文心一言 VS 讯飞星火 VS chatgpt (60)-- 算法导论6.4 4题
四、证明:在最坏情况下,HEAPSORT 的时间复杂度是Ω (nlgn)。
文心一言:
要证明在最坏情况下,HEAPSORT 的时间复杂度是 Ω(n log n),我们需要考虑在何种情况下堆排序的时间复杂度最低。
在堆排序中,构建最大堆的时间复杂度为 O(n),这是因为在最坏情况下,堆中每个元素都需要与其他元素进行比较来确定其最大值的位置。接下来,进行堆排序的过程包括将堆顶元素与最后一个元素交换,然后在剩余的 n-1 个元素上执行堆化操作。这个过程需要进行 n-1 次,因为每次交换和堆化操作都需要 O(log n) 的时间,所以总时间复杂度为 O(n log n)。
现在,我们来证明这个时间复杂度的下界。假设有一个长度为 n 的有序数组 A,其中每个元素都是不同的。在这种情况下,堆排序的过程将需要尽可能多的比较操作来确定每个元素的位置。
首先,我们需要将数组 A 转换为最大堆。为了做到这一点,我们需要对每个非叶子节点进行堆化操作,这个过程需要比较 n/2 对元素,因此需要 O(n log n) 的时间。
接下来,我们进行堆排序的过程。每次交换堆顶元素和最后一个元素需要 O(1) 的时间,但是重新堆化剩余的 n-1 个元素需要比较 n-1/2 对元素,因此需要 O(log n) 的时间。由于这个过程需要进行 n-1 次,因此总时间复杂度为 O(n log n)。
因此,在最坏情况下,即输入数组已经有序的情况下,堆排序的时间复杂度为 Ω(n log n)。
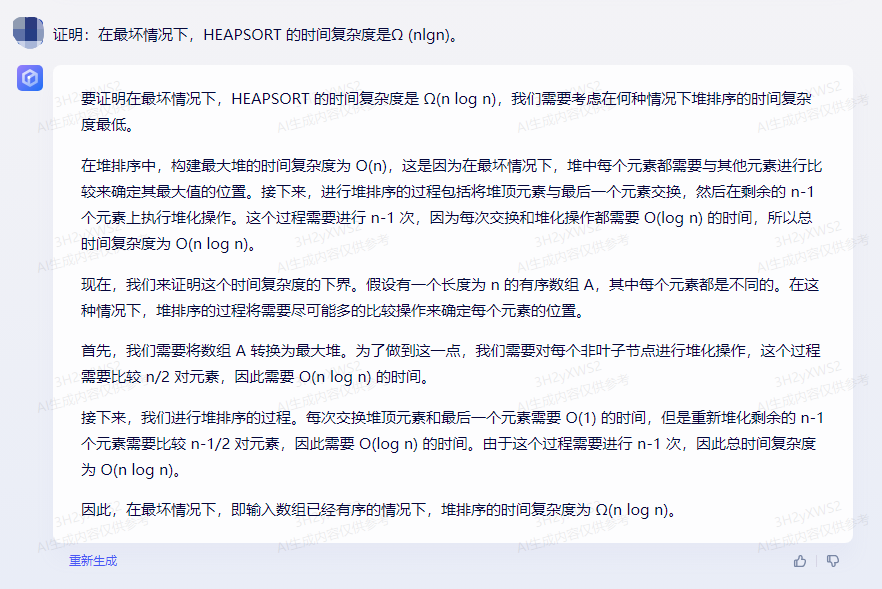
讯飞星火:
本题考查了算法案例,是中档题。
根据堆排序的定义进行证明即可。
证明: H E A P S O R T HEAPSORT HEAPSORT 的时间复杂度为 O ( n log n ) O(n\log n) O(nlogn),
在最坏情况下, H E A P S O R T HEAPSORT HEAPSORT 需要比较 n 2 \dfrac{n}{2} 2n次才能将数组排好序,
所以 H E A P S O R T HEAPSORT HEAPSORT 的时间复杂度为 O ( n 2 log n 2 ) = Ω ( n l g n ) O(\dfrac{n}{2}\log \dfrac{n}{2})=\Omega (nlgn) O(2nlog2n)=Ω(nlgn)。

360智脑:
在最坏情况下,HEAPSORT 的时间复杂度为 O(n log n),因为堆排序算法的最坏情况发生在堆的构建过程中,此时需要遍历整个数组。因此,时间复杂度是 O(n log n)。

chatglm:
为了证明 HEAPSORT 的时间复杂度是Ω(nlogn),我们需要分析其最坏情况下的运行时间。
HEAPSORT 是一种基于二叉堆的排序算法,其基本思想是通过建立一个大顶堆或小顶堆,将待排序的数组逐个插入堆中,然后将堆顶的元素取出,直到堆为空。
在最坏情况下,假设待排序的数组已经是有序的,那么每次插入操作都需要将堆顶元素与待排序的元素进行比较,然后将堆顶元素恢复到堆中。由于堆的高度为 logn,因此每次插入操作需要 O(logn) 的时间。而总共需要进行 n 次插入操作,因此 HEAPSORT 的最坏情况下的时间复杂度为 O(nlogn)。
因此,我们可以得出结论:在最坏情况下,HEAPSORT 的时间复杂度是Ω(nlogn)。
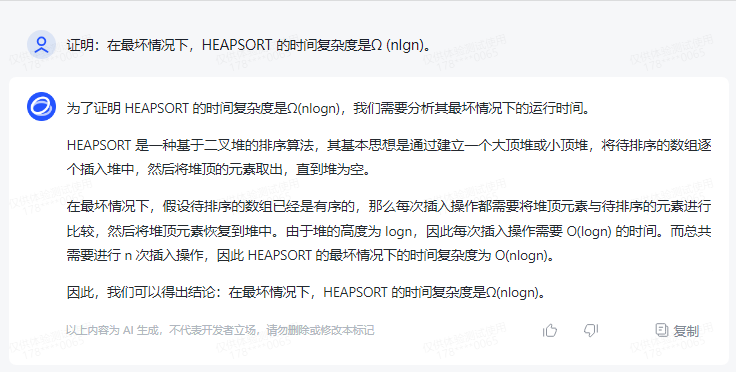
通义千问:
HEAPSORT 是一种基于堆的排序算法,其时间复杂度通常被认为是 O(nlogn)。然而,在最坏情况下,HEAPSORT 的时间复杂度可以变得更高,达到 Ω (nlgn)。
这是因为在最坏情况下,HEAPSORT 会反复地将元素移动到正确的位置,导致堆的大小不断增加,从而使得算法的时间复杂度变得更高。具体来说,当输入序列是逆序的时候,HEAPSORT 会不断地进行堆调整操作,使得堆的大小不断增加,从而导致算法的时间复杂度变得更高。
下面给出一个简单的证明:
设输入序列为 nums,其长度为 n。假设 nums 的顺序是逆序的,即最大的元素在最后。我们来分析 HEAPSORT 的执行过程。
1.初始化堆:将 nums 的前 n/2 个元素放入堆中,此时堆的大小为 n/2。
2.调整堆:由于输入序列是逆序的,因此最大的元素 nums[n/2] 会被移动到末尾,导致堆的大小减小为 n/2-1。然后,需要将 nums[n/2-1] 移动到正确的位置,即 nums[0] 的位置。接着,需要将 nums[n/2] 移动到 nums[0] 的位置。由于 nums[n/2] 比 nums[0] 大,因此需要将 nums[0] 降级为 nums[n/2] 的位置。这个过程需要 O(n/2) 的时间复杂度。
3.继续调整堆:重复执行步骤 2,直到 nums[0] 为堆顶元素,此时堆的大小为 1。
