1、工作中遇到一个场景就是对某个单一接口进行循环请求,并需要获取每次请求后返回的相应数据;
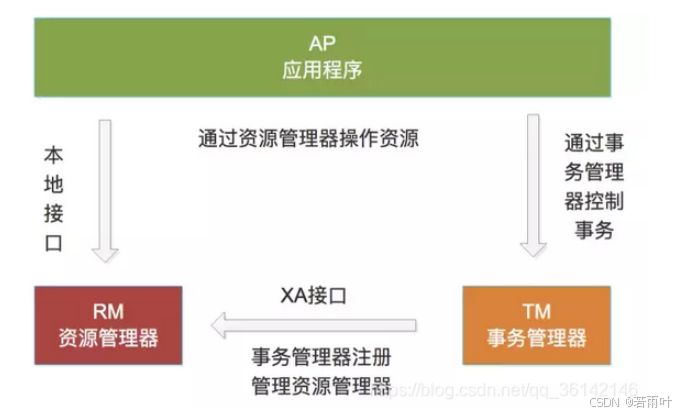
2、首先就在jmeter对接口相关组件进行配置,需要组件有:循环控制器、CSV数据文件设置、计数器、访问接口、HTTP信息头管理器、正则表达式提取器;BeanShell取样器;这些组件排列方式如图所示:

3、循环控制器:其它组件都在循环控制器下,需要循环访问多少次就配置多少次循环

4、CSV数据文件设置:是用于循环访问接口中从配置文件提取参数时用到的配置组件,文件名:参数文件路径;文件编码:如果有中文则需要选择:UTF-8;变量名:如果是一个参数就输入一个变量名称,如:userID,两个就输入两个名称;如:user,pass 其它配置默认即可。

引用文件配置如下:两种方式手动在txt文件编辑,两个引用tab页隔开,或者通过excel表格配置好后复制过来。不要有空白行。

5、计数器:用于接口访问时给接口编号。Starting value:初始值。递增:每次增加多少个;引用名称:设置引用变量:num

6、除BeanShell取样器是在循环控制器下且放在最后一个,其它的组件就是在访问接口下级进行配置了,信息头管理器的配置不赘述了,该接口下的正则表达式是用来提取接口返回的响应数据配置如下:
引用名称:result${num} 后面BeanShell取样器中响应数据写入文件时需要引用的参数,${num}是计数器,每次循环加1,在BeanShell取样器中,需要用函数来存储和传递${num},不能直接引用
正则表达式:(.+) 表示提取全部相应响应数据

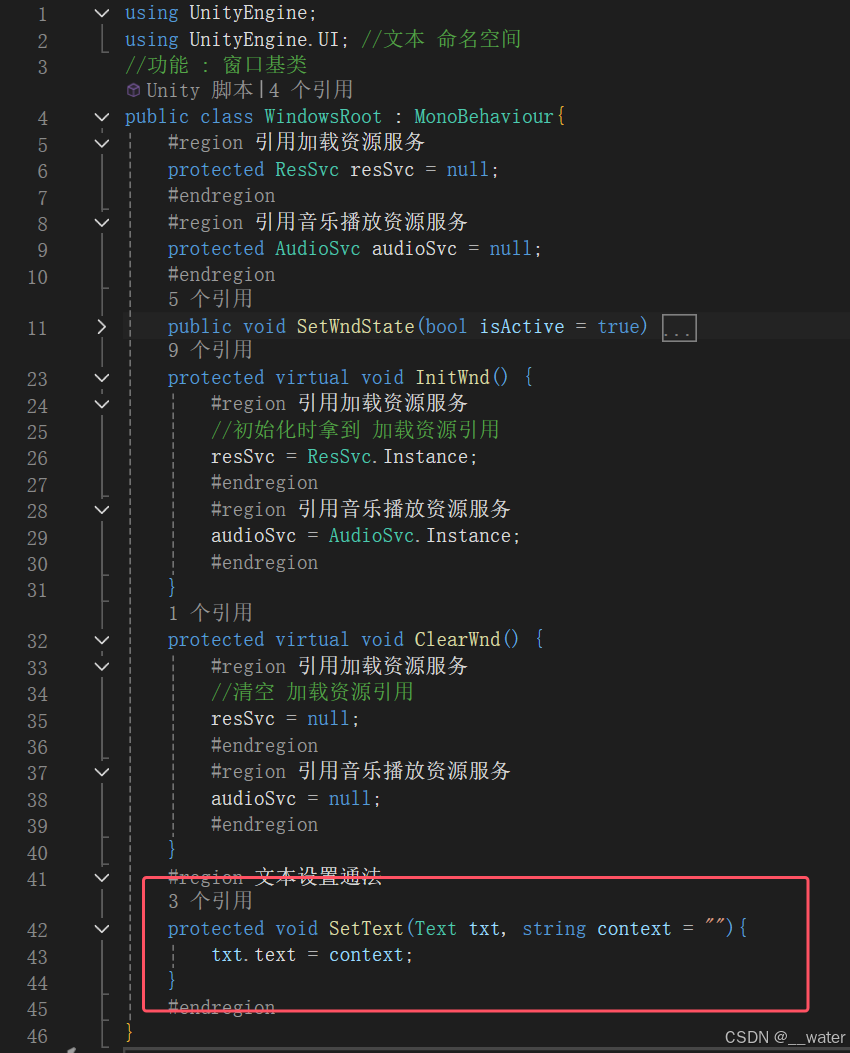
7、BeanShell取样器,着重需要配置该取样器,其位置是处于循环控制器的下级,并在访问接口组件的下方如图所示:
脚本内容:
//指定需要写入到哪个文件,格式:TXT,csvFileWriter file = new FileWriter("D:\\Program Files\\apache-jmeter-5.1.1\\bin\\WedoJB\\text.txt",true);//创建一个字符缓存输出流BufferedWriter out = new BufferedWriter(file);//写入文件内容//vars.get:获取 jmeter 中的变量值//将计数器组件参数 num 通过vars.get函数传递给字符串 countString count=vars.get("num");//通过Integer.parseInt函数将字符串count类型转化为int类型并赋值给countNumint countNum=Integer.parseInt(count);//"接口"+countNum+":写入文件每一行记录接口循环数
//vars.get("result"+countNum):引用正则表达式组件中的参数,countNum对应${num}
//\r\n\r\n 表示两次回车换行。
out.write("接口"+countNum+":\r\n"+vars.get("result"+countNum)+"\r\n\r\n");//关闭写数据流out.close();//关闭文件
file.close();
配置完成后,写入文件格式如下: