首先说一下,今日头条的面试主要分为三轮到四轮,如果是旺季面三轮,首先是基础面试,基本面试一般10个题左右,最近面试了一下今日头条的移动Android资深工程师,记录下。
第一面是北京的开发进行视频面试,有理论和编程题组成。用的是在线编程工具,如下图。

第一面
1,请编程实现单例模式,懒汉和饱汉写法。
//饱汉写法
public static Singleton getInstance() { if (singleton == null) { synchronized (Singleton.class) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; }//懒汉写法private static final Singleton1 single = new Singleton1(); //静态工厂方法 public static Singleton1 getInstance() { return single; } 2,请编程实现Java的生产者-消费者模型
看到这个有点懵逼,要是大学毕业的时候写这个肯定没问题,这都工作多年,这也只能按照自己的思路写了。这里使用synchronized锁以及wait notify实现一个比较简单的。
import java.io.IOException;public class WaitAndNotify
{public static void main(String[] args) throws IOException{Person person = new Person();new Thread(new Consumer("消费者一", person)).start();new Thread(new Consumer("消费者二", person)).start();new Thread(new Consumer("消费者三", person)).start();new Thread(new Producer("生产者一", person)).start();new Thread(new Producer("生产者一", person)).start();new Thread(new Producer("生产者一", person)).start();}
}class Producer implements Runnable
{private Person person;private String producerName;public Producer(String producerName, Person person){this.producerName = producerName;this.person = person;}@Overridepublic void run(){while (true){try{person.produce();} catch (InterruptedException e){e.printStackTrace();}}}}class Consumer implements Runnable
{private Person person;private String consumerName;public Consumer(String consumerName, Person person){this.consumerName = consumerName;this.person = person;}@Overridepublic void run(){try{person.consume();} catch (InterruptedException e){e.printStackTrace();}}}class Person
{private int foodNum = 0;private Object synObj = new Object();private final int MAX_NUM = 5;public void produce() throws InterruptedException{synchronized (synObj){while (foodNum == 5){System.out.println("box is full,size = " + foodNum);synObj.wait();}foodNum++;System.out.println("produce success foodNum = " + foodNum);synObj.notifyAll();}}public void consume() throws InterruptedException{synchronized (synObj){while (foodNum == 0){System.out.println("box is empty,size = " + foodNum);synObj.wait();}foodNum--;System.out.println("consume success foodNum = " + foodNum);synObj.notifyAll();}}
}关于更多的知识可以https://zhuanlan.zhihu.com/p/20300609
3,HashMap的内部结构? 内部原理?
关于HashMap的问题,不再详述,这方面的资料也挺多,不多需要注意的是Java1.7和1.8版本HashMap内部结构的区别。
4,请简述Android事件传递机制, ACTION_CANCEL事件何时触发?
