1 项目背景
使用2015年7月到2017年8月两年的订单数据进行分析,了解酒店预订需求的基本情况,找出导致订单取消的特征。
2 数据初步探索
2.1 数据结构梳理
拿到数据之后,首先看看里面具体有哪些内容,理解每个字段(变量)的意思,具体的数值代表什么,数据之间有哪些关系。根据二八法则,简单的数据分析、结构梳理和数据清洗的工作占数据分析80%以上的工作量,虽然很基础枯燥,没什么技术含量,但是这些前提工作必须要做好,才可能把项目理解透彻,很大程度上决定了项目的成败。
这里的每一行数据代表着一个订单。
| id | 字段名 | 解析 |
|---|---|---|
| 1 | hotel | 酒店类型:city hotel(城市酒店),resort hotel(度假酒店) |
| 2 | is_canceled | 订单是否取消:1(取消),0(没有取消) |
| 3 | lead_time | 下单日期到抵达酒店日期之间间隔的天数 |
| 4 | arrival_date_year | 抵达年份:2015、2016、2017 |
| 5 | arrival_date_month | 抵达月份:1月-12月 |
| 6 | arrival_date_day_of_month | 抵达日期:1-31日 |
| 7 | arrival_date_week_number | 抵达的年份周数:第1-72周 |
| 8 | stays_in_weekend_nights | 周末(星期六或星期天)客人入住或预定入住酒店的次数 |
| 9 | stays_in_week_nights | 每周晚上(星期一至星期五)客人入住或预定入住酒店的次数 |
| 10 | adults | 成年人数 |
| 11 | children | 儿童人数 |
| 12 | babies | 婴儿人数 |
| 13 | meal | 预订的餐型:SC\BB\HB\FB |
| 14 | country | 原国籍 |
| 15 | market_segment | 细分市场 |
| 16 | distribution_channel | 预订分销渠道 |
| 17 | is_repeated_guest | 订单是否来自老客户(以前预订过的客户):1(是)0(否) |
| 18 | previous_cancellations | 客户在当前预订前取消的先前预订数 |
| 19 | previous_bookings_not_canceled | 客户在本次预订前未取消的先前预订数 |
| 20 | reserved_room_type | 给客户保留的房间类型 |
| 21 | assigned_room_type | 客户下单时指定的房间类型 |
| 22 | booking_changes | 从预订在PMS系统中输入之日起至入住或取消之日止,对预订所作的更改/修改的数目 |
| 23 | deposit_type | 预付定金类型,是否可以退还:No Deposit(无订金)Non Refund(不可退)Refundable(可退) |
| 24 | agent | 预订的旅行社 |
| 25 | company | 下单的公司(由它付钱) |
| 26 | days_in_waiting_list | 订单被确认前,需要等待的天数 |
| 27 | customer_type | 客户类型 |
| 28 | adr | 平均每日收费,住宿期间的所有交易费用之和/住宿晚数 |
| 29 | required_car_parking_spaces | 客户要求的停车位数 |
| 30 | total_of_special_requests | 客户提出的特殊要求的数量(例如。 双人床或高层) |
| 31 | reservation_status | 订单的最后状态:canceled(订单取消)Check-Out(客户已入住并退房)No-show(客户没有出现,并且告知酒店原因) |
| 32 | reservation_status_date | 订单的最后状态的设置日期 |
ps:当is_canceled为1(取消)时,后面的数据并不是都为0,而是正常的数值,说明,这里的信息代表的是预订的时候的信息,比如lead_time,代表的是预订之日,到预计抵达之日之间间隔的日期,而非实际抵达的日期。
2.2 简单探索性数据分析
简单的探索性数据分析主要用于研究数据的分布结构,比如一个变量的极大值、极小值、中位数是什么,数据的分布情况是怎样,通过探索性分析,可以直观地掌握数据的各项特征,为后续的数据清洗工作提供有效的帮助,对清洗后的数据进行探索性分析,将有利于后续分析中选取更合适的数据分析技术。
用pandas_profiling生成探索性数据分析报告,对数据进行初步了解。
import pandas as pd
import pandas_profiling as ppfile_path = r'G:\hotel_booking.csv'
data = pd.read_csv(file_path)
report = pp.pandas_profiling(data)

