编者按:本文详细解剖 Milvus 2.0 主要的数据处理流程以及访问接入层( Access Layer)。
主要数据处理流程
MsgStream 接口
写路径
读路径
DDL 流程
建索引流程
Access Layer 代码
主要数据处理流程
Milvus 2.0 中主要的数据处理流程包括读写路径、建表等数据定义操作以及向量索引构建流程。
《前所未有的 Milvus 源码架构解析》一文中曾提到 Milvus 2.0 依赖 Pub/sub 系统来做日志的存储和持久化。Pub/sub 系统是指类似 Kafka 或者 Pulsar 的消息队列,采用该系统后,其他系统的角色就变成了日志的消费者,以保证 Milvus 本身是没有状态的,进而提升故障恢复速度。同时可以依赖 Kafka 或者 Pulsar 来提升数据的可靠性。Pub/sub 系统的引入可以保证系统的扩展性,Milvus 可以与更多的系统做集成,而和这些交互的重要接口封装就是MsgStream。
文章中出现的诸如 Collection、Shard、Partition 和 Segment 等概念,本文不再赘述。如果读者朋友对这些概念不了解,请参考《前所未有的 Milvus 源码架构解析》这篇综述性文章。
MsgStream 接口
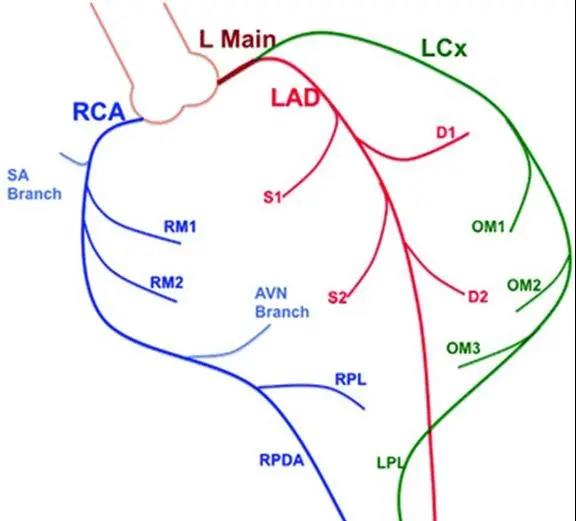
Milvus 2.0 中重要的接口之一就是 MsgStream。
![]()
MsgStream 的接口定义如上图左半部分所示。通过 Start 和 Close 可以开启和关闭 MsgStream 对象的后台协程。一个 MsgStream 对象在被 Start 之后,后台的 Go 协程会去处理将数据写入到消息存储系统里或者从消息存储系统订阅和读取数据等逻辑。
MsgStream 既可以作为生产者(producer) 也可以作为消费者(consumer)。AsProducer 接口将该 MsgStream 对象定义为 producer。AsConsumer 接口将 MsgStream 定义为 consumer。注意到这两个接口都有名为 channels 的参数。前面我们提到 collection 在创建时可以指定 shard 的数目。一个 shard 代表一个 virtual channel,每个 collection 可以有多个 virtual channel。对于 collection 的每一个 virutal channel 在消息存储系统中都有一个 channel 与其对应,为了做区分,我们将消息存储系统中的 channel 称之为 physical channel。AsProducer 和 AsConsumer 的 channels 参数代表的就是消息存储系统中 physical channel 的名字列表。这些 channels 限定了 MsgStream 对象的写入或者消费的 physical channel 的范围。
通过 Produce 方法将数据写入到消息存储系统中的 physical channel 里。有两种写入模式:单一写入模式和广播写入模式。单一写入模式是通过写入数据中 entity 的主键 hash 值确定的 shard(virtual channel)进而决定数据写入的 physical channel。广播写入模式是指将数据写入到 channels 参数指定的所有的 physical channel 里。
Consume() 是一个阻塞式的接口。调用这个接口时如果 physical channel 里没有数据,协程会阻塞。
Chan() 返回的是 Go 语言定义的 channel,目的是提供一种非阻塞的消费数据的方式。比如使用 select 语句可以做到有数据可读时才会进入相应的数据读取和处理逻辑里,而当无数据可读时协程可以去处理其他逻辑而不用阻塞等待。
Seek() 服务于宕机恢复。消费者消费到某个位置之后,会记录当前消费到的位置。这个位置需要写到 meta 里的,当新起一个节点来接管工作后,它是可以调这个 Seek 接口,传入宕机前消费的位置,接着上次的位置再接着消费。
写路径
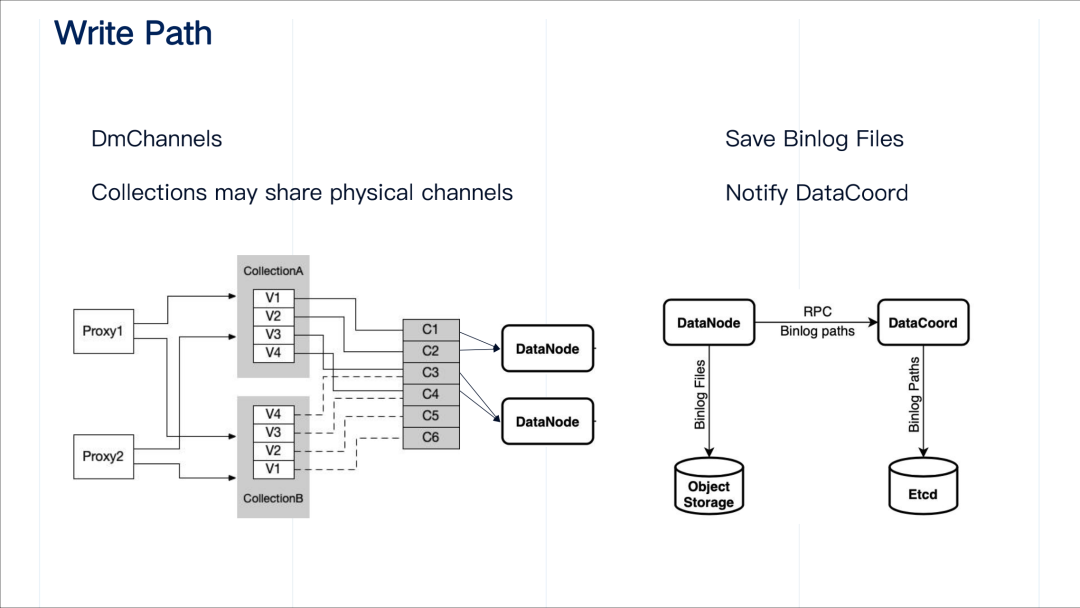
接下来我们来看一下写路径。这里写路径里流经的是写入到 collection 中的数据。写入的数据既可以是 insert 消息也可以是 delete 消息。这些消息(entity) 会被写入到不同的 virtual channel(shard)里。对于这些 virtual channel,我们也称之为 DmChannels(data manipulation channels).