关于第一个问题,不做任何解释。
关于ACTION_CANCEL何时被触发,系统文档有这么一种使用场景:在设计设置页面的滑动开关时,如果不监听ACTION_CANCEL,在滑动到中间时,如果你手指上下移动,就是移动到开关控件之外,则此时会触发ACTION_CANCEL,而不是ACTION_UP,造成开关的按钮停顿在中间位置。
意思是当滑动的时候就会触发,不知道大家搞没搞过微信的长按录音,有一种状态是“松开手指,取消发送”,这时候就会触发ACTION_CANCEL。
5,Android的进程间通信,Liunx操作系统的进程间通信。
关于这个问题也是被问的很多,此处也不做解释。
6,JVM虚拟机内存结构,以及它们的作用。
这个问题也比较基础,JVM的内存结构如下图所示。
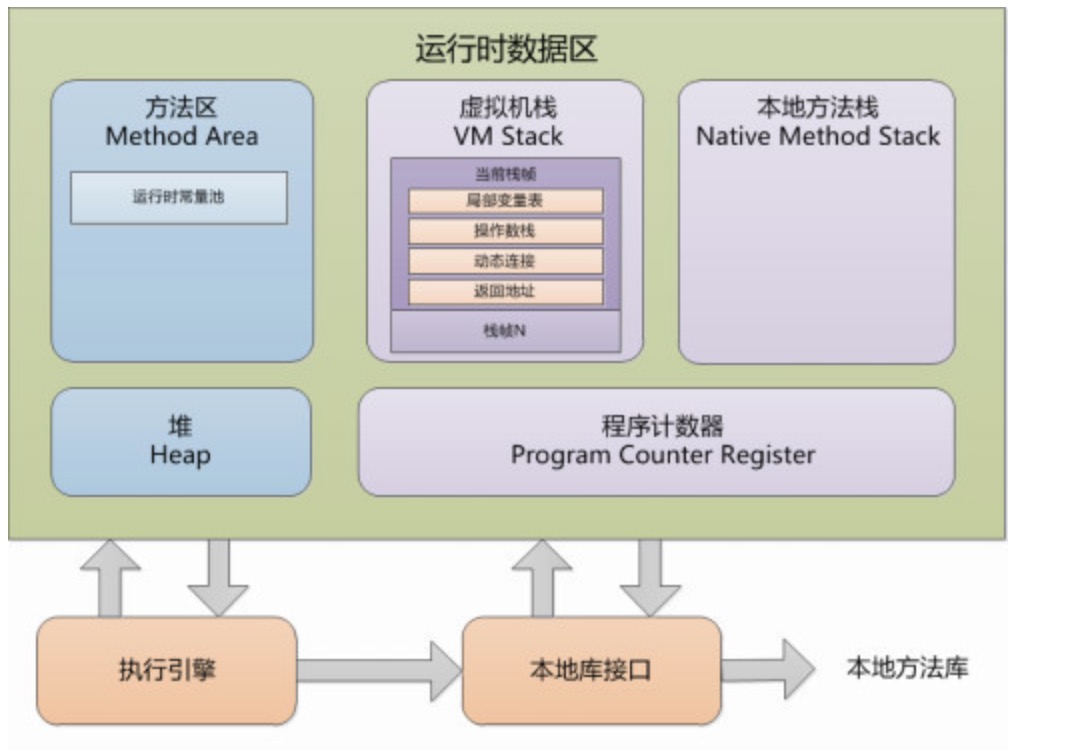
可以通过下面的问题来学习:
https://www.cnblogs.com/jiyukai/p/6665199.html
https://www.zhihu.com/question/65336620
7,简述Android的View绘制流程,Android的wrap_content是如何计算的。
8,有一个整形数组,包含正数和负数,然后要求把数组内的所有负数移至正数的左边,且保证相对位置不变,要求时间复杂度为O(n), 空间复杂度为O(1)。例如,{10, -2, 5, 8, -4, 2, -3, 7, 12, -88, -23, 35}变化后是{-2, -4,-3, -88, -23,5, 8 ,10, 2, 7, 12, 35}。
要实现上面的效果有两种方式:
第一种:两个变量,一个用来记录当前的遍历点,一个用来记录最左边的负数在数组中的索引值。然后遍历整个数组,遇到负数将其与负数后面的数进行交换,遍历结束,即可实现负数在左,正数在右。
第二种:两个变量记录左右节点,两边分别开始遍历。左边的节点遇到负值继续前进,遇到正值停止。右边的节点正好相反。然后将左右节点的只进行交换,然后再开始遍历直至左右节点相遇。这种方式的时间复杂度是O(n).空间复杂度为O(1)
//方法1public void setParted(int[] a){ int temp=0; int border=-1; for(int i=0;i<a.length;i++){ if(a[i]<0){ temp=a[i]; a[i]=a[border+1]; a[border+1]=temp; border++; } } for(int j=0;j<a.length;j++){ System.out.println(a[j]); } }
//方法2
public void setParted1(int[] a,int left,int right){ if(left>=right||left==a.length||right==0){ for(int i=0;i<a.length;i++){ System.out.println(a[i]); } return ; } while(a[left]<0){ left++; } while(a[right]>=0){ right--; } if(left>=right||left==a.length||right==0){ for(int i=0;i<a.length;i++){ System.out.println(a[i]); } return; } swap(a,left,right); left++; right--; setParted1(a,left,right); } private