系数(<1):
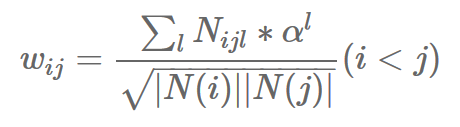
召回策略全景视图
经过一年的迭代,目前线上在线的召回策略如下图,此外还尝试了基于ALS的矩阵分解,但推荐的结果比较冷门,可解释性较差;另外启动了基于用户标签的推荐,对用户和POI都打上相应的属性标签,可以直接单维度标签进行推荐,比如:给亲子类用户推荐亲子类POI,也可以把标签当做维度,多维度计算用户和POI的相关性。
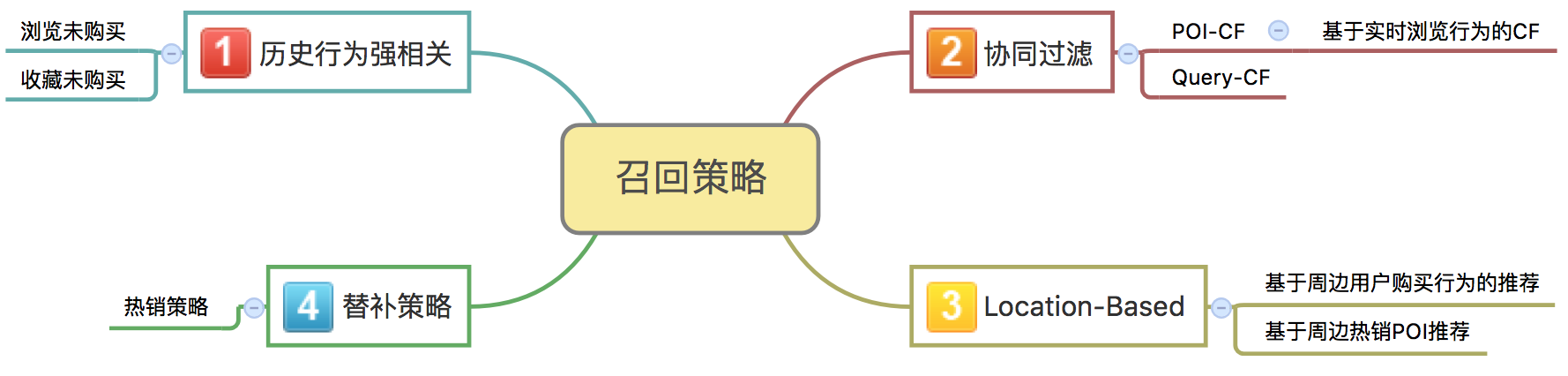
每类召回策略的结果都需要做过滤,过滤策略主要有几类:
- 黑名单过滤。如源头有脏数据或需要人工干预的Case。
- 无售卖POI过滤。即过滤没有售卖Deal的POI。
- POI距离过滤。过滤据当前浏览城市几百公里外的POI。
- 非当前城市过滤。过滤非当前浏览城市的POI。
- 已购买POI过滤。
| 召回策略 | 过滤规则 |
|---|---|
| 热销策略 | POI距离过滤 |
| 历史行为强相关 | 已购买POI过滤/非当前城市过滤 |
| Location-Based | 非当前城市过滤 |
| ItemCF | 已购买POI过滤/非当前城市过滤 |
排序策略迭代
每类召回策略都会召回一定的结果,这些结果去重后需要统一做排序。在早期只有热销策略一个时不需要Rerank,直接根据热销得分来排序,加入历史行为强相关和Location-Based策略后也是按固定展位交叉展示的,比如:第1、3、5、7位给历史行为强相关策略,第2、4、6、8位给Location-Based策略。
在2016年Q1初尝试了第一版的Rerank策略,当时推荐样式还是Deal,因此排序对象也是Deal,主要特征是30/180天的销量/评分数据,因为考虑的特征比较少,上线后效果并不明显。
在Q2初由于基本完成了POI化展示,排序对象变成POI,主要特征包括销量、评分、价格、退款数据,上线后效果仍不明显。
因为推荐列表页跟筛选列表页类似,在Q2中期尝试直接接入筛选Rerank,但效果不太理想。随后基于推荐的数据样本重新进行了训练,并新增了一些特征,特征上大致分为以下几类:
| 特征维度 | 特征名称 | 说明 |
|---|---|---|
| 上下文 | HOUR_OF_DAY | 一天中的第几小时 |
| DAY_OF_WEEK | 一周中的第几天 | |
| CITY_ID | 客户端选择城市id | |
| DISTANCE | 用户和POI的距离 | |
| POI | REC_POI_CTR_DAY7 … | POI 7天的点击率 |
| POI_ALLCATE_PAY_F_CNT_DAY7… | POI 7天的支付数据 | |
| POI_COMMENT_CNT_DAY7… | POI 7天的评分数 |
从上表看在销量和评价基础上主要新增了上下文特征、距离特征和访购相关特征,注意到HOUR_OF_DAY、DAY_OF_WEEK、CITY_ID并没有采用one-hot编码,在线上实验one-hot编码效果并不优于直接使用原始值。可能的解释是HOUR_OF_DAY离散值可以用于树模型来分类,比如:0~11点可以表示上午、12点~18点可以表示下午、19点~23点表示夜晚;同理DAY_OF_WEEK周一到周四可以认为是平日,周五到周日认为是周末;CITY_ID可能的解释是ID越小,越是开站较早的城市,也是更热门的城市。
模型上取最后一个点击前的样本为候选样本集,以支付为正样本,其他为负样本,正负样本采样比为1:10。如果不做样本采样,假设每100人访问只有1个支付,每次访问列表页假设用户平均能看到10个POI,即正负样本比例大约为1:1000,样本分布极不均衡,容易导致过拟合。模型训练上采用XGBoost算法,上线后点击率和访购率均明显正向,证明了Rerank的有效性。
在上述基础上后续又逐步丰富了上下文特征,比如:召回可能触发周边城市圈的POI,因此增加POI是否本城市的特征,另外热销召回策略拆分了本异地,Rerank也对应增加了用户请求是否本异地特征;增加了User-POI组合特征:User 7天内是否浏览/收藏过POI、实时特征、基于协同过滤的User-POI相关性等,跟历史行为强相关、协同过滤的召回策略能相呼应;增加了POI静态属性特征,如:星级,另外把POI的销量也按本异地进行了拆分。这些特征上线后效果基本都正向,符合预期。
| 特征维度 | 特征名称 | 说明 |
|---|---|---|
| 上下文 | SCENE_LR | 是本地OR异地用户 |
| IS_POI_LOCAL | POI是否本城市 | |
| User-POI | POI_VIEWED_DAY7… | POI 7天内是否被浏览过 |
| POI_RT_VIEWED… | 实时特征:用户最近是否浏览过 | |
| REC_POI_CF_SCORE… | 通过POI CF计算出的User和POI的语义相关性 | |
| POI | PLACE_STAR… | 景区星级 |
| POI_SCENE_PAY_F_CNT_DAY7… | POI分本异地的销量(当用户是本地请求时使用本地销量,异地时使用异地销量) |
模型上尝试了短周期模型+长周期模型的融合,短周期为近期一个月数据,长周期为近期三个月数据。从线上结果看直接用短周期模型效果最好,这可能跟旅游应季变化快有关。除了上述特征外,后续还可以增加User个性化特征、天气上下文特征、POI特征CTR/CVR可以拆分本异地等。
排序策略全景视图
推荐的离线训练流程跟搜索、筛选排序保持一致,流程图如下:

- 首先是数据标注,数据源是原始的样本日志,记录在Hive中,输出是ISample对象,同时打上label。另外可能部分特征需要在线上生产并写入样本日志中,比如:实时特征,没办法用离线ETL采集;
- 样本选择:对初始样本做过滤,比如:过滤最后一个点击样本之后的数据,输出还是ISample;