需要指出的是,不同的 collection 可能会共享消息存储系统中的 physical channel。一个 collection 在创建时可以指定很多个 shard(virtual channel),因而该 collection 的数据也就会流经消息存储中的多个 physical channel。这样有个好处是可以在写的时候可以大量并通过依赖消息存储系统的并发的特性提高写吞吐。我们的初步设定是每一个 collection 可以在底层复用相同的物理 channel,这样物理 channel 维持在一个固定大小,然后 collection 级别的 virtual channel 可以很多,而且不同 collection 之间也可以共用 physical channel。
这里需要指出的是 collection 在创建时不仅指定了 shard 的个数,也会确定 virutal channel 和消息存储中 physical channel 之间的映射关系。
在写路径中,访问接入层 proxy 作为生成者会通过 MsgStream 对象的 produce 接口将数据写入到消息存储系统里,同时 data node 作为消费者消费数据之后,按照时间窗口以及每个 segment 的阈值大小,定期将这些消费到的数据转换并存到对象存储中。同时存储的路径是一个 meta 信息,需要通过 RPC 去通知 data coordinator,data coordinator 将这些 Binlog paths 记录到 etcd 里。
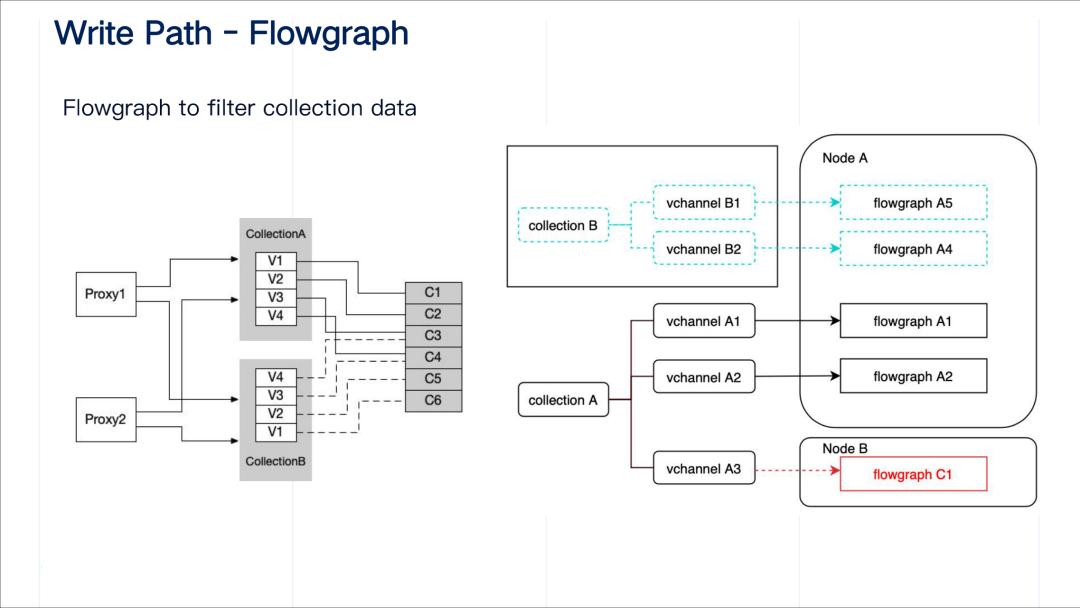
既然不同的 collection 可能共用消息存储系统的 physical channel,那么 data node/query node 消费数据是需要区分该 channel 中数据的归属问题。因此引入 flowgraph 这个对象,它可以负责对 physical channel 中的数据根据 collection 的 ID 做过滤。可以认为一个 flowgraph 负责相应 collection 中的一个 shard(virtual channel)中的数据流。

什么时候创建 MsgStream 呢?对于 proxy 来说,它是在处理 insert 请求时创建的。当 proxy 收到一个数据写入请求时,它首先询问 root coordinator 拿到 virtual channel 和 physical channel 的映射关系,然后构造一个 MsgStream 对象。