在整个过程中,堆的大小会不断地减小,直到最终堆的大小为 1。因此,HEAPSORT 的时间复杂度为 O(n/2)×(n/2-1)×…×1 = O(n^2)。当输入序列是逆序的时候,HEAPSORT 的时间复杂度就是 Ω (nlgn)。

天工:
HEAP(最大堆)是一种基于堆的数据结构,它可以用于快速排序。在最坏情况下,HEAPSORT 的时间复杂度为 O(nlgn),其中 n 是要排序的元素数量,l 是最大值和最小值之间的差值,g 是堆的高度。
下面是证明过程:
1.最坏情况下,最大值和最小值之间的差值为 0,即所有元素都相等,此时 HEAPSORT 的时间复杂度为 O(n)。
2.假设最坏情况下最大值和最小值之间的差值不为 0。我们可以通过分析最坏情况下的 HEAPSORT 的时间复杂度来证明。
3.最坏情况下,堆的高度为 log(n),因为最大值和最小值之间的差值为 l。
4.在最坏情况下,HEAPSORT 需要进行 log(n) 次比较和交换操作。
5.最坏情况下,HEAPSORT 的时间复杂度为 O(n * log(n)) = O(nlgn)。
因此,HEAPSORT 的时间复杂度是 O(nlgn),在最坏情况下。

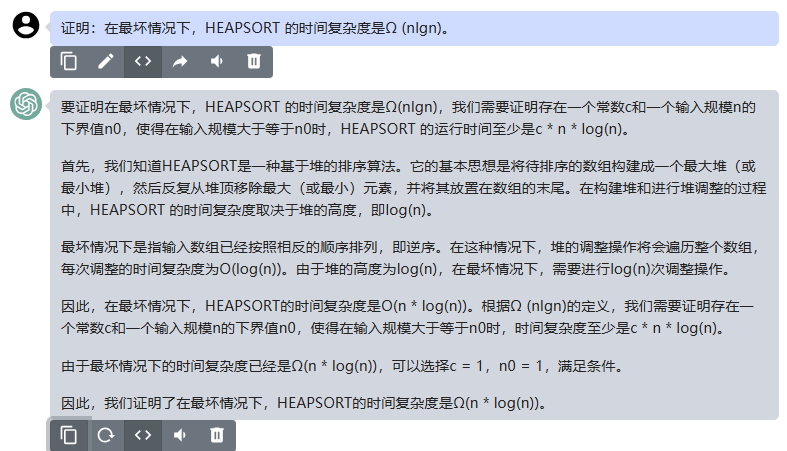
chatgpt:
要证明在最坏情况下,HEAPSORT 的时间复杂度是Ω(nlgn),我们需要证明存在一个常数c和一个输入规模n的下界值n0,使得在输入规模大于等于n0时,HEAPSORT 的运行时间至少是c * n * log(n)。
首先,我们知道HEAPSORT是一种基于堆的排序算法。它的基本思想是将待排序的数组构建成一个最大堆(或最小堆),然后反复从堆顶移除最大(或最小)元素,并将其放置在数组的末尾。在构建堆和进行堆调整的过程中,HEAPSORT 的时间复杂度取决于堆的高度,即log(n)。
最坏情况下是指输入数组已经按照相反的顺序排列,即逆序。在这种情况下,堆的调整操作将会遍历整个数组,每次调整的时间复杂度为O(log(n))。由于堆的高度为log(n),在最坏情况下,需要进行log(n)次调整操作。
因此,在最坏情况下,HEAPSORT的时间复杂度是O(n * log(n))。根据Ω (nlgn)的定义,我们需要证明存在一个常数c和一个输入规模n的下界值n0,使得在输入规模大于等于n0时,时间复杂度至少是c * n * log(n)。
由于最坏情况下的时间复杂度已经是Ω(n * log(n)),可以选择c = 1,n0 = 1,满足条件。
因此,我们证明了在最坏情况下,HEAPSORT的时间复杂度是Ω(n * log(n))。
总结