- 特征抽取:在样本中有POI ID,根据POI ID可以抽取POI的销量、评价等特征;同理可以根据样本中的UUID抽取用户相关特征。这样就生成了带上Feature的Sample;
- 数据采样:按事先定义的正负样本比例对样本进行抽象;
- 训练集构建&输出:按XGBoost格式输出训练集。
整个训练集的构造过程由Scala编写在Spark集群上运行,而由于XGBoost的Spark版本效果不太稳定,在最后的模型训练与评估中使用的XGBoost的单机版本,模型的训练参数(迭代次数、树的深度等)一般选取经验值,训练集选一个月的数据,测试集一般选训练集日期后的若干天,离线评估指标主要参考AUC,离线效果有提升就会上线ABTest实验,逐步迭代。
工程架构设计
推荐系统的整体工程架构如下图,从下至上包括离线计算层、核心数据层、推荐服务层和应用场景层,另外是后台配置管理系统和数据调度服务。
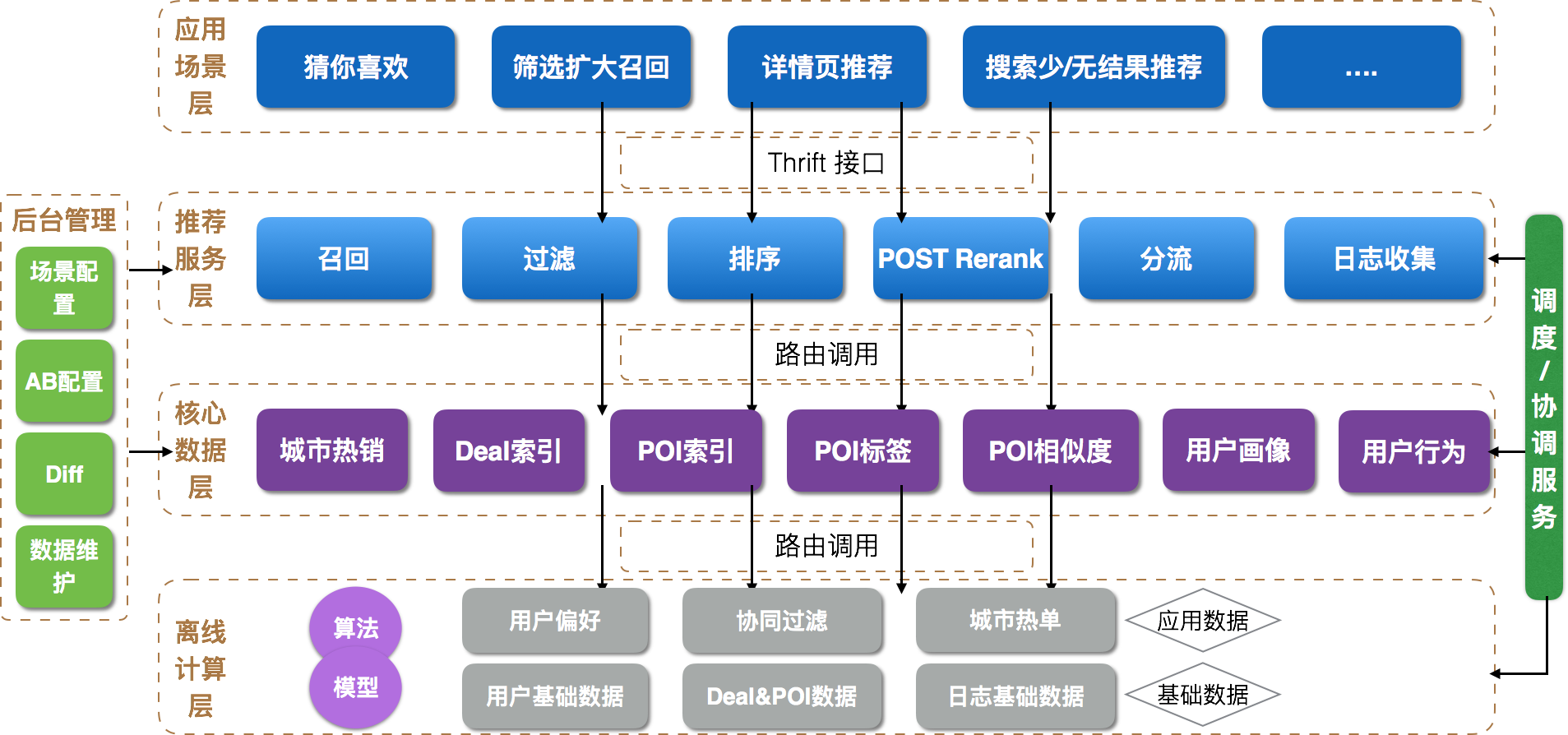
离线计算层
离线计算层除了Rerank需要的特征和训练日志外,主要包括基础数据和应用数据两类。基础数据中最重要的是Deal和POI的数据,为了保证数据的准确性和实时性,Deal和POI的数据直接从旅游产品中心去取,通过定时全量拉取并辅以消息队列实时更新。应用数据按生产方式又可以分为三类:
- Hive ETL生产的数据:比如POI过滤需要用到的离线表(主门店等逻辑),另一大类是统计数据,比如:城市POI热销、线路游热销、用户对POI的浏览/购买行为。
- Spark生产的数据:比如:User CF、POI CF、矩阵分解算法等,这类数据生产逻辑复杂,不好直接通过ETL计算完成。
- Storm生产的数据:用户实时行为在召回、排序都需要用到,目前公司提供统一的实时用户行为数据流user__action_basic,包括:浏览/收藏 POI/Deal、下单、支付、消费、退款,从中过滤出旅游POI/Deal的行为即可。
核心数据层
抽象出核心数据层的一个重要原因是需要离线计算工程和线上服务工程复用DataSet,从供线上使用的存储方式看可以分为三类:
- 存储在ElasticSearch(以下简称ES)中的数据。主要是POI/Deal索引,比如:POI的地理位置、所在城市,当线上需要根据地理位置过滤时可使用ES查询,比如:城市圈的距离限制,Location-Based策略一定距离内的召回。另外对于多维查询场景ES也比KV存储更为合适。这类数据通过公司统一的任务调度系统来定时调度,通常几小时更新一次。这里为ES索引建立一个别名,离线更新索引切别名的指向,保证操作的原子性。
- 存储在DataHub中的数据。DataHub是酒旅搜索团队开发的一套数据管理系统,集数据存储、管理、使用于一体。目前支持将Hive表的数据定期导入,DataHub内部主要使用Tair作为存储,对客户端使用透明,客户端接口支持一维和二维的Key,接口对应用方基本是一致的,另外应用方也不需要自行维护Tair集群配置管理了。DataHub自带调度功能,通过扫描HDFS分区生成后自动写入Tair。
