最近接了一个私活,指导学妹完成毕业设计。核心思想就是利用SVM模型来预测股票涨跌,并完成策略构建,自动化选择最优秀的股票进行资产配置。
在做这个项目的过程中,我体会到想成为一个合格的数据分析或者数据挖掘工程师不仅技术要过关,还需要了解所要挖掘数据涉及到的领域的相关知识。举个例子,在做数据预处理的时候,不知道超额收益率是怎么个意思,查阅资料才了解,超额收益率是股票行业里的一个专有名词,指大于无风险投资的收益率,在我国无风险投资收益率即是银行定期存款。
也稍微打个小广告,简书上如果有需要做毕业设计的同学可以找我私聊哦。而且如果只是简单咨询一些技术问题,学长会很热心得解答。
废话少说,言归正传。这里有关SVM、PCA等等这些与项目相关的数学知识不会提及,我以后会在算法专题里详细描述。
本项目用pycharm + anaconda3.6开发,涉及到的第三方库有pandas,numpy,matplotlib,skllearn。
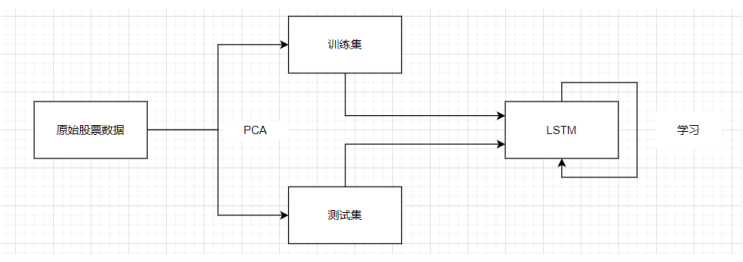
流程图
参数设置
class Para:method = 'SVM' #模型选择为SVMmonth_in_sample = range(1, 7 + 1) #训练集数据对应月份month_test = range(8, 12 + 1) #测试集数据对应月份percent_select = [0.3, 0.3] #正反例股票选取比例percent_cv = 0.1 #交互验证机占样本内数据比例path_data = 'C:/my python/python code/stock predict/Datas/Tests/Tests/' #输入数据文件路径path_result = 'C:/my python/python code/stock predict/Datas/Results/' #输出数据文件路径seed = 42 #random seed设置随机种子,制造伪随机数svm_kernel = 'linear' #支持向量机的核函数类型svm_c = 0.01 #线性支持向量机的惩罚系数
para = Para()
这个就是参数的初始化,没有什么要说的。
数据读取以及标记
#function: label data
#3数据标记
def label_data(data):data['return_bin'] = np.nan #在data表格最后添加一列,并命名为return_bin,这一列将记录每个样本的标签data = data.sort_values(by = '超额收益', ascending = False) #将整个表格按照return列的值降序排列n_stock_select = np.multiply(para.percent_select, data.shape[0]) #选取的股票个数n_stock_select = np.around(n_stock_select).astype(int) #将上行所选取的股票个数取整,注意n_stock_select是个含有两个整数的列表data.iloc[0:n_stock_select[0],-1] = 1data.iloc[-n_stock_select[1]:, -1] = 0 #这两行将表现好的股票标签置1,差的置0data = data.dropna(axis = 0) #将没有1,0标签的,即不是最好的前百分之三十也不是最差的前百分之三十股票从表格里剔除return data#4数据读取
for i_month in para.month_in_sample:file_name = para.path_data + str(i_month) + '.csv'data_curr_month = pd.read_csv(file_name, header = 0) #header=0意思是将表格第一行作为列名para.n_stcok = data_curr_month.shape[0]data_curr_month = data_curr_month.dropna(axis = 0) #去除缺省值data_curr_month = label_data(data_curr_month) #将读入的数据进行标记if i_month == para.month_in_sample[0]:data_in_sample = data_curr_monthelse:data_in_sample = data_in_sample.append(data_curr_month)
