python工匠学习小结
基于对python有一定的实践使用,缺乏编码/工程的规范性,在阅读python工匠书籍后进行部分的小结。
1、变量与注释
1.1 变量解包:
- 值语句左侧添加小括号(…),甚至可以一次展开多层嵌套数据;
- 用星号表达式(*variables)作为变量名,它便会贪婪地捕获多个值对象,并将捕获到的内容作为列表赋值给variables;
- 假如你想在解包赋值时忽略某些变量,就可以使用_作为变量名;python交互式命令行里,_变量还默认保存我们输入的上个表达式的返回值
# 解包案例 1
>>> attrs = [1, ['piglei', 100]]
>>> user_id, (username, score) = attrs
>>> user_id
1
>>> username
'piglei'#解包案例 2 ----动态解包
>>> data = ['piglei', 'apple', 'orange', 'banana', 100]
>>> username, *fruits, score = data
>>> username
'piglei'
>>> fruits
['apple', 'orange', 'banana']
>>> score
100#解包案例 3 ---切片赋值
# 切片赋值
>>> username, fruits, score = data[0], data[1:-1], data[-1]
# 两种变量赋值方式完全等价#解包案例 4 ---循环语句
>>> for username, score in [('piglei', 100), ('raymond', 60)]:
... print(username)
...
piglei
raymond# 解包案例 5
#忽略展开时的第二个变量
>>> author, _ = usernames
# 忽略第一个和最后一个变量之间的所有变量
>>> username, *_, score = data
以上解包操作也可用于循环语句,但是实际上并不太好使。
1.2 给变量注明类型
Python是动态类型语言,使用变量时不需要做任何类型声明,但是动态类型所带来的缺点是代码的可读性会因此大打折扣。使用类型注解,只需在变量后添加类型,并用冒号隔开即可,比如func(value:str)表示函数的value参数为字符串类型。
from typing import List
# List表示参数为列表类型,[int]表示里面的成员是整型
def remove_invalid(items: List[int]): """剔除 items 里面无效的元素"""... ...
“类型注解”只是一种有关类型的注释,不提供任何校验功能。要校验类型正确性,需要使用其他静态类型检查工具
类型注解带来的优势:
1.代码更易读,读代码时可以直接看到变量类型;
2.大部分的现代化IDE[插图]会读取类型注解信息,提供更智能的输入提示
3.类型注解配合mypy等静态类型检查工具,能提升代码正确性(13.1.5节)。
1.3 命名规则
1、遵循PEP 8原则:一是通过大小写界定单词的驼峰命名派CamelCase,二是通过下划线连接的蛇形命名派snake_case。
2、描述性强:体现出变量作用
3、尽可能短:为变量命名要结合代码情境和上下文
4、要匹配类型:体现出变量类型
5、超短命名:通常作为变量少用,目前做索引可以酌情用一下

1、在同一段代码内,不要出现多个相似的变量名,比如同时使用users、users1、users3这种序列;·
2、可以尝试换词来简化复合变量名,比如用is_special来代替is_not_normal;·
3、如果你苦思冥想都想不出一个合适的名字,请打开GitHub ( chatgpt 开源项目有太多可以学习的地方);
1.4 注释
文件、类、函数接口需要提供段落注释进行简要说明(接口注释),行注释采用 # 进行说明。
1、注释不是用来复述代码,而是描述该代码的作用,为什么要这么做,尽量提供那些读者无法从代码里读出来的信息
指引性注释并不提供代码里读不到的东西——假如没有注释,耐心读完所有代码,你也能知道代码做了什么事儿。指引性注释的主要作用是降低代码的认知成本,让我们能更容易理解代码的意图。无论代码写得多好,多么“自说明”,同读代码相比,读注释通常让人觉得更轻松。注释会让人们觉得亲切(尤其当注释是中文时),高质量的指引性注释确实会让代码更易读。有时抽象一个新函数,不见得就一定比一行注释加上几行代码更好。
