大家好,我是微学AI,今天给大家讲一下人工智能的发展,从专家系统到机器学习再到深度学习,从大模型到现在的GPT4,讲这个的目的是让每个人都懂得人工智能,每个人都懂得人工智能的发展,未来人工智能是大方向,会贴近我们的生活,每个人都离不开它。
人工智能的发展
自20世纪40年代以来,人工智能(Artificial Intelligence, AI)就一直是计算机科学最有趣和最具挑战性的研究领域之一。起初是为了解决复杂问题而模拟人类智能思维,但随着技术的发展,人工智能已经广泛应用于图像识别、语音识别、自然语言处理、机器人等诸多领域。在这个漫长的发展历程中,数学知识在很大程度上成为了实现智能算法的基石。
早期的人工智能算法主要包括基于规则的专家系统、机器学习等。专家系统是一套通过硬编码问题解决方案的程序,通常用于解决特定问题。这种方法相对受限,不具备泛化能力,此外,通过人工设定规则的方式需要耗费大量时间、精力。而机器学习作为一个重要分支,从数据中提取知识,是推动人工智能发展的关键技术。这里涉及到的数学知识主要有线性代数、概率与统计、优化等。
初代的人工神经网络(ANN),是基于大脑神经元的结构和功能搭建的简单模型,通过输入层、输出层以及若干隐藏层以实现各种功能。在这里,我们用到了矩阵计算、激活函数、模型参数更新等多种数学工具。
机器学习中重要的模型:支持向量机(SVM),他是一类常用的监督学习算法,它旨在找到一个最优超平面将样本正确分类,主要思想是最大化类别间距离。SVM算法中涉及诸如向量空间(VSM)、凸优化(与拉格朗日对偶、KKT条件相关)等多种数学原理。支持向量机广泛应用于图像识别、文本分类等领域。
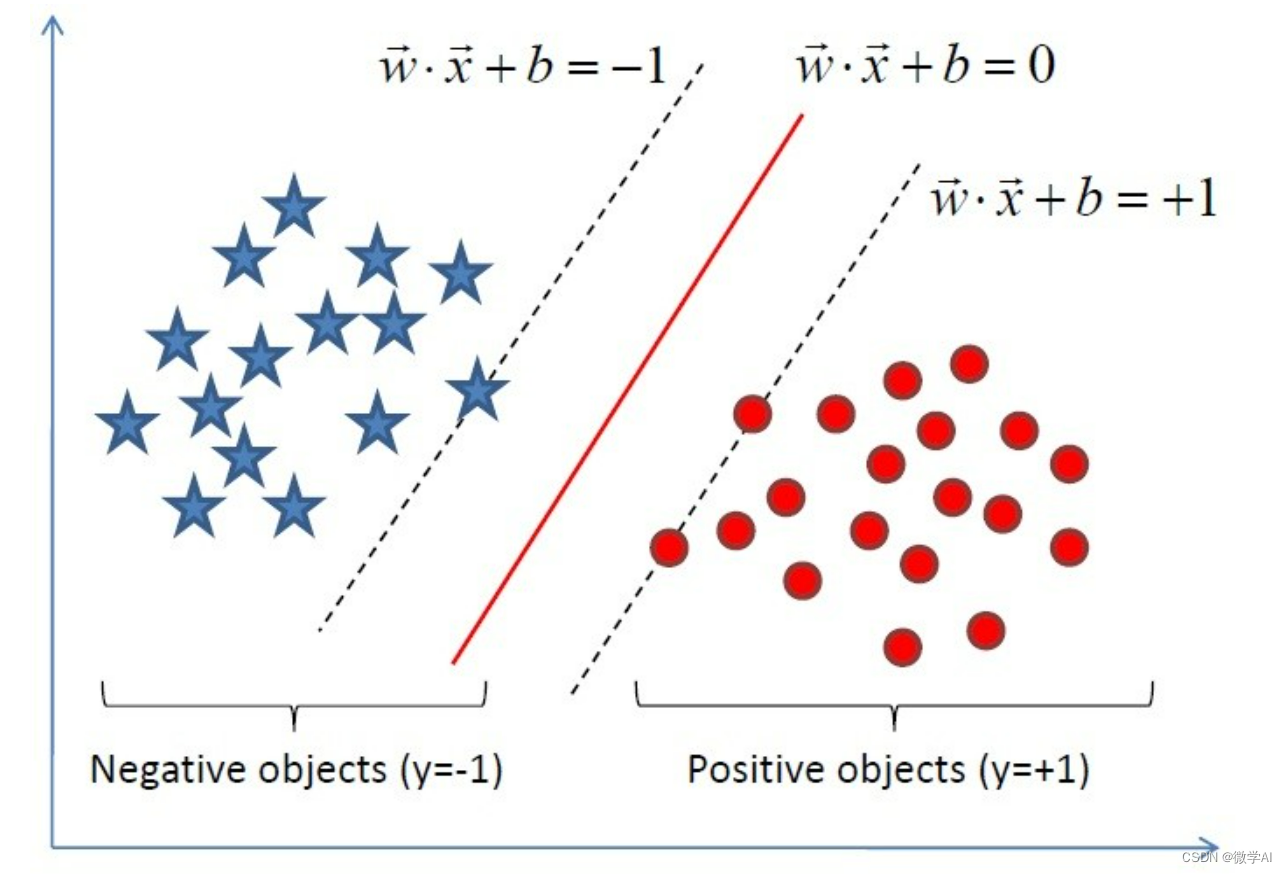
