如今,AI产品属实是位于风口浪尖,火的不行,在国外AI产品GPT4公布的第二天,我们熟悉的百度公司就推出了他们家的AI产品“文心一言”。

在百度的发布会中,总裁李彦宏亲自在视频中做出了相应的展示,包括使用文心一言生成文本、图片、音频、视频等功能。
李彦宏的作图的演示

尽管文心一言开始并未被资本市场所看好,但作为大家也能够使用的新技术,手谈姬也早早进行了预约,想把文心一言作为玩具好好把玩把玩。
于是这几天,文心一言生成的图片就广泛在网络上流传,大家惊喜的发现,这百度的AI还挺幽默的,基于它的顶级理解,生成的图片能让人乐的不行。
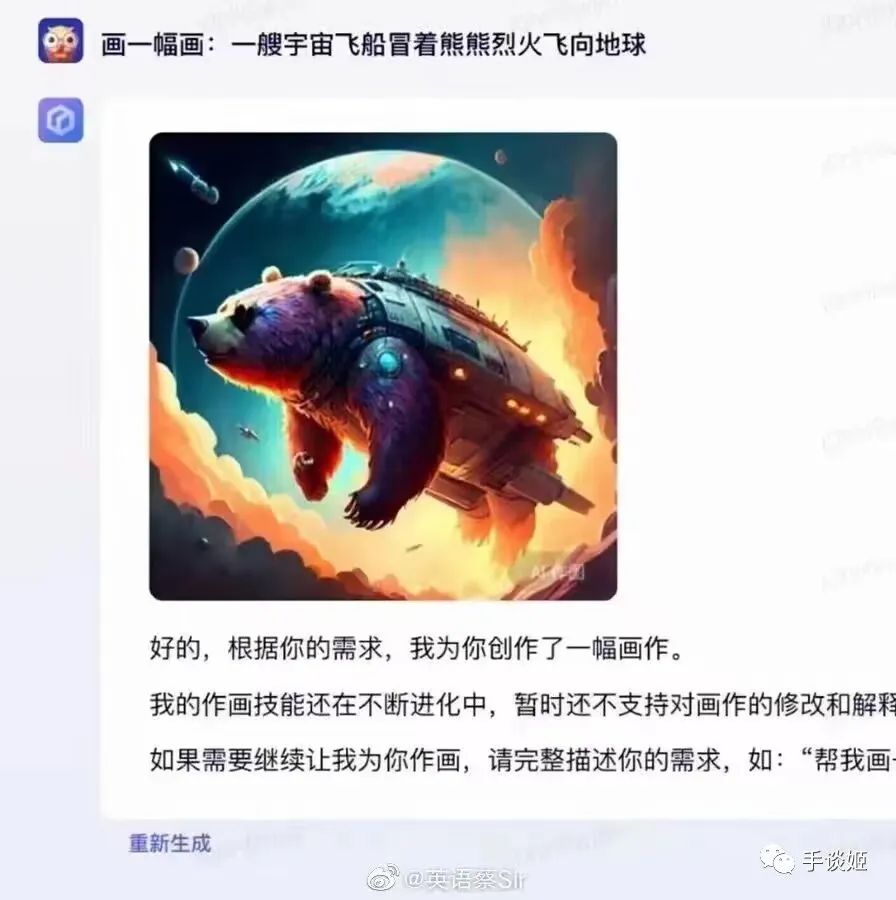


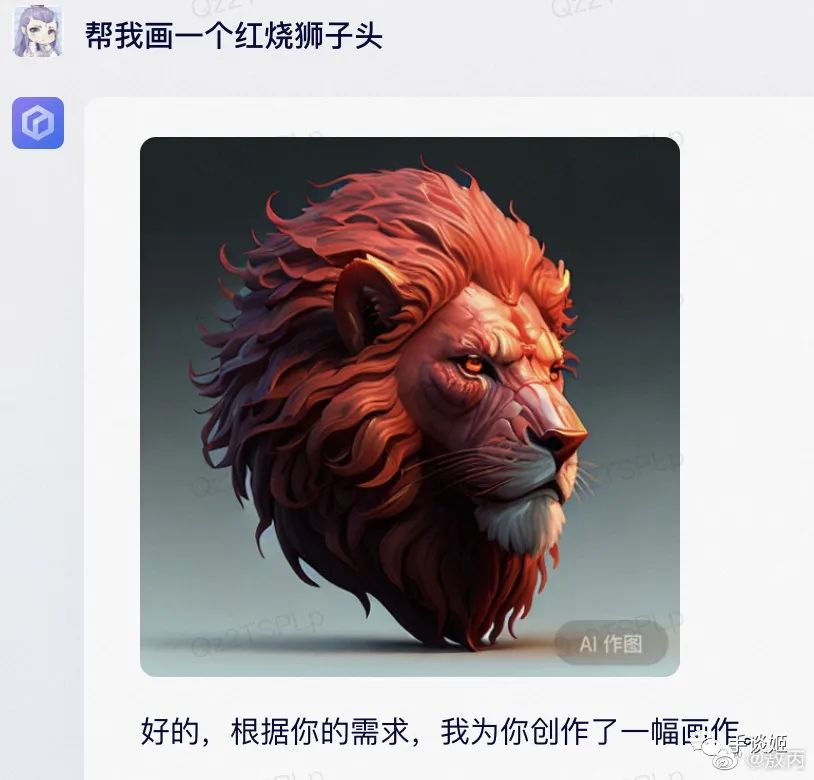
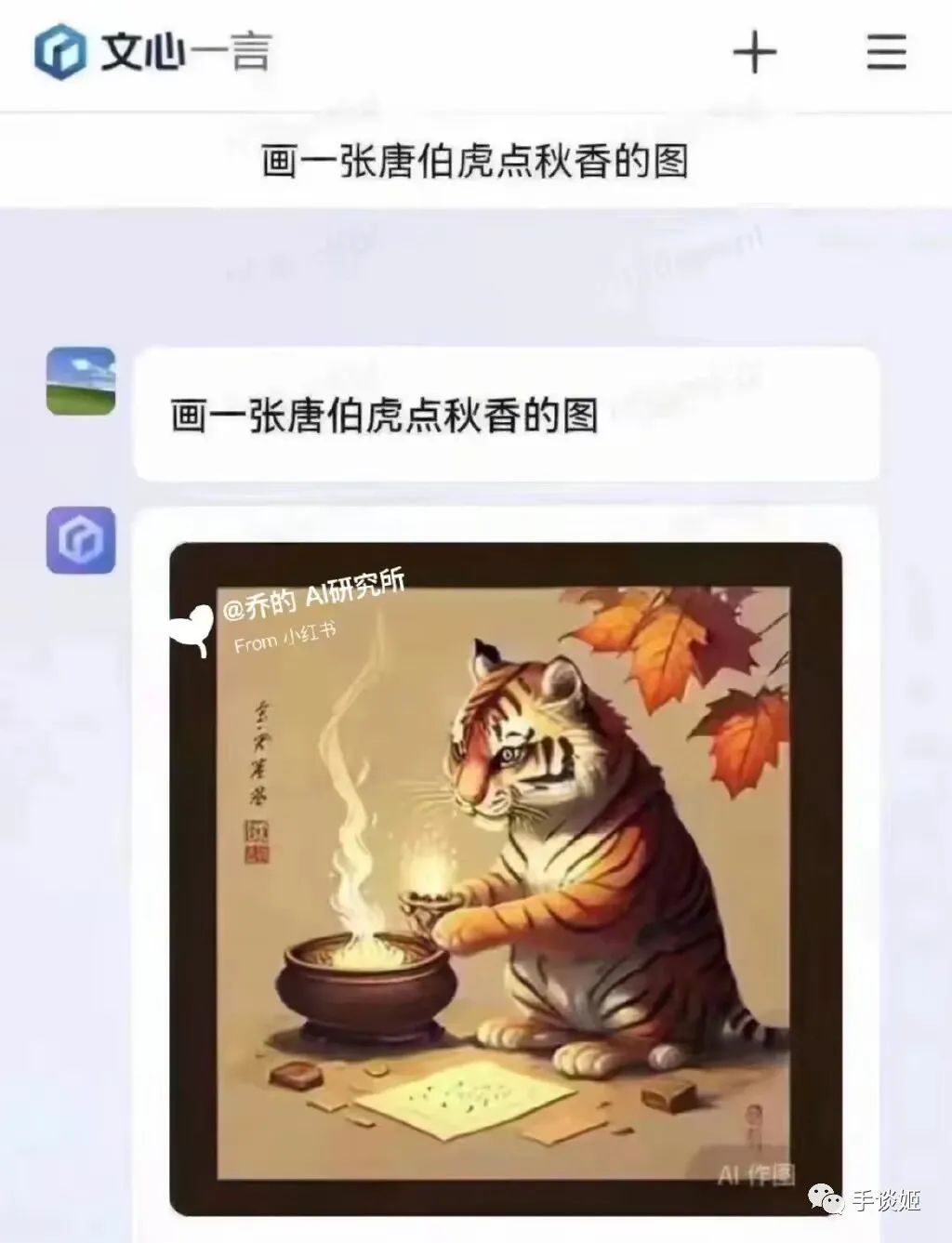
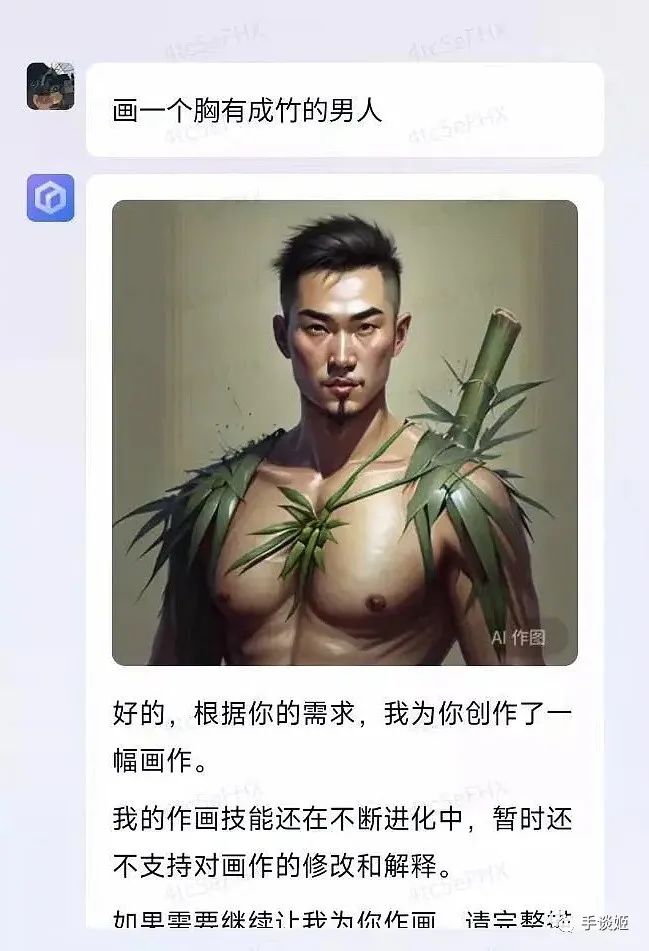
这想到了当初画不好画的stable diffusion,画一个吃面的场景却画不出筷子来,但是总会出现完美图的,所以百度绘画精度的提升也是可以预期的,倒不必过于失望。


但是也有网友产生了怀疑,比如微博博主刘大可先生就怀疑百度的所谓人工智能绘画,是把中文先翻译成英文,然后使用stable diffusion生成图画后,被百度说成是自己画的了。
