机器学习的基本步骤:
前馈运算、反向传播计算梯度、根据梯度更新参数值。
一、定义及基本概念
深度学习,就是一种利用深度人工神经网络来进行自动分类、预测和学习的技术。它可以从海量的数据中自动学习,找寻数据中的特征。所以说,它的本质就是自动提取特征的能力。
可以说,深度学习就等于深度人工神经网络。
一般认为超过三层的神经网络就可以叫做深度神经网络。
深度学习属于一种特殊的人工智能技术。
反向传播算法:
此算法是人工神经网络中的关键性技术。它可以精确地调整人工神经网络出现问题的部件,从而快速降低网络进行分类或预测的错误率。因此,反向传播算法是人工神经网络的核心。
在应用层面,深度学习的最大特点是能处理各种非结构化数据,如文本、图片、音频、视频等。
一般的机器学习更适合处理结构化数据。
结构化数据:可以用关系型数据库进行存储、管理和访问的数据。
影响深度学习的3个因素:大数据、深度网络架构(算法)和GPU(算力)。
二、深度网络架构
人工神经网络
也被称为通用拟合器,因为可以拟合任意的函数或映射。它是一种受人脑的生物神经网络启发而设计的计算模型,非常擅长从输入数据和标签中学习映射关系,从而完成预测或者分类问题。
它类似于生物神经网络,由人工神经元构成。每个神经元则由简单的数学模型来模拟生物神经细胞的信号传递与激活。
通用逼近定理Universal Approximation Theorem:
用有限多的隐含神经元可以逼近任意的有限区间内的曲线。
深度网络架构
就是整个网络体系的构建方式和拓扑连接结构,主要有3种:前馈神经网络、卷积神经网络和循环神经网络。
1、前馈神经网络
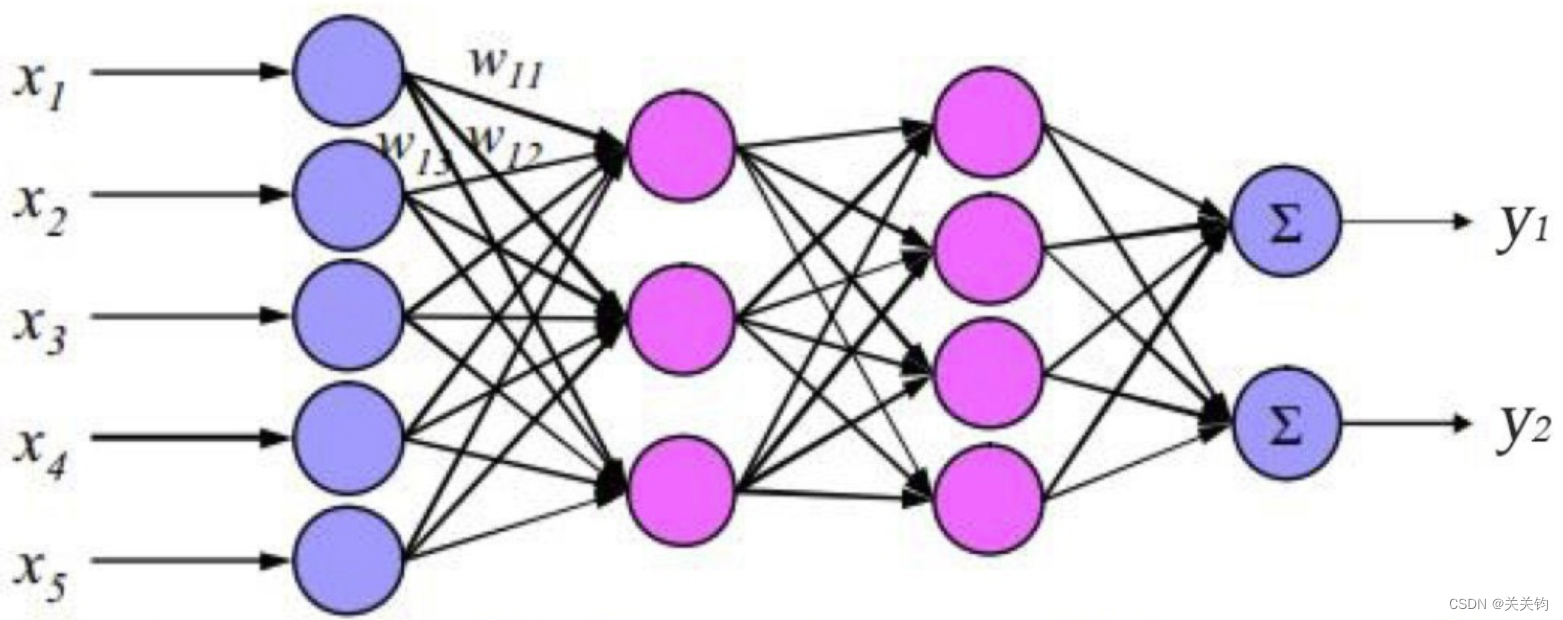
也叫全连接网络fully connected neural network,是目前最常用的一类神经网络。在这种结构中,所有的节点都可以分为一层一层的,每个节点只跟它的相邻层节点而且是全部的节点相连接。
这些层一般分为输入层、输出层,以及介于两者之间的隐含层。
隐含层可以包含多层,这样就构成了深度神经网络。
隐含层的神经元个数根据我们对数据复杂度的预估决定,通常,数据越复杂,数据量越大,需要的神经元就越多。但是,神经元过多也容易造成过拟合。
神经网络的运行通常包括前馈的预测过程(或叫决策过程)和反馈的学习过程。
前馈的预测过程:
- 信号从输入神经元进入,沿着网络连边传输,每个信号都会与连边上的权重w相乘,得到隐含神经元的输入;
- 接着,隐含神经元对所有连边输入的信号进行汇总求和,经过一定地处理后输出;
- 这些输出的信号再与从隐含层到输出层的那组连线上的权重相乘,这样就得到了输入给输出神经元的信号;
- 然后,输出神经元对每一条输入连边的信号进行汇总,加工处理后输出。
- 最后的输出就是整个神经网络的输出。
神经网络再训练阶段会调整每条连边上的权重w的数值。
反馈的学习过程:
- 首先,每个输出神经元会计算出它的预测误差;
- 然后,将这个误差沿着神经网络的所有连边进行反向传播,这样就能得到每个隐含层神经元的误差;
- 最后,根据每条连边所连接的两个神经元的误差重新计算出连边上的权重数值,从而完成神经网络的学习与调整。
前馈(feedforward)是指网络的传播方向是单向的。具体地说,先将输入信号传给下一层(隐含层),接收到信号的层也同样传给下一层,然后再传给下一层⋯像这样,信号仅在一个方向上传播,最后直到输出层。
