将我自己在github pages上的文章转载到这里。
- 卷积神经网络与图像识别背景
- LeNet概述
- ImageNet大规模图像识别挑战赛
- 卷积与图像处理
- 卷积的定义
- 图像卷积的物理意义
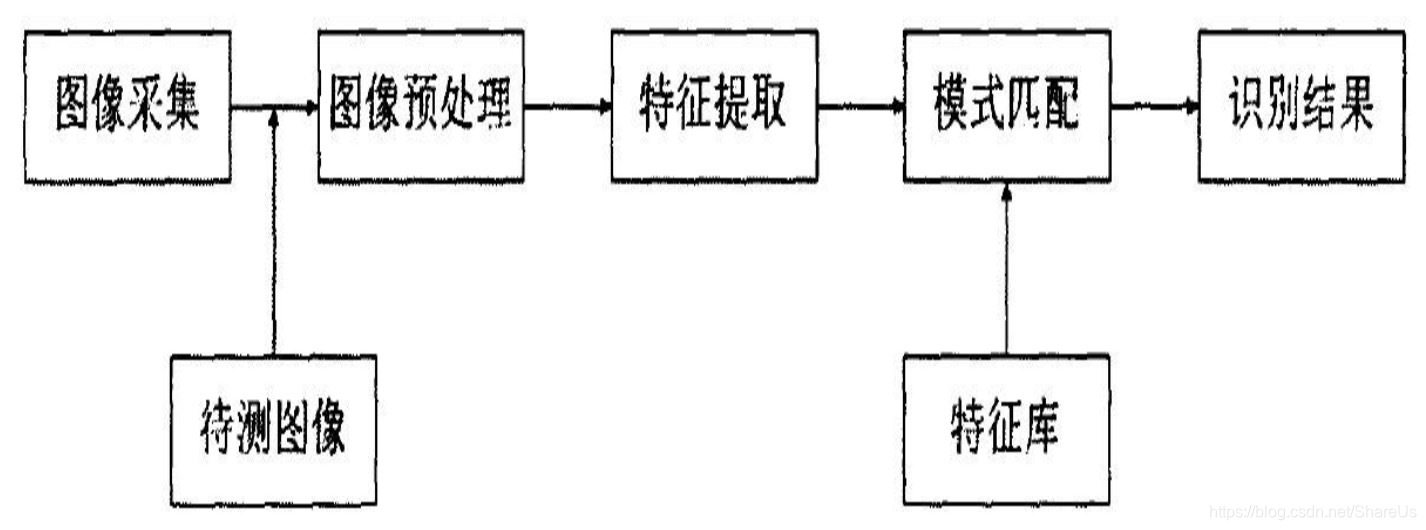
- LeNet详解
- 手写数字识别过程可视化
- 神经网络中的“神经元”和“权重”在哪里?
卷积神经网络与图像识别背景
LeNet概述
LeNet是最早用于深度学习了领域的卷积神经网络之一。Yann LeCun的这一杰作得名于他自1988年以来的系列成功迭代。彼时LeNet架构还主要被用于识别邮政编码等任务。LeNet的基本架构如下:
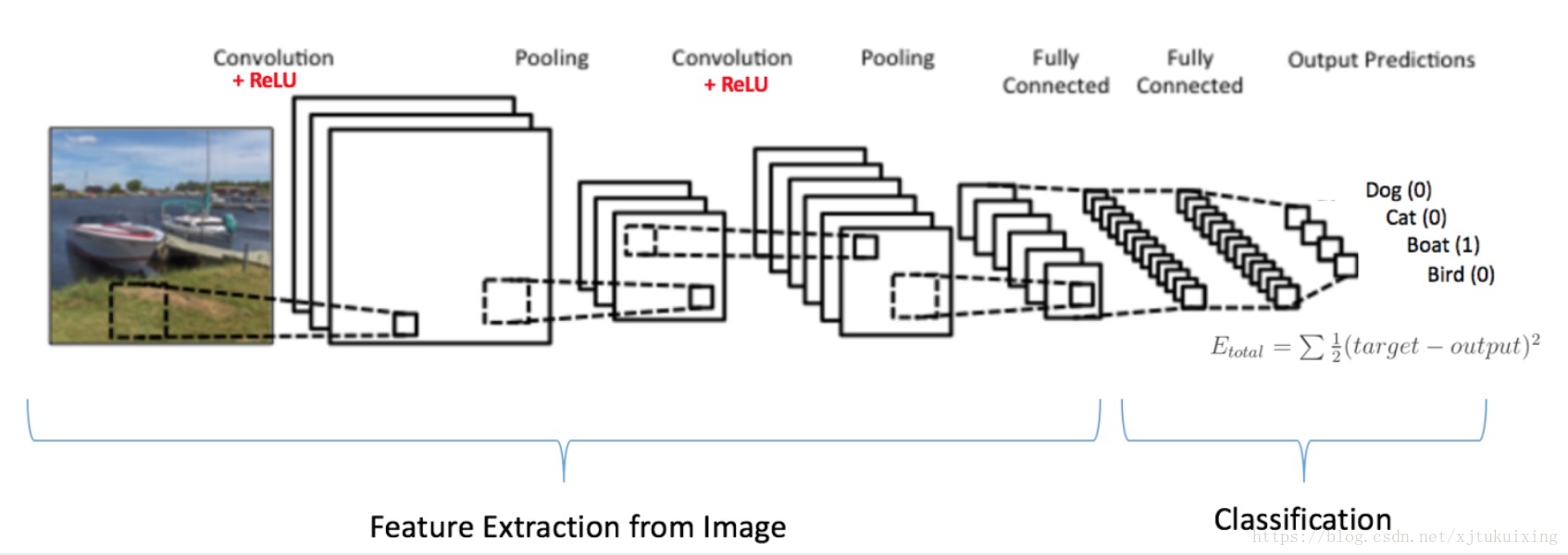
近几年已经出现了很多建立在LeNet之上的新架构,但是基本概念还是来自于LeNet。
卷积神经网络始自1990年代起,我们已经认识了最早的LeNet,其他一些很有影响力的架构列举如下:
- 1990s至2012:从90年代到2010年代早期,卷积神经网络都处于孵化阶段。随着数据量增大和计算能力提高,卷积神经网络能搞定的问题也越来越有意思了。
- AlexNet(2012):2012年,Alex Krizhevsky发布了AlexNet,是LeNet的更深、更宽版本,并且大比分赢得了当年的ImageNet大规模图像识别挑战赛(ILSVRC)。这是一次非常重要的大突破,现在普及的卷积神经网络应用都要感谢这一壮举。
- ZF Net(2013):2013年的ILSVRC赢家是Matthew Zeiler和Rob Fergus的卷积网络,被称作ZF Net,这是调整过架构超参数的AlexNet改进型。
- GoogleNet(2014):2014的ILSVRC胜者是来自Google的Szegedy et al.。其主要贡献是研发了Inception Module,它大幅减少了网络中的参数数量(四百万,相比AlexNet的六千万)。
- VGGNet(2014):当年的ILSVRC亚军是VGGNet,突出贡献是展示了网络的深度(层次数量)是良好表现的关键因素。