后面研究人员发现,通过随机森林(Random Forests)等多个弱分类器的组合,能提高模型的准确性。这一发现促成了集成学习(Ensemble Learning)的诞生,其中包括Bagging、Boosting等策略,涉及的数学知识有投票原则、模型误差计算等。
随着研究的深入,神经网络模型得到了拓展,产生了卷积神经网络(CNN)、循环神经网络(RNN)等。卷积神经网络是用于解决图像分类等问题的一种有效算法,它利用卷积操作在局部区域内提取特征,降低维度。RNN由于在时间序列数据处理上的优势,被广泛应用于自然语言处理、语音识别等场景。
深度学习(Deep Learning)则是基于多层神经网络模型发展而来,模型有着更深的层数、更复杂的结构。深度学习通过优化算法以自动学习深层次的信息表达和特征。但随之而来的问题是梯度消失和梯度爆炸。为了解决这一难题,引入了梯度裁剪、权值正则化等技术。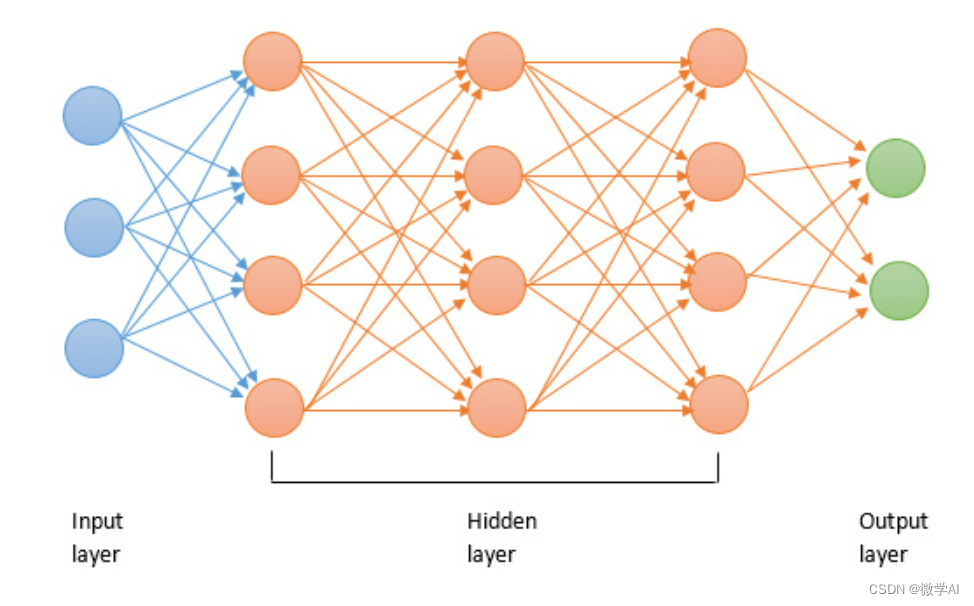
另一方面,LSTM(长短时记忆网络)是一种为解决长序列问题所设计的循环神经网络结构。它引入了一种叫做“门”的结构来控制信息在不同时间步的流动。该网络在自然语言处理、语音识别等领域取得了巨大成功。
BERT(Bidirectional Encoder Representations from Transformers)是一种基于 Transformer 架构的预训练模型,通过大量语料数据预训练得到了丰富的词向量表示。Transformer 架构是一种自注意力机制(self-attention)构建的深层网络结构,用于解决序列数据的问题。BERT 提供了一个强大的预训练模型,可以通过微调应用于各种自然语言处理任务,如问答、机器翻译等。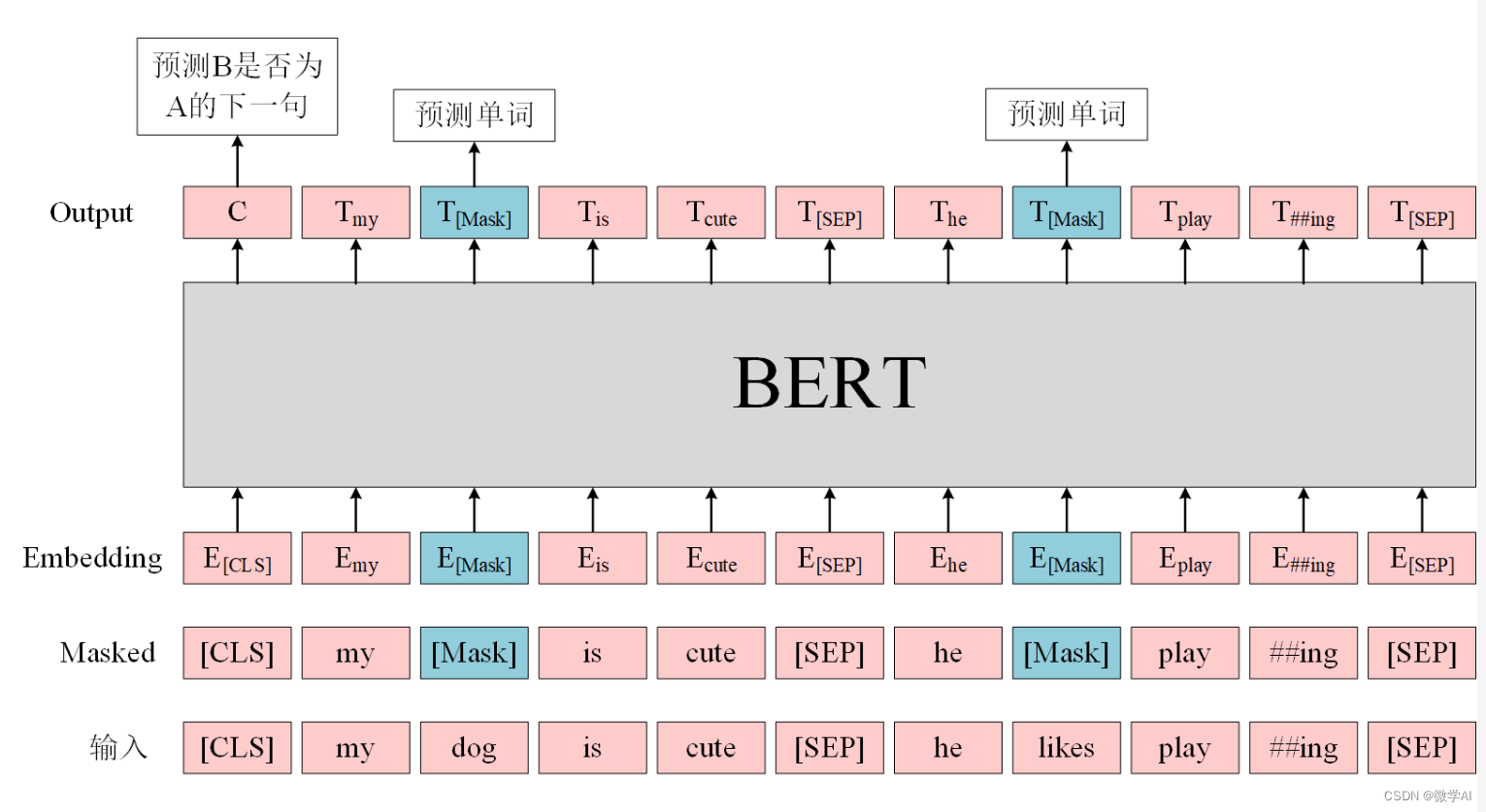
