由于CSDN审核机制,导致原文章无法发出,故修改了相关词汇,并改为两篇问章发布。
数据获取
翻页操作
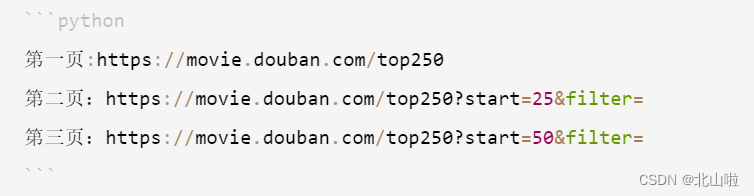
观察可知,我们只需要修改start参数即可
headers字段
headers中有很多字段,这些字段都有可能会被对方服务器拿过来进行判断是否为爬虫
通过headers中的User-Agent字段来
- 原理:默认情况下没有User-Agent,而是使用模块默认设置
- 解决方法:请求之前添加User-Agent即可;更好的方式是使用User-Agent池来解决(收集一堆User-Agent的方式,或者是随机生成User-Agent)
在这里我们只需要添加请求头即可
数据定位
这里我使用的是xpath
# -*- coding: utf-8 -*-
# @Author: Kun
import requests
from lxml import etree
import pandas as pd
df = []
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4343.0 Safari/537.36','Referer': 'https://movie.douban.com/top250'}
columns = ['排名','电影名称','导演','上映年份','制作国家','类型','评分','评价分数','短评']
def get_data(html):xp = etree.HTML(html)lis = xp.xpath('//*[@id="content"]/div/div[1]/ol/li')for li in lis:"""排名、标题、导演、演员、"""ranks = li.xpath('div/div[1]/em/text()')titles = li.xpath('div/div[2]/div[1]/a/span[1]/text()')directors = li.xpath('div/div[2]/div[2]/p[1]/text()')[0].strip().replace("\xa0\xa0\xa0","\t").split("\t")infos = li.xpath('div/div[2]/div[2]/p[1]/text()')[1].strip().replace('\xa0','').split('/')dates,areas,genres = infos[0],infos[1],infos[2]ratings = li.xpath('.//div[@class="star"]/span[2]/text()')[0]scores = li.xpath('.//div[@class="star"]/span[4]/text()')[0][:-3]quotes = li.xpath('.//p[@class="quote"]/span/text()')for rank,title,director in zip(ranks,titles,directors):if len(quotes) == 0:quotes = Noneelse:quotes = quotes[0]df.append([rank,title,director,dates,areas,genres,ratings,scores,quotes])d = pd.DataFrame(df,columns=columns)d.to_excel('Top250.xlsx',index=False)
for i in range(0,251,25):url = "https://movie.douban.com/top250?start={}&filter=".format(str(i))res = requests.get(url,headers=headers)html = res.textget_data(html)
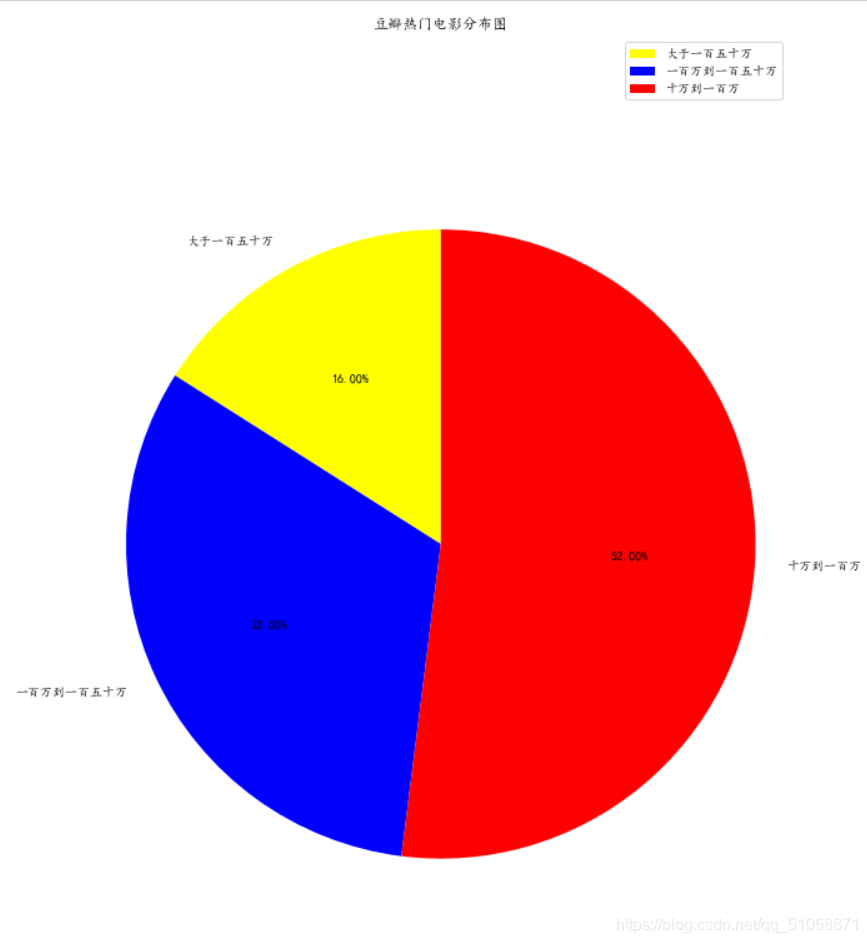
生成的数据保存在Top250.xlsx中。
- 使用面向对象+线程
# -*- coding: utf-8 -*-
"""
Created on Tue Feb 2 15:19:29 2021@author: 北山啦
"""
import pandas as pd
import time