2、接口文档主要是给函数(或类)的使用者看的,它最主要的存在价值,是让人们不用逐行阅读函数代码,也能很快通过文档知道该如何使用这个函数,以及在使用时有什么注意事项。在编写接口文档时,我们应该站在函数设计者的角度,着重描述函数的功能、参数说明等。而函数自身的实现细节,比如调用了哪个第三方模块、为何有性能问题等,无须放在接口文档里,放置于函数内部。
1.5 小贴士tips
1.5.1 、保持变量的一致性:
<1>名字一致性是指在同一个项目(或者模块、函数)中,对一类事物的称呼不要变来变去。
<2>类型一致性则是指不要把同一个变量重复指向不同类型的值
mypy工具
1.5.2、变量定义尽量靠近使用
这一点和C语言有点不一样,总是把变量声明放在最前面。python变量本身可读性稍差。变量定义移动到每段“各司其职”的代码头部,大大缩短了变量从初始化到被使用的“距离”。当读者阅读代码时,可以更容易理解代码的逻辑,而不是来回翻阅代码。函数不宜过长,超过200行需要进行功能拆分/切割
1.5.3、定义临时变量提升可读性
将复杂的表达式赋值为一个临时变量,代码更易读。
1.5.4、同一作用域内不要有太多变量
对局部变量分组并建模, 增加数据类,函数内的变量被更有逻辑地组织了起来,数量变少了许多
# 增加两个数据类,函数内的变量被更有逻辑地组织了起来,数量变少了许多
class ImportedSummary:"""保存导入结果摘要的数据类"""def __init__(self):self.succeeded_count = 0self.failed_count = 0class ImportingUserGroup:"""用于暂存用户导入处理的数据类"""def __init__(self):self.duplicated = []self.banned = []self.normal = []def import_users_from_file(fp):"""尝试从文件对象读取用户,然后导入数据库 :param fp: 可读文件对象:return: 成功与失败的数量"""importing_user_group = ImportingUserGroup()for line in fp:parsed_user = parse_user(line)# …… 进行判断处理,修改上面定义的importing_user_group 变量summary = ImportedSummary()# …… 读取 importing_user_group,写入数据库并修改成功与失败的数量return summary.succeeded_count, summary.failed_count
函数内变量的数量太多,通常意味着函数过于复杂,承担了太多职责。只有把复杂函数拆分为多个小函数,代码的整体复杂度才可能实现根本性的降低。
1.5.5、空行注释
即对函数内功能进行分类–增加可读性。
1.5.6、不要使用locals()
locals()是Python的一个内置函数,调用它会返回当前作用域中的所有局部变量。locals()看似简洁,但其他人在阅读代码时,为了搞明白模板渲染到底用了哪些变量,必须记住当前作用域里的所有变量。假如函数非常复杂,“记住所有局部变量”简直是个不可能完成的任务。使用locals()还有一个缺点,那就是它会把一些并没有真正使用的变量也一并暴露。
显式优于隐式
1.5.7、能不定义变量就别定义
把不必要的东西赋值为临时变量,反而会让代码显得啰唆,删掉赘语的句子,变得更精练、更易读。
1.5.8、先写注释,后写代码
要在函数名和短短几行注释里,把函数内代码所做的事情,高度浓缩地表达清楚。正因如此,接口注释其实完全可以当成一种协助你设计函数的前置工具。这个工具的用法很简单:假如你没法通过几行注释把函数职责描述清楚,那么整个函数的合理性就应该打一个问号。在写出一句有说服力的接口注释前,别写任何函数代码。
先写伪代码,进行打桩。然后再写具体的实现过程。
2、数值与字符串
2.1 数值基础
-
变量类型转换:int、float、str …
-
进制转换
n=input()
#16进制转换成10进制
print((int(n,16)))
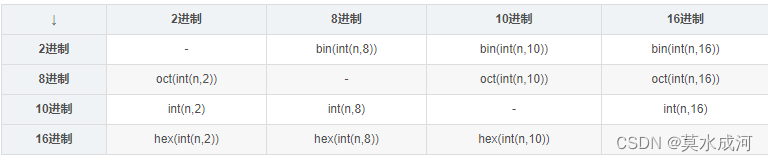
如果数字特别长,可以通过插入_分隔符来让它变得更易读:
- 浮点数精度问题
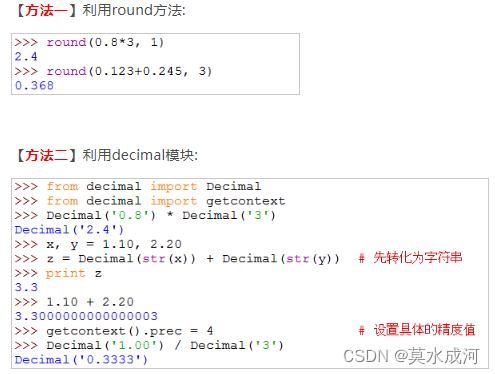
#0.1 + 0.2的最终结果多出来0.000…4
>>> 0.1 + 0.2
0.30000000000000004#在使用Decimal的过程中,大家需要注意:必须使用字符串来表示数字
>>> from decimal import Decimal
# 注意:这里的'0.1'和'0.2' 必须是字符串
>>> Decimal('0.1') + Decimal('0.2')
Decimal('0.3')
- 布尔值其实也是数字
>>> int(True), int(False)
(1, 0)
>>> True + 1
2# 把 False 当除数的效果和0 一样
>>> 1 / False
Traceback (most recent call last):File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
- 字符串常用操作
1、遍历一个字符串,将会逐个返回每个字符
2、对字符串进行切片假如你想反转一个字符串,可以使用切片操作或者reversed内置方法
3、切片最后一个字段使用-1,表示从后往前反序
4、reversed会返回一个可迭代对象,通过字符串的.join方法可以将它转换为字符串
username, score = 'piglei', 100
# 1. C 语言风格格式化
print('Welcome %s, your score is %d' % (username, score))
# 2. str.format
print('Welcome {}, your score is {:d}'.format(username, score))
# 3. f-string,最短最直观
print(f'Welcome {username}, your score is {score:d}')
# 输出:
# Welcome piglei, your score is 100
- 不常用但特别好用的字符串方法
#1、str.translate(table)方法有时也非常有用。它可以按规则一次性替换多个字符,使用它比调用多次replace方法更快也更简单
>>> s = '明明是中文,却使用了英文标点.'
# 创建替换规则表:',' -> ',', '.' -> '。'
>>> table = s.maketrans(',.', ',。')
>>> s.translate(table)
'明明是中文,却使用了英文标点。'#2、str.partition(sep)的功能是按照分隔符sep切分字符串
#返回一个包含三个成员的元组:(part_before, sep, part_after),它们分别代表分隔符前的内容、分隔符以及分隔符后的内容
#而spilt 不带有 分割符 sep2.2 其它
- 枚举
from enum import Enum
# 在定义枚举类型时,如果同时继承一些基础类型,比如int、str,
# 枚举类型就能同时充当该基础类型使用。比如在这里,UserType 就可以当作int 使用
class UserType(int, Enum):# VIP 用户VIP = 3# 小黑屋用户BANNED = 13
1、使用SQLAlchemy模块改写代码
2、使用Jinja2模板处理字符串
2.3 小贴士tips
2.3.1、保留计算
Python是一门解释型语言,但在解释器真正运行Python代码前,其实仍然有一个类似“编译”的加速过程:将代码编译为二进制的字节码。我们没法直接读取字节码,但利用内置的dis模块,可以将它们反汇编成人类可读的内容——类似一行行的汇编代码。用到复杂计算的数字字面量时,请保留整个算式吧。这样做对性能没有任何影响,而且会让代码更容易阅读。
使用dis 模块反编译字节码
2.3.2、使用特殊数字:“无穷大”
float(“-inf”)<任意数值< float(“inf”)
2.3.3、改善超长字符串的可读性
除了用斜杠\和加号+将长字符串拆分为几段,还有一种更简单的办法,那就是拿括号将长字符串包起来,之后就可以随意折行了。
s = ("This is the first line of a long string, ""this is the second line")# 如果字符串出现在函数参数等位置,可以省略一层括号
def main():logger.info("There is something really bad happened during the process. ""Please contact your administrator.")