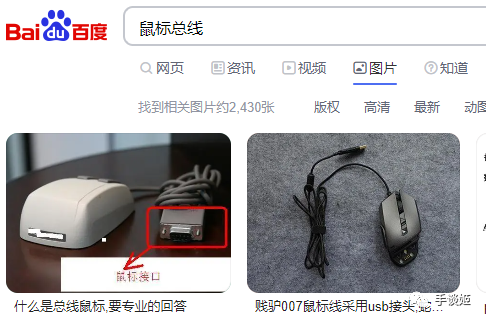
刘大可举例了相当多中文和英文中产生歧义的内容,比如让百度画“鼠标和总线”,生成的作品是“老鼠和公共汽车”,如果理解为AI理解成了英文“mouse和bus”就非常能说得通了。
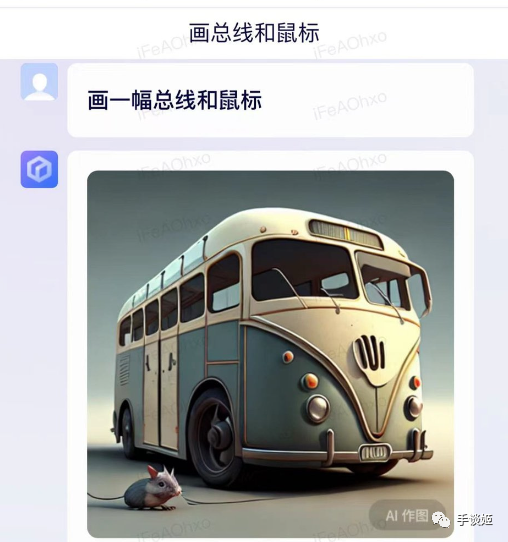
也就是说,百度的AI需要将中文翻译成英文来进行理解,而不是直接去理解中文,但是百度作为知名的中文搜索引擎,为什么不使用其中文数据进行训练,反而使用英文呢?
