通过拖拉方式配置话术流程。

全局流程
需要多处重复执行的流程,可以单独配置一个全局流程
时间限制
只匹配通话的前多少毫秒的识别结果,不设置或者0无限制,单位毫秒
按次限制
只匹配前多少次的识别结果,不设置或者0无限制,一句话算一次,禁止打断时候说话不算
忽略禁止打断
就算配置了禁止打断,也尝试匹配这个全局流程,典型的用法开场白设置了静止打断,但是要挂断语音信箱应答的通话。
流程节点
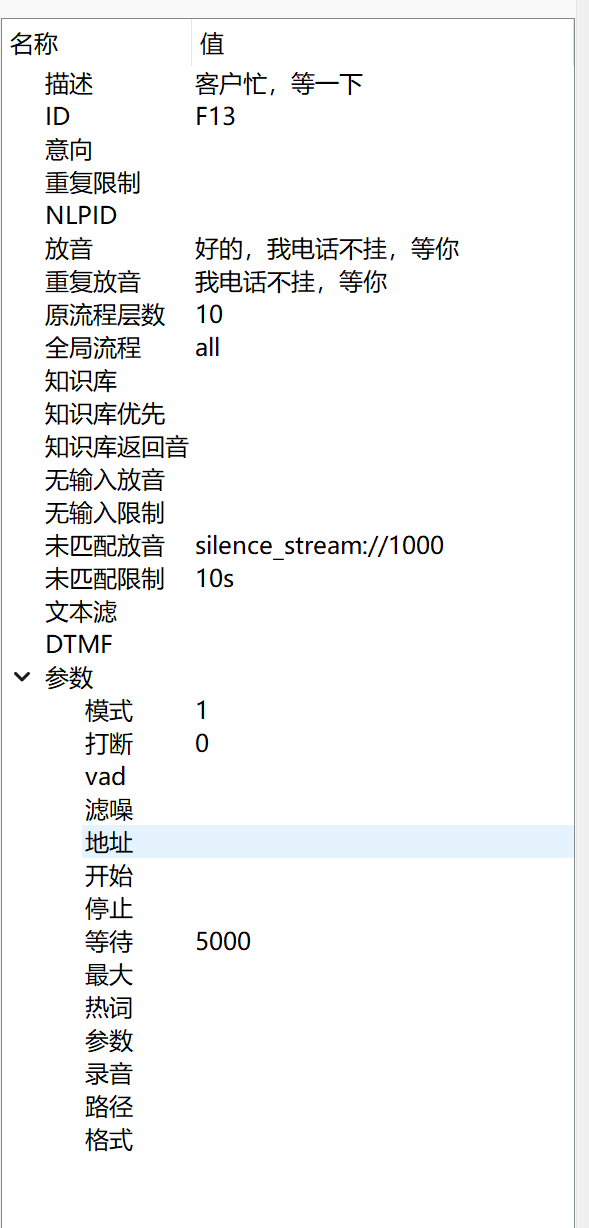
通用
- 描述:介绍流程的用处
- ID: 唯一ID
- 意向: 意向分级,如果是正数比如3,就是意向加3,如果是负数比如-2,就是意向减2,强制设置意向值前面加个等于号,比如=5意向强制设置为5。
- 重复限制:动作最大执行次数,可防止流程进入死循环,不设置或者0,不限制,比如设置1,就是限制只能执行1次
放音
- NLPID(nlpid):NLP ID,配置了这个值才会把输入事件提交给NLP接口处理
- 放音(playbacks):机器人播放的声音文件
- 重复放音(replaybacks):第二次进入(比如其他流程返回)机器人播放的声音文件,如果不设置,会使用“放音”设置的参数。如果没配置知识库返回音,知识库返回也会播放这个声音。
- 第三次放音(thirdplaybacks):第三次或者更多次进入(比如其他流程返回)机器人播放的声音文件,如果不设置,会使用“重复放音”设置的参数。知识库返回会忽略这个配置
- 更多次放音(fourplaybacks):第四次或者以后进入(比如其他流程返回)机器人播放的声音文件,如果不设置,会使用“重复放音”设置的参数。知识库返回会忽略这个配置。
- 原流程层数(sourceflowdepth):输入和原流程(通过知识库切换流程或者全局流程进入时的流程)的子流程条件进行匹配。0:不关联原流程,大于0:关联原流程的层数。用法见下图。