- 1、该数据集一共有119390行,32个变量。
- 2、重复的行数有26.8%。
- 3、缺失率3.4%,含有缺失值的变量由:children、agent、country、company。
- 4、异常值:adr中包含负值、可能的显著离群点。
- 5、85%以上数据为0的变量:children、babies、is_repeated_guest、previous_cancellations、previous_bookings_not_canceled、booking_changes、day_in_waiting_list、required_car_parking_spaces。
- 6、订单的时间范围为:2015/7/1–2017/8/31,全面跨越的年度只有2016年。
3 数据清洗
3.1 缺失值处理
1、children 有4个缺失值,缺失率<0.01%,应该是没有children入住,用0填充
2、agent 有16340个缺失值,很可能是非机构客户预订的,为个人客户,用0填充
3、country 有488个缺失值,缺失率约0.409%,可能是采集的时候出的问题,用众数进行填充
4、company 中缺失值率超过94%,说明大多数订单是个人客户,之后可以分别对公司和个人预订的行为进行分析,暂用0填充
data_new['children'].fillna(0,inplace=True)
data_new['agent'] = data['agent'].fillna(0)
data_new['country'] = data['country'].fillna(data['country'].mode())
data_new.drop('company',axis=1,inplace=True)
3.2 重复值处理
根据pandas_profilling显示的报告,该数据集的重复率超过23%,但是考虑每一行的订单没有特定的id标识,默认其为合理现象,对重复数据不进行处理。
3.3 异常数据处理
1、adult、children、babies同时为0的情况不合理,共180行,把这些类数据删除。
2、adr平均每日收费中,有1行为负值,删掉。
3、adr中最大值为5400,其他数据均在510以内,且相似的订单(总人数、房型、年月份、特殊要求数,用餐类型相同)的平均adr仅为69,由此判断此值为显著离群点,删除。
4、undefined值
market_segment中2个undefined,用众数Online TA替换。
distribution_channel有5个undefined,用众数TO/TA替换。
meal中有1169个undefined,应该是没有订任何餐型,跟SC意义相同,用SC替换。
data_new['market_segment'].replace('Undefined','Online TA')
data_new['distribution_channel'].replace('Undefined','TO/TA')
data_new['meal'].replace('Undefined','SC')
ps:存在一些看似不太合理,但根据业务具体情况,有可能是合理的数据,不进行处理。比如:
1、对于previous_bookings_not_canceled,当is_repeated_guest为0(全新客户)的时候,此字段有783行数据不为0,即存在这样的客户:在预定日期到抵达日期这个时间段里,下了多个订单。所以,is_repeated_guest为0,previous_bookings_not_canceled不为0,是合理的。
2、stays_in_weekend_nights+stays_in_week_nights=0(总住宿晚数)的adr全部为零,而adr为0的时候,stays_in_weekend_nights+stays_in_week_nights不一定为0。第一,考虑adr是根据总住宿费用/总住宿晚数来计算的,所以出现第一种情况很正常,如果在实际场景中的分析,需要重新考量adr的计算方法,这里为了可以进行下一步的分析,暂时把这种情况定义为合理情况。而第二种情况,可能是由于平台给出的优惠,搞活动之类的,吸引客户,不用给钱也可以住宿。
3.4 数据转化、重组
为了方便分析,需要对一些数据类型进行修改,或者增加分析变量。
1、将arrival_date_month中的英文月份变为中文月份。
2、增加一列预订到店的年月日arrival_date =(arrival_date_year+arrival_date_month+arrival_date_day_of_month)。
3、增加一列总住宿晚数stays_nights_total
=(stays_in_weekend_nights+stays_in_week_nights)。
4、增加一列住宿人数number_of_people
=(adults+children+babies)
处理后的数据数量:共119208行,35列。
print(data.shape)
(119208, 35)
4 构建分析框架
1、EDA分析:

5 分析
在进行具体的分析之前,我了解了一下City Hotel和Resort Hotel两种酒店的一些不同特性,作出一下的对比:

不同的酒店,面对的客户类型不同,营销策略也会有明显差异,也可能会有不同的趋势,在进行分析的时候,如果忽略不同酒店的影响,仅对总体进行分析,那么无论是趋势分析,或者用户结构分析,可能都会模糊掉一些信息,所以,对以下的分析,我都会先对总体进行分析,在对不同酒店类型进行分析。
5.1 运营角度
5.1.1 订单需求趋势
5.1.1.1 总体订单需求趋势


