文章目录
- 原理小结
- deepctr实现DIN(基于df的数据格式)
原理小结
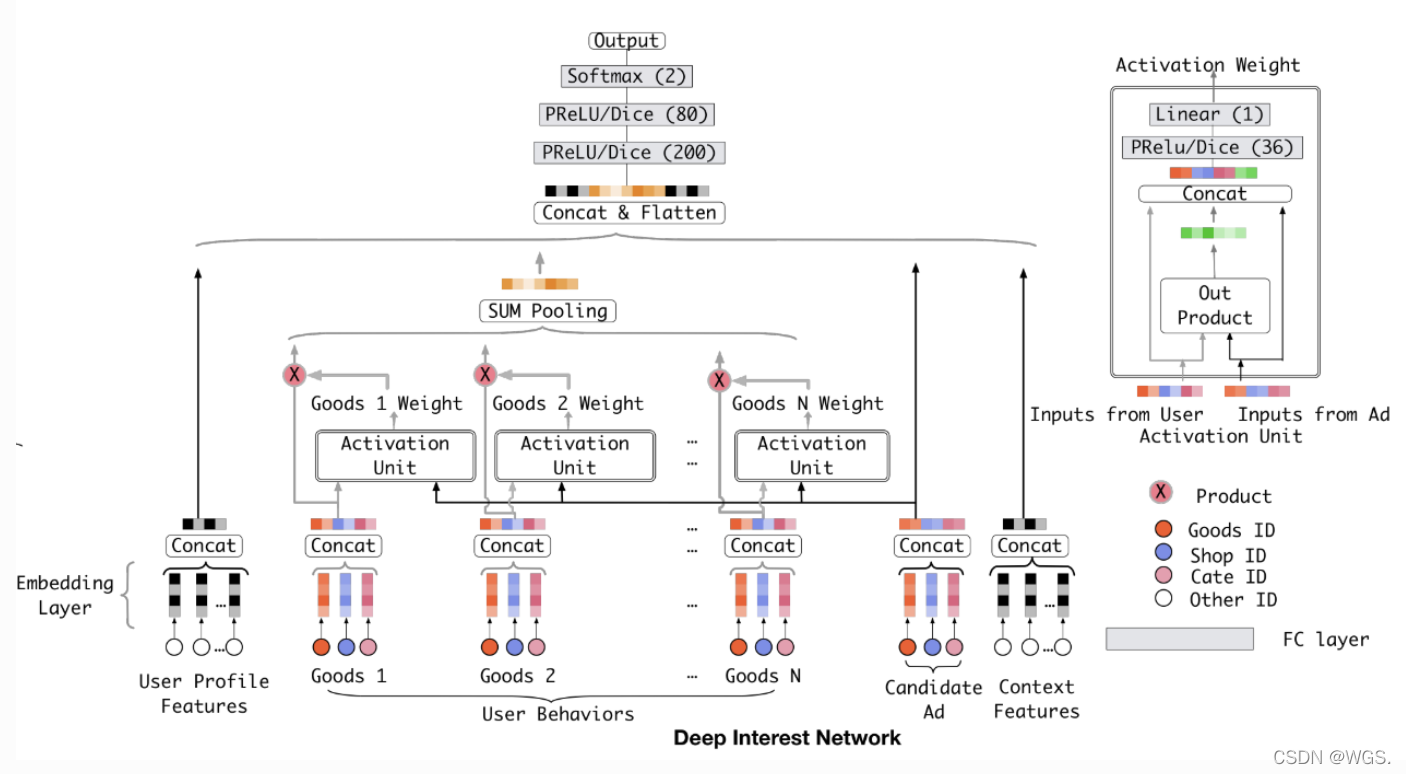

-
Candidate Ad
- item,在这指广告特征。
-
User profile features
- 代表用户的特征。
-
Context Features
- 代表跟场景有关的特征,比如时间戳之类的。
-
User Behaviors
- 代表着用户行为特征。
- 主要就是过去用户明确表示感兴趣的item统统都打包起来,我们看一个人不是看他说什么,是看他做什么,所以这些特征要重点关照。
-
Activation Unit
-
通常DNN网络抽取特征的高阶特征,减少人工特征组合,对用户历史行为数据进行处理时,需要把它们编码成一个固定长的向量,但是每个用户的历史点击个数是不相等的,通常的做法是对每个item embedding后,进入pooling层(求和或最大值)。DIN认为这样操作损失了大量的信息,故此引入attention机制,并提出了 Dice 激活函数,自适应正则,显著提升了模型性能与收敛速度。
-
在Base Model里,这些用户行为特征在映射成embedding后直接一个sum/average pooling就算完事了,结果就是一个静态的embedding无法表征一个用户广泛的兴趣,所以在DIN中考虑加入Activation Unit,每个曾经的用户行为都跟Candidate Ad交互,交互的方法在上图的右上角也给出了,交互呢会交互出一个权重,代表着曾经的一个用户行为与Candidate Ad的相关性。比如你曾经买过篮球,买过毛衣针,那眼下有一个哈登同款保温杯,那我们肯定是更关注你以前买篮球的行为,那你买篮球的行为映射出的一个embedding的权重就大,买毛衣针的行为映射出的一个embedding的权重就小。有了这个权重,我们就可以在所有用户行为特征映射成embedding后做weighted sum pooling了。这样,针对每个不同的 Candidate Ad,每个用户行为特征在映射成embedding后经过weighted sum pooling后就会生成一个汇总的不同的embedding,这就是动态的embedding,动态的embedding就能表征出用户广泛的兴趣了。
-
关于DIN中,attention注意力机制、Dice激活函数、自适应正则详见:
注:链接文中Dice激活函数模块,PReLU的图是错的。
https://blog.csdn.net/Super_Json/article/details/105334936
参考自:
https://blog.csdn.net/Super_Json/article/details/105334936
https://blog.csdn.net/suspend2014/article/details/104377681
https://www.freesion.com/article/70981345211/
https://www.heywhale.com/mw/project/5d47d118c143cf002becca99
deepctr实现DIN(基于df的数据格式)
# coding:utf-8
import os, warnings, time, sys
import pickle
import matplotlib.pyplot as plt
import pandas as pd, numpy as np
from sklearn.utils import shuffle
from sklearn.metrics import f1_score, accuracy_score, roc_curve, precision_score, recall_score, roc_auc_score
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder
# from sklearn.preprocessing import LabelEncoder as LEncoder # 重写LabelEncoder
from sklearn.preprocessing import LabelEncoder
from deepctr.models import DeepFM, xDeepFM, MLR, DeepFEFM, DIN, DIEN, AFM
from deepctr.feature_column import SparseFeat, DenseFeat, get_feature_names
from deepctr.layers import custom_objects
from tensorflow.keras.models import save_model, load_model
from tensorflow.keras.models import model_from_yaml
import tensorflow as tf
from tensorflow.python.ops import array_ops
import tensorflow.keras.backend as K
from sklearn import datasets
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
from keras.models import model_from_json
from tensorflow.keras.callbacks import *
from tensorflow.keras.models import *
from tensorflow.keras.layers import *
from tensorflow.keras.optimizers import *
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import one_hot
from keras.layers.embeddings import Embedding
from deepctr.feature_column import SparseFeat, VarLenSparseFeat, DenseFeat, get_feature_namesfrom toolsnn import *
