Python 预测 NBA 比赛结果
一、 内容介绍
不知道你是否在朋友圈被刷屏过 NBA 的某场比赛进度或者结果?或者你就是一个 NBA 狂热粉,比赛中的每个进球、抢断或是逆转压哨球都能让你热血沸腾。除去观赏精彩的比赛过程,我们也同样好奇比赛的结果会是如何。因此本节课程,将给同学们展示如何使用 NBA 比赛的以往统计数据,判断每个球队的战斗力,及预测某场比赛中的结果。
我们将基于 2015-2016 年的 NBA 常规赛及季后赛的比赛统计数据,预测在当下正在进行的 2016-2017 常规赛每场赛事的结果。
二、 实现原理及步骤
1. 获取 NBA 比赛统计数据
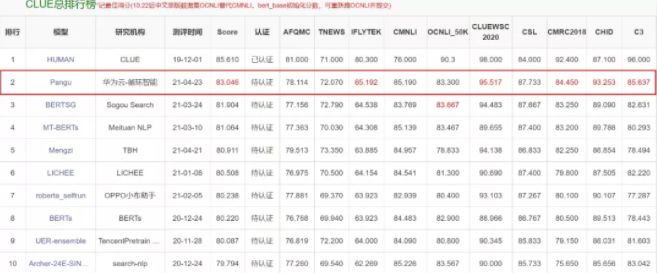
我们将以获取 Team Per Game Stats 表格数据为例,展示如何获取这三项统计数据:
-
进入到 Basketball Reference.com 中,在导航栏中选择Season并选择2015~2016赛季中的Summary:
-
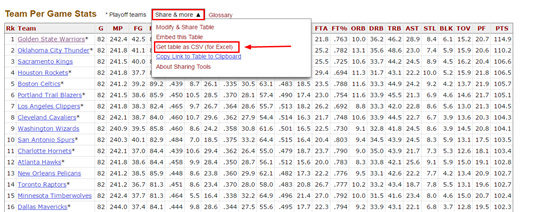
进入到 2015~2016 年的Summary界面后,滑动窗口找到Team Per Game Stats表格,并选择左上方的 Share & more,在其下拉菜单中选择 Get table as CSV (for Excel):
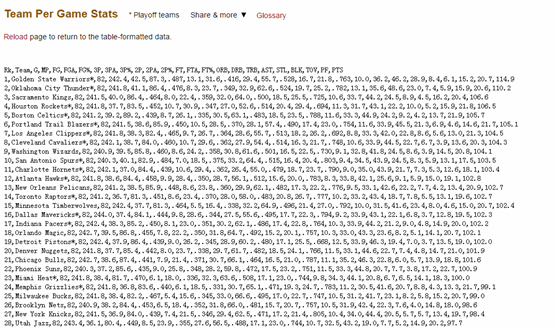
- 复制在界面中生成的 csv 格式数据,并粘贴至一个文本编辑器保存为 csv 文件即可:
2. 数据分析
在这里我们将基于国际象棋比赛,大致地介绍下 Elo 等级划分制度。在上图中 Eduardo 在窗户上写下的公式就是根据Logistic Distribution计算 PK 双方(A 和 B)对各自的胜率期望值计算公式。假设 A 和 B 的当前等级分为 RAR_ARA和 RBR_BRB,则
A 对 B 的胜率期望值为:
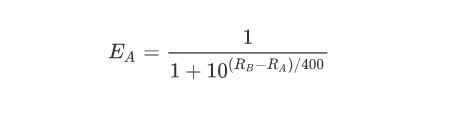
B 对 A 的胜率期望值为
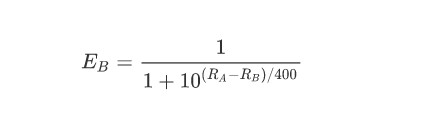
如果棋手 A 在比赛中的真实得分 SAS_ASA(胜 1 分,和 0.5 分,负 0 分)和他的胜率期望值 EAE_AEA不同,则他的等级分要根据以下公式进行调整:
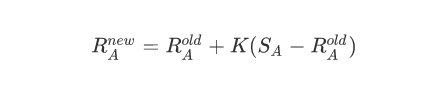
在国际象棋中,根据等级分的不同 K 值也会做相应的调整:
• 大于等于2400,K=16
• 2100~2400 分,K=24
• 小于等于2100,K=32
因此我们将会用以表示某场比赛数据的特征向量为(假如 A 与 B 队比赛):[A 队 Elo score, A 队的 T,O 和 M 表统计数据,B 队 Elo score, B 队的 T,O 和 M 表统计数据]
###3.基于数据进行模型训练和预测
我们下载相应的数据文件并解压。
# 获取数据文件
!wget http://labfile.oss.aliyuncs.com/courses/782/data.zip# 安装 unzip
!apt-get install unzip# 解压data压缩包并且删除该压缩包
!unzip data.zip
!rm -r data.zip
4. 代码实现
首先,引入实验相关模块:
import pandas as pd
import math
import csv
import random
import numpy as np
from sklearn import linear_model
from sklearn.model_selection import cross_val_score
设置回归训练时所需用到的参数变量:
# 当每支队伍没有elo等级分时,赋予其基础elo等级分
base_elo = 1600
team_elos = {}
team_stats = {}
X = []
y = []
# 存放数据的目录
folder = 'data'
在最开始需要初始化数据,从 T、O 和 M 表格中读入数据,去除一些无关数据并将这三个表格通过Team属性列进行连接:
# 根据每支队伍的Miscellaneous Opponent,Team统计数据csv文件进行初始化
def initialize_data(Mstat, Ostat, Tstat):new_Mstat = Mstat.drop(['Rk', 'Arena'], axis=1)new_Ostat = Ostat.drop(['Rk', 'G', 'MP'], axis=1)new_Tstat = Tstat.drop(['Rk', 'G', 'MP'], axis=1)team_stats1 = pd.merge(new_Mstat, new_Ostat, how='left', on='Team')team_stats1 = pd.merge(team_stats1, new_Tstat, how='left', on='Team')return team_stats1.set_index('Team', inplace=False, drop=True)
获取每支队伍的Elo Score等级分函数,当在开始没有等级分时,将其赋予初始base_elo值:def get_elo(team):try:return team_elos[team]except:# 当最初没有elo时,给每个队伍最初赋base_eloteam_elos[team] = base_eloreturn team_elos[team]
定义计算每支球队的Elo等级分函数:# 计算每个球队的elo值
def calc_elo(win_team, lose_team):winner_rank = get_elo(win_team)loser_rank = get_elo(lose_team)rank_diff = winner_rank - loser_rankexp = (rank_diff * -1) / 400odds = 1 / (1 + math.pow(10, exp))# 根据rank级别修改K值if winner_rank < 2100:k = 32elif winner_rank >= 2100 and winner_rank < 2400:k = 24else:k = 16# 更新 rank 数值new_winner_rank = round(winner_rank + (k * (1 - odds))) new_loser_rank = round(loser_rank + (k * (0 - odds)))return new_winner_rank, new_loser_rank
基于我们初始好的统计数据,及每支队伍的 Elo score 计算结果,建立对应 2015~2016 年常规赛和季后赛中每场比赛的数据集(在主客场比赛时,我们认为主场作战的队伍更加有优势一点,因此会给主场作战队伍相应加上 100 等级分):
def build_dataSet(all_data):print("Building data set..")X = []skip = 0for index, row in all_data.iterrows():Wteam = row['WTeam']Lteam = row['LTeam']#获取最初的elo或是每个队伍最初的elo值team1_elo = get_elo(Wteam)team2_elo = get_elo(Lteam)# 给主场比赛的队伍加上100的elo值if row['WLoc'] == 'H':team1_elo += 100else:team2_elo += 100# 把elo当为评价每个队伍的第一个特征值team1_features = [team1_elo]team2_features = [team2_elo]# 添加我们从basketball reference.com获得的每个队伍的统计信息for key, value in team_stats.loc[Wteam].iteritems():team1_features.append(value)for key, value in team_stats.loc[Lteam].iteritems():team2_features.append(value)# 将两支队伍的特征值随机的分配在每场比赛数据的左右两侧# 并将对应的0/1赋给y值if random.random() > 0.5:X.append(team1_features + team2_features)y.append(0)else:X.append(team2_features + team1_features)y.append(1)if skip == 0:print('X',X)skip = 1# 根据这场比赛的数据更新队伍的elo值new_winner_rank, new_loser_rank = calc_elo(Wteam, Lteam)team_elos[Wteam] = new_winner_rankteam_elos[Lteam] = new_loser_rankreturn np.nan_to_num(X), y