- 直接存储在Tair中的数据。主要面向DataHub还不支持的两类场景,一是实时数据的存储落地,二是value直接存储对象,存储为对象的好处是从Tair读取出来的对象可直接供线上使用,无需自行序列化和赋值。实时数据无需定时调度,通过Spark直接写入Tair的数据通常需要依赖上游Hive表先Ready才能执行,所以通过公司统一的数据协同平台调度。
推荐服务层
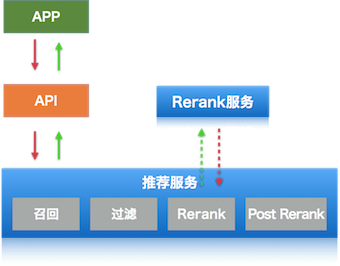
服务上下游
推荐上下游的架构图如下图,客户端向API发起调用,API调用推荐服务拿到推荐的ID再添加供App展示用的相关字段传会给App。推荐和搜索没有整合成一个服务的重要原因是推荐的召回策略复杂多样,每次请求可能命中多个召回策略,而搜索单次请求的意图一般比较单一,通常只有一个召回策略。另外推荐服务重点在召回和过滤,Rerank调用独立的rank服务,原因是推荐Rerank和搜索筛选Rerank在特征上有很多是可以复用的,比如:用户特征、POI特征等。
整体流程
推荐服务向下从数十个数据源中获取数据,经过业务逻辑处理后向上支持数十个应用场景,整个调用流程如下:
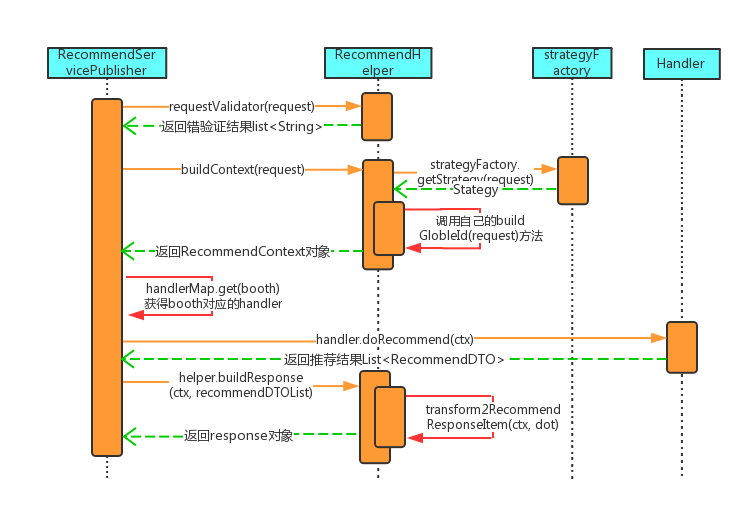
- RecommendServicePublisher作为服务的入口,从Client接到Request请求后首先验证请求是否合法,比如:请求参数中场景Booth和UUID不能为空。
- 构造请求上下文Context,其中会生成唯一的global ID标识一次请求,根据UUID查询用户画像服务获取常驻城市,根据定位的经纬度查询定位城市,以及根据ABTest分流配置获取处理请求的召回排序Strategy。
- 根据请求场景的Booth获取对应的Handler,默认使用统一的AbstractHandler即可,包括召回、过滤、rerank、post rerank。
- 对Handler返回的结果做包装,增加召回和排序策略名称、得分等,最终返回给Client。
核心流程与模型
Handler是整个流程的核心,其调用流程如下:
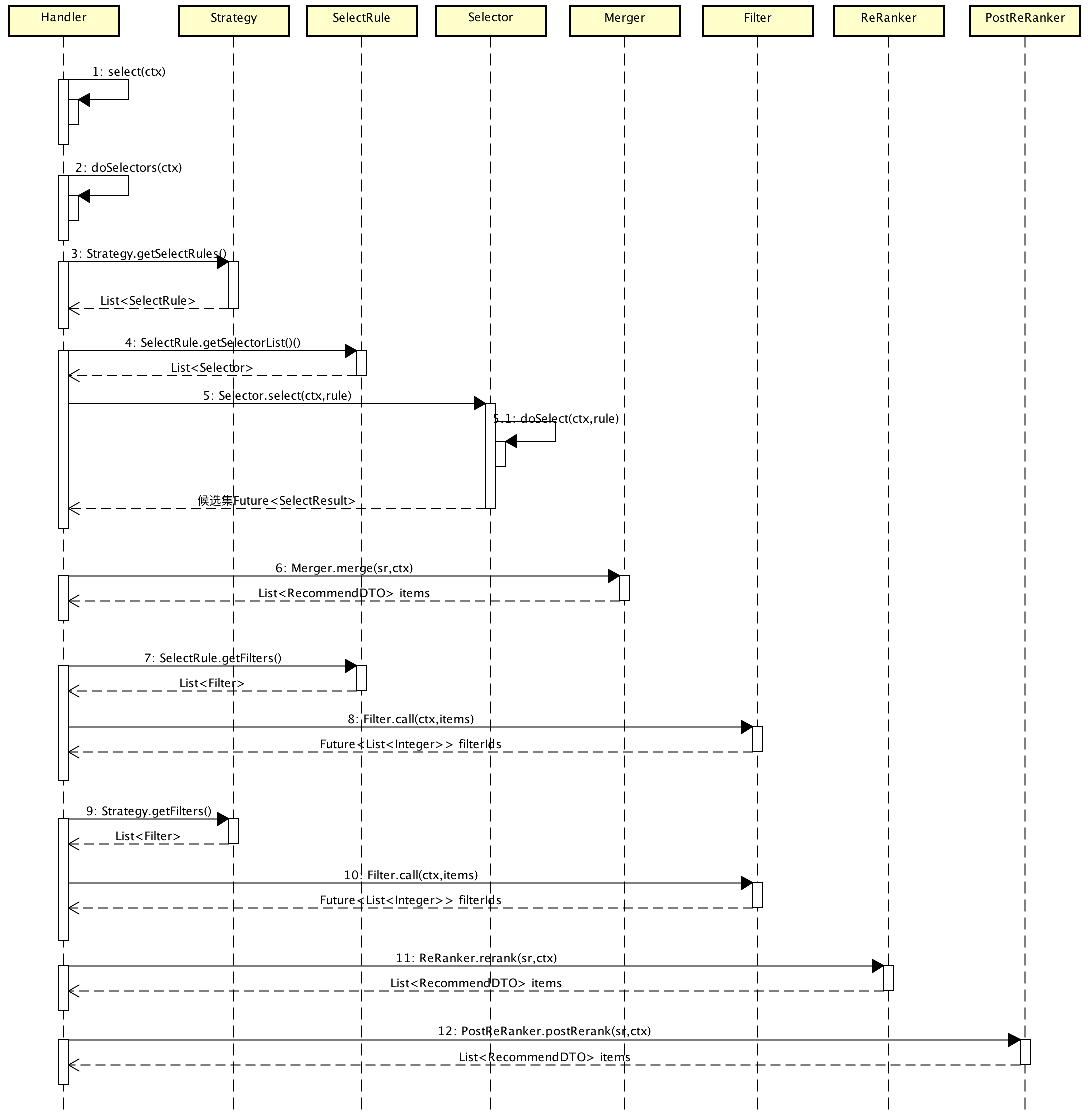
- Handler根据不同的Strategy获取对应的SelectRule集合,一个场景Booth可能对应多个Strategy,跟ABTest对应,比如:Baseline就是一个Strategy。每个Strategy可能有多个SelectRule,比如:Baseline策略由历史行为强相关SelectRule、Location-Based SelectRule、热销Rule等组成。
- 召回:每个SelectRule又对应多个Selector,多个Selector通过线程池并发获取结果,比如:Location-Based Rule可以细分为基于周边热销POI召回和基于周边用户购买POI召回。Selector可再做抽象,比如:分本异地场景的城市热销策略,美团和点评双平台都需要,只是数据源稍有不同,另外对于从ES和DataHub获取的数据可以加Cache。