生成式预训练模型 (GPT) 则是一种基于 Transformer 架构的自回归模型,通过调整模型参数使生成结果最小化预定义代价函数。GPT 的一个重要特点是可以生成自然的文本,最初的 GPT 只能生成相对简短的文本,随着模型发展,GPT-2 可以生成更加流畅、丰富的文本。进一步发展的 GPT-3 已经具备强大的预训练模型,可以生成更长、更精确的文本,甚至用于编程、学术论文写作等领域。 GPT的发展历程
GPT的发展历程
GPT-1: 发表于 2018 年,在迭代过程中加入了 softmax 层,实现了有趣的生成任务,如创作歌词和文章。但受限于模型参数,效果并不理想。
GPT-2: 发表于 2019 年,以 1.54 亿参数量为特点,已实现生成高质量文本,但可能出现信息偏差,甚至有安全隐患。
GPT-3: 发表于 2020 年,参数量高达 1750 亿,但计算成本极高,影响了模型的应用。
ChatGPT: 发表于 2022 年11月,ChatGPT是一种基于GPT模型的AI聊天机器人,可以用于各种任务,包括文本生成、问答和对话系统等。用户可以输入问题或对话内容,并通过ChatGPT获得回复。
GPT-4: 发表于 2023年3月,GPT-4在参数量上达到了100万亿个参数、生成能力、计算性能以及安全方面有更进一步的提升,支持多模态的输入,可以读懂图片信息,功能更加强大。
从专家系统到深度学习,再到 GPT 系列模型的发展中,我们目睹了一系列令人惊叹的技术进步。在这个过程中,数学知识包括线性代数、概率统计、优化等方向发挥了巨大作用。未来,我们有理由相信,GPT-4 及其他先进人工智能模型将为我们的生活带来更多便捷、美好的改变。但与此同时,伴随着这些技术的普及和应用,也面临着更多的挑战与问题,例如数据安全、隐私保护、算法歧视等。

人工智能数据安全性
在数据安全方面,GPT-4 及其他自然语言处理模型的训练过程需要大量的样本数据作为输入。然而,在现实应用场景中,数据来源可能存在安全风险。诸如窃取、篡改数据等行为可能导致模型训练出现偏差,甚至被用于恶意攻击。因此,加强数据安全意识,建立严格监管制度,确保训练数据的合法性、合规性以及有效性,是未来应对挑战的重要方向。