- 全局流程(globalflow): 关联的知全局流程,可以设置多个,all:关联所有全局流程。为了防止死循环,全局流程的子流程,会自动排除所在的全局流程,即不会关联所在的全局流程。
- 知识库优先(kb_priority):0:子流程优先,1:知识库优先。默认是先匹配子流程关键词,然后匹配知识库关键词,如果设置了知识库优先,就会先匹配知识库关键词,然后再匹配子流程关键词。
- 知识库(kb):设置关联的知识库
- 知识库返回音(kbplaybacks):播放完知识库回答后面播放的声音,或者全局流程返回播放的声音。
- 返回切换流程(kbswitchflow):触发知识库或者全局流程返回后,直接执行切换流程(不播放知识库返回音),top:返回到最顶级流程,return:返回到上一级流程,也可以指定流ID。其他参数和return动作的返回值一样”)
- 无输入放音(timeoutplaybacks):DTMF按键超时或者未检测到用户说话(ASR没识别到文字)机器人播放的声音文件,优先级高于(ANY),如果无输入次数超过限制,则执行ANY流程。如果没设置无输入放音但是设置了未匹配放音,则执行未匹配放音。
- 无输入追加放音(timeoutaddplayback):无输入放音之后是否播放默认放音(如果配置了重复放音,就是播放重复放音,如果没配置重复放音,就是使用放音配置)。
- 无输入限制(timeoutrepetition):无输入放音最大连续执行次数,如果最后一个字符是s,表示使用时间限制代替次数限制,单位秒。比如10s,表示10秒之内TIMEOUT()输入,都执行无输入放音,10秒之后则执行ANY流程。
- 未匹配放音(mismatchplaybacks):未匹配到关键词播放的声音
- 未匹配追加放音(mismatchaddplayback):未匹配放音之后是否播放默认放音(如果配置了重复放音,就是播放重复放音,如果没配置重复放音,就是使用放音配置)。
- 未匹配限制(mismatchrepetition):未匹配关键词最大重复播放未匹配声音的次数,超过次数会走ANY流程。
- dtmf(filter.dtmf): DTMF终止符,any:任意字符,none:无终止符,max=最大输入DTMF个数,比如max=16,只有设置了DTMF终止符,才会处理DTMF输入(DTMF就是电话按键的别称)
- 噪音规则(noiserule):ASR会把噪音错误的识别成文字,可以通过正则表达式,把一些识别结果判断为噪音过滤掉。
- 禁止打断(disablebreak):控制是否允许打断,-1:放音的时候都不允许打断。0:任何时候都允许打断,大于0:放音前多少毫秒内禁止打断。 【禁止打断时说话会执行ASR识别,但是不会执行关键词匹配逻辑,如果需要放音时说话不执行ASR识别,可以直接修改ASR模式。】
- 允许抢话(quickresponse):需要ASR流接口能实时返回识别结果才支持抢话,就是不等用户说完,就开始匹配关键词,让机器人更快的回答。
- 模式:【mode】0:不启动ASR识别 1:放音的同时开启ASR识别; 2:放音完成之后才开启ASR识别。
- ASR参数可以覆盖全局配置的默认ASR设置
转移
- 分机:extension:拨号方案目的的。
- 拨号方案:dialplan:拨号方案类型,默认XML。
- 上下文:拨号方案上下文。类如public,default
返回
- 重放知识库: 如果上一个放音是知识库放音,是否重放知识库
- 放音:这个放音会和跳转后节点的放音连接起来,如果跳转后的节点不支持放音,那么这个放音不会生效。
- 返回值:空:返回到调用流程;流程ID:返回到指定流程(如果找不到流程,则挂机);”text:”:前缀匹配调用流程的文本输入;”dtmf:”:前缀匹配调用流程的DTMF输入;”complete:”:前缀匹配调用流程的完成输入。(如果通过输入匹配不到子流程,则返回调用流程)
排队
- 名字:要进入的排队名字。
- 等待:最大等待时间,单位秒。默认不限制。
- 优先级: 总的3个优先级, 0:低优先级 1:中(默认) 2:高优先级别。
条件判断

- 优先级:匹配的顺序,从高到低匹配。
- 文本: 说话会触发这个事件,[asr识别结果,支持正则表达书,ANY表示匹配任意文本,如果配置了未匹配放音,只有未匹配次数超过了限制,才执行ANY(前缀F:识别完成,前缀E:系统错误,前缀S:识别中,需要开启允许抢话才有实时输入)。
- 完成:流程节点执行完成会触发这个事件,完成原因格式BREAK|DONE|TIMEOUT|ERROR,ANY匹配任意原因,如果配置了未匹配放音,只有未匹配次数超过了限制,才执行ANY,为了意外情况,建议每个节点,都添加一个any子节点。有关系统问题欢迎和博主交流学习,飞机okccai
- TIMEOUT 放音完成后,等待【wait_speech_timeout_ms】事件内没有按键或者说话,或者最大说话时间到了,还没停止说话。TIMEOUT(F:放音时候的识别内容S:超过最大说话时间了)。如果没检测到声音就是TIMEOUT()。
- DONE 按键符合终止条件,或者说话停止了,但是 DTMF和文本都没匹配上子流程。
- ERROR 动作执行遇到错误。比如放音文件不存在
- BREAK 动作给外部打断了。
- 按键:必须配置了DTMF终止符,电话按键才会触发这个事件,输入格式[d|D]后跟DTMF字符,d:未匹配到终止符,D:已经匹配到终止符,[ANY表示匹配任意按键,如果配置了未匹配放音,只有未匹配次数超过了限制,才执行ANY]