最终在 main 函数中调用这些数据处理函数,使用 sklearn 的Logistic Regression方法建立回归模型:
if __name__ == '__main__':Mstat = pd.read_csv(folder + '/15-16Miscellaneous_Stat.csv')Ostat = pd.read_csv(folder + '/15-16Opponent_Per_Game_Stat.csv')Tstat = pd.read_csv(folder + '/15-16Team_Per_Game_Stat.csv')team_stats = initialize_data(Mstat, Ostat, Tstat)result_data = pd.read_csv(folder + '/2015-2016_result.csv')X, y = build_dataSet(result_data)# 训练网络模型print("Fitting on %d game samples.." % len(X))model = linear_model.LogisticRegression()model.fit(X, y)# 利用10折交叉验证计算训练正确率print("Doing cross-validation..")print(cross_val_score(model, X, y, cv = 10, scoring='accuracy', n_jobs=-1).mean())
最终利用训练好的模型在 16~17 年的常规赛数据中进行预测。
利用模型对一场新的比赛进行胜负判断,并返回其胜利的概率:
def predict_winner(team_1, team_2, model):features = []# team 1,客场队伍features.append(get_elo(team_1))for key, value in team_stats.loc[team_1].iteritems():features.append(value)# team 2,主场队伍features.append(get_elo(team_2) + 100)for key, value in team_stats.loc[team_2].iteritems():features.append(value)features = np.nan_to_num(features)return model.predict_proba([features])
在 main 函数中调用该函数,并将预测结果输出到16-17Result.csv文件中:
# 利用训练好的model在16-17年的比赛中进行预测print('Predicting on new schedule..')
schedule1617 = pd.read_csv(folder + '/16-17Schedule.csv')
result = []
for index, row in schedule1617.iterrows():team1 = row['Vteam']team2 = row['Hteam']pred = predict_winner(team1, team2, model)prob = pred[0][0]if prob > 0.5:winner = team1loser = team2result.append([winner, loser, prob])else:winner = team2loser = team1result.append([winner, loser, 1 - prob])
with open('16-17Result.csv', 'w') as f:writer = csv.writer(f)writer.writerow(['win', 'lose', 'probability'])writer.writerows(result)print('done.')