虽然前馈网络结构简单、易于理解,但是可以应用于许多任务中。不过,这种网络存在一个大问题,就是不能很好地处理时间序列数据(以下简称为〝时序数据”)。更确切地说,单纯的前馈网络无法充分学习时序数据的性质(模式)。
于是,循环神经网络便应运而生。
2、卷积神经网络
一般用于处理数字图像。它可以使原始图像即使经历平移、缩放等变换后仍然具有很高的可识别性。因此,它被广泛应用于计算机视觉、图像识别、图像生成等领域。(深度学习——卷积神经网络(CNN)简介_cnn深度神经网络_南方惆怅客的博客-CSDN博客![]() https://blog.csdn.net/johnny_love_1968/article/details/117636049?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168308183316800184167936%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168308183316800184167936&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-4-117636049-null-null.142%5Ev86%5Einsert_down1,239%5Ev2%5Einsert_chatgpt&utm_term=%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&spm=1018.2226.3001.4187
https://blog.csdn.net/johnny_love_1968/article/details/117636049?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168308183316800184167936%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168308183316800184167936&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-4-117636049-null-null.142%5Ev86%5Einsert_down1,239%5Ev2%5Einsert_chatgpt&utm_term=%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C&spm=1018.2226.3001.4187
3、循环神经网络
RNN:Recrurrent Neural Network
它的网络结构和前馈神经网络很相似,但RNN的隐含层彼此之间有连接。
RNN的这种架构使得网络当前的运行不仅跟当前的输入数据有关,还与之前的数据有关。所以,RNN适合处理语言、音乐、股票曲线等时间序列类型的数据,它被广泛地应用于自然语言处理。RNN网络的循环结构可以应付输入序列中存在的长程记忆性和周期性。
训练方式也会影响深度网络的学习:
- 如果我们将少量有特定标签的数据输入网络,然后拿剩下的数据去训练它,就会比一股脑儿地把所有标签的数据都输入给它要更加有效,这种方式可以提高深度网络的“学习”能力,让其像人类一样学习。