void swap(int a[],int left,int right){ int temp=0; temp=a[left]; a[left]=a[right]; a[right]=temp; } public static void main(String[] args) { int a[]={1,2,-1,-5,-6,7,-7,-10}; new PartTest().setParted1(a,0,a.length-1); } 显然,第二种实现的难点比较高,不过只要此种满足条件。
第二面
1,bundle的数据结构,如何存储,既然有了Intent.putExtra,为啥还要用bundle。
bundle的内部结构其实是Map,传递的数据可以是boolean、byte、int、long、float、double、string等基本类型或它们对应的数组,也可以是对象或对象数组。当Bundle传递的是对象或对象数组时,必须实现Serializable 或Parcelable接口。
2,android的IPC通信方式,是否使用过
这方面的资料比较多,也不方便阐述
3,Android的多点触控如何传递
核心类
4,asynctask的原理
AsyncTask是对Thread和Handler的组合包装。
https://blog.csdn.net/iispring/article/details/50670388
5,android 图片加载框架有哪些,对比下区别
主要有4种:Android-Universal-Image-Loader、Picasso、Glide和Fresco
Android-Universal-Image-Loader
优点:支持下载进度监听(ImageLoadingListener) * 可在View滚动中暂停图片加载(PauseOnScrollListener) * 默认实现多种内存缓存算法(最大最先删除,使用最少最先删除,最近最少使用,先进先删除,当然自己也可以配置缓存算法)
缺点:2015年之后便不再维护,该库使用前需要进行配置。
Picasso
优点:包较小(100k) * 取消不在视野范围内图片资源的加载 * 使用最少的内存完成复杂的图片转换 * 自动添加二级缓存 * 任务调度优先级处理 * 并发线程数根据网络类型调整 * 图片的本地缓存交给同为Square出品的okhttp处理,控制图片的过期时间。
缺点:
功能较为简单,自身无法实现“本地缓存”功能。
Glide
优点:多种图片格式的缓存,适用于更多的内容表现形式(如Gif、WebP、缩略图、Video) * 生命周期集成(根据Activity或者Fragment的生命周期管理图片加载请求) * 高效处理Bitmap(bitmap的复用和主动回收,减少系统回收压力) * 高效的缓存策略,灵活(Picasso只会缓存原始尺寸的图片,Glide缓存的是多种规格),加载速度快且内存开销小(默认Bitmap格式的不同,使得内存开销是Picasso的一半)。
缺点:方法较多较复杂,因为相当于在Picasso上的改进,包较大(500k),影响不是很大。
Fresco
缺点:最大的优势在于5.0以下(最低2.3)的bitmap加载。在5.0以下系统,Fresco将图片放到一个特别的内存区域(Ashmem区) * 大大减少OOM(在更底层的Native层对OOM进行处理,图片将不再占用App的内存) * 适用于需要高性能加载大量图片的场景。
缺点:包较大(2~3M) * 用法复杂 * 底层涉及c++领域
5,主线程中的Looper.loop()一直无限循环为什么不会造成ANR?