- ResNet(2015): Kaiming He研发的Residual Network是2015年的ILSVRC冠军,也代表了卷积神经网络的最高水平,同时还是实践的默认选择(2016年5月)。
- DenseNet(2016年8月): 由Gao Huang发表,Densely Connected Convolutional Network的每一层都直接与其他各层前向连接。DenseNet已经在五个高难度的物体识别基础集上,显式出非凡的进步。
ImageNet大规模图像识别挑战赛
参考一个时代的终结:ImageNet竞赛2017是最后一届,WebVision 竞赛或接。
上面的变种卷积神经网络基本上都来自一项比赛(DenseNet除外):ImageNet大规模图像识别挑战赛(ImageNet Large Scale Visual Recognition Competition,ILSVRC)。
ILSVRC是基于ImageNet图像库的一个图像识别比赛。ImageNet可以说是计算机视觉研究人员进行大规模物体识别和检测时,最先想到的视觉大数据来源。ImageNet 数据集最初由斯坦福大学李飞飞等人在CVPR 2009的一篇论文中推出,并被用于替代 PASCAL数据集(后者在数据规模和多样性上都不如 ImageNet)和LabelMe数据集(在标准化上不如ImageNet)。
ImageNet不但是计算机视觉发展的重要推动者,也是这一波深度学习热潮的关键驱动力之一。截至2016年,ImageNet中含有超过1500万由人手工注释的图片网址,也就是带标签的图片,标签说明了图片中的内容,超过2.2万个类别。
CVPR2017研讨会“超越ILSVRC”将宣布今年是 ImageNet 竞赛正式组织的最后一年,2016年ILSVRC 的图像识别错误率已经达到约2.9%,不仅远远超越人类(5.1%),今后再进行这类竞赛意义也不大了。这无疑标志着一个时代的结束,但也是新征程的开始:未来,计算机视觉的重点在图像理解,而作为ILSVRC替代者的候选人之一是苏黎世理工大学和谷歌等联合提出的 WebVision Challenge,也将于CVPR2017同期举办,内容侧重于学习和理解网络数据。