作为消费者,data node 创建 MsgStream 对象的时机则在 data node 启动之后。data coordinator 将 collection 的 virtual channel 在不同的 data node 做好分配后,会将分配信息写入 etcd。data node 启动之后可以读取这个 etcd 中的分配信息,就可知其负责的 virutal channel 及相应的 physical channel 然后创建 MsgStream 对象。以上图右半边所示, data node 1 负责 V1、C1、V2、C2,data node 2 负责 V3、C5、V4、C6。
读路径
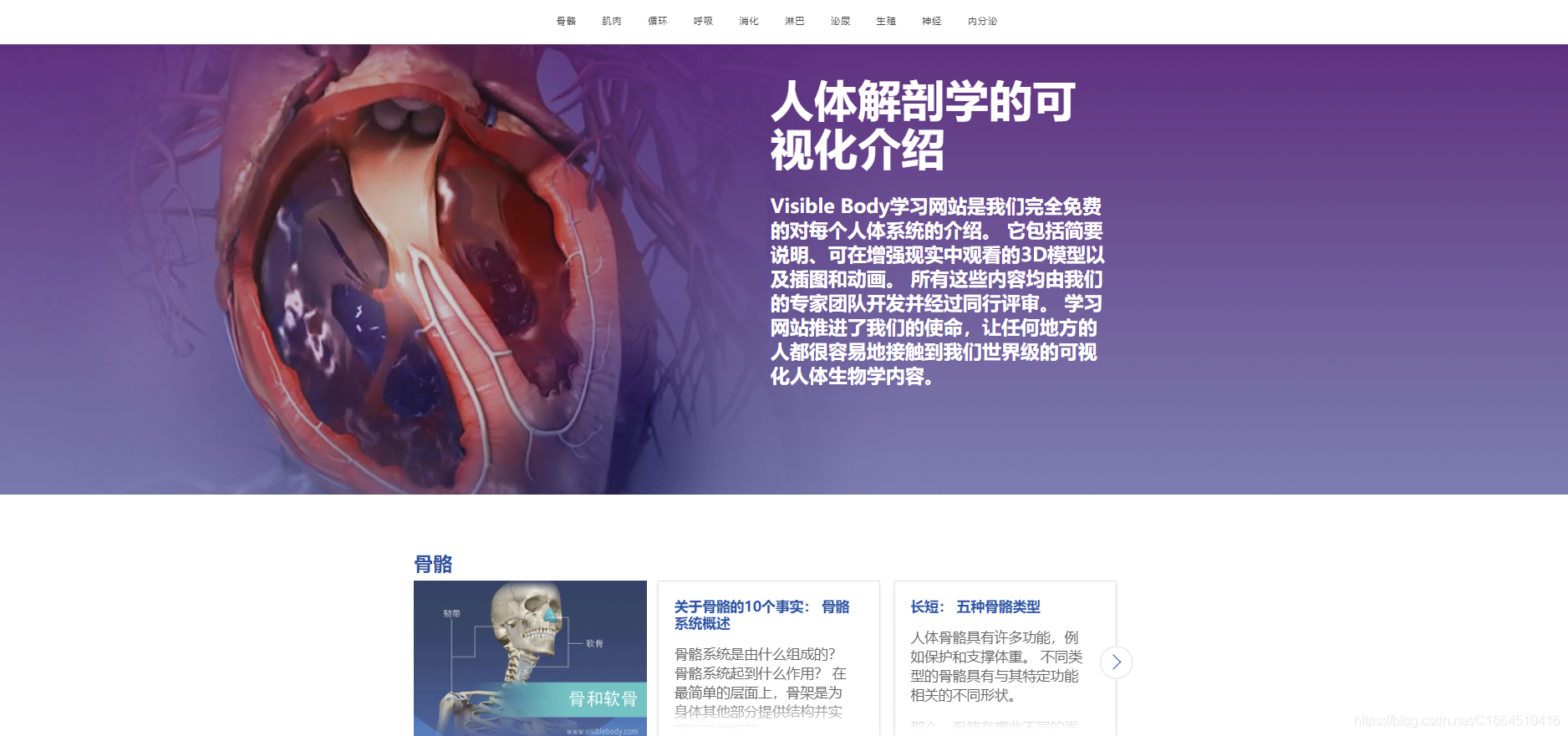
Milvus 是一个典型的 MPP 架构的系统。每个 query node 的搜索是并行执行的,proxy 聚合最终的结果返回给客户端。在读路径中,查询请求通过 DqRequestChannel 进行广播,而查询结果通过 gRPC 汇总到 proxy。
proxy 作为生产者,将查询请求写入到 DqRequestChannel 中。query node 消费 DqRequestChannel 的方式比较特殊:每个 query node 的都会订阅这个 channel,这样该 channel 中的每条消息会广播给所有的 query node。
query node 收到请求之后,本地做查询,并以 segment 为粒度做一次聚合,将聚合后的结果通过 gRPC 发送给相应的 proxy 。需要指出的是,在查询请求里有唯一的 ProxyID 标识查询的发起方。query node 据此将不同查询结果路由到相应的 proxy。
proxy 判定收集到所有 query node 的查询结果后,做一次全局的聚合得到最终的查询结果,并将查询结果返回给客户端。需要指出的是在查询请求和查询结果里有相同且唯一 requestID 可以标记查询本身,proxy 据此区分哪些查询结果归属于同一个查询请求。
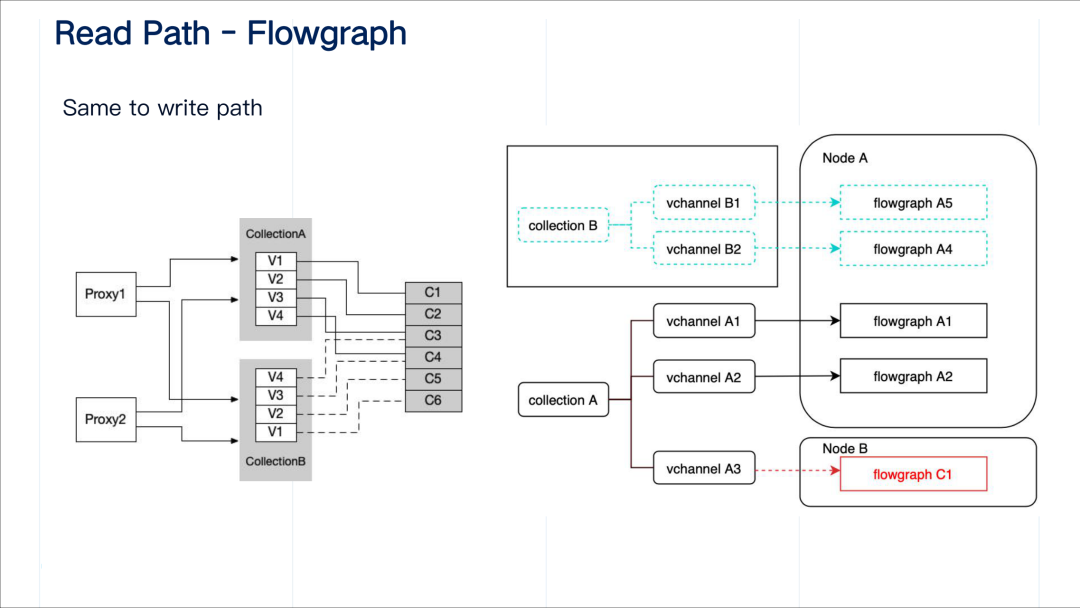
Milvus 2.0 设计要求是流批统一摄取的,query node 等查询节点也需要从消息存储中摄取实时流数据。因此 query node 同样需要引入 flowgraph 对象对数据做过滤,以对归属不同表的数据做隔离。
![]()
query node 是什么时候创建这个 MsgStream 对象的呢?
