vim 中粘贴内容时提示: -- (insert) VISUAL --


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/6829.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

总结与展望,龙蜥社区第 30 次运营委员会会议线上召开
2025 年 1 月 20 日,龙蜥社区召开了第 30 次运营委员会线上会议,来自 24 家理事单位的 22 位委员及委员代表出席,本次会议由运营委员凝思软件李晨斌主持。会上总结和回顾了龙蜥社区 1 月运营发展情况,同步了龙蜥社区 3 大运营目标…

新型人工智能“黑帽”工具:GhostGPT带来的威胁与挑战
生成式人工智能的发展既带来了有益的生产力转型机会,也提供了被恶意利用的机会。 最近,Abnormal Security的研究人员发现了一个专门为网络犯罪创建的无审查AI聊天机器人——GhostGPT,是人工智能用于非法活动的新前沿,可以被用于网…

计算机网络 (53)互联网使用的安全协议
一、SSL/TLS协议 概述: SSL(Secure Sockets Layer)安全套接层和TLS(Transport Layer Security)传输层安全协议是工