import settingsdef get_xy_fd2():data = pd.DataFrame({# 基础特征数据'user': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10],'gender': [10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20],'item_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],'cate_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],'pay_score': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.10, 0.11],# 构造历史行为序列数据# 构造长度为 4 的 item_id 序列,不足的部分用0填充'hist_item_id': [np.array([1, 2, 3, 10]), np.array([6, 1, 0, 0]), np.array([3, 2, 1, 0]), np.array([1, 2, 10, 0]), np.array([1, 3, 0, 0]), np.array([3, 2, 0, 0]), np.array([5, 2, 0, 0]), np.array([10, 6, 0, 0]), np.array([1, 2, 10, 0]), np.array([3, 2, 10, 0]), np.array([9, 2, 10, 0])],# 构造长度为 4 的 cate_id 序列,不足的部分用0填充'hist_cate_id': [np.array([1, 2, 3, 10]), np.array([6, 1, 0, 0]), np.array([3, 2, 1, 0]), np.array([1, 2, 10, 0]), np.array([1, 3, 0, 0]), np.array([3, 2, 0, 0]), np.array([5, 2, 0, 0]), np.array([10, 6, 0, 0]), np.array([1, 2, 10, 0]), np.array([3, 2, 10, 0]), np.array([9, 2, 10, 0])],'y': [1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0]})print(data)print(data.dtypes)dcols = len(data.columns)# 对基础特征进行 embeddingbise_feature = [SparseFeat('user', vocabulary_size=int(data['user'].max())+1, embedding_dim=4),SparseFeat('gender', vocabulary_size=int(data['gender'].max())+1, embedding_dim=4),SparseFeat('item_id', vocabulary_size=int(data['item_id'].max())+1, embedding_dim=4),SparseFeat('cate_id', vocabulary_size=int(data['cate_id'].max())+1, embedding_dim=4),DenseFeat('pay_score', 1)]# 指定历史行为序列对应的特征behavior_feature_list = ["item_id", "cate_id"]# 构造 ['item_id', 'cate_id'] 这两个属性历史序列数据的数据结构: hist_item_id, hist_cate_id# 由于历史行为是不定长数据序列,需要用 VarLenSparseFeat 封装起来,并指定序列的最大长度为 4# 注意,对于长度不足4的部分会用0来填充,因此 vocabulary_size 应该在原来的基础上 + 1behavior_feature = [VarLenSparseFeat(SparseFeat('hist_item_id', vocabulary_size=int(data['item_id'].max())+1, embedding_dim=4, embedding_name='item_id'), maxlen=4),VarLenSparseFeat(SparseFeat('hist_cate_id', vocabulary_size=int(data['cate_id'].max())+1, embedding_dim=4, embedding_name='cate_id'), maxlen=4)]feature_columns = bise_feature + behavior_featurefeature_names = get_feature_names(bise_feature + behavior_feature)print(feature_names)x = {}for name in feature_names:if name not in ['hist_item_id', 'hist_cate_id']:x[name] = data[name].valuesprint(name, type(data[name].values))else:tmp = [t for t in data[name].values]x[name] = np.array(tmp)print(name, type(x[name]))y = data['y'].valuesprint(x)print(y)print(feature_columns)print(behavior_feature_list)return x, y, feature_columns, behavior_feature_listif __name__ == "__main__":x, y, feature_columns, behavior_feature_list = get_xy_fd2()# 构造 DIN 模型model = DIN(dnn_feature_columns=feature_columns, history_feature_list=behavior_feature_list)model.compile('adam', 'binary_crossentropy',metrics=['binary_crossentropy'])history = model.fit(x, y, verbose=1, epochs=3)