- Merge去重:多个召回策略的结果需要Merge去重,比如早期没有Rerank时Location-Based策略固定在2、4、6位。
- 过滤:具体有两级过滤,一级是针对SelectRule的,比如:针对历史行为强相关策略中基于浏览行为和收藏行为召回的结果都需要过滤用户已购买过的POI;另一级是针对所有策略通过的过滤,比如黑名单、旅行社代理商。
- 重排序:对于POI列表调用POI Rerank服务,对于Deal列表调用Deal Rerank服务。
- PostRerank:一般用于处理广告运营的需求和人工干预的Case。
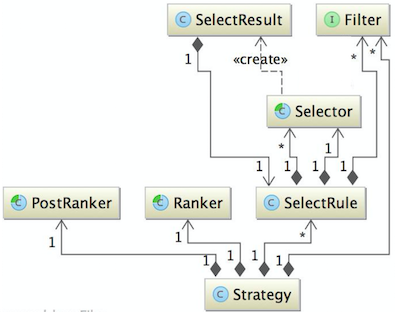
核心的对象模型如下图:
监控降级
监控分为离线监控和实时监控两部分,离线监控使用Falcon来监控以下几类指标:
- JVM监控:比如FullGC次数、内存使用情况、Thread block情况
- ES监控:ES查询次数和平均响应时间
- 业务监控:各接口、各策略的请求次数和平均响应时间
实时监控接入公司统一的实时数据统计平台,可以分时、分多粒度统计各Booth的请求次数和响应时间。
降级主要通过Hystrix来实现,比如:调用Rerank服务在一定时间内响应时间超过设定的阈值,则直接熔断不请求Rerank服务。
工具化
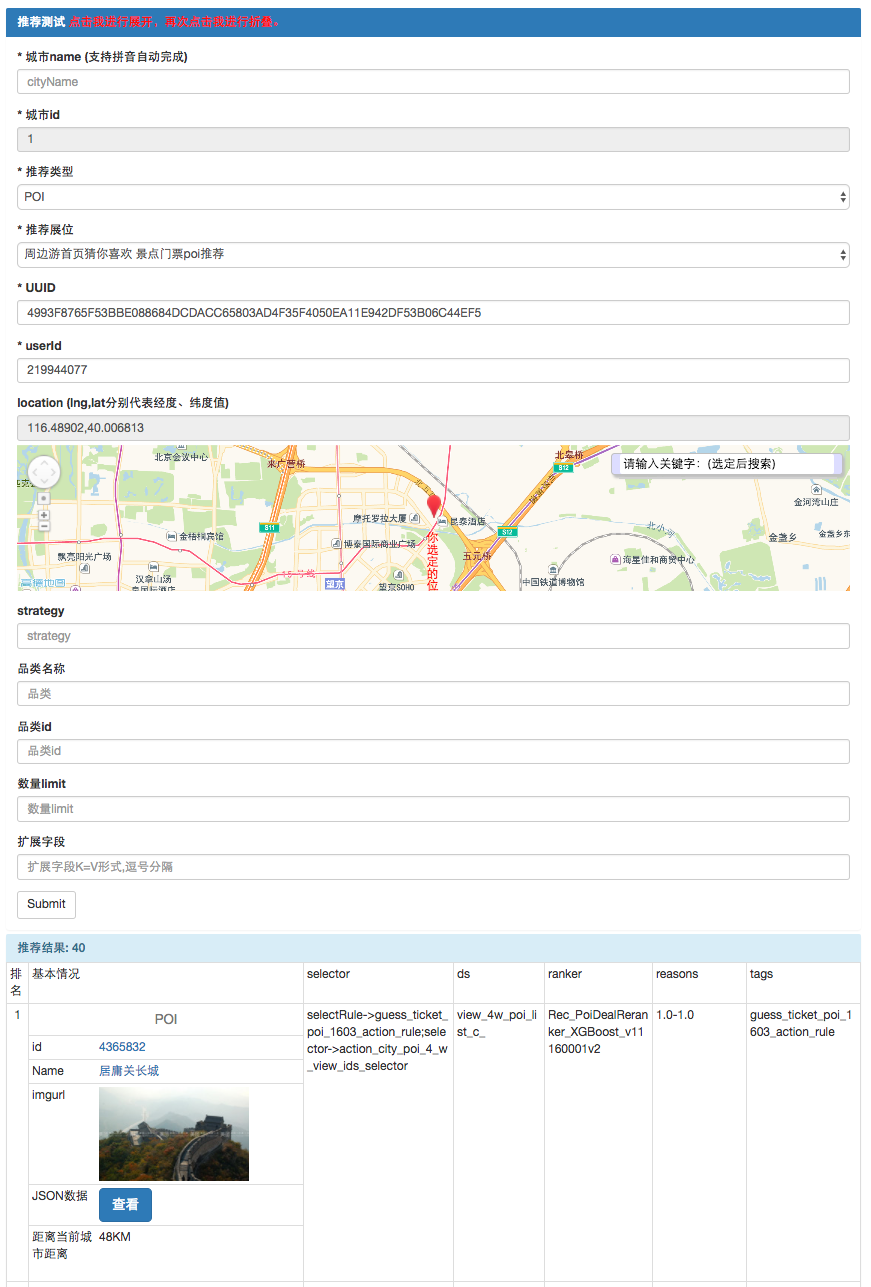
推荐服务开发了Debug工具,输入支持城市、展位、UUID、经纬度等参数,输出展示了POI/Deal的头图、标题、和用户的距离、召回排序策略与得分等。方便PM和RD测试、定位追查Case。
应用场景
推荐系统支持了美团/点评共20个应用场景,主要场景是周边游频道首页猜你喜欢,其召回策略在上文中已有阐述,这里重点阐述其他几类推荐场景:
跟团游推荐
跟团游Deal一般会绑定多个景点,不适合按POI样式展现,因此采用Deal形式展现,召回策略跟热销POI策略类似,区分本异地,从结果看北京本地人会推荐“古北水镇一日游”,外地人浏览北京时会推荐“故宫、长城一日游”。
筛选异地召回
用户在筛选酒店时会先选择入住城市再筛选该城市的酒店POI,而周边游存在客源地旅游资源不丰富的问题,筛选时需要突破选择城市限制,能够推荐出周边城市的热门POI,筛选异地召回上线后增加了一定比例的订单,是对本地召回的有效补充。
筛选主题标签挖掘
即为POI打标签,用户可以用这些标签进行筛选,比如:附近热门、近郊周边、周末去哪、亲子同乐、夜场休闲。每个标签都可以定义一套挖掘方法,比如:“亲子同乐”有以下几类方法:
- POI下有亲子票种
- Deal标题包含“亲子”
- 同一POI下同时包含“成人票”和“儿童票”
- 用户画像为“亲子”的用户最近一个月购买的POI
上述挖掘方法偏规则,后续希望能通过半/无监督方法,挖掘POI描述和评论,自动为POI打标。
搜索少/无结果推荐