print('数据读取完成')#5数据预处理
X_in_sample = data_in_sample.loc[:,'货币资金(万元)':'应收分保账款(万元)']
y_in_sample = data_in_sample.loc[:,'return_bin'] #从样本内数据中分别提取特征与标签因子
X_train,X_cv,y_train,y_cv = train_test_split(X_in_sample,y_in_sample,test_size=para.percent_cv, random_state=para.seed)#按照固定比例随机分配训练集与交叉验证集
pca = decomposition.PCA(n_components=0.95)
pca.fit(X_train)
X_train = pca.transform(X_train)
X_cv = pca.transform(X_cv) #以上是关于主成分分析模型的代码
print('数据预处理完成')
代码的基本功能注释里也写了一些,不过不够全面,我再详细说一下。这三部分代码所实现的功能是读取数据,并对数据进行预处理。我已经把最原始的数据整理好放在了excel表格里,并且将第一个月的全部股票的参数放在一个excel里,并将其命名为1.csv,以此类推,我爬取了157个月的数据,总共有157个excel。因此代码里循环的便是excel的文件名,也就是依次读取excel文件。因为数据量太大,所以我一般调试的时候只跑12个月。所以我在参数初始化阶段,训练集(1,8),测试集(8,12)。
将数据读取到DataFrame表格里后,并不是全部使用,而是取超额收益值最好的前百分之三十,以及最差的后百分之三十,并在表格后追加一列,列名叫return_bin,将最好最差的百分之三十的股票的return_bin列各赋值1,0。然后将每个读取并加工的excel表格拼接在一起形成一个大表格,从总抽取70个因子作为X_in_sample,抽取return_bin作为y_in_sample作为训练集。
训练模型
#6
print('选择模型')
if para.method == 'SVM':model = svm.SVC(kernel=para.svm_kernel, C=para.svm_c)
print('模型选择为SVM')#7用训练好的模型分别放到训练集和验证集上去预测,用来调参
print('模型开始训练')
if para.method == 'SVM':model.fit(X_train, y_train)y_pred_train = model.predict(X_train)y_score_train = model.decision_function(X_train)y_pred_cv = model.predict(X_cv)y_score_cv = model.decision_function(X_cv)
print('模型训练结束')
这个也比较好理解,就是选择sklearn库里的svm模块对数据进行训练。svm模型是集成封装好的,拿来用就可以。
模型预测与评价
#8使用训练完成的模型再测试集上做预测
print('模型预测开始')
y_true_test = pd.DataFrame([np.nan] * np.ones((para.n_stcok, para.month_test[-1])))
y_pred_test = pd.DataFrame([np.nan] * np.ones((para.n_stcok, para.month_test[-1])))
y_score_test = pd.DataFrame([np.nan] * np.ones((para.n_stcok, para.month_test[-1]))) #先对各种参数做一个初始化
print(y_true_test)