2.3.4、多级缩进里出现多行字符串
可以用标准库textwrap来解决这个问题。dedent方法会删除整段字符串左侧的空白缩进。使用它来处理多行字符串以后,整段代码的缩进视觉效果就能保持正常了。
from textwrap import dedentdef main():if user.is_active:message = dedent("""\Welcome, today's movie list:- Jaw (1975)- The Shining (1980)- Saw (2004)""")
2.3.5、别忘了以r开头的字符串内置方法
比如rsplit()就是split()的镜像“逆序”方法
2.3.6、不要害怕字符串拼接
以前Python里的字符串是不可变对象,因此每拼接一次字符串都会生成一个新对象,触发新的内存分配,效率非常低。但是,如今,使用+=拼接字符串基本已经和"".join(str_list)一样快了。
2.3.7、dis & timeit
如果需要验证某个“经验之谈”,dis和timeit两个优秀的工具可以帮到你:前者能让你直接查看编译后的字节码,后者则能让你方便地做性能测试
3、容器类型
1、元组(tuple)和列表非常类似,但跟列表不同,它不能被修改
2、每个类实例的所有属性,就都存放在一个名为dict的字典
3、集合(set)最大的特点是成员不能重复,所以经常用来去重(剔除重复元素)
class Foo:def __init__(self, value):self.value = valuefoo = Foo('bar')
print(foo.__dict__, type(foo.__dict__))
#{'value': 'bar'} <class 'dict'>
可变(mutable):列表、字典、集合。·
不可变(immutable):整数、浮点数、字符串、字节串、元组。(没法修改一个已经存在的字符串对象)
def add_str(in_func_obj):print(f'In add [before]: in_func_obj="{in_func_obj}"')in_func_obj += ' suffix'print(f'In add [after]: in_func_obj="{in_func_obj}"')orig_obj = 'foo'
print(f'Outside [before]: orig_obj="{orig_obj}"')
add_str(orig_obj)
print(f'Outside [after]: orig_obj="{orig_obj}"')'''
#同样的示例,如果参数是列表,函数内的+=操作居然可以修改原始变量的值
Outside [before]: orig_obj="foo"
In add [before]: in_func_obj="foo"
In add [after]: in_func_obj="foo suffix"# 重要:这里的orig_obj 变量还是原来的值
Outside [after]: orig_obj="foo"
'''
(1)值传递(pass-by-value):调用函数时,传过去的是变量所指向对象(值)的拷贝,因此对函数内变量的任何修改,都不会影响原始变量——对应orig_obj是字符串时的行为。
(2)引用传递(pass-by-reference):调用函数时,传过去的是变量自身的引用(内存地址),因此,修改函数内的变量会直接影响原始变量——对应orig_obj是列表时的行为。
Python在进行函数调用传参时,采用的既不是值传递,也不是引用传递,而是传递了“变量所指对象的引用”(pass-by-object-reference)。
3.1 列表
- 内置函数list(iterable)则可以把任何一个可迭代对象转换为列表。删除列表中的某些内容,可以直接使用del语句
>>> list('foo')
['f', 'o', 'o']#通过索引获取内容,如果索引越界,会抛出 IndexError异常
>>> numbers[2]
3# 使用切片获取一段内容
>>> numbers[1:]
[2, 3, 4]# 删除列表中的一段内容
>>> del numbers[1:]
>>> numbers
[1]
- 在遍历列表时获取下标,选择用内置函数enumerate()包裹列表对象。enumerate()适用于任何“可迭代对象”,因此它不光可以用于列表,还可以用于元组、字典、字符串等其他对象。
>>> names = ['foo', 'bar']
>>> for index, s in enumerate(names):
... print(index, s)
...
0 foo
1 bar#enumerate()接收一个可选的start参数,用于指定循环下标的初始值(默认为0)
>>> for index, s in enumerate(names, start=10):
... print(index, s)
...
10 foo
11 bar
- 列表推导式
def remove_odd_mul_100(numbers):"""剔除奇数并乘以100"""results = []for number in numbers:if number % 2 == 1:continueresults.append(number * 100)return results#用一个表达式完成4件事情
#
# 1. 遍历旧列表:for n in numbers
# 2. 对成员进行条件过滤:if n % 2 == 0
# 3. 修改成员: n * 100
# 4. 组装新的结果列表
#
results = [n * 100 for n in numbers if n % 2 == 0]
3.2 元组
- 函数可以一次返回多个结果,这其实是通过返回一个元组来实现的;函数返回值一次赋值给多个变量时,其实就是对元组做了一次解包操作:
def get_rectangle():"""返回长方形的宽和高"""width = 100height = 20return width, height# 获取函数的多个返回值
result = get_rectangle()
print(result, type(result))
# 输出:
# (100, 20) <class 'tuple'>width, height = get_rectangle()
# 可以理解为:width, height = (width, height)- 没有“元组推导式”
>>> results = (n * 100 for n in range(10) if n % 2 == 0)
>>> results
<generator object <genexpr> at 0x10e94e2e0>
#并没有生成元组,而是返回了一个生成器(generator)对象。生成器仍然是一种可迭代类型。
>>> results = tuple((n * 100 for n in range(10) if n % 2 == 0))
>>> results
(0, 200, 400, 600, 800)
- 元组经常用来存放结构化数据–具名元组
1、初始化具名元组
2、指定字段名称来初始化
3、可以像普通元组一样,通过数字索引访问成员
4、具名元组也支持通过名称来访问成员
5、普通元组一样,具名元组是不可变的
用名字访问成员(rect.width)比用普通数字(rect[0])更易读、更好记
思考:对于列表/字典成员属性,是否也可以对成员“具名”,增强代码的可读性!
from collections import namedtuple
Rectangle = namedtuple('Rectangle', 'width,height') >>> rect = Rectangle(100, 20) ➊
>>> rect = Rectangle(width=100, height=20) ➋
>>> print(rect[0]) ➌
100
>>> print(rect.width) ➍
100
>>> rect.width += 1 ➎
...
AttributeError: can't set attribute#typing.NamedTuple和类型注解语法
class Rectangle(NamedTuple):width: intheight: intrect = Rectangle(100, 20)
#写法虽然给width和height加了类型注解,但Python在执行时并不会做真正的类型校验。也就是说,下面这段代码也能正常执行
#提供错误的类型来初始化
rect_wrong_type = Rectangle('string', 'not_a_number')
3.3 字典
字典在底层使用了哈希表(hashtable)数据结构
- items() 函数以列表返回可遍历的(键, 值) 元组数组
#遍历获取字典所有的key
>>> for key in movie:
... print(key, movie[key])
# 一次获取字典的所有 key: value 键值对
>>> for key, value in movie.items():
... print(key, value)
- 直接操作,但是捕获KeyError异常。
>>> try:
... rating = movie['rating']
... except KeyError:
... rating = 0
...
