🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
实验背景
实验目的
实验环境
实验过程
1.加载数据
2.训练模型
3.模型评估
源代码
文末福利
实验背景
脑肿瘤是一种严重的疾病,对患者的生命和健康造成了威胁。在脑肿瘤的治疗过程中,准确地识别和分类不同类型的脑肿瘤对于制定个性化的治疗方案和预测患者的病情发展非常重要。
传统的脑肿瘤分类方法通常依赖于医学专家对影像学图像的视觉解读和分析,但这种方法受限于主观性、经验依赖性和人力成本较高等问题。随着深度学习技术的快速发展,特别是在计算机视觉领域的应用,基于深度学习的脑肿瘤图片识别分类成为了一种有潜力的解决方案。深度学习模型,尤其是卷积神经网络(Convolutional Neural Networks,简称CNN),具备从大规模数据中自动学习特征和进行高度抽象的能力。这使得它们在图像分类和分割任务中具有出色的表现。通过使用深度学习方法,可以将医学影像图像作为输入,训练一个分类器来自动识别和分类不同类型的脑肿瘤,从而为医生提供辅助诊断和治疗决策的依据。基于深度学习的脑肿瘤图片识别分类实验具有重要的研究意义和应用前景。通过该实验,可以评估深度学习模型在脑肿瘤分类任务中的准确性、鲁棒性和可解释性。同时,还可以探索不同深度学习架构、数据增强技术和迁移学习方法对脑肿瘤分类性能的影响。这些研究成果有望为脑肿瘤的早期检测、治疗规划和病情预测提供有力的支持,提高医疗诊断的精确性和效率,最终改善患者的治疗结果和生存率。
实验目的
本实验旨在利用深度学习方法,特别是卷积神经网络(CNN),进行脑肿瘤图片的识别和分类,以实现以下目标:
1.提高脑肿瘤识别的准确性:通过训练深度学习模型,使其能够准确地识别不同类型的脑肿瘤,包括恶性和良性肿瘤。通过提高准确性,可以辅助医生进行更精确的诊断和制定个性化的治疗方案。
2.探索深度学习模型的鲁棒性:在面对不同的脑肿瘤图像数据集时,评估深度学习模型的鲁棒性和泛化能力。通过研究模型的鲁棒性,可以提高在实际应用中的可靠性,并应对不同来源、不同质量和不同噪声水平的脑肿瘤图像数据。
3.比较不同深度学习架构的性能:尝试使用不同的深度学习架构,如常见的卷积神经网络(CNN)模型和一些最新的架构,比较它们在脑肿瘤分类任务上的性能和效果。通过对比不同模型的表现,可以确定最适合该任务的模型架构,为后续的研究和应用提供参考。
4.评估深度学习模型在临床实践中的应用价值:将深度学习模型应用到真实世界的脑肿瘤影像数据中,并与传统的医学影像诊断方法进行对比。通过评估深度学习模型在临床实践中的准确性和效率,可以为医生提供辅助诊断的工具,并改善脑肿瘤患者的治疗结果和预后。
实验环境
Python3.9
Jupyter notebook
实验过程
1.加载数据
首先导入本次实验用到的第三方库

定义数据集的路径

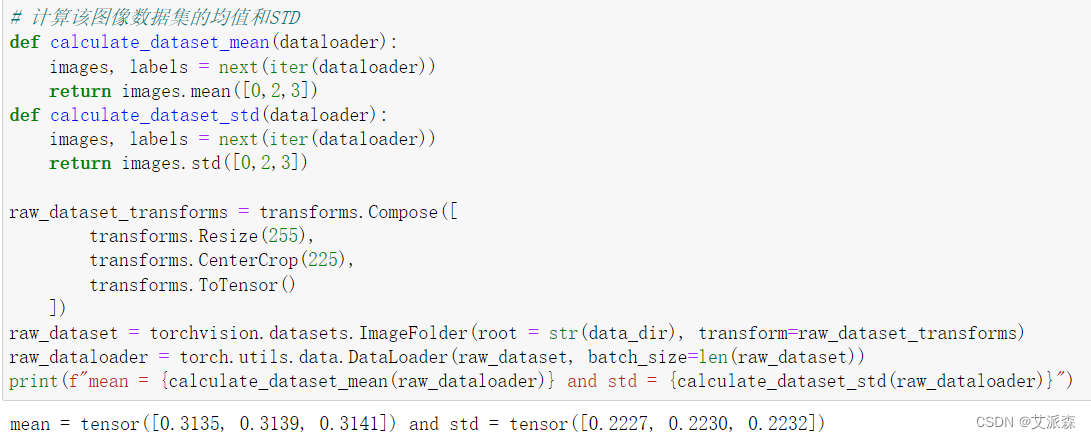
计算该图像数据集的均值和STD
创建数据加载器,为训练和验证数据集组合转换
使用采样器在训练和验证之间分割数据

配置数据集定义加载器
将数据进行展示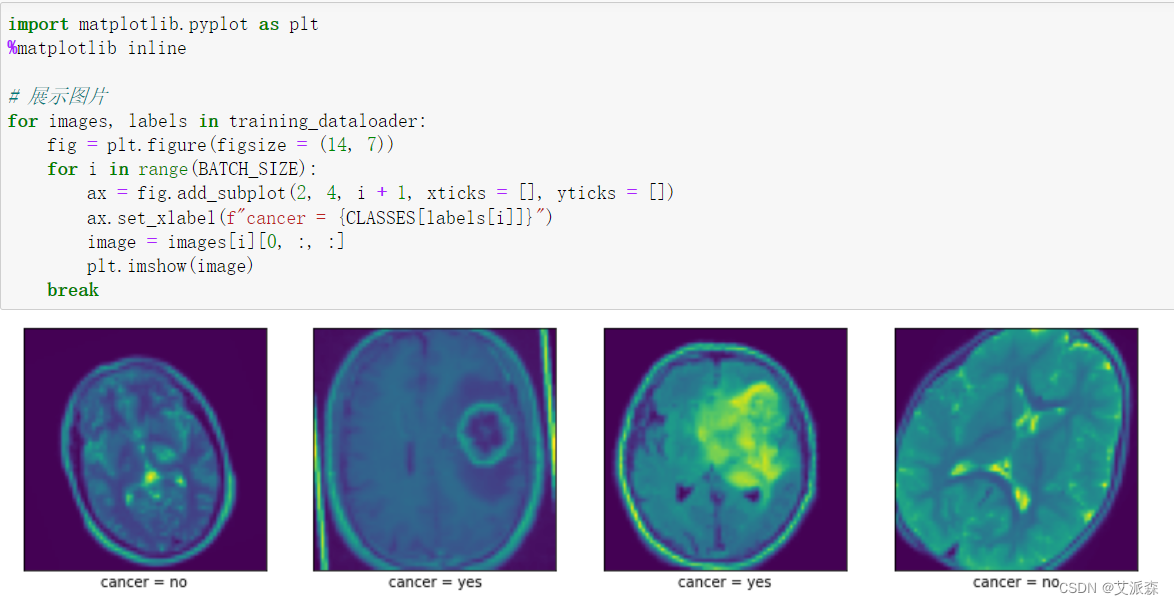
2.训练模型
训练模型配置,初始化模型

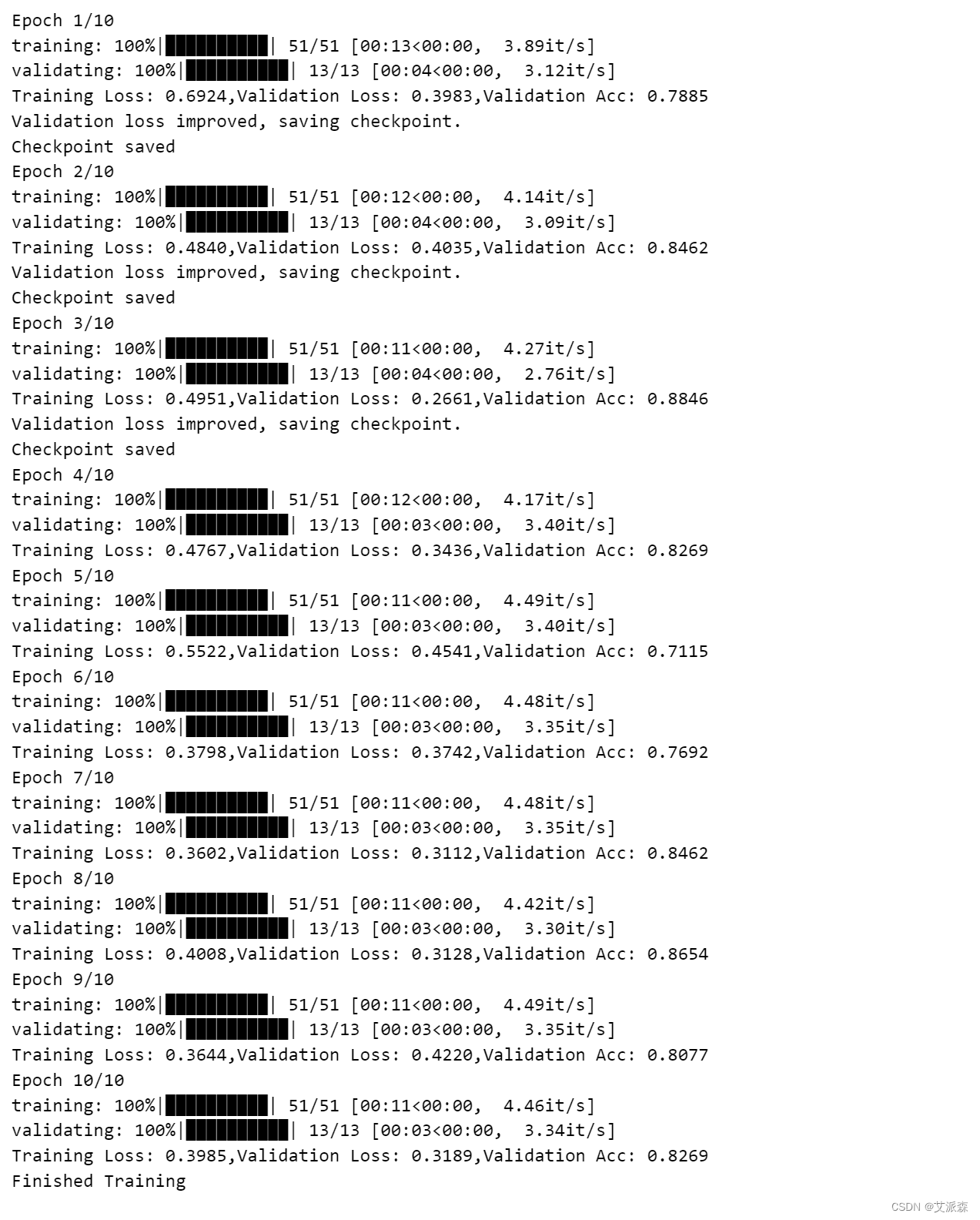
开始训练模型
3.模型评估
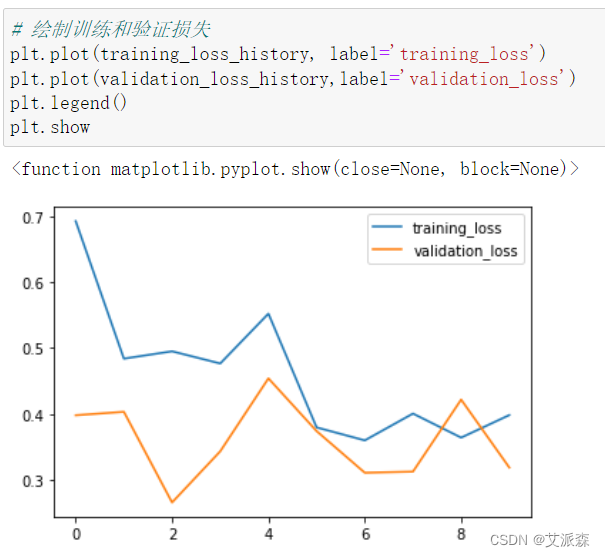
绘制训练和验证损失
