前言
关于国内拉取不到docker镜像的问题,可以利用Github Action将需要的镜像转存到阿里云私有仓库,然后再通过阿里云私有仓库去拉取就可以了。
参考项目地址:使用Github Action将国外的Docker镜像转存到阿里云私有仓库
一、Docker简介
Docker 是一个开源的应用容器引擎工具,使用Docker可以在同一个操作系统下,利用同一套操作系统资源,创建相互隔离的运行时环境,即容器,容器完全使用沙箱机制,相互之间不会有任何接口。
Docker的主要作用是将应用程序及其运行环境和依赖,打包成一个可移植包,即镜像;方便应用程序的部署和维护。
二、名词解释:
Docker引擎:Docker引擎是Docker的核心,负责镜像创建,管理容器运行,停止等工作。
镜像:将应用程序,及其运行环境和依赖整合到一起打成的包,可以理解为类似操作系统的镜像(iso文件)
容器:容器是通过镜像来启动和运行的,容器是镜像的运行实例,Docker容器是一个独立运行的执行单元,可以将其看作一个极简的Linux系统环境(包括root权限、进程空间、用户空间和网络空间等),以及运行在其中的应用程序;各个容器之间是是相互隔离的,互不影响。
仓库(Docker Hub):存放镜像的地方,类似于代码仓库;Docker Hub是一个官方的,用于存储和共享Docker镜像的公共仓库。开发者可以在Docker Hub上找到各种各样的官方和社区创建的镜像,也可以将自己的镜像上传到这个平台。
容器编排(Docker Compose、K8s): Docker Compose是一个工具,允许定义和运行多个Docker容器的配置。通过一个简单的YAML文件,可以定义应用程序的各个组件、服务和它们之间的关系。
三、Docker安装
官方文档:
Install Docker Desktop on Linux
打不开链接请使用魔法 !
笔者使用的debian操作系统,直接使用官方提供的脚本安装:
curl -fsSL https://get.docker.com -o get-docker.sh四、Dockerfile的使用
在构建镜像时,可以创建一个Dockerfile文件,在文件中定义构建镜像的指令(如基础镜像、拷贝文件、暴露端口等)。
常用指令:
1.FROM:指定构建镜像时需要使用的基础镜像,可以指定基础镜像的版本,格式:镜像:tag
2.COPY:拷贝文件或文件夹到指定位置
3.ADD:拷贝文件或文件夹到指定位置,若拷贝的文件是压缩文件(如 .tar, .tar.gz, .zip 等)
将会自动解压;若是从URL下载文件,ADD 还支持从URL来源复制文件,这意味
着可以直接从互联网上下载文件并将其添加到镜像中
4.RUN:构建镜像时需要运行的shell命令
5.EXPOSE:构建的镜像在运行时对外暴露的端口号,在运行容器时,指定-p参数中的容
器端口可以覆盖此参数(-p 宿主机端口:容器端口)
6.WORKDIR:构建的镜像在运行时,终端登录进来默认的工作目录
7.CMD:构建的镜像,在容器启动时要运行的命令,参数为数组形式(CMD ["命令","参数1","参数2",...])