历届ILSVRC的作品,可以参考ILSVRC历届冠军论文笔记,包含模型框架和识别率等。
卷积与图像处理
卷积的定义
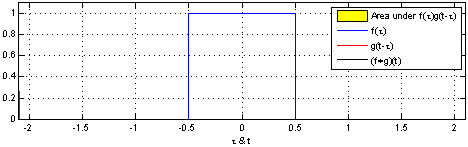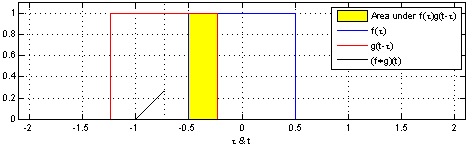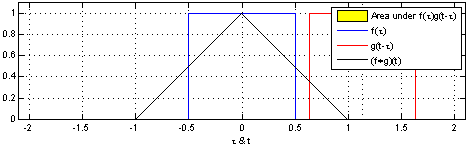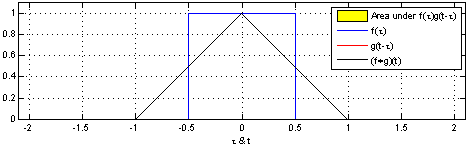
参考Convolution。
图像卷积的物理意义
卷积矩阵也叫“滤波器”、“核”或“特征探测器”。
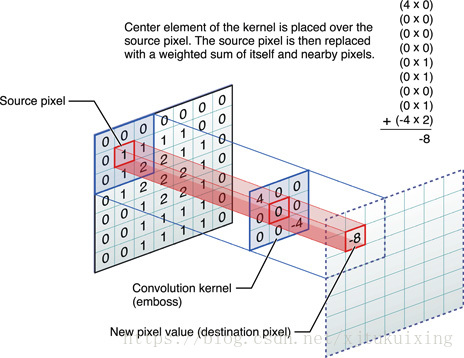

参考Kernel (image processing)。

LeNet详解
参考Basics of Convolutional Neural network (CNN)。
- Convolutional Layer
- Pooling Layer
- Fully Connected Layer
- Understanding Training Process
An Intuitive Explanation of Convolutional Neural Networks的讲解也不错,中文版在这里。
手写数字识别过程可视化

官方网站:
http://scs.ryerson.ca/~aharley/vis/
3D可视化:
http://scs.ryerson.ca/~aharley/vis/conv/
2D可视化:
http://scs.ryerson.ca/~aharley/vis/conv/flat.html
相关论文:
http://scs.ryerson.ca/~aharley/vis/harley_vis_isvc15.pdf
神经网络中的“神经元”和“权重”在哪里?
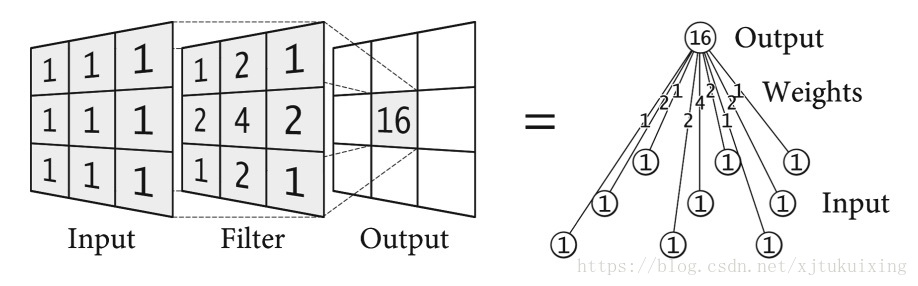
各个卷机滤波器的里面的每个位置的值,即是我们需要训练的权重(卷积滤波器的尺寸是需要我们提前指定好的),每个像素对应于一个神经元。
其中神经网络的基本概念可以参考TensorFlow Playground。