绘制验证精度图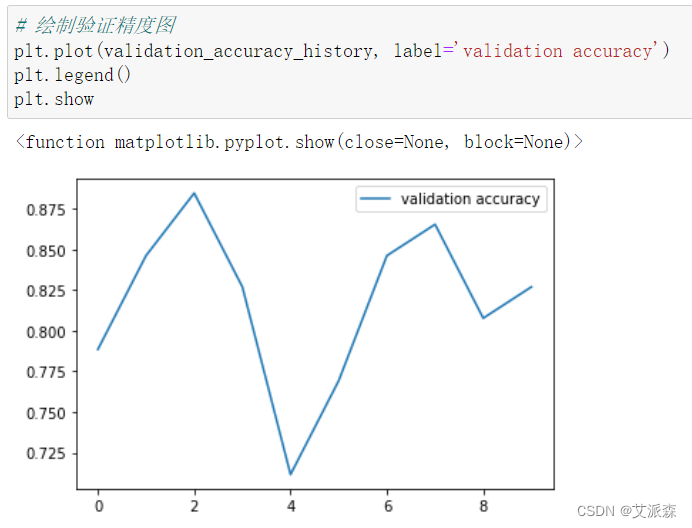
源代码
import numpy as np
from pathlib import Path
import random
import torch
import torchvision
from torchvision import transforms
import tqdm
data_dir = Path("./brain_tumor_dataset")
list(data_dir.iterdir())
# 计算该图像数据集的均值和STD
def calculate_dataset_mean(dataloader): images, labels = next(iter(dataloader))return images.mean([0,2,3])
def calculate_dataset_std(dataloader):images, labels = next(iter(dataloader))return images.std([0,2,3])raw_dataset_transforms = transforms.Compose([transforms.Resize(255), transforms.CenterCrop(225), transforms.ToTensor()])
raw_dataset = torchvision.datasets.ImageFolder(root = str(data_dir), transform=raw_dataset_transforms)
raw_dataloader = torch.utils.data.DataLoader(raw_dataset, batch_size=len(raw_dataset))
print(f"mean = {calculate_dataset_mean(raw_dataloader)} and std = {calculate_dataset_std(raw_dataloader)}")
'''
创建数据加载器
为训练和验证数据集组合转换
创建应用了适当转换的数据集
使用数据集创建数据加载程序
'''
# 数据集配置
CLASSES = ["no","yes"]
NUMBER_OF_CLASSES = len(CLASSES)
SHUFFLE = True
VALIDATION_SIZE = 0.2
RESIZE = 64
# 为训练和验证数据集组合图像转换
normalize = transforms.Normalize(mean=calculate_dataset_mean(raw_dataloader),std=calculate_dataset_std(raw_dataloader),)
training_transform = transforms.Compose([transforms.RandomRotation(30),transforms.Resize(RESIZE),transforms.CenterCrop(RESIZE),transforms.RandomHorizontalFlip(),transforms.ToTensor(),normalize,
] )
validation_transform = transforms.Compose([transforms.Resize(RESIZE),transforms.CenterCrop(RESIZE), transforms.ToTensor(),normalize,])# 创建数据集并应用相关转换