import requests
from lxml import etree
from queue import Queue
from threading import Thread, Lockclass Movie():def __init__(self):self.df = []self.headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4343.0 Safari/537.36','Referer': 'https://movie.douban.com/top250'}self.columns = ['排名','电影名称','导演','上映年份','制作国家','类型','评分','评价分数','短评']self.lock = Lock()self.url_list = Queue()def get_url(self):url = 'https://movie.douban.com/top250?start={}&filter='for i in range(0,250,25):self.url_list.put(url.format(str(i)))def get_html(self):while True:if not self.url_list.empty():url = self.url_list.get()resp = requests.get(url,headers=self.headers)html = resp.textself.xpath_parse(html)else:break def xpath_parse(self,html):xp = etree.HTML(html)lis = xp.xpath('//*[@id="content"]/div/div[1]/ol/li')for li in lis:"""排名、标题、导演、演员、"""ranks = li.xpath('div/div[1]/em/text()')titles = li.xpath('div/div[2]/div[1]/a/span[1]/text()')directors = li.xpath('div/div[2]/div[2]/p[1]/text()')[0].strip().replace("\xa0\xa0\xa0","\t").split("\t")infos = li.xpath('div/div[2]/div[2]/p[1]/text()')[1].strip().replace('\xa0','').split('/')dates,areas,genres = infos[0],infos[1],infos[2]ratings = li.xpath('.//div[@class="star"]/span[2]/text()')[0]scores = li.xpath('.//div[@class="star"]/span[4]/text()')[0][:-3]quotes = li.xpath('.//p[@class="quote"]/span/text()')for rank,title,director in zip(ranks,titles,directors):if len(quotes) == 0:quotes = Noneelse:quotes = quotes[0]self.df.append([rank,title,director,dates,areas,genres,ratings,scores,quotes])d = pd.DataFrame(self.df,columns=self.columns)d.to_excel('douban.xlsx',index=False)def main(self):start_time = time.time()self.get_url()th_list = []for i in range(5):th = Thread(target=self.get_html)th.start()th_list.append(th)for th in th_list:th.join()end_time = time.time()print(end_time-start_time)
if __name__ == '__main__':spider = Movie()spider.main()