ActivityThread.java 是主线程入口的类,ActivityThread.java 的main函数的内容如下。
Looper.prepareMainLooper();...//创建Looper和MessageQueueLooper.prepareMainLooper();ActivityThread thread = new ActivityThread();thread.attach(false);if (sMainThreadHandler == null) {sMainThreadHandler = thread.getHandler();}if (false) {Looper.myLooper().setMessageLogging(newLogPrinter(Log.DEBUG, "ActivityThread"));}// End of event ActivityThreadMain.Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);//轮询器开始轮询Looper.loop();然后再看Looper.loop()的源码,可以发现:
while (true) {
//取出消息队列的消息,可能会阻塞
Message msg = queue.next(); // might block
…
//解析消息,分发消息
msg.target.dispatchMessage(msg);
…
}显然,ActivityThread的main方法主要就是做消息循环,一旦退出消息循环,那么你的应用也就退出了。那么这个死循环不会造成ANR异常呢?
说明:因为Android 的是由事件驱动的,looper.loop() 不断地接收事件、处理事件,每一个点击触摸或者说Activity的生命周期都是运行在 Looper.loop() 的控制之下,如果它停止了,应用也就停止了。只能是某一个消息或者说对消息的处理阻塞了 Looper.loop(),而不是 Looper.loop() 阻塞它。也就说我们的代码其实就是在这个循环里面去执行的,当然不会阻塞了。来看一下handleMessage的源码:
public void handleMessage(Message msg) {
if (DEBUG_MESSAGES) Slog.v(TAG, “>>> handling: ” + codeToString(msg.what));
switch (msg.what) {
case LAUNCH_ACTIVITY: {
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, “activityStart”);
final ActivityClientRecord r = (ActivityClientRecord) msg.obj;
r.packageInfo = getPackageInfoNoCheck(r.activityInfo.applicationInfo, r.compatInfo);
handleLaunchActivity(r, null);
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
}
break;
case RELAUNCH_ACTIVITY: {
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, “activityRestart”);
ActivityClientRecord r = (ActivityClientRecord) msg.obj;
handleRelaunchActivity(r);
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
}
break;
case PAUSE_ACTIVITY:
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, “activityPause”);
handlePauseActivity((IBinder) msg.obj, false, (msg.arg1 & 1) != 0, msg.arg2, (msg.arg1 & 2) != 0);
maybeSnapshot();
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
break;
case PAUSE_ACTIVITY_FINISHING:
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, “activityPause”);
handlePauseActivity((IBinder) msg.obj, true, (msg.arg1 & 1) != 0, msg.arg2, (msg.arg1 & 1) != 0);
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
break;
...
}
}可以看见Activity的生命周期都是依靠主线程的Looper.loop,当收到不同Message时则采用相应措施。
如果某个消息处理时间过长,比如你在onCreate(),onResume()里面处理耗时操作,那么下一次的消息比如用户的点击事件不能处理了,整个循环就会产生卡顿,时间一长就成了ANR。
总结:Looer.loop()方法可能会引起主线程的阻塞,但只要它的消息循环没有被阻塞,能一直处理事件就不会产生ANR异常。
除此之外,关于这个问题还有另外一种问法:Android中为什么主线程不会因为Looper.loop()里的死循环卡死?