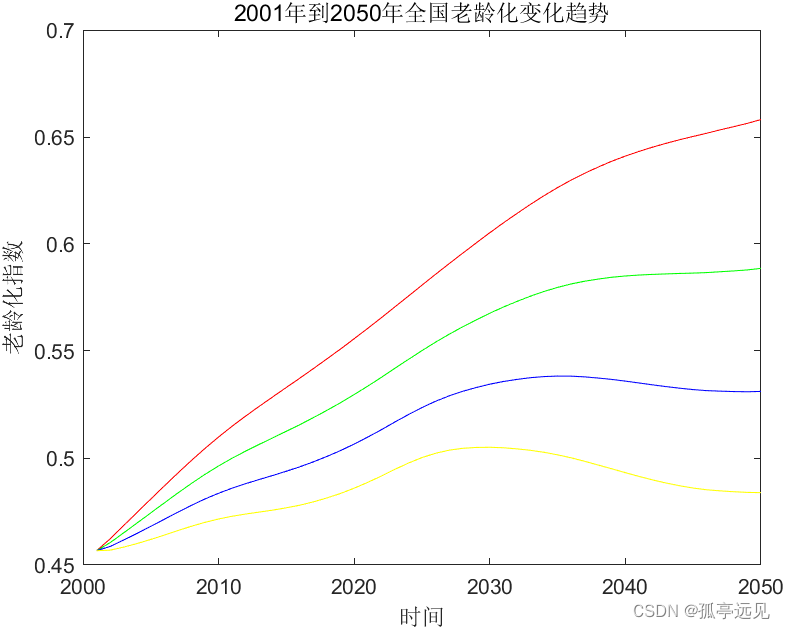
在 Milvus 的用户侧,提供了一个 load collection 的操作接口,其含义分两部分:第一是将批数据从对象存储中加载到 query node 中;第二是对接到 MsgStream 里能够接收流式数据。这样可以保证数据的完整性。表只有经过 load 之后才能执行读操作。
proxy 收到一个关于表的 load 请求后,会将该请求转发到 query coordinator。quary coordinator 来决策 shard(virtual channel)在不同的 query node 上的分配方式。这种分配信息以函数调用或者 RPC 的方式发送给 query node。query node 收到分配信息后,创建对应的 MsgStream 对象来消费数据。这些分配信息包括 vitural channel 名字及其和相应 physical channel 的映射关系。
![]()
在 query node 里,查询结果是来自两部分:第一部分是批量数据查询得到的结果。这些批量数据是从对象存储中加载所有的 sealed segment。第二部分来自于从消息存储中消费的实时数据的查询结果。这些实时数据也会形成一些 segment,这些 segment 被称为 growing segment。query node 需要对这两部分查询结果做一个本地的聚合。本地聚合之后再将结果发送给相应的 proxy。
DDL流程
DDL 表示的是 data definition language。针对元数据操作的请求也分为读和写两类,不过处理这些请求的流程是一样的,并不区分读写。读类型的元数据操作包括,查询表的 schema、查询索引信息等;写类型的元数据操作包括创建表、删表、建索引和删除索引等等。
客户端将 DDL 请求发送至 proxy, proxy 需要对这些请求做一个定序并打上时间戳,然后将请求转发到 root coordinator 并等待其返回结果。这里的时间戳指的是 root coordinator 分配的全局混合时间戳。这意味着对于每个 DDL 的请求,proxy 都会从 root coordinator 申请一个时间戳。proxy 对于每个 DDL 请求的处理是串行执行的,每次只处理一个 DDL 请求,当前 DDL 请求处理完并且收到反馈结果后才会执行下一个 DDL 请求。proxy 收到 root coordinator 的结果后,将其返回给客户端。
root coordinator 主要做的工作就是对请求做一些动态检查,检查通过后执行相应的逻辑。
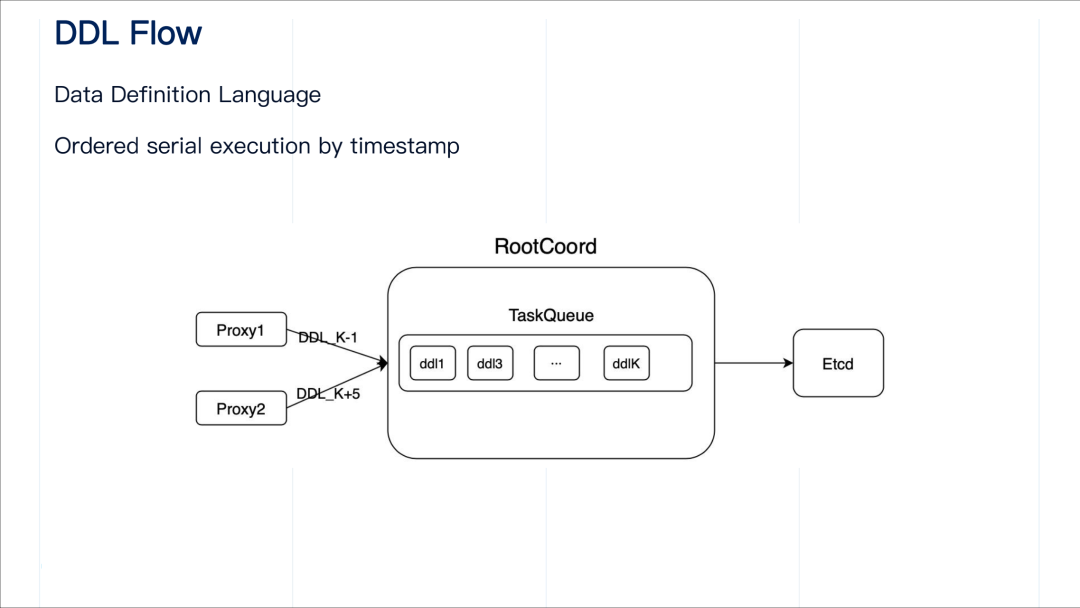