- 还可以通过迁移学习将训练好的神经网络迁移到新的小数据集中,从而提高其学习能力。
三、GPU加速神经网络训练
图形处理单元Graphics Processing Unit。和CPU一样是做计算的基本单元,只不过GPU是嵌在显卡上的,CPU是嵌在主机主板上的。
GPU可以帮助深度神经网络的计算加速,因为GPU非常擅长于大规模的张量(高阶矩阵)运算,并且为这种运算加速,包含多个数值的张量运算所需要的平均时间远少于对每个数字运算的时间。
最开始,GPU的发明是为3D电子游戏的3D图像渲染,因为3D图像渲染需要进行大规模的矩阵运算,GPU可以使这种运算并行化,让计算机图形渲染的画面更流畅和光滑。
后来,人们发现深度神经网络的训练运算过程可以全部转化为高阶矩阵(一般叫张量)的运算过程,所以GPU的矩阵运算并行化可以加速神经网络的训练。
四、特征学习
Feature Learning。
把不同的信息表达到不同层次的网络单元(权重)之中,并且这一过程不需要手动干预,全靠机器学习自动完成。
五、迁移学习
Transfer Learning
把一个训练好的神经网络迁移并拼接到另一个神经网络上,然后用前面部分的神经网络进行特征提取,再将这个特征提取器与后面的神经网络进行拼接,后面部分的神经网络会根据这些特征进行分类或者预测,去解决另一个完全不同的问题。
特征提取和迁移学习,使我们能够实现各种端到端(end to end)式的学习。即是可以直接输入原始数据,让深度网络输出最终的结果即可。之余中间的处理环节,我们都不关心,因为整个深度网络会自动学习到一种最优的模式,从而使模型可以精确地输出预测值。
这种端到端的学习方式有个优点:它可以通过不断吸收大量数据而表现得越来越专业,甚至在训练神经网络的过程中不需要所解决问题的领域知识。
六、深度学习取得成功的原因
- 深度神经网络可以自动学习特征,避免了大量的人工工作,使得端到端的机器学习成为可能;
- 可以对深度神经网络实施类似于脑外科手术的迁移和拼接,这不仅实现了利用小数据完成高精度的机器学习,也让我们的深度神经网络能够像软件模块一样拼接和组装。
七、深度学习术语
1、模型
对数据预测原理的基本假设。
2、拟合
将模型应用到训练数据上,并试图达到最佳匹配的过程。
欠拟合
模型没有很好地捕捉到数据特征,不能很好地拟合数据。即高偏差,低方差。
过拟合overfitting
模型可以在训练数据上进行非常好的预测,但在全新的测试数据上表现不行。
模型把数据学习得太彻底,以至于把噪声数据的特征也学习到了,这样会导致在后期测试的时候不能很好地识别数据,即不能正确地分类,模型泛化能力太差。即低偏差,高方差。
泛化能力
机器学习的目标是使学得的模型能够很好地适用于新的样本,而不是仅仅在训练样本上工作得很好,学得的模型适用于新样本的能力称为泛化能力。
3、特征变量
特征变量构成了模型的自变量集合,然后根据数据中的这些特征变量来进行预测。
4、目标标量
是模型去拟合的目标。
5、参数
通过调整参数来改善拟合效果,参数越多,往往拟合得越准,但是也容易引起过拟合现象。
6、损失函数
衡量模型质量的损失函数,用平均误差、交叉熵或者似然函数,它通常是目标变量和模型预测值的函数,然后根据损失函数来优化模型,求出最优参数组合。
7、训练
反复不停调整模型中参数的过程
8、测试
检验已经训练好的模型的过程。