回答这个问题,需要弄清Android系统中线程和进程的相互关系。
进程:每个app运行时前首先创建一个进程,该进程是由Zygote fork出来的,用于承载App上运行的各种Activity/Service等组件。进程对于上层应用来说是完全透明的,这也是google有意为之,让App程序都是运行在Android Runtime。大多数情况一个App就运行在一个进程中,除非在AndroidManifest.xml中配置Android:process属性,或通过native代码fork进程。线程:线程对应用来说非常常见,比如每次new Thread().start都会创建一个新的线程。该线程与App所在进程之间资源共享,从Linux角度来说进程与线程除了是否共享资源外,并没有本质的区别,都是一个task_struct结构体,在CPU看来进程或线程无非就是一段可执行的代码,CPU采用CFS调度算法,保证每个task都尽可能公平的享有CPU时间片。
对于Looper.loop()为什么不会出现卡死的问题,可以按照下面的思路:
对于线程既然是一段可执行的代码,当可执行代码执行完成后,线程生命周期便该终止了,线程退出。而对于主线程,我们是绝不希望会被运行一段时间,自己就退出,那么如何保证能一直存活呢?简单做法就是可执行代码是能一直执行下去的,死循环便能保证不会被退出,例如,binder线程也是采用死循环的方法,通过循环方式不同与Binder驱动进行读写操作,当然并非简单地死循环,无消息时会休眠。但这里可能又引发了另一个问题,既然是死循环又如何去处理其他事务呢?通过创建新线程的方式。真正会卡死主线程的操作是在回调方法onCreate/onStart/onResume等操作时间过长,会导致掉帧,甚至发生ANR,looper.loop本身不会导致应用卡死。
6,图片框架的一些原理知识
7,其他的一些Android的模块化开发,热更新,组件化等知识。
Android面试之主流框架
在Android面试的时候,经常会被问到一些Android开发中用到的一些开发框架,如常见的网络请求框架Retrofit/OkHttp,组件通信框架EventBus/Dagger2,异步编程RxJava/RxAndroid等。本文给大家整理下上面的几个框架,以备面试用。
EventBus
EventBus是一个Android发布/订阅事件总线,简化了组件间的通信,让代码更加简介,但是如果滥用EventBus,也会让代码变得更加辅助。面试EventBus的时候一般会谈到如下几点:
(1)EventBus是通过注解+反射来进行方法的获取的
注解的使用:@Retention(RetentionPolicy.RUNTIME)表示此注解在运行期可知,否则使用CLASS或者SOURCE在运行期间会被丢弃。
通过反射来获取类和方法:因为映射关系实际上是类映射到所有此类的对象的方法上的,所以应该通过反射来获取类以及被注解过的方法,并且将方法和对象保存为一个调用实体。
(2)使用ConcurrentHashMap来保存映射关系
调用实体的构建:调用实体中对于Object,也就是实际执行方法的对象不应该使用强引用而是应该使用弱引用,因为Map的static的,生命周期有可能长于被调用的对象,如果使用强引用就会出现内存泄漏的问题。
说明:并发编程实践中,ConcurrentHashMap是一个经常被使用的数据结构,相比于Hashtable以及Collections.synchronizedMap(),ConcurrentHashMap在线程安全的基础上提供了更好的写并发能力,但同时降低了对读一致性的要求。详情可以查看下面的文章:
http://www.importnew.com/22007.html。
(3)方法的执行
使用Dispatcher进行方法的分派,异步则使用线程池来处理,同步就直接执行,而UI线程则使用MainLooper创建一个Handler,投递到主线程中去执行。
Retrofit
首先要明确EventBus中最核心的就是动态代理技术。
Java中的动态代理:
首先动态代理是区别于静态代理的,代理模式中需要代理类和实际执行类同时实现一个相同的接口,并且在每个接口定义的方法前后都要加入相同的代码,这样有可能很多方法代理类都需要重复。而动态代理就是将这个步骤放入运行时的过程,一个代理类只需要实现InvocationHandler接口中的invoke方法,当需要动态代理时只需要根据接口和一个实现了InvocationHandler的代理对象A生成一个最终的自动生成的代理对象A*。这样最终的代理对象A*无论调用什么方法,都会执行InvocationHandler的代理对象A的invoke函数,你就可以在这个invoke函数中实现真正的代理逻辑。
动态代理的实现机制实际上就是使用Proxy.newProxyInstance函数为动态代理对象A生成一个代理对象A*的类的字节码从而生成具体A*对象过程,这个A*类具有几个特点,一是它需要实现传入的接口,第二就是所有接口的实现中都会调用A的invoke方法,并且传入相应的调用实际方法(即接口中的方法)。
