简介
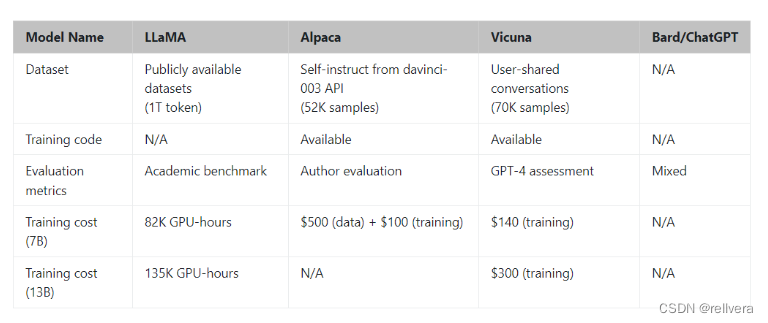
前段时间,斯坦福发布了Alpaca,是由Meta的LLaMA 7B微调而来,仅用了52k数据,性能可以与GPT-3.5匹敌。
FastChat集成了Vicuna、Koala、alpaca、llama等开源模型,其中Vicuna号称能够达到gpt-4的90%的质量,是开源的chatGPT模型中对答效果比较好的。
现在UC伯克利学者联手CMU、斯坦福等,再次推出一个全新模型70亿/130亿参数的Vicuna,俗称「小羊驼」(骆马)。小羊驼号称能达到GPT-4的90%性能,下面来体验一下。
项目地址:https://github.com/lm-sys/FastChat
体验地址:https://chat.lmsys.org/
部署
环境搭建
#官网要求Python版本要>= 3.8
conda create -n fastchat python=3.9
conda activate fastchat
#安装pytorch
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
安装后测试