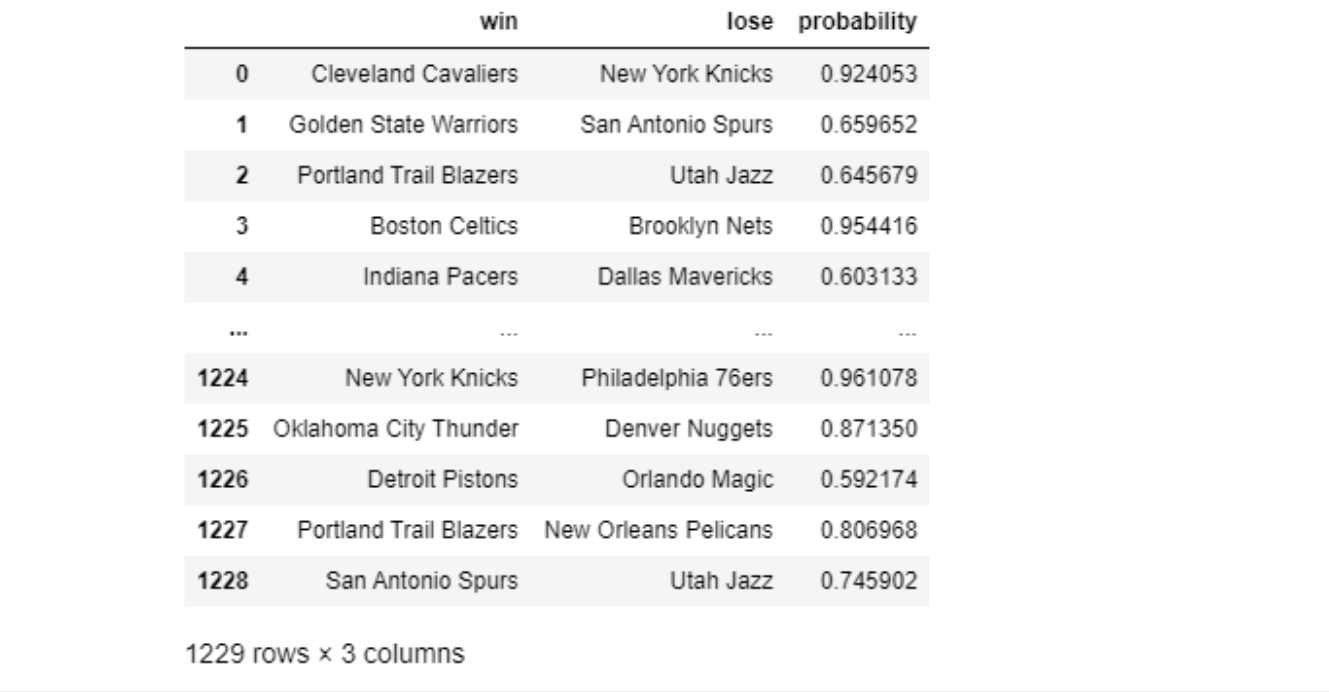
最后,我们实验 Pandas 预览生成预测结果文件16-17Result.csv文件:
pd.read_csv('16-17Result.csv',header=0)
三、 结果及分析
在本节课程中,我们利用Basketball-reference.com的部分统计数据,计算每支 NBA 比赛队伍的Elo socre,和利用这些基本统计数据评价每支队伍过去的比赛情况,并且根据国际等级划分方法Elo Score对队伍现在的战斗等级进行评分,最终结合这些不同队伍的特征判断在一场比赛中,哪支队伍能够占到优势。但在我们的预测结果中,与以往不同,我们没有给出绝对的正负之分,而是给出胜算较大一方的队伍能够赢另外一方的概率。当然在这里,我们所采用评价一支队伍性能的数据量还太少(只采用了 15~16 年一年的数据),如果想要更加准确、系统的判断,有兴趣的你当然可以从各种统计数据网站中获取到更多年份,更加全面的数据。
四、 源代码
import pandas as pd
import math
import csv
import random
import numpy as np
from sklearn import linear_model
from sklearn.model_selection import cross_val_score
# 当每支队伍没有elo等级分时,赋予其基础elo等级分
base_elo = 1600
team_elos = {}
team_stats = {}
X = []
y = []
# 存放数据的目录
folder = 'data'# 根据每支队伍的Miscellaneous Opponent,Team统计数据csv文件进行初始化
def initialize_data(Mstat, Ostat, Tstat):new_Mstat = Mstat.drop(['Rk', 'Arena'], axis=1)new_Ostat = Ostat.drop(['Rk', 'G', 'MP'], axis=1)new_Tstat = Tstat.drop(['Rk', 'G', 'MP'], axis=1)team_stats1 = pd.merge(new_Mstat, new_Ostat, how='left', on='Team')team_stats1 = pd.merge(team_stats1, new_Tstat, how='left', on='Team')return team_stats1.set_index('Team', inplace=False, drop=True)def get_elo(team):try:return team_elos[team]except:# 当最初没有elo时,给每个队伍最初赋base_eloteam_elos[team] = base_eloreturn team_elos[team]# 计算每个球队的elo值def calc_elo(win_team, lose_team):winner_rank = get_elo(win_team)loser_rank = get_elo(lose_team)rank_diff = winner_rank - loser_rankexp = (rank_diff * -1) / 400odds = 1 / (1 + math.pow(10, exp))# 根据rank级别修改K值if winner_rank < 2100:k = 32elif winner_rank >= 2100 and winner_rank < 2400:k = 24else:k = 16# 更新 rank 数值new_winner_rank = round(winner_rank + (k * (1 - odds)))new_loser_rank = round(loser_rank + (k * (0 - odds)))return new_winner_rank, new_loser_rankdef build_dataSet(all_data):print("Building data set..")X = []skip = 0for index, row in all_data.iterrows():Wteam = row['WTeam']Lteam = row['LTeam']#获取最初的elo或是每个队伍最初的elo值team1_elo = get_elo(Wteam)team2_elo = get_elo(Lteam)# 给主场比赛的队伍加上100的elo值if row['WLoc'] == 'H':team1_elo += 100else:team2_elo += 100# 把elo当为评价每个队伍的第一个特征值team1_features = [team1_elo]team2_features = [team2_elo]# 