搜索少结果推荐是指当搜索结果POI类聚结果数=1时,为丰富页面内容给用户提供推荐信息。这里重点利用搜索的POI结果根据POI CF触发推荐,以及利用搜索POI的品类进行同城市同品类推荐。
搜索无结果推荐可以直接统计搜索Query后一定时间内用户浏览的POI做推荐,但这个策略的覆盖面有限,进一步可以计算一段时间内的Query CF,然后做协同推荐;另一方面可以通过意图识别判断Query中是否有品类词,触发同品类推荐。
酒旅交叉推荐
目前只实现了酒店和旅游之间的交叉推荐,当用户在酒店频道搜索时先判断Query是否旅游意图,其中重点分析两类意图:一是景点POI意图,推荐该景点几公里范围内的POI;二是品类意图,比如:温泉、滑雪,会推荐用户定位附近该品类的热销POI。
在酒店POI详情页会获取酒店POI的地理位置,推荐酒店附近的景点。对于异地用户浏览酒店时都会触发景点推荐,对于本地用户只有在浏览郊区酒店时会触发旅游推荐,这是假设本地用户在浏览市区酒店时旅游度假的意图可能不明显。
除了在各类推荐场景的应用,这些策略在运营上也有应用尝试,比如:用户浏览或购买过POI后根据POI CF给用户PUSH相似的POI,实验证明推荐策略的PUSH点击率要高于平均水平。
未来的挑战
经过一年多的迭代优化,周边游频道内相当比例的订单来自推荐,线上支持了20个左右的推荐场景,很多推荐策略被作为特征加入搜索、筛选Rerank,有明显正向效果,在用户运营上也有了初步的探索。基于目前的推荐系统本身还有不少优化点:
- 召回策略:策略的广度和深度都有不少提升空间,广度方面可以继续探索矩阵分解FFM、User CF、基于用户画像的推荐、图挖掘;深度方面尝试LLR等多种相似度计算方法、以及多时间/多用户维度改进召回策略。数据上可以扩大到酒店甚至美团全平台的用户数据,另外对策略的离线实现还要更模块化、抽象化,比如:相似度改进算法在一处场景验证有效,可快速推广上线到其他场景
- 排序策略:特征工程方面可以增加User个性化特征、天气/Listwise上下文特征等,模型上可以尝试DNN等方法,评估指标可以从访购率改进成访消率(消费UV/访问UV),另外对美团/点评双平台可以定制不同的特征数据和排序策略
- 工程架构:搜索少/无结果推荐从搜索工程迁移到推荐工程,另外对核心数据层存储方式的边界划分,线上服务层的缓存、Selector/Rerank降级、Filter/Merge逻辑梳理等需要做“轻量重构”
- 应用场景:除了在酒店购买前的交叉推荐外还可以增加购买后的推荐,以及和机票、火车票大交通相关的交叉推荐,在旅游内部可以探索更多的场景化建设,比如:亲子游、情侣游
跳出目前单一的以POI/Deal列表为主体的推荐形态看,可以从用户、场景、内容、触达方式四个方面看如何做好旅游推荐:
用户需求
首先考虑用户是谁?要满足用户的什么需求?这里可以利用美团/点评的数亿用户,打“人群标签”,是一二线城市高端品质女用户、勤俭住宿的中年大叔还是三线城市实惠型年轻妈妈。然后分析这些人群背后的需求,是本地休闲用户、差旅用户还是高频度假用户,不同用户的需求是不一样的。