8.MAINTAINER:指定镜像创建者信息
9.ENV:设置环境变量
10.USER:构建的镜像在运行时,设置容器进程的一些用户
eq:
#基于nginx最新版本为基础镜像,必须放在第一句
FROM nginx:latestMAINTAINER "author by Kevin"#在容器中创建一个html目录
RUN mkdir /html#设置登入容器后,shell默认工作目录为html
WORKDIR /html#复制当前目录下的所有内容到容器当前工作目录(html)
COPY . .#复制当前目录(Dockerfile所在目录)下的index.html文件到html目录下
COPY ./index.html /html#复制当前目录下hls目录下的所有文件到html目录下的hls目录(若没有hls目录将自动创建)
COPY ./hls /html/hls#删除nginx的默认配置文件default.conf
RUN rm /etc/nginx/conf.d/default.conf#复制当前目录下的default.conf文件到路径/etc/nginx/conf.d下
ADD default.conf /etc/nginx/conf.d#对外暴露容器端口为8080
EXPOSE 8080#赋予文件install.sh执行权限
RUN chmod -v +x /install.sh#容器启动时,运行bash程序并执行install.sh脚本
CMD ["/bin/bash","install.sh"]在执行复制操作时,若希望Dockerfile忽略某些目录或文件,可在当前目录下创建一个 .dockerignore文件,如:
#忽略node_modules目录
node_modules#忽略package-lock.json文件
package-lock.json五、Docker常用命令
1.Docker服务启停
# 启动Docker服务
systemctl start docker# 停止Docker服务
systemctl stop docker# 重启服务
systemctl restart docker# 设置开机自启
systemctl enable docker
2.Docker查看命令
#查看docker版本
docker --version
#或
docker -v#查看docker运行状态
systemctl status docker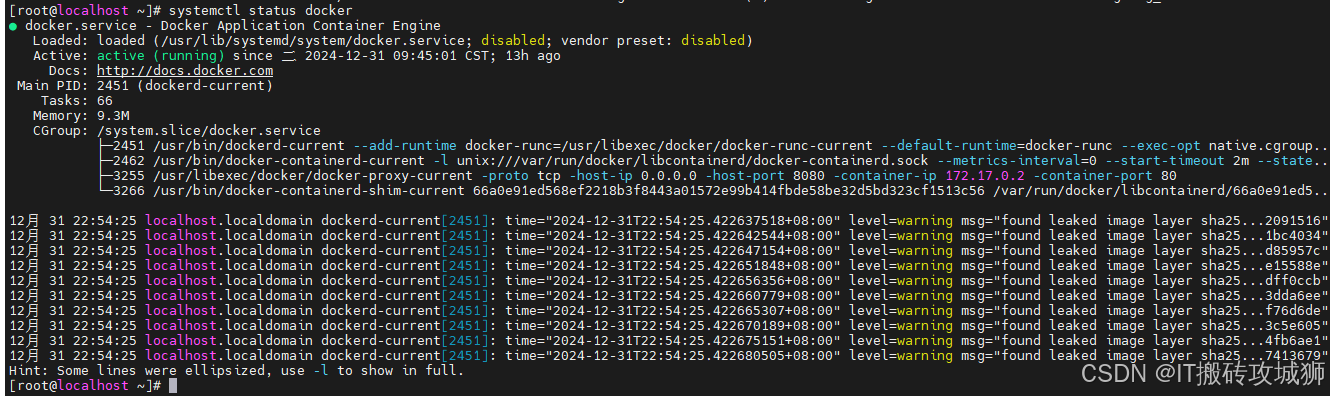
#查看docker概要信息
docker info#查看容器、镜像、网络、卷等详细信息,返回JSON格式的结果
docker inspect 容器id/容器名称/镜像id/镜像名/卷名#查看容器日志
docker logs <容器id或容器名>#查看正在运行的容器
docker ps#查看最近创建的容器
docker -ps -l#查看正在运行的容器,只显示id
docker ps -q#查看所有运行的容器,包含历史运行过的容器
docker ps -a#注:容器id不用输完整,在保证不会重复的情况下,输前几位就行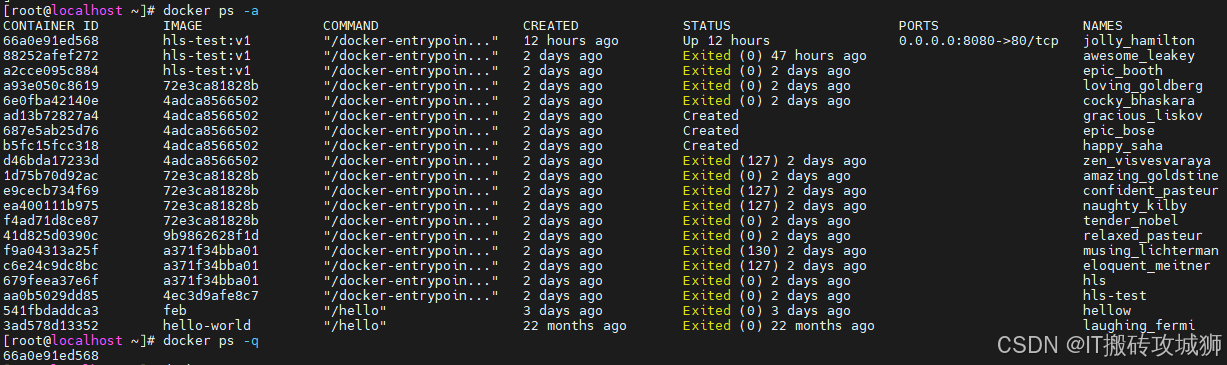
#查看容器端口映射情况
docker port 容器id#查看运行中的容器资源占用情况
docker stats 容器id(可以为多个id,空格分割,或者不传查看所有容器)#查看容器内部运行的进程列表
docker top 容器id#查看本地镜像列表
docker images#查看本地镜像列表,包含历史镜像
docker images -a#查看本地镜像列表,只显示id
docker images -q#在镜像仓库搜索镜像
docker search 镜像名称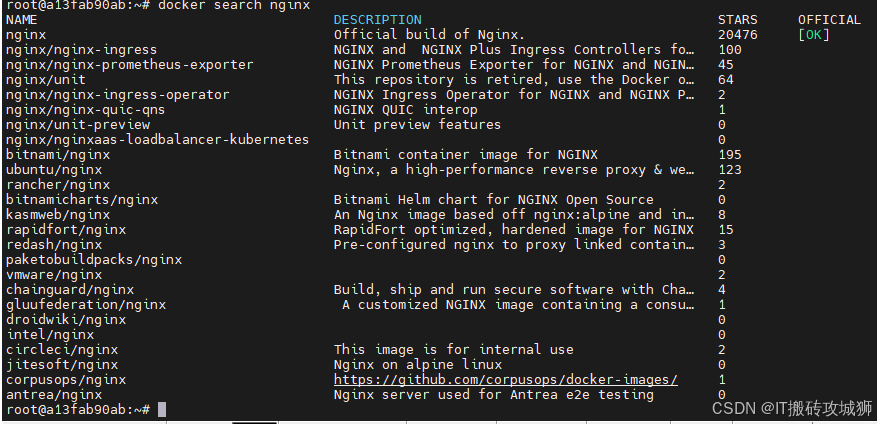
#查看容器/镜像/数据卷所占用的空间大小,数量等
docker system df
3.镜像操作
3.1.镜像创建
#构建镜像,"."表示使用当前目录下的Dockerfile构建
docker build -t 镜像名:tag .
#eq: docker build -t test-image:v1.0#从镜像仓库拉取镜像到本地环境,若不指定版本将拉取最新版本
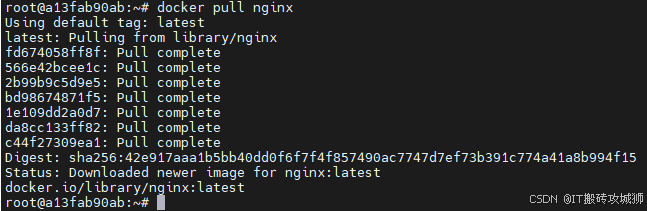
docker pull 镜像名:版本
#eq:docker pull nginx#镜像仓库登录
docker login --username=<your-account-name> <your-repo-address>
3.2.镜像删除
#删除镜像,可删除多个镜像,镜像id用空格分割
docker rmi 镜像id:tag#强制删除镜像
docker rmi 镜像id -f#删除所有镜像,$()的作用可以理解为执行一个子查询
docker rmi -f $(docker images -aq)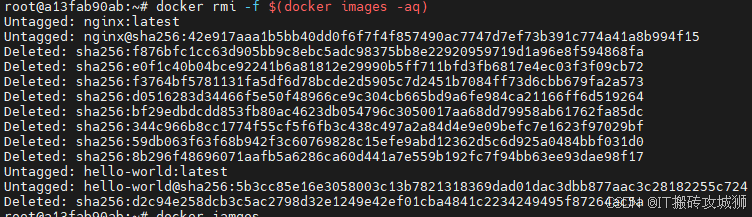
3.3.镜像导入导出
#保存hls-test镜像的v1版本到home目录下,并命名为hls.tar归档文件
docker save hls-test:v1 > /home/hls.tar
#加载hls.tar归档文件镜像
docker load < hls.tar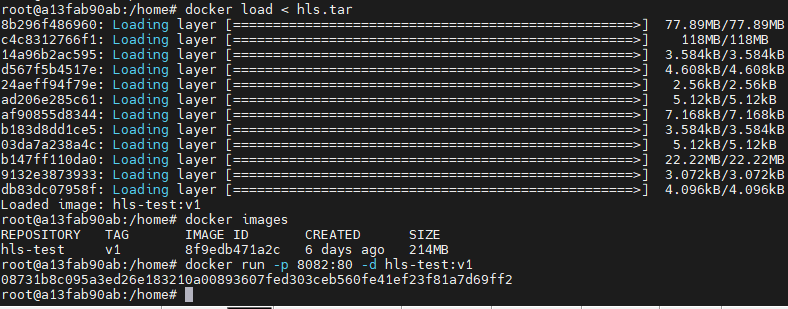
4.容器操作
4.1.容器运行
语法:docker run [options] image:tag [command]
参数:
--name=“容器新名字”
-d:后台运行容器
-i:以交互模式运行容器 interactive
-t:为容器重新分配一个为输入终端
-P:随机终端口映射,大写P
-p:指定终端口映射,小写p,格式:-p <宿主机端口>:<容器端口>
-v:容器目录挂载或卷映射,格式:<宿主机目录路径>:<容器目录路径>或
<卷名>:<容器目录路径>
eq:
#用hls-test:v1镜像,以后台模式运行一个容器,并将容器的80端口映射到宿主机的8080端口
#并指定容器名为test,将宿主机的home/html目录(自动创建)挂载到容器html/hls目录
docker run --name test -p 8080:80 -v /home/html:/html/hls -d hls-test:v1#使用卷映射方式替代目录挂载,卷名nginx_html(宿主机自动创建,默认在/var/lib/docker/volumes目录下)
docker run --name test -p 8080:80 -v nginx_html:/html/hls -d hls-test:v1

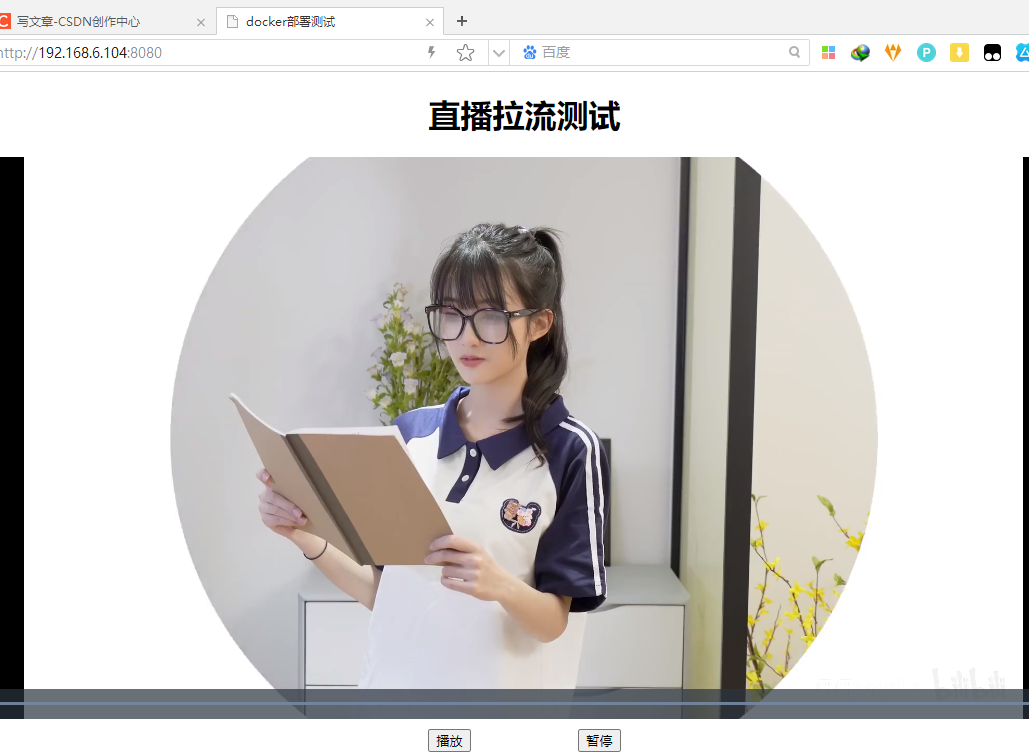
#交互式运行容器,可以进入到容器内部,执行一些操作
#在容器中输入exit可退出容器,退出同时容器也会停止运行
#按快捷键ctrl+p+q可退出容器,退出后容器不会停止运行
docker run -p 8080:80 -it hls-test:v1 /bin/bash
#退出容器后可再次进入容器(前提是容器没有停止)
docker exec -it <容器id> bash
docker exec -it <容器id> /bin/bash
#或
docker attach <容器id>#注:exec命令是在容器中打开新的终端,不会启动新进程,用exit退出后,容器不会停止
#attach命令是直接进入容器的终端,用exit退出后,会导致容器停止

4.2.容器启停
#停止正在运行的容器
docker stop <容器id或容器名>#停止所有正在运行的容器
docker stop $(docker ps -q)#重启容器
docker restart <容器id或容器名>#启动已停止的容器
docker start <容器id或容器名>#强制停止容器
docker kill <容器id或容器名>#强制停止所有容器
docker kill $(docker ps -a -q)#注:容器id不用输完整,在保证不会重复的情况下,输前几位就行4.3.容器删除
#删除已停止的容器
docker rm <容器id或容器名>#正在运行的容器需要强制删除
docker rm -f <容器id或容器名>#清理所有没有在运行状态的容器
docker continer prune#删除正在运行的所有容器
docker rm -f $(docker ps -a -q)
#或
docker ps -q -a | xargs docker rm -f
4.4.文件拷贝
#拷贝容器中的index.html文件到宿主机的home目录
docker cp <容器id>:容器内index.html的路径 /home
4.5.容器导入导出
#导出正在运行的容器为一个tar归档文件
docker export <容器id> -o 文件名.tar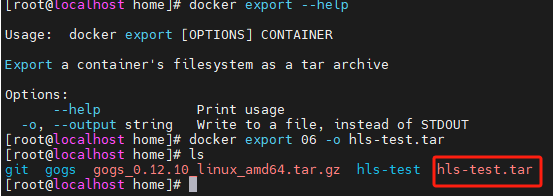
#将hls-test.tar归档文件中的内容导入为一个新的镜像,-m参数表示注释
#短横线“-”后的hls-test:v1分别表示镜像名称和版本(tag)
cat hls-test.tar | docker import -m 导入测试 - hls-test:v1
六、Docker网络
1.基本网络的使用
每台机器在安装了docker后,都会创建一个虚拟的docker0网卡,用于容器之间的通信

有了这个网卡,后续每创建一个容器都会分配一个ip地址,docker0网卡的ip(172.17.0.1)将作为容器的网关地址;使用以下命令可查看容器ip
docker inspect <容器id或容器名称>
进入到另一个运行的容器中,可以通过ip地址(172.17.0.3)加端口(容器端口)访问这个容器的内容
eq:

2.自定义网络
docker支持创建自定义网络
#创建一个名为docker_net的网络,网段参数可以省略
docker network create <网段> docker_net#查看docker网络列表
docker network ls#删除创建的自定义网络
docker network rm <网卡id或者名称>

创建自定义网络后,在启动容器时可以指定容器使用这个网络,并且指定容器的名称,那么这样启动的容器可以通过以下方式访问
http://容器名称:端口