需要重点注意的是,root coordinator 在设计上要确保 DDL 操作按照时间戳升序顺序执行。
举个例子,我们可以看到上图里,root coordinator 的 task queue 包括 k 个操作,分别是 "ddl1、ddl3…… ddlk",数字代表时间戳。root coordinator 会对该 task queue 中的请求按照时间戳递增的顺序依次执行,并且记录当前已经执行完毕的最大时间戳。在分布式部署方式下,proxy 和 root coordinator 之间的通讯是通过 gRPC,两个独立组件,请求到达的顺序不一定严格按照时间戳先后。假设当前 task queue 中执行完毕的最大时间戳为 k,来自 proxy1 的 "ddl(K-1)" 到达时发现 "ddlK" 已经被执行了,那这个时候 "ddl(k-1)" 就会被拒绝进入 task queue,否则就会打破所有请求按照时间戳递增顺序执行的约定。而来自 proxy2 的 请求 "ddl(k+5)" 则被允许进入 task queue 中。
建索引流程
![]()
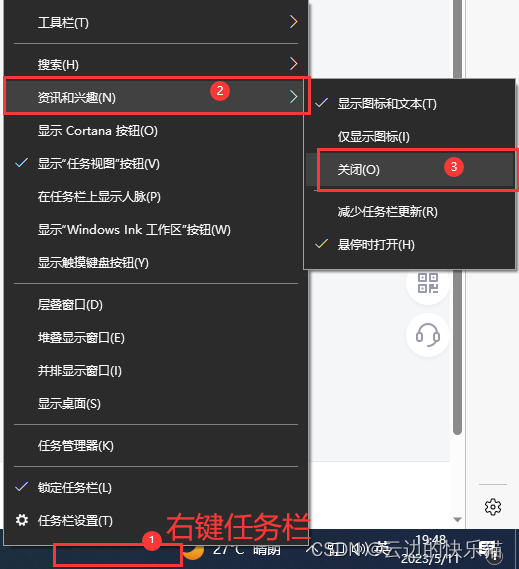
建索引的过程在 Milvus 系统内部来看,是一个长期的异步的过程。当客户端发起建索引的请求之后,proxy 收到该请求首先做一些静态检查,通过后将该请求转发到 root coordinator。root coordinator 将这些建索引的请求持久化到 KV 存储中,就立马返回给 proxy,proxy 返回给 SDK。既然是异步,那就需要有状态,以便需要查询索引建立的进度或者状态。
在用户的视角上,建索引针对的是向量 field,而向量 field 的数据在物理上是由一个个 segment 组成的。建索引是在 segment 粒度上进行的,因此 root coordinator 需要向 index coordinator 发起针对每个 sealed segment 的建索引请求。
上面这张图是每个 segment 其上的 Index 状态变化的一个过程。index coordinator 收到 root coordinator 发来的建索引的请求后,首先会将该任务持久化到 meta store 中。索引任务的初始状态是 Unissued。index coordinator 维护一个记录每个 index node 负载的优先级队列,选择一个负载比较低的 index node,将这个任务发送到 index node 去做。index node 建完索引后会把成功/失败状态写入到 meta store 中。index coordinator 通过感知 meta store 中索引状态的变化。如果由于系统资源或者 index node 失活等可恢复的失败原因,index coordinator 会重新触发这个流程,选择另外一个 index node 重新做索引构建的任务。