Retrofit中的动态代理
Retrofit中使用了动态代理是不错,但是并不是为了真正的代理才使用的,它只是为了动态代理一个非常重要的功能,就是“拦截”功能。我们知道动态代理中自动生成的A*对象的所有方法执行都会调用实际代理类A中的invoke方法,再由我们在invoke中实现真正代理的逻辑,实际上也就是A*的所有方法都被A对象给拦截了。
而Retrofit的功能就是将代理变成像方法调用那么简单。
public interface ServiceApi {@GET("/api/columns/{user} ")Call<Author> getAuthor(@Path("user") String user)
}再用这个retrofit对象创建一个ServiceApi对象,并通过getAuthor函数来调用函数。
ServiceApi api = retrofit.create(ServiceApi.class);
Call<Author> call = api.getAuthor("zhangsan");也就是一个网络调用你只需要在你创建的接口里面通过注解进行设置,然后通过retrofit创建一个api然后调用,就可以自动完成一个Okhttp的Call的创建。Retrofit的create()函数的代码如下:
public <T> T create(final Class<T> service) {
Utils.validateServiceInterface(service);
if (validateEagerly) {eagerlyValidateMethods(service);
}
return (T) Proxy.newProxyInstance(service.getClassLoader(), new Class<?>[] { service },new InvocationHandler() {private final Platform platform = Platform.get();@Override public Object invoke(Object proxy, Method method, Object... args)throws Throwable {// If the method is a method from Object then defer to normal invocation.if (method.getDeclaringClass() == Object.class) {return method.invoke(this, args);}if (platform.isDefaultMethod(method)) {return platform.invokeDefaultMethod(method, service, proxy, args);}ServiceMethod serviceMethod = loadServiceMethod(method);OkHttpCall okHttpCall = new OkHttpCall<>(serviceMethod, args);return serviceMethod.callAdapter.adapt(okHttpCall);}});我们可以看出怎么从接口类创建成一个API对象?就是使用了动态代理中的拦截技术,通过创建一个符合此接口的动态代理对象A*,那A呢?就是这其中创建的这个匿名类了,它在内部实现了invoke函数,这样A*调用的就是A中的invoke函数,也就是被拦截了,实际运行invoke。而invoke就是根据调用的method的注解(,从而生成一个符合条件的Okhttp的Call对象,并进行真正的请求。
Retrofit作用
Retrofit实际上是为了更方便的使用Okhttp,因为Okhttp的使用就是构建一个Call,而构建Call的大部分过程都是相似的,而Retrofit正是利用了代理机制带我们动态的创建Call,而Call的创建信息就来自于你的注解。
OkHttp3
关于OkHttp3的内容大家可以访问下面的博客链接:OkHttp3源码分析。该文章主要从以下几个方面来讲解OkHttps相关的内容:
OkHttp3源码分析[综述]
OkHttp3源码分析[复用连接池]
OkHttp3源码分析[缓存策略]
OkHttp3源码分析[DiskLruCache]
OkHttp3源码分析[任务队列]
请求任务队列
Okhttp使用了一个线程池来进行异步网络任务的真正执行,而对于任务的管理采用了任务队列的模型来对任务执行进行相应的管理,有点类似服务器的反向代理模型。Okhttp使用分发器Dispatcher来维护一个正在运行任务队列和一个等待队列。如果当前并发任务数量小于64,就放入执行队列中并且放入线程池中执行。而如果当前并发数量大于64就放入等待队列中,在每次有任务执行完成之后就在finally块中调用分发器的finish函数,在等待队列中查看是否有空余任务,如果有就进行入队执行。Okhttp就是使用任务队列的模型来进行任务的执行和调度的。