在隐私保护方面,随着人工智能技术在诸如金融、医疗等领域的应用,涉及大量个人隐私数据(如身份证号、住址、病例等)。然而,过度依赖这些信息作为训练数据,可能导致个人隐私被泄露、滥用。未来,可以借鉴差分隐私(Differential Privacy)、同态加密等技术,实现在保护个人隐私的前提下,实现对数据的有效处理和利用。
在算法歧视方面,由于训练数据中可能包含有潜在偏见,导致算法结果对特定人群或企业产生歧视。为了解决这个问题,研究人员可以在训练数据预处理阶段剔除掉与歧视相关的信息,或者在模型验证阶段采用公平性评估(Fairness Evaluation)等方法检测模型是否存有歧视行为,并进行针对性的调整和优化。
在模型的可解释性方面,由于模型参数和网络结构越来越复杂,其预测过程变得难以理解,甚至被称为“黑盒子”。未来,研究人员可以从改善模型结构、选择更适合解释的参数,提高模型的解释性能。此外,可视化技术也可以在很大程度上帮助用户直观地理解模型预测的机理。
人工智能的未来
从专家系统发展到GPT-4模型等人工智能技术的演进,展现了计算机科学和数学领域无穷尽的创新能力。面临诸多挑战,我们需要依靠科研人员的努力与合作,找到关键解决方案,确保人工智能在各行各业得到健康、可持续的发展。同时,我们也相信,在不远的将来,人工智能技术将会为我们的生活带来更大的便利和价值,而我们也将拥有更智慧、更高效的未来世界。















![全网多种方式解决The requested resource [/] is not available的错误](https://img-blog.csdnimg.cn/32f638ced4f74da29fb5177a304cd320.png)