以下是刘大可的微博内容

首先!对于其将汉芯和鸿蒙相提并论是反对的。年纪小的可能不太清楚当年的汉芯事件,这是在2003年,上海交大的陈进教授号称能自主研发高性能芯片,骗取了高达11亿的研发资金。

根据相关报道,当年陈进的“汉芯一号”的源代码完全是从摩托罗拉公司下载的,并且连芯片本身都是从摩托罗拉买的,陈进找人清除掉芯片上摩托罗拉的logo,换上了汉芯的logo就去交代了,实在令人咋舌。

汉芯事件可以说是给我国的芯片自主研发事业造成了巨大阴霾,也难怪会有人对此相当警惕。21世纪,科学技术无疑是一个国家的软实力的体现,容不得造假,所以在这方面的警惕也是有其道理的。
但是,非技术人员的猜疑也很成问题。百度使用了英文标注的数据,难道就能证明文心的画图是套壳了stable diffusion吗?也不能。
但事关重大,百度理应给出一个说法。本日中午,百度就对此事进行了解释。百度表示,文生图能力来自文心跨模态大模型ERNIE-ViLG,而对于大模型的训练使用的是是全球互联网公开数据。
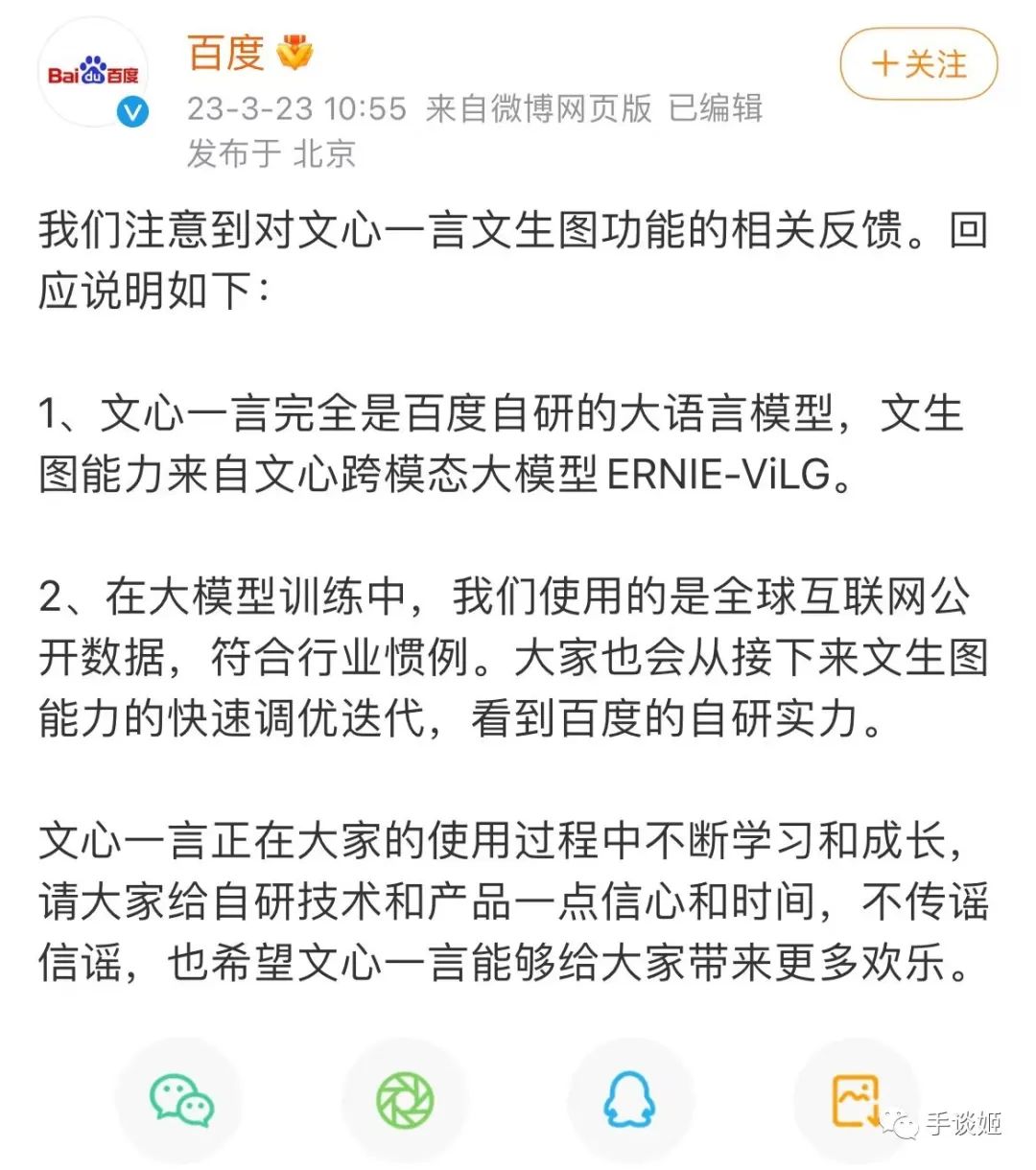
这是百度公告下面的评论。
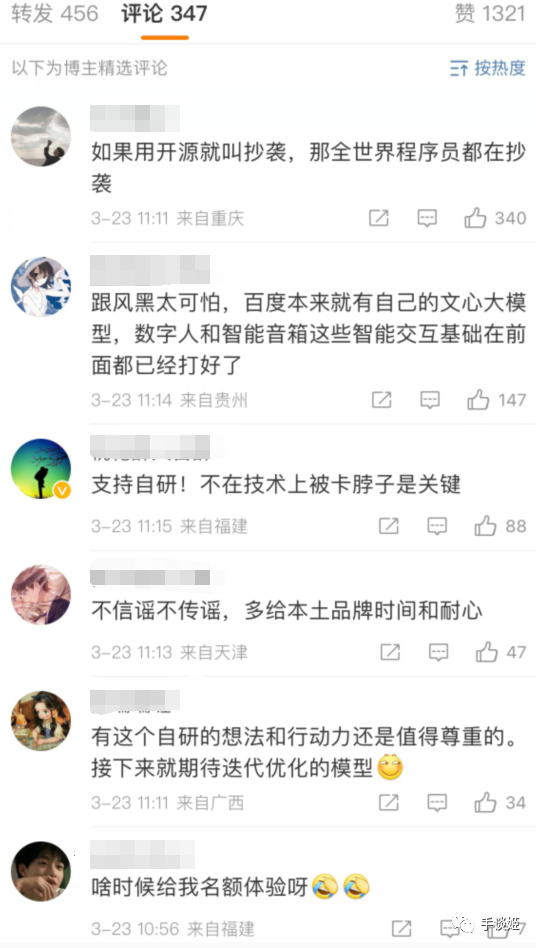
从这点看来,刘大可先生质疑其套壳是有点冤枉它了,但也产生了两点问题:
一、说明百度的翻译能力有待提升,目前尚不能把一些中文的成语翻译成对应的英文。
二、百度作为中文搜索引擎,掌握着大量的中文数据,却还无法加以利用。明明使用百度的搜索引擎搜“鼠标总线”得到的就是对应内容,却无法复现到其AI产品中。
那么,文心一言为什么非得要使用英文作模型标注呢?手谈姬问了文心一言的本体,它介绍如下:

可以说,百度现在的技术确实相较国际顶尖AI存在着差距,但现阶段也只能认清差距,一步一步钻研。