复用连接池
Http使用的TCP连接有长连接和短连接之分,对于访问某个服务器的频繁通信,使用短连接势必会造成在建立连接上大量的时间消耗;而长连接的长时间无用保持又会造成资源你的浪费。Okhttp底层是采用Socket建立流连接,而连接如果不手动close掉,就会造成内存泄漏,那我们使用Okhttp时也没有做close操作,其实是Okhttp自己来进行连接池的维护的。在Okhttp中,它使用类似引用计数的方式来进行连接的管理,这里的计数对象是StreamAllocation,它被反复执行aquire与release操作,这两个函数其实是在改变Connection中的List<WeakReference<StreamAllocation>>大小。List中Allocation的数量也就是物理socket被引用的计数(Refference Count),如果计数为0的话,说明此连接没有被使用,是空闲的,需要通过淘汰算法实现回收。
在连接池内部维护了一个线程池,这个线程池运行的cleanupRunnable实际上是一个阻塞的runnable,内部有一个无限循环,在清理完成之后调用wait进行等待,等待的时间由cleanup的返回值决定,在等待时间到了之后再进行清理任务。相关代码如下:
while (true) {
//执行清理并返回下场需要清理的时间
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {synchronized (ConnectionPool.this) {try {//在timeout内释放锁与时间片ConnectionPool.this.wait(TimeUnit.NANOSECONDS.toMillis(waitNanos));} catch (InterruptedException ignored) {}}
}其中,Cleanup函数的执行过程如下:
- 遍历Deque中所有的RealConnection,标记泄漏的连接;
- 如果被标记的连接满足(空闲socket连接超过5个&&keepalive时间大于5分钟),就将此连接从Deque中移除,并关闭连接,返回0,也就是将要执行wait(0),提醒立刻再次扫描;
- 如果(目前还可以塞得下5个连接,但是有可能泄漏的连接(即空闲时间即将达到5分钟)),就返回此连接即将到期的剩余时间,供下次清理;
- 如果(全部都是活跃的连接),就返回默认的keep-alive时间,也就是5分钟后再执行清理;
- 如果(没有任何连接),就返回-1,跳出清理的死循环。
说明:“并发”==(“空闲”+“活跃”)==5,而不是说并发连接就一定是活跃的连接。
如何标记空闲的连接呢?我们前面也说了,如果一个连接身上的引用为0,那么就说明它是空闲的,那么就要使用pruneAndGetAllocationCount来计算它身上的引用数,如同引用计数过程。
其实标记引用为0的算法很简单,就是遍历它的List<Reference<StreamAllocation>>,删除所有已经为null的弱引用,剩下的数量就是现在它的引用数量,pruneAndGetAllocationCount函数的源码如下:
//类似于引用计数法,如果引用全部为空,返回立刻清理
private int pruneAndGetAllocationCount(RealConnection connection, long now) {
//虚引用列表
List<Reference<StreamAllocation>> references = connection.allocations;
//遍历弱引用列表
for (int i = 0; i < references.size(); ) {Reference<StreamAllocation> reference = references.get(i);//如果正在被使用,跳过,接着循环//是否置空是在上文`connectionBecameIdle`的`release`控制的if (reference.get() != null) {//非常明显的引用计数i++;continue;}//否则移除引用references.remove(i);connection.noNewStreams = true;//如果所有分配的流均没了,标记为已经距离现在空闲了5分钟if (references.isEmpty()) {connection.idleAtNanos = now - keepAliveDurationNs;return 0;}
}return references.size();
}RxJava
从15年开始,前端掀起了一股异步编程的热潮,在移动Android编程过程中,经常会听到观察者与被观察者等概念。
观察者与被观察者通信
Observable的通过create函数创建一个观察者对象。
public final static <T> Observable<T> create(OnSubscribe<T> f) {return new Observable<T>(hook.onCreate(f));