for i_month in para.month_test: #遍历测试集的每一个月份,每个月份都有上市的所有股票file_name = para.path_data + str(i_month) + '.csv' #读取预测集上的数据data_curr_month = pd.read_csv(file_name, header=0)data_curr_month = data_curr_month.dropna(axis=0)X_curr_month = data_curr_month.loc[:,'货币资金(万元)':'应收分保账款(万元)']X_curr_month = pca.transform(X_curr_month)if para.method == 'SVM':y_pred_curr_month = model.predict(X_curr_month)y_score_curr_month = model.decision_function(X_curr_month)y_true_test.iloc[data_curr_month.index, i_month - 1] = data_curr_month['超额收益'][data_curr_month.index]y_pred_test.iloc[data_curr_month.index, i_month - 1] = y_pred_curr_monthy_score_test.iloc[data_curr_month.index, i_month - 1] = y_score_curr_month
print(y_true_test)
print('模型预测结束')#9模型评价
print('模型开始评价')
print('training set, accuracy = %.2f'%metrics.accuracy_score(y_train, y_pred_train))
print('training set, ACU = %.2f'%metrics.roc_auc_score(y_train, y_score_train))
print('cv set, accuracy = %.2f'%metrics.accuracy_score(y_cv, y_pred_cv))
print('cv set, ACU = %.2f'%metrics.roc_auc_score(y_cv, y_score_cv))
for i_month in para.month_test:y_true_curr_month = pd.DataFrame({'超额收益':y_true_test.iloc[:, i_month - 1]})y_pred_curr_month = y_pred_test.iloc[:,i_month - 1]y_score_curr_month = y_score_test.iloc[:,i_month - 1]y_true_curr_month = y_true_curr_month.dropna(axis=0)y_curr_month = label_data(y_true_curr_month)['return_bin']y_pred_curr_month = y_pred_curr_month[y_curr_month.index]y_score_curr_month = y_score_curr_month[y_curr_month.index]print('test set, month %d, accuracy = %.2f'%(i_month, metrics.accuracy_score(y_curr_month, y_pred_curr_month)))print('test set, month %d, AUC = %.2f'%(i_month, metrics.roc_auc_score(y_curr_month, y_score_curr_month)))
print('模型评价结束')
现在模型就训练好了,然后就那训练好的模型在测试集上来跑,看看情况到底如何。

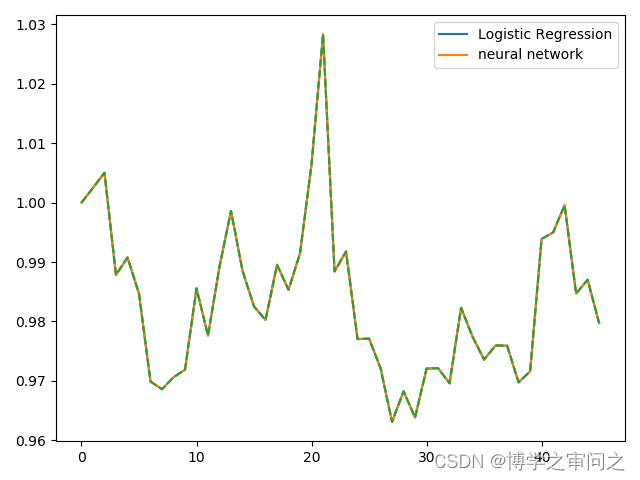
可以看到参数并不是多好,这是训练集上数据太少的原因。那我们来改动一下,把训练集改成(1,10),测试集改成(10,12)看看有没有改变。
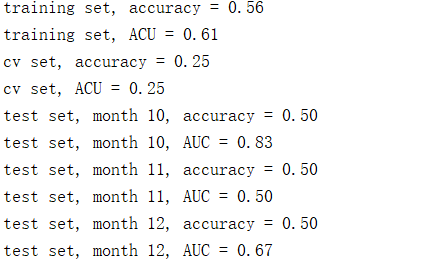
训练集从只有6个月变成9个月(1-10在代码上体现为1-9),参数情况大有改观。可见数据对机器学习模型训练的重要性。
