一、概述

二、要点分析原始ppt解读
2.1 作用:语义表达作用检索+聚类

2.2 简述:简单的对比学习来做语义表征
- 预训练+对比学习:最佳的语义表征方法
- 无监督:dropout
- 有监督:NLI 蕴含+矛盾数据
- 原理:
- 利用对比学习目标,将预训练的embedding进行uniform化
- 利用监督数据,aligns对齐相同语句的embedding表达

2.3 原理:对比学习原理
- 拉近邻居,push非邻居

2.4 目标函数:无监督学习目标函数
- 正样本:相同句子,独立的dropout mask
- 负样本:batch内,其他句子的embedding

2.5 目标函数:监督学习目标函数
- 正样本:NLI数据集 蕴含 样本
- 负样本:batch内的负样本+矛盾样本,原来是两部分啊?相当于利用标注的负样本做了一个补充

2.6 主要评估方法:语义相似度任务,而非下游文本分类任务

2.7 结果:无监督学习结果

2.8 结果:监督学习结果

2.9 原因分析:为啥能更好呢?构造无监督正样本对的方法不一样
- SimCSE:dropout
- 其他方法:
- 下个句子增强
- 同义词替换
- crop
- 删除
- 优点总结:
- 用他自己来做正样本>>下一个句子来做正样本
- dropout增强>>其他数据增强


2.10 embedding表征特点分析:embedding各向异性分析
- 预训练模型好的alignment,差的uniformity
- 后处理可以改进uniformity
- SimCSE:改进uniformity并且保持好的alignment性质


2.11 最终效果
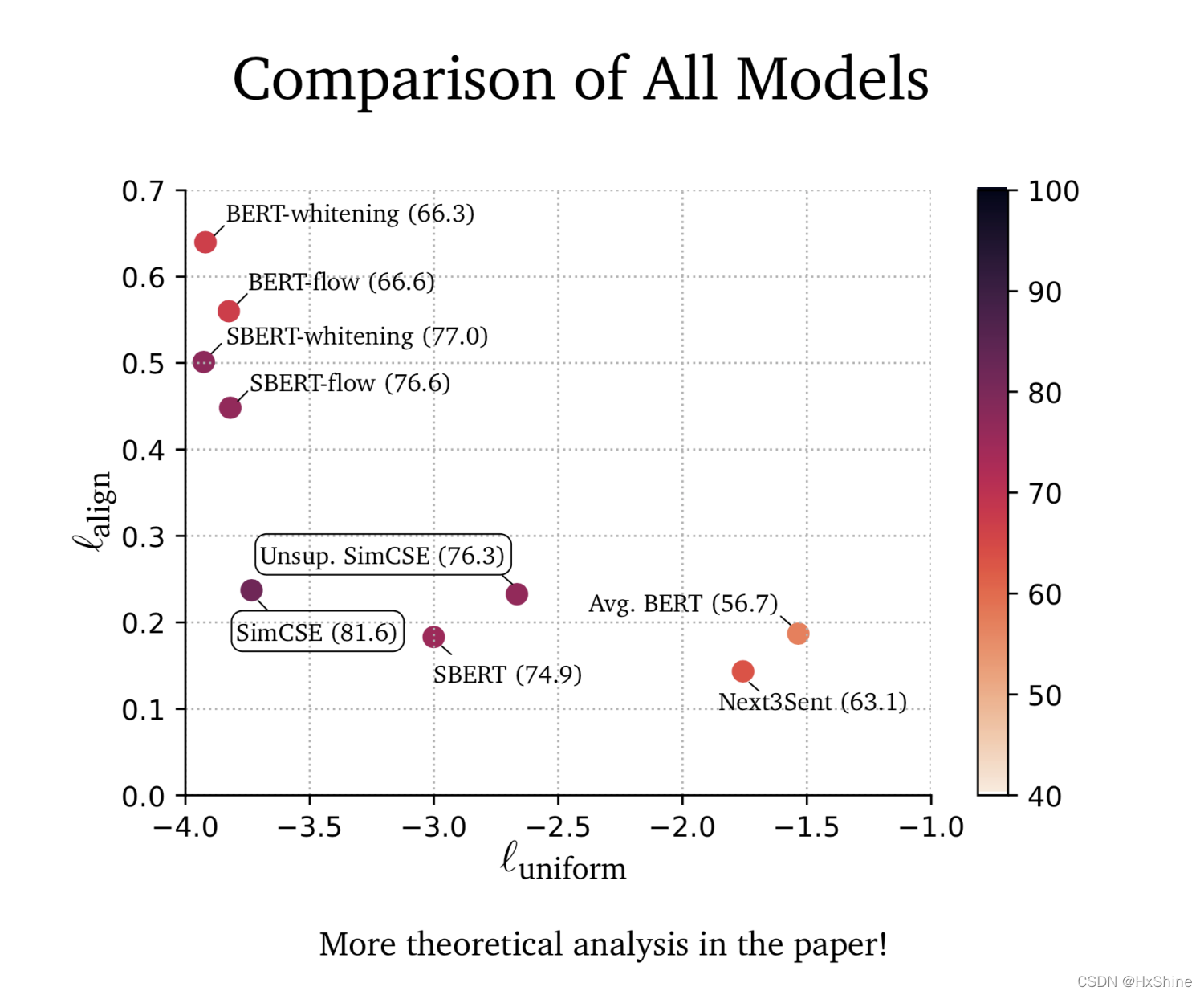
2.12 总结
- SimCSE:对比学习来做句子embedding
- 无监督:标准dropout来做正样本对
- 有监督:entailment做正样本,contradiction来做难样本
- 原因:
- 可以利用alignment和uniformity来分析不同的模型
- 理论显示对比学习能改进embedding的uniformity