conda activate fastchatimport torch
print(torch.__version__)
安装fastchat
pip3 install fschat
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
pip3 install --upgrade pip # enable PEP 660 support
pip3 install -e .
权重文件
这里由于经费有限,所以使用7B模型,7B大约 需要30 GB 的 CPU RAM
python3 -m fastchat.model.apply_delta \--base-model-path /path/to/llama-7b \--target-model-path /path/to/output/vicuna-7b \--delta-path lmsys/vicuna-7b-delta-v1.1
13B大约需要大约 60 GB 的 CPU RAM。执行方式如下
python3 -m fastchat.model.apply_delta \--base-model-path /path/to/llama-13b \--target-model-path /path/to/output/vicuna-13b \--delta-path lmsys/vicuna-13b-delta-v1.1
推理
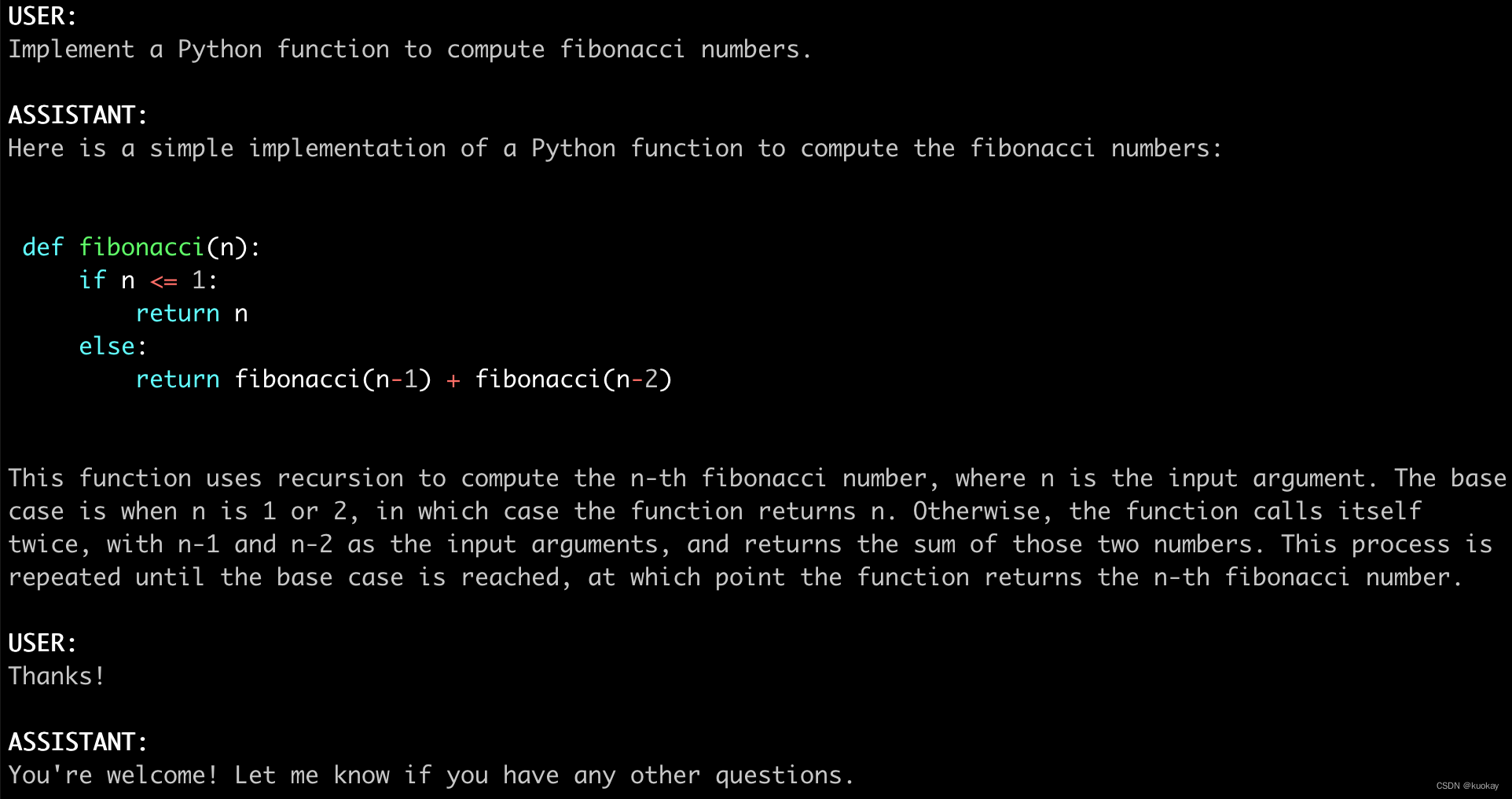
执行以下命令后,可以在命令行窗口进行对话
python3 -m fastchat.serve.cli --model-path lmsys/fastchat-t5-3b-v1.0
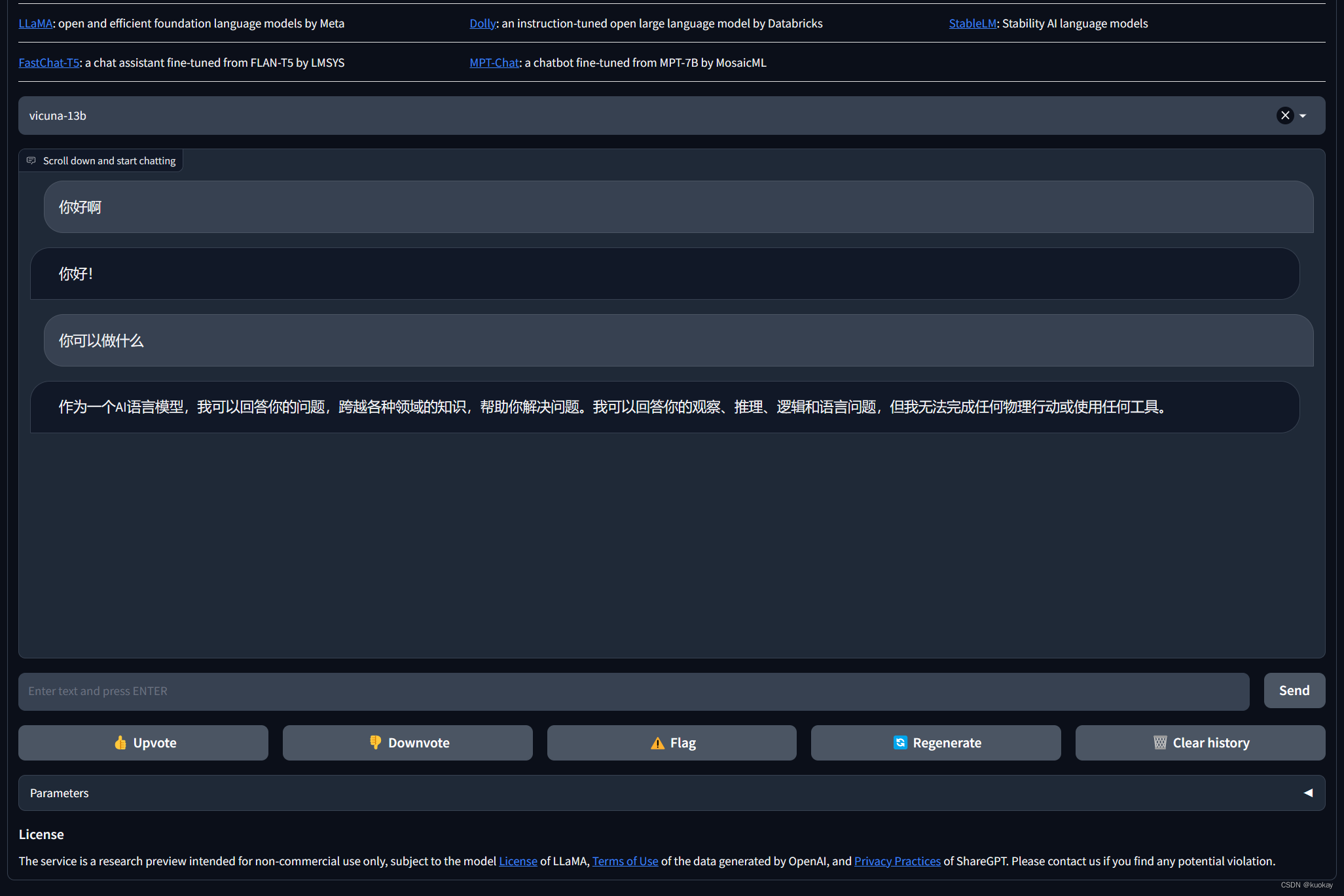
效果如下:
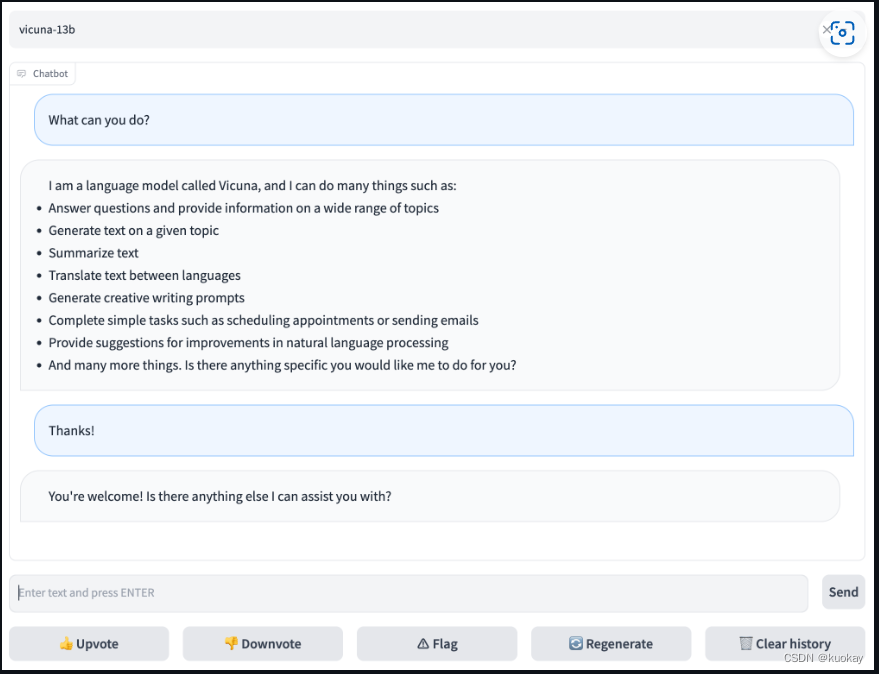
webGuI
FastChat还提供了web界面可以使用,具体流程如下
- 启动 controller
- 新开命令行,进入fastchat环境 执行 conda activate fastchat
- 然后执行命令 执行 python -m fastchat.serve.controller
- 启动 model worker
- 新开命令行,进入fastchat环境 执行 conda activate fastchat