}Observable的构造函数如下:
protected Observable(OnSubscribe<T> f) {this.onSubscribe = f;
}创建了一个Observable我们记为Observable1,保存了传入的OnSubscribe对象为onSubscribe,这个很重要,后面会说到。
onSubscribe方法
public final Subscription subscribe(Subscriber<? super T> subscriber) {return Observable.subscribe(subscriber, this);
}
private static <T> Subscription subscribe(Subscriber<? super T> subscriber, Observable<T> observable) {...subscriber.onStart();onSubscribe.call(subscriber);return hook.onSubscribeReturn(subscriber);
}Rxjava的变换过程
在RxJava中经常会数据转换,如map函数,filtmap函数和lift函数。
lift函数
public <R> Observable<R> lift(Operator<? extends R, ? super T> operator) {return Observable.create(new OnSubscribe<R>() {@Override
public void call(Subscriber subscriber) {
Subscriber newSubscriber = operator.call(subscriber);newSubscriber.onStart();onSubscribe.call(newSubscriber);}});
}我们可以看到这里我们又创建了一个新的Observable对象,我们记为Observable2,也就是说当我们执行map时,实际上返回了一个新的Observable对象,我们之后的subscribe函数实际上执行再我们新创建的Observable2上,这时他调用的就是我们新的call函数,也就是Observable2的call函数(加粗部分),我们来看一下这个operator的call的实现。这里call传入的就是我们的Subscriber1对象,也就是调用最终的subscribe的处理对象。
call函数
public Subscriber<? super T> call(final Subscriber<? super R> o) {return new Subscriber<T>(o) {@Overridepublic void onNext(T t) {o.onNext(transformer.call(t));}};
}这里的transformer就是我们在map调用是传进去的func函数,也就是变换的具体过程。那看之后的onSubscribe.call(回到call中),这里的onSubscribe是谁呢?就是我们Observable1保存的onSubscribe对象,也就是我们前面说很重要的那个对象。而这个o(又回来了)就是我们的Subscriber1,这里可以看出,在调用了转换函数之后我们还是调用了一开始的Subscriber1的onNext,最终事件经过转换传给了我们的结果。
线程切换过程(Scheduler)
RxJava最好用的特点就是提供了方便的线程切换,但它的原理归根结底还是lift,使用subscribeOn()的原理就是创建一个新的Observable,把它的call过程开始的执行投递到需要的线程中;而 observeOn() 则是把线程切换的逻辑放在自己创建的Subscriber中来执行。把对于最终的Subscriber1的执行过程投递到需要的线程中来进行。
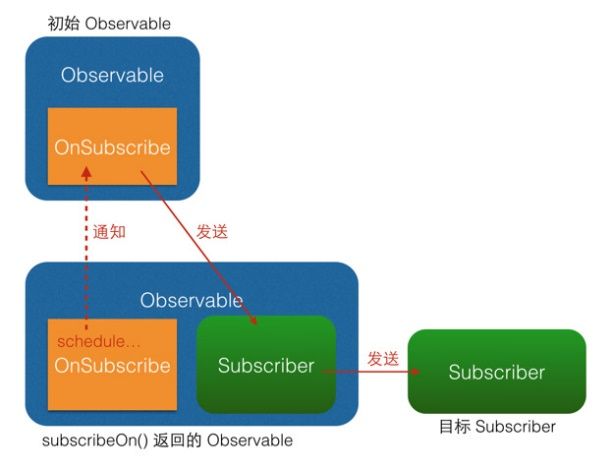
从图中可以看出,subscribeOn() 和 observeOn() 都做了线程切换的工作(图中的 “schedule…” 部位)。不同的是, subscribeOn()的线程切换发生在 OnSubscribe 中,即在它通知上一级 OnSubscribe 时,这时事件还没有开始发送,因此 subscribeOn() 的线程控制可以从事件发出的开端就造成影响;而 observeOn() 的线程切换则发生在它内建的 Subscriber 中,即发生在它即将给下一级 Subscriber 发送事件时,因此 observeOn() 控制的是它后面的线程。
为什么subscribeOn()只有第一个有效?
因为它是从通知开始将后面的执行全部投递到需要的线程来执行,但是之后的投递会受到在它的上级的(但是执行在它之后)的影响,如果上面还有subscribeOn() ,又会投递到不同的线程中去,这样就不受到它的控制了。