index coordinator 还需要负责回收那些被标记删除的索引任务及其相应的索引文件。这里我们可以看到 一个名为 recycleIndexFiles 接口,它的主要作用是将被标记删除的索引任务相应的索引文件从对象存储中删除。
当客户端发送索引的 drop 请求之后, root coordinator 会标记这个索引被 drop,然后立马返回给客户端。索引的 drop 也是一个异步的过程。root coordinator 通知 index coordinator 包含属性 IndexID 的索引需要被标记删除。每个 segment 的索引都记录属性 IndexID,它唯一标识表中向量 field 上的索引。index coordinator 根据这个 IndexID 为过滤条件,将所有索引任务中匹配到属性 IndexID 的索引任务标记为删除。index coordinator 有一个后台的协程,逐渐将所有标记为删除的任务对应的索引文件从对象存储中删除,当该索引任务对应的 索引文件被全部删除后,再将改索引任务的 meta 信息从 meta store 中移除。
Access Layer 代码
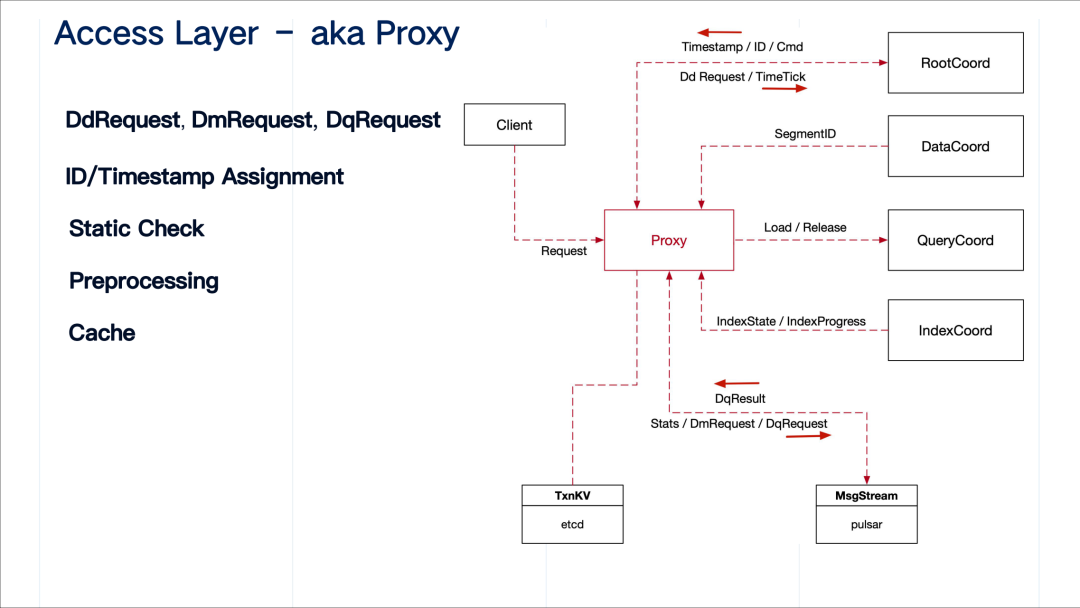
proxy 把所有的请求分为三类:
-
DdRequest(data definition request)
-
DmRequest(data manipulation request)
-
DqRequest(data quary request)
proxy 针对每个具体的请求封装一个 task 类,实现通用的 preExecute、Execute、postExecute 三个标准流程,在标准流程里,完成静态检查、预处理等。同时,proxy 会对每一个请求分配时间戳和全局 ID 标记请求。上方图中右边展示了 proxy 和其他系统所有主要组件的交互,以及交互中的数据。
![]()
proxy 的调度逻辑如下:proxy 把请求分为三类,每一类都有一个对应的 task queue;来自 SDK 的请求都会被封装成一个 task,并放入对应的 task queue 里;针对不同的 task queue 后台有不同的调度逻辑。
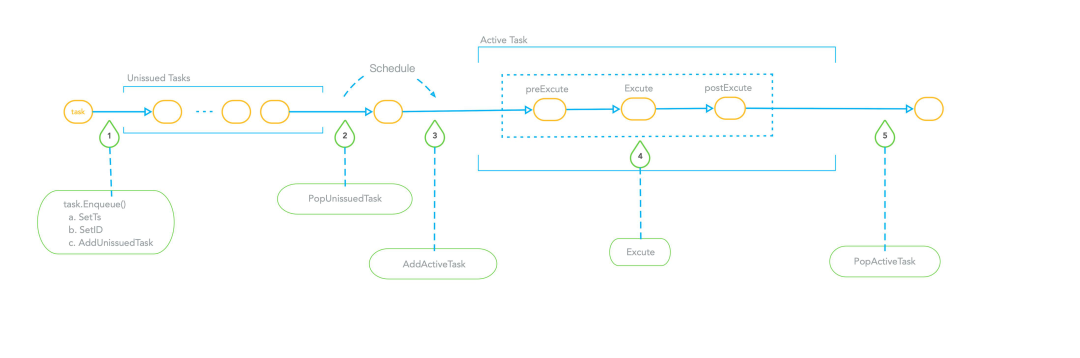
对于 data definition request 类型请求的队列,其中的请求是串行执行的,流水线主要分为五个步骤。首先是进队(enqueue)操作,在这里需要设置一个时间戳,给这个操作定序,同时设置 ID 唯一标识该请求,接着把它放入到一个待办的 unissuted tasks 列表里。而该 task queue 的 schedule 就发生在步骤 2 和 3 之间。