(营收=平均ADR酒店预订数量)
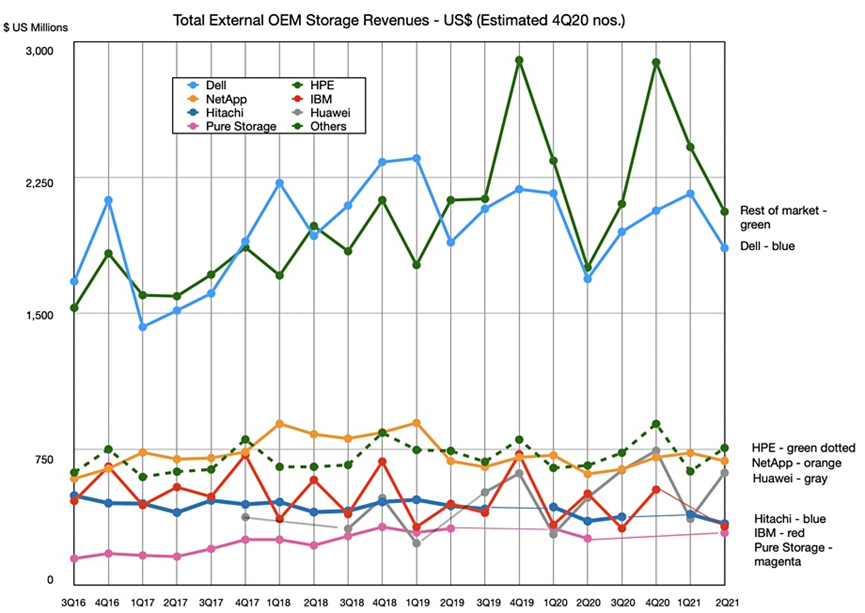
从酒店预订需求曲线来看,酒店预订需求的趋势不是很明显,但是呈明显季节性波动,可以结合年度折叠时间序列图,能更清楚地看出需求首季节影响比较大,有明显的“旺季”和“淡季”。
酒店预订的高峰期分别出现在四月、五月、六月,和九月、十月这两个连续时间段,十二月、一月、二月的预订比较低,2016年一年中,最低值为一月2248笔预订单,最高值为十月6196笔预订单。最低需求比最高需求相差174%。
5.1.1.2 不同酒店订单需求趋势


从图中可以看出,城市酒店(City Hotel)的需求和平均ADR、营收的趋势较为一致,需求最大的时候,酒店的价格越高,需求小的时候,酒店的价格就小。而度假酒店(Resort Hotel)的情况则有差别,需求最大的时候,价格反而较低,由于在旺季的时候,度假酒店的竞争也较大,往往会通过降低价格来吸引更多的客户。
5.1.2 订单取消情况
通过tableau对数据进行可视化分析:

总体订单取消率为37.08%,其中city hotel(城市酒店)类型的酒店预订单取消率更高,为41.79%,resort hotel(度假酒店)为27.77%,相差14.02%。从业务角度出发,一般来说,预订city hotel的客户比较多应是商务出差的需求,而预订resort hotel的多为休闲度假游客。工作行程通常会由于工作的性质,变化较多,相对来说,旅游计划的变动会少一些,因为一般来说是提前做好了规划,请假等,取消计划的成本较高。这是否说明,酒店类型是否对订单取消率产生显著影响?下面进行分析:
假设现有的这119208条数据,是总数据的一个抽样,对酒店类型和订单取消情况这两个分类变量进行独立性检验。
原假设:H0:两个变量之间相互独立。
用spss进行交叉表分析:

结果表明,订单取消情况跟酒店类型有相关性,但是这种相关性并不是很强(克莱姆V=0.247)
5.2 用户角度
5.2.1 新老客户占比

由图看出,酒店的客户大多数为新客户,老客户只占3.15%,酒店需要考虑在这方面的提升,可以通过会员制度等,提高客户的回购率。
渠道分析


一共有7个渠道,总体平均价格ADR为81.9。
onlineTA渠道和Direct渠道的平均价格ADR较高,均超过115,其余均在100以内,Groups渠道和Corporate渠道的平均价格ADR稍低于平均水平,Complementary渠道的价格只有2.9,远远低于市场水平,对其进一步进行分析:
订单数量占比(市场份额)较大,
相关系数热力图
挑选并删除部分重合字段,做出相关系数热力图,查看影响订单取消率的主要因素有哪些。(satified字段:如果reserved_room_type等于assigned_room_type,则satified = 1,表示客户预订和酒店保留的房型一致,如果不相等,则satified=0,表示客户预订和酒店保留的房型不一致)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns#导入文件
file_path = r'G:\数据\hotel_bookings - 相关系数热力图.csv'
df = pd.read_csv(file_path)#复制副本
data_copy=df.copy(deep=True)cor = data_copy.corr()plt.figure(figsize=(23,23))
sns.heatmap(cor,annot=True,vmax=1,square=True,cmap='PuBu',linewidths=.5,fmt='.2f')
plt.savefig('./相关系数热力图.jpg')
plt.show()