场景划分
当知道用户后需要知道用户的场景是什么?可以从四个维度定义场景:时间、位置、行为、渠道。

时间很好理解,当用户在周四周五搜索“滑雪场”,会被认为是休闲度假周末用户,可以协同推荐北京郊区的滑雪场。
地理位置是核心要素,要根据用户的常驻城市和客户端选择城市来判断是本地还是异地需求,对于异地的差旅用户可以推荐商务型的酒店。
行为是用户需求最直接的反应,比如:用户搜索“古北水镇”,不管用户后续是否有浏览行为,都可以推荐古北水镇相关的酒店和景点门票。
渠道包括美团/点评双平台App、i版、PC等多个终端,以美团App为例,周边游、酒店、机票/火车票频道的用户特征都不一样,比如:大交通频道最常见的是差旅用户、周边游频道更多是本地度假休闲的人群。
内容形态
知道了用户是谁以及处于什么场景,要考虑提供什么样的内容产品?对于美团来说核心是交易,内容不是最核心的目标,但内容是一个非常好的引流措施。以本地场景为例,可以加强场景建设,比如:亲子、团建、温泉等;异地行前场景可以加强目的地、点评游记攻略、酒店交通行程安排等内容建设。
触达方式
除了目前的搜索推荐外,还可以增加定向投放、内容引导、广告植入、活动运营等多种触达方式。
总之旅游推荐问题复杂多样,需要从度假出行六要素:吃、住、行、游、购、娱综合考虑和规划,对产品形态、业务策略、技术架构都还有很大的挑战和机遇。
2017年6月10-11日,SDCC 2017·深圳站之架构&大数据峰会将于深圳中南海滨大酒店开幕,涵盖高可用/高并发/高性能的系统架构设计、分布式缓存服务、Web App前端架构、消息引擎架构、弹性计算、大数据平台构建、优化提升大数据平台的各项性能、Spark部署实践、企业流平台实践,以及实现应用大数据支持业务创新发展等核心话题,更多嘉宾和议题参见峰会官网和敬请注册参会,目前门票6折售票中。
主编推荐:架构技术实践系列文章(部分):
- 郑刚:旅游推荐系统的演进
- 陈清渠:日处理20亿数据,实时用户行为服务系统架构实践
- 者文明:OLTP类系统数据结转最佳实践
- 王晓波:同程旅游缓存系统(凤凰)打造Redis时代的完美平台实践
- 张成远:京东分布式数据库系统演进之路
- 丛磊:一场完美的“秒杀”:API加速的业务逻辑
- 熊明辉:缓存那些事
- 倪江利:魅族推荐平台的架构演进之路
- 章耿:服务化框架技术选型实践
- 赵琨:视频直播早期创业团队的技术架构与选型
- 卢誉声:分布式实时处理系统架构设计与机器学习实践
- 陈斌:架构师的必备素质和成长途径
- 林伟:高可用的大数据计算平台如何持续发布和演进
- 柳宗扬:蘑菇街直播实战技巧带你解决直播开发难题
- 胡骏:详解自动化运维平台的构建过程
- 黄日成:从UDP的连接性说起——告知你不为人知的UDP
- 林昊:阿里超大规模Docker化之路
- 罗金鹏:双11媒体大屏背后的数据技术与产品
- 袁岳峰:手机端创新体验——手把手教你搭建VR&AR架构
- 张铭:双11背后的网络自动化技术