9、样本
每一个数据点就叫做一个样本
10、训练集
用于训练模型的数据集合
11、测试集
用于检验模型的数据集合
12、梯度下降算法
根据梯度信息更新参数的算法,简单且有效。
13、训练迭代
反复利用梯度下降算法的循环过程。
14、超参数
对于一个神经网络,网络每层的神经元个数就是超参数。超参数与参数的区别是参数会在训练中调节,而超参数不会。
15、变量
类型变量:这个变量可以在不同的类别中取值,比如星期这个变量,取值是1,2,3,4,5,6,0。它的大小没有任何翻译,只是为了区分不同的类型而已。
数值变量:这类变量会从一个数值区间连续取值,比如湿度、温度、风速。
数值类型的变量是每个变量的变化范围都不一样,单位也不一样,所以,不同的变量不能比较。解决方法是对此类变量进行标准化处理,也就是用变量的均值和标准差来对该变量做标准化,从而把特征数值的平均值变为0,标准差变为1.
16、批处理
当数据量过多的时候,采用批处理batch processing的模式,就是将所有的数据划分为一个批次大小batch size的小数据集,然后在每个训练周期给神经网络输入一批数据。批次的大小按照问题的复杂度和数据量的大小而定。
八、神经网络的学习训练与运行
只要调节神经网络中各个参数的组合,就能得到想要的任何曲线。而这些参数是通过训练得来的。
要想完成神经网络的训练,首先要给这个神经网络定义一个损失函数,用它来衡量神经网络在现有的参数组合下输出的表现如何。
神经网络要学习的就是神经元之间的连边上的权重和偏置,而学习的目的就是得到一组能够使神经网络总误差(损失函数)最小的参数值组合。
降低总误差其实是一个求极值的优化问题,用高等数学里的方式就是求导,让导数等于零就行。但是实际中的神经网络包含了大量的非线性运算,无法直接用求导数的方式。
因此,采用梯度下降算法来求解。此算法的每次迭代都向梯度的负方向前进,使误差值逐步减小。
参数的更新则需要用到反向传播算法,将损失函数沿着神经网络一层一层地反向传播,来修正每一层的参数。
PyTorch中的反向传播算法就是函数backward(),只要执行该命令,PyTorch就会自动执行反向传播算法,计算出每一个参数的梯度,然后根据这些梯度信息更新参数即可,这样就完成了一个学习过程。
神经网络的学习和运行是交替进行的。 即,在每一个周期内,神经网络都会进行前馈运算,从输入端到输出端,然后根据输出端的损失值(误差值)来进行反向传播算法,从而调整更新神经网络上的各个参数。只要不停地重复,就可以让神经网络学习得越来越好。
语言模型:language model
语言模型 给出了单词序列发生的概率。具体来说,就是使用概率来评估一个单词序列发生的可能性,即在多大程度上是自然的单词序列。比如,对于“you say goodbye” 这一单词序列,语言模型给出高概率(比如 0.092):对于“you say good die' 这一单词序列,模型则给出低概率(比如 0.000 000 000 0032 )。
语言模型可以应用于多种应用,典型的例子有机器翻译和语音识别。比如,语音识別系统会根据人的发言生成多个句子作为候选。此时,使用语言模型,可以按照〝作为句子是否自然〞这一基淮对候选句子进行排序。
语言模型也可以用于生成新的句子。因为语言模型可以使用概率来评价单词序列的自然程度,所以它可以根据这一概率分布造出(采样)单词。