- 使用setdefault取值并修改
>>> d = {'title': 'foobar'}
>>> d.setdefault('items', []).append('foo') ➊
>>> d
{'title': 'foobar', 'items': ['foo']}
>>> d.setdefault('items', []).append('bar') ➋
>>> d
{'title': 'foobar', 'items': ['foo', 'bar']}
- 使用pop方法删除不存在的键
try:del d[key]
except KeyError:# 忽略 key 不存在的情况pass# 调用pop方法时传入默认值None,在键不存在的情况下也不会产生任何异常
d.pop(key, None)
- 字典推导式
>>> d1 = {'foo': 3, 'bar': 4}
>>> {key: value * 10 for key, value in d1.items() if key == 'foo'}
{'foo': 30}
3.4 集合
集合是一种无序的可变容器类型,它最大的特点就是成员不能重复。集合里装的是一维的值{value, …},而不是键值对{key: value, …}。集合最重要的两个特征——去重与无序。初始化一个空集合,只能调用set()方法,因为{}表示的是一个空字典,而不是一个空集合。
#正确初始化一个空集合
>>> empty_set = set()#集合也有自己的推导式语法
>>> nums = [1, 2, 2, 4, 1]
>>> {n for n in nums if n < 3}
{1, 2}
- 不可变的集合frozenset
集合是一种可变类型,使用.add()方法可以向集合追加新成员。你想要一个不可变的集合,可使用内置类型frozenset,它和普通set非常像,只是少了所有的修改类方法。
>>> f_set = frozenset(['foo', 'bar'])
>>> f_set.add('apple')
# 报错:没有 add/remove 那些修改集合的方法
AttributeError: 'frozenset' object has no attribute 'add'
- 集合运算
集合的最大独特之处在于:你可以对其进行真正的集合运算,比如求交集、并集、差集,等等。所有操作都可以用两种方式来进行:方法和运算符。
>>> fruits_1 = {'apple', 'orange', 'pineapple'}
>>> fruits_2 = {'tomato', 'orange', 'grapes', 'mango'}#使用& 运算符(求交集)
>>> fruits_1 & fruits_2
{'orange'}
# 使用intersection 方法完成同样的功能
>>> fruits_1.intersection(fruits_2)#使用| 运算符(求并集)
>>> fruits_1 | fruits_2
{'mango', 'orange', 'grapes', 'pineapple', 'apple', 'tomato'}
# 使用union 方法完成同样的功能
>>> fruits_1.union(fruits_2)#使用- 运算符(求差集)
>>> fruits_1 - fruits_2
{'apple', 'pineapple'}
# 使用difference 方法完成同样的功能
>>> fruits_1.difference(fruits_2)
- 集合只能存放可哈希对象
集合里只能存放“可哈希”(hashable)的对象。假如把不可哈希的对象(比如上面的列表)放入集合,程序就会抛出TypeError异常。字典的键也只能是可哈希的对象。
1、不可变的内置类型都是可哈希的,如str、int、tuple、frozenset
2、可变的内置类型都无法正常计算哈希值。如列表/字典
3、用户定义的所有对象默认都是可哈希的
4、对于不可变容器类型(tuple, frozenset),仅当它的所有成员都不可变时,它自身才是可哈希的;
3.5 深拷贝与浅拷贝
>>> nums = [1, 2, 3, 4]
>>> nums_copy = nums
>>> nums[2] = 30
#完成修改-。-
>>> nums_copy
[1, 2, 30, 4]
- 浅拷贝
1、最通用的办法是使用copy模块下的copy()方法
>>> import copy
>>> nums_copy = copy.copy(nums)
>>> nums[2] = 30
# 修改不再相互影响
>>> nums, nums_copy
([1, 2, 30, 4], [1, 2, 3, 4])2、推导式也可以产生一个浅拷贝对象
>>> d = {'foo': 1}
>>> d2 = {key: value for key, value in d.items()}
>>> d['foo'] = 2
>>> d, d2
({'foo': 2}, {'foo': 1})3、各容器类型的内置构造函数
>>> d2 = dict(d.items()) ➊
>>> nums_copy = list(nums) ➋4、支持切片操作的容器类型——比如列表、元组,对其进行全切片
#nums_copy会变成 nums的浅拷贝
>>> nums_copy = nums[:]5、类型自身就提供了浅拷贝方法
#列表有 copy方法
>>> num = [1, 2, 3, 4]
>>> nums.copy()
[1, 2, 3, 4]
# 字典也有 copy 方法
>>> d = {'foo': 'bar'}
>>> d.copy()
{'foo': 'bar'}
- 深拷贝





![[第一步]homekit智能家居,homebridge与homebridge-aqara通信协议](https://img-blog.csdn.net/20161030104357945?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)