添加我们从basketball reference.com获得的每个队伍的统计信息for key, value in team_stats.loc[Wteam].iteritems():team1_features.append(value)for key, value in team_stats.loc[Lteam].iteritems():team2_features.append(value)# 将两支队伍的特征值随机的分配在每场比赛数据的左右两侧# 并将对应的0/1赋给y值if random.random() > 0.5:X.append(team1_features + team2_features)y.append(0)else:X.append(team2_features + team1_features)y.append(1)if skip == 0:print('X',X)skip = 1# 根据这场比赛的数据更新队伍的elo值new_winner_rank, new_loser_rank = calc_elo(Wteam, Lteam)team_elos[Wteam] = new_winner_rankteam_elos[Lteam] = new_loser_rankreturn np.nan_to_num(X), yif __name__ == '__main__':Mstat = pd.read_csv(folder + '/15-16Miscellaneous_Stat.csv')Ostat = pd.read_csv(folder + '/15-16Opponent_Per_Game_Stat.csv')Tstat = pd.read_csv(folder + '/15-16Team_Per_Game_Stat.csv')team_stats = initialize_data(Mstat, Ostat, Tstat)result_data = pd.read_csv(folder + '/2015-2016_result.csv')X, y = build_dataSet(result_data)# 训练网络模型print("Fitting on %d game samples.." % len(X))model = linear_model.LogisticRegression()model.fit(X, y)# 利用10折交叉验证计算训练正确率print("Doing cross-validation..")print(cross_val_score(model, X, y, cv = 10, scoring='accuracy', n_jobs=-1).mean())def predict_winner(team_1, team_2, model):features = []# team 1,客场队伍features.append(get_elo(team_1))for key, value in team_stats.loc[team_1].iteritems():features.append(value)# team 2,主场队伍features.append(get_elo(team_2) + 100)for key, value in team_stats.loc[team_2].iteritems():features.append(value)features = np.nan_to_num(features)return model.predict_proba([features])# 利用训练好的model在16-17年的比赛中进行预测print('Predicting on new schedule..')schedule1617 = pd.read_csv(folder + '/16-17Schedule.csv')result = []for index, row in schedule1617.iterrows():team1 = row['Vteam']team2 = row['Hteam']pred = predict_winner(team1, team2, model)prob = pred[0][0]if prob > 0.5:winner = team1loser = team2result.append([winner, loser, prob])else:winner = team2loser = team1result.append([winner, loser, 1 - prob])with open('16-17Result.csv', 'w') as f:writer = csv.writer(f)writer.writerow(['win', 'lose', 'probability'])writer.writerows(result)print('done.')pd.read_csv('16-17Result.csv', header=0)