- 执行命令 执行 python3 -m fastchat.serve.model_worker --model-path /path/to/model/weights
- 如果你显卡内存不够,需要使用CPU,在后面加上参数–device cpu
- 启动前可以测试一下
- 新开命令行,进入fastchat环境 执行 conda activate fastchat
- 然后执行 python -m fastchat.serve.test_message --model-name vicuna-7b
- 最后,启动 web server,执行 python -m fastchat.serve.gradio_web_server
- 打开浏览器,访问地址 http://127.0.0.1:7860/
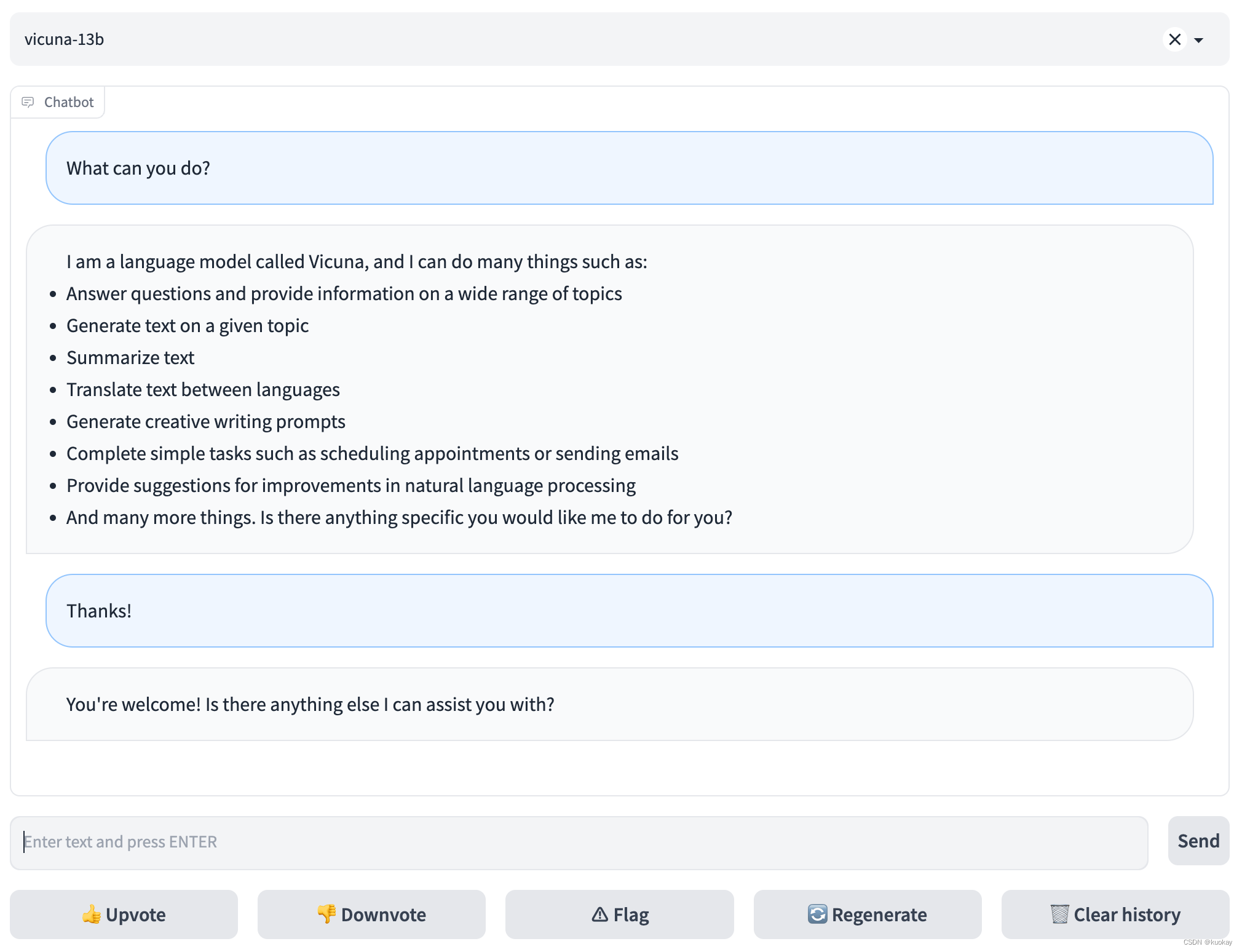
此外还提供了API调用方法,具体可以参考官网调用方法。






![[思维模式-13]:《复盘》-1- “知”篇 - 认识复盘](https://img-blog.csdnimg.cn/08f31da6b7904e6f9ee678d9c24c5f74.png)