training_dataset = torchvision.datasets.ImageFolder(root = str(data_dir),transform = training_transform,
)
validation_dataset = torchvision.datasets.ImageFolder(root = str(data_dir),transform = validation_transform
)
# 检查数据集规范化
# 归一化后,均值应接近0,std应接近1
normalized_dataloader = torch.utils.data.DataLoader(validation_dataset, batch_size=len(validation_dataset),)
print(f"mean = {calculate_dataset_mean(normalized_dataloader)}",f"std = {calculate_dataset_std(normalized_dataloader)}")
# 使用采样器在训练和验证之间分割数据
split = int(np.floor(len(training_dataset) * VALIDATION_SIZE))
indices = list(range(len(training_dataset)))
if SHUFFLE:random.shuffle(indices)validation_indices, training_indices = indices[: split], indices[split :]training_sampler = torch.utils.data.sampler.SubsetRandomSampler(training_indices)
validation_sampler = torch.utils.data.sampler.SubsetRandomSampler(validation_indices)
# 数据加载器配置
BATCH_SIZE = 4
NUMBER_OF_WORKERS = 2
PIN_MEMORY = False
# 创建数据加载器
training_dataloader = torch.utils.data.DataLoader(training_dataset, batch_size=BATCH_SIZE, sampler=training_sampler,num_workers=NUMBER_OF_WORKERS, pin_memory=PIN_MEMORY,)validation_dataloader = torch.utils.data.DataLoader(training_dataset, batch_size=BATCH_SIZE, sampler=validation_sampler,num_workers=NUMBER_OF_WORKERS, pin_memory=PIN_MEMORY,)
import matplotlib.pyplot as plt
%matplotlib inline# 展示图片
