请提前准备好python的数据分析相关库,例如pandas、numpy、sklearn等
1. 参加比赛:Titanic
1.1 在比赛页面下载数据
这里以“泰坦尼克号生存率预测”案例为例

train.csv为训练集,
test.csv为测试集,
gender_submission.csv为提交的样例,用于告诉你提交的格式
1.2 分析数据并训练分类器
# -*- coding: utf-8 -*-import pandas as pd #数据分析
import numpy as np #科学计算
from pandas import Series,DataFramedata_train = pd.read_csv("G:/Machine Learning/Kaggle/GettingStar/Titanic/train.csv")
data_trainfrom sklearn.ensemble import RandomForestRegressor### 使用 RandomForestClassifier 填补缺失的年龄属性
def set_missing_ages(df):# 把已有的数值型特征取出来丢进Random Forest Regressor中age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]# 乘客分成已知年龄和未知年龄两部分known_age = age_df[age_df.Age.notnull()].as_matrix()unknown_age = age_df[age_df.Age.isnull()].as_matrix()# y即目标年龄y = known_age[:, 0]# X即特征属性值X = known_age[:, 1:]# fit到RandomForestRegressor之中rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)rfr.fit(X, y)# 用得到的模型进行未知年龄结果预测predictedAges = rfr.predict(unknown_age[:, 1::])# 用得到的预测结果填补原缺失数据df.loc[ (df.Age.isnull()), 'Age' ] = predictedAges return df, rfrdef set_Cabin_type(df):df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes"df.loc[ (df.Cabin.isnull()), 'Cabin' ] = "No"return dfdata_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train)dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin')dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked')dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()from sklearn import linear_model# 用正则取出我们要的属性值
train_df = df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.as_matrix()# y即Survival结果
y = train_np[:, 0]# X即特征属性值
X = train_np[:, 1:]# fit到RandomForestRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(X, y)data_test = pd.read_csv("G:/Machine Learning/Kaggle/GettingStar/Titanic/test.csv")
data_test.loc[ (data_test.Fare.isnull()), 'Fare' ] = 0
# 接着我们对test_data做和train_data中一致的特征变换
# 首先用同样的RandomForestRegressor模型填上丢失的年龄
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
# 根据特征属性X预测年龄并补上
X = null_age[:, 1:]
predictedAges = rfr.predict(X)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAgesdata_test = set_Cabin_type(data_test)
dummies_Cabin = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')df_test = pd.concat([data_test, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("G:/Machine Learning/Kaggle/GettingStar/Titanic/logistic_regression_predictions.csv", index=False)
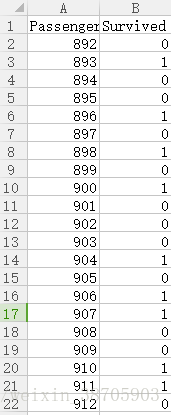
1.3 得到分类结果,根据比赛格式要求,输出
运行完上述代码后,会得到一个logistic_regression_predictions.csv,打开后如图
1.4 提交结果




2. 编码环境
2.1 使用自己的Jupyter Notebook
2.2 使用Kaggle网站上的Notebook
创建一个Kaggle笔记本(“Notebook”),在其中存储所有代码
(1)单击比赛页面上的笔记本(“Notebooks”)选项卡。然后,点击“新笔记本”(“New Notebook”)。

(2)点击“创建”(“Create”)。(不要更改默认设置:“Python”应该出现在“Select language”下面,而您应该在“Select type”下面选择了“Notebook”。)


这显示了比赛数据的存储位置,以便我们可以将文件加载到笔记本中,下一步我们会做的。

至此,你只需要不断的提升你的模型即可













![[开题报告+论文+源码]基于Android仿QQ聊天系统](https://img-blog.csdnimg.cn/img_convert/6bf03e5a5ccca76641e7114835f53966.jpeg)

