- 论深度学习
笔者对于深度学习有着自己独特的见解…借这个机器学习课程大作业,发表一下我的观点。
时光荏苒,社会的发展日新月异,越来越多的数据分析师、数据科学家倾向于对某次统计过程的分析进行研究,并把这种统计的模型称之为“人工智能”。没错,人工智能就是一个统计数据的过程。自己在学习的过程中很多时候也会怀疑,现阶段的深度学习理论究竟是不是真正的“人工智能”。
人类,作为碳基生物,其如椰子般大的大脑却能存储近77TB的权重,并且可以自适应训练,但是我们在做深度学习训练的时候却很容易发现,其一是需要外部庞大的算力去训练模型,其二是训练出来的模型往往达不到人类这样智能化的水准。因此不得不怀疑我们的深度学习理论究竟是否正确,就算我们拥有强大的算力,但是耗费的资源也是庞大的,如果未来能够突破这一点,重新定义人工智能,能够更快速的拟合权重,能够自适应地学习,那我们就会从现在的“弱”人工智慧时代进入“强”人工智能时代。
2023年2月,美国OPENAI公司发布了一款名为CHATGPT的智能对话聊天机器人,一经发布,火爆全网。该产品不仅能够智能完成各种写作任务,甚至能一定程度上替代“码农”。在我看来,CHATGPT一定程度上是一次AI应用领域的革新。人工智能的发展史其实是曲折的,一直到现在,即便是前沿科学家,或许也并不知道在训练的过程中,这些权重干了些什么事情。
1943年,神经科学家麦卡洛克和数学家皮兹在《数学生物物理学公告》上发表论文《神经活动中内在思想的逻辑演算》。该文中,两位科学家建立了神经网络数学模型,称之为MCP模型。该模型其实就是按照生物神经元的结构和工作构造出来的一个抽象和简化的模型,也由此打开了人工神经网络的大门。MCP模型原理如图1所示。

图1 MCP模型原理图
1958年,计算机科学家罗森布拉特提出了两层神经元组成的神经网络,称之为“感知器”(Perceptrons)。第一次将MCP用于机器学习分类。“感知器”算法算法使用MCP模型对输入的多维数据进行二分类,且能够使用梯度下降法从训练样本中自动学习更新权值。1962年,该方法被证明为能够收敛,理论与实践效果引起第一次神经网络的浪潮。
1969年,美国数据科学家,以及人工智能先驱Marvin Minsky提出感知机本质上是一种线性模型,只能处理线性分类,如果数据任务变成了非线性关系,那么连最简单的亦或问题都无法正确分类。这次提出,等于宣告了感知机的错误,因此人工智能的研究也陷入了近20年的停滞。
1986年,神经网络之父Geoffrey Hinton在1986年发明了适用于多层感知机的BP神经网络,并采用Sigmoid函数进行非线性映射,该方法的出现,掀起了人工智能的第二次浪潮。对于sigmoid函数,其实就是把数据映射到概率。
1991年BP算法被指出存在梯度消失的问题,也就是说在误差梯度后项传递的过程中,后层梯度以乘性方式叠加至前层,因此无法对前层进行有效学习,这个问题直接阻碍了深度学习的进一步发展。
同年代,支持向量机等各类机器学习模型被提出,SVM是一种有监督学习模型,以统计学为基础,与神经网络存在明显差异。其原理如图2所示。

图.2支持向量机原理图
2011年,ReLu激活函数的提出,能够有效的抑制梯度消失问题。
2012年,Hinton课题组,首次参加ImageNet图像识别比赛,通过其构建的CNN网络AlexNet一举夺得冠军,也正因这次比赛,我们常听到的卷积神经网络引起了更多的数据科学研究者的重视。其AlexNet原理如图3所示。

图.3 AlexNet模型原理图
2015年,清华大学毕业生、FAIR研究科学家何恺明在ImageNet图像识别大赛中,采用“深度残差学习”系统,击败谷歌、英特尔、高通等业界团队,荣获第一,他也是AI领域研究者的中国代表之一。深度残差系统是一种影响深远的网络模型,一方面是残差网络更好的拟合分类函数以获得更高的分类精度,另一方面是残差网络如何解决网络在层数加深时优化训练上的难题。其原理图如图4所示。

图.4 Resnet 2015原理图
2017年Google发表论文《Attention is All You Need》提出了一种心的神经网络架构,Transformer,仅仅依赖注意力机制就可以处理序列数据,从而抛弃了RNN、CNN等模型。这个新的网络结构,刷爆了各大翻译任务,目前火热的CHATGPT也正是以Tansformer为基础的大语言模型。其原理图如图5所示。

图.5 Transformer结构原理图
其实大致的主干AI研究历程应该就是上面所讲,还有一些偏应用的研究历程,比如图像识别、目标检测、NLP、语义分割等。
目标检测,目前常用的深度学习模型是YOLO系列,由于特征信息和评价指标等问题,该类任务仍然存在很多难点与挑战。
- 检测目标尺寸很小,导致占比小,检测难度大
- 检测目标尺度变化大,网络难以提取高效特征
- 待检测目标所在背景复杂,噪音干扰严重,检测难度大
- 检测目标与背景颜色对比度低,网络难以提取出具有判别性的特征
- 各待检测目标之间的数量极度不均衡,导致样本不均匀
- 检测算法的速度与精度难以取得良好平衡
NLP,用自然语言与计算机进行通信,这是人们长期以来所追求的。因为它既有明显的实际意义,同时也有重要的理论意义,人们也可通过它进一步了解人类的语言能力和智能的机制。目前最新的进展就是以前文中所提到的Transformer模型为基础,进行训练。
语义分割,图像语义分割,它是将整个图像分成一个个像素组,然后对其进行标记和分类。特别地,语义分割试图在语义上理解图像中每个像素的角色。实际上就是每个图像中都包含一定的语义信息,然后你通过模型训练,预测图像中不同类别事物的语义信息进行标记不同的颜色,常用的语义分割模型有FCN、U-Net模型等。为了便于理解,展示其中的效果图如图6和图7所示。

图.6原始图
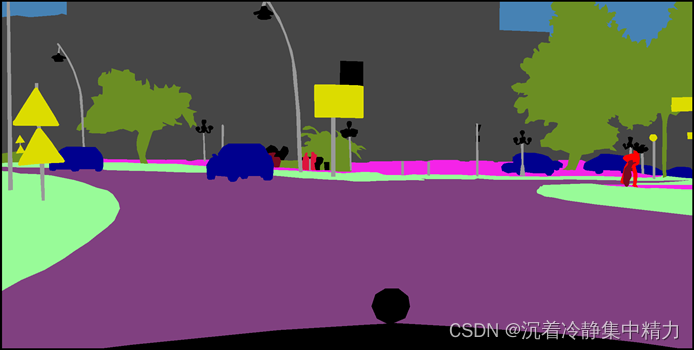
图.7语义分割图
对于AI的研究,本文就讨论上述内容,希望能帮助大家更好的理解现阶段AI的发展历程以及AI的主要研究方向。




![luogu p4556 [Vani有约会]雨天的尾巴 树上差分,最近公共祖先,线段树合并](https://img-blog.csdn.net/20181018202147519?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMxOTA4Njc1/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)