- 王鹤:Vue.js 2.0源码解析之前端渲染篇
- 黄日成:从TCP三次握手说起–浅析TCP协议中的疑难杂症
- 厉心刚:JavaScript引擎分析
- 蓝邦珏:来看看机智的前端童鞋怎么防盗
- 陈志兴:让页面滑动流畅得飞起的新特性:Passive Event Listeners
- 唐聪:大规模排行榜系统实践及挑战
- 左明:半小时深刻理解React
- 王照辉:魅族自动化测试架构之路
- 翁宁龙:美团数据库运维自动化系统构建之路
- 何轼:美团外卖订单中心的演进
- 申政:唯品会多线程Redis设计与实现
- 阿刘:千万级用户的Android客户端是如何养成的
- 卜赫:大道至简——React Native在直播应用中的实践
- 陈爱珍:从运维的角度看微服务和容器
- 孙其瑞:VR应用在直播领域上的实践与探索
- 刘丁:bilibili高并发实时弹幕系统的实战之路
- 秦鹏:从应用到平台,云服务架构的演进过程
- 郭炜:从0到N建立高性价比的大数据平台
- 李智慧:宅米网技术变迁——初创互联网公司的技术发展之路
- 陶文质:分布式系统设计的求生之路
- 魏晓军:React Native实践之携程Moles框架
- 学霸君姜波:耳目一新的在线答疑服务背后的核心技术
- 爱乐奇麦凯臻:在线教育的内容研发和技术的迭代创新
- 长虹李玮:老牌消费电子企业如何拥抱Docker
- 徐汉彬:日请求过亿的Web系统PHP7升级实践
- 窦威:AcFun的视频架构演化实践
- 傅鸿城:QQ亿级日活跃业务后台核心技术揭秘
- 宁峰峰:尖峰日96万订单,59校园狂欢节技术架构剖析
- 梁阳鹤:每秒处理10万订单乐视集团支付架构
- 沈辉煌:亿级日PV的魅族云同步的核心协议与架构实践
- 李任:携程Docker最佳实践
- 王海军:游戏研发与运营环境Docker化
- 史海峰:当当网高可用架构之道
- 黄哲铿:应对电商大促峰值的九个方法
- 1号店交易系统架构如何向「高并发高可用」演进
- 京东闫国旗:从C10K到C10M高性能网络的探索与实践
- 李林锋:服务化架构的演进与实践
- 1号店架构师王富平:一号店用户画像系统实践
- 唯品会官华:实现电商平台从业务到架构的治理体系
- 沈剑:58同城数据库架构最佳实践
- 荔枝FM架构师刘耀华:异地多活IDC机房架构
- UPYUN的云CDN技术架构演进之路
- 初页CTO丁乐:分布式以后还能敏捷吗?
- 陈科:河狸家运维系统监控系统的实现方案
- 途牛谭俊青:多数据中心状态同步&两地三中心的理论
- 云运维的启示与架构设计
- 魅族多机房部署方案
- 艺龙十万级服务器监控系统开发的架构和心得
- 京东商品详情页应对“双11”大流量的技术实践
- 架构师于小波:魅族实时消息推送架构











![[DNS 设置] 电脑无法访问网页,但可以正常使用QQ和微信。](https://img-blog.csdnimg.cn/bc1063fe2c5647ba9649a39f69f63700.png)