for images, labels in training_dataloader:fig = plt.figure(figsize = (14, 7))for i in range(BATCH_SIZE):ax = fig.add_subplot(2, 4, i + 1, xticks = [], yticks = [])ax.set_xlabel(f"cancer = {CLASSES[labels[i]]}")image = images[i][0, :, :]plt.imshow(image)break
# 训练模型配置
MODEL_NAME = "resnet18"
WEIGHTS = "DEFAULT"
LEARNING_RATE = 0.0001
MOMENTUM = 0.9
NUMBER_OF_EPOCHS = 10
MODEL_SAVE_PATH = "model.pt"# 初始化模型
model = torchvision.models.get_model(MODEL_NAME, weights=WEIGHTS)
model.fc = torch.nn.Linear(512, 2)
# 选择一个损失函数和一个优化函数
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
# 开始训练模型
# 存储训练过程状态的地方
training_loss_history = []
validation_loss_history = []
validation_accuracy_history = []# 训练和验证循环
for epoch in range(NUMBER_OF_EPOCHS):model.train()training_step_loss = []print(f"Epoch {epoch + 1}/{NUMBER_OF_EPOCHS}")for data in tqdm.tqdm(training_dataloader, desc="training"):features, labels = dataoptimizer.zero_grad()outputs = model(features)training_loss = criterion(outputs, labels)training_loss.backward()optimizer.step()training_step_loss.append(training_loss.item())training_epoch_loss = sum(training_step_loss)/len(training_step_loss)training_loss_history.append(training_epoch_loss)model.eval()validation_step_loss = []correct_predictions = 0 for data in tqdm.tqdm(validation_dataloader, desc="validating"):features, labels = dataoutputs = model(features)correct_predictions += torch.sum(torch.argmax(outputs, axis=1)==labels)validation_loss = criterion(outputs, labels)validation_step_loss.append(validation_loss.item())validation_epoch_loss = sum(validation_step_loss)/len(validation_step_loss)validation_loss_history.append(validation_epoch_loss)validation_epoch_accuracy = correct_predictions / (len(validation_dataloader) * BATCH_SIZE)print(f"Training Loss: {training_epoch_loss:.4f},"f"Validation Loss: {validation_epoch_loss:.4f}," f"Validation Acc: {validation_epoch_accuracy:.4f}")# 保存模型if epoch==0 or validation_epoch_accuracy > max(validation_accuracy_history):print("Validation loss improved, saving checkpoint.")torch.save({'epoch': epoch,'model_state_dict': model.state_dict(),'optimizer_state_dict': optimizer.state_dict(),'loss': validation_epoch_loss,}, MODEL_SAVE_PATH)print("Checkpoint saved")validation_accuracy_history.append(validation_epoch_accuracy)
print('Finished Training')
# 绘制训练和验证损失
plt.plot(training_loss_history, label='training_loss')
plt.plot(validation_loss_history,label='validation_loss')
plt.legend()
plt.show
# 绘制验证精度图
plt.plot(validation_accuracy_history, label='validation accuracy')
plt.legend()
plt.show
文末福利
《人工智能与ChatGPT》免费包邮送出3本!

内容简介:
人们相信人工智能可以为这个时代的技术带来突破,而ChatGPT则使这种希望成为现实。现在,许多人都渴望了解与ChatGPT相关的一切,包括技术的历史和背景,其神奇的功能以及如何使用它。虽然ChatGPT的使用方法很简单,但它具有无限的潜力。如果不去亲身体验,很难体会到它的强大之处。本书尽可能全面地介绍了与ChatGPT相关的内容,特别是许多应用示例,可以给读者带来启发。
希望读者通过这本书了解ChatGPT后,在自己的工作中也能充分利用它。本书适合希望了解和使用ChatGPT的人阅读。
编辑推荐:
ChatGPT的背景:从大语言模型到GPT
ChatGPT的技术:从Transformer模型到RLHF
ChatGPT的使用:从对话到OpanAI API
ChatGPT的应用:从编程到统计分析
ChatGPT的案例:从写专利到出试卷
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-07-10 20:00:00
- 京东购买链接:https://item.jd.com/14049920.html
名单公布时间:2023-07-10 21:00:00