schedule 的过程就是将一个任务从 unissuted tasks 取出放置到 active task 列表中。当任务放置到 active task 之后,它里面的每个任务都会顺序执行 preExecute、Execute、postExecute 三个操作,最后 从 active task 列表中删除。任何一个请求任务需要完整地处理完,其中任何一个环节发生错误,都会提前退出流水线并返回错误信息。
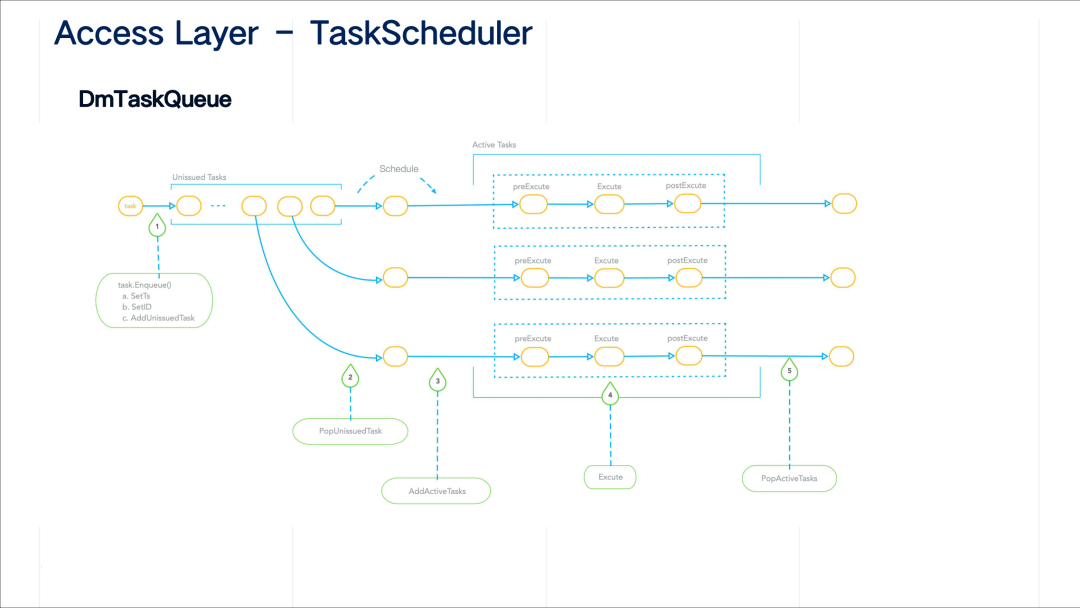
DmTaskQueue 的特点就是它可以并发执行。第一个 enqeue 的步骤和 DdTaskQueue 中 task 的 enque 逻辑相同,也会经历设置时间戳、设置 ID 等步骤,区别点在于步骤二和步骤三,针对该 DmTaskQueue 的调度是一次取出多个任务,每个协程处理一个任务的后续流水线步骤。

proxy 需要缓存一些重要的对象和数据,Cache 功能的实现位于 GlobalMetaCache 这个类。它主要缓存两大部分数据,第一部分是 name 到 ID 映射,客户端看到的是 name 而系统中下游看到的都是相应对象的 ID,第二部分是每个 collection 的 schema 等重要元信息。proxy 需要大量做一些前期的静态检查,因此为了避免经常向 root coordinator 询问元数据,需要添加缓存。当然 Cache 也应该有清理机制,当 root coordinator 执行了一个表的元信息的更改操作,会通知所有 proxy 其上关于该表的元信息缓存失效。

ChannelMgr 这个类主要维护了 virtual channel 到 physical channel 的映射,以及管理相应的 MsgStream 对象。上图右侧主要列出了 ChannelMgr 的主要接口。

曹镇山
Zilliz 高级研发工程师
Milvus 项目 maintainer
毕业于华中科技大学,主要兴趣方向包括分布式系统、数据库和大数据处理。在 Milvus 社区主要负责多个核心模块的编写和维护,是 Milvus 项目的 maintainer。除了敲代码,他也喜欢钻研心理学(尤其是犯罪心理学和积极心理学)和爬山。他的 Github 账号:czs007。
Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz 构建了 Milvus 向量数据库,以加快下一代数据平台的发展。Milvus 数据库是 LF AI & Data 基金会的毕业项目,能够管理大量非结构化数据集,在新药发现、推荐系统、聊天机器人等方面具有广泛的应用。

阅读原文,解锁更多应用场景