策略构建以及策略评价
#10策略构建
print('策略构建开始')
para.n_stcok_select = 3
strategy = pd.DataFrame({'return' : [0]*para.month_test[-1], 'value' : [1]*para.month_test[-1]}) #这并不是字典格式,而是表格格式,分别表示每月收益和每月净值,初始值为0和1
print(strategy)
for i_month in para.month_test:y_true_curr_month = y_true_test.iloc[:,i_month - 1]print(y_true_curr_month)y_score_curr_month = y_score_test.iloc[:,i_month - 1]y_score_curr_month = y_score_curr_month.sort_values(ascending=False)print(y_score_curr_month)index_select = y_score_curr_month[0:para.n_stcok_select].indexprint(index_select)strategy.loc[i_month-1, 'return'] = np.mean(y_true_curr_month[index_select])print(strategy)
strategy['value'] = (strategy['return'] + 1).cumprod()print('策略构建结束')#11策略评价
print('策略评价开始')
month_test = np.array(para.month_test)
month_test = month_test - 1
print(strategy.loc[month_test, 'value'])
plt.plot(month_test, strategy.loc[month_test, 'value'],'r-')
plt.show()ann_excess_return = np.mean(strategy.loc[month_test,'return']) * 12 #策略年化超额收益
print(ann_excess_return)
ann_excess_vol = np.std(strategy.loc[month_test,'return']) * np.sqrt(12) #策略年化超额收益波动
info_ratio = ann_excess_return/ann_excess_vol #数值越大策略越好
print('annual excess return = %.2f'%ann_excess_return)
print('annual excess volatility = %.2f'%ann_excess_vol)
print('information ratio = %.2f'%info_ratio)
print('以上为策略评价参数')print('策略评价结束')
所谓策略构建就是选择什么样的股票,代码里将股票按照超额收益率进行排序,然后我设置para.n_stcok_select = 3意思就是选择超额收益率前三名进行购买。
所谓策略评价这里采用的评价体系就是将选择的三支股票的每月超额收益率取平均值乘12,来作为这三只股票在该月的年化收益率。
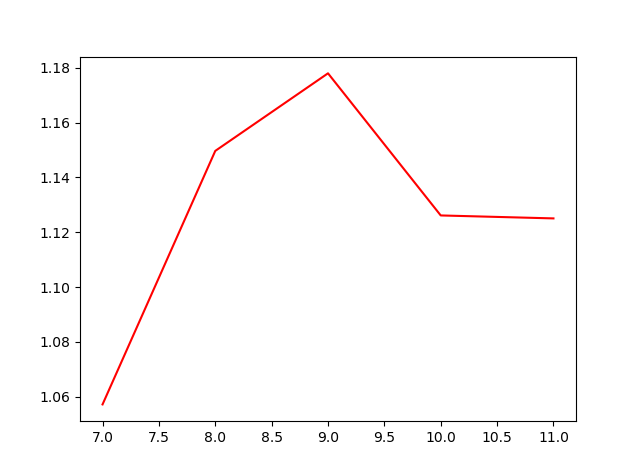
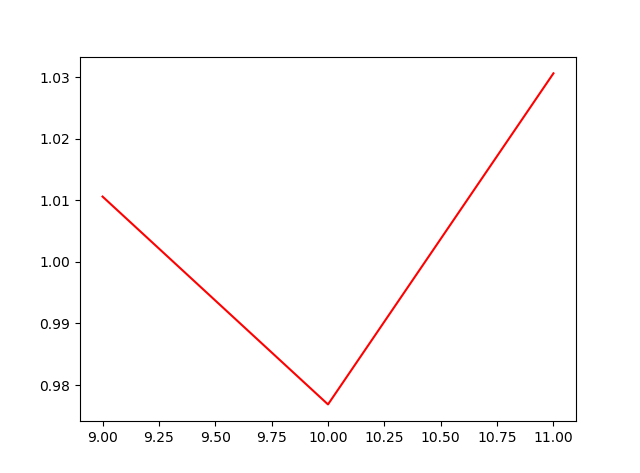
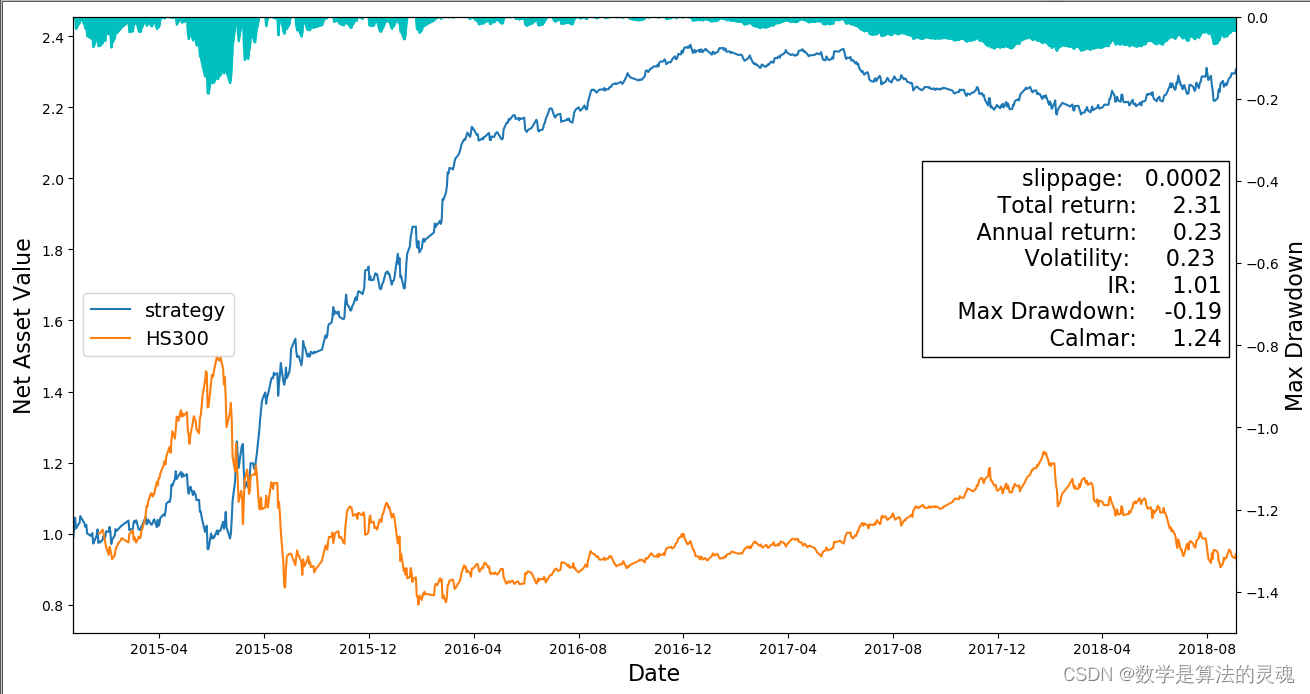
以上两张图是选择不同月份做训练集后,模型策略的表现。
在这里还要提及的是这行代码,month_test = np.array(para.month_test)
month_test = month_test - 1。这个涉及到了np数组的高阶用法。一般数组是无法和数字做运算的,可是将普通数组用np.array()加工过后,变成了np数组,他拥有一个广播属性,可以直接与数字运算。该行代码就是将数组里每个元素都减1。
想要数据集跑程序又不会爬虫,微信里输入CS_mastering搜索公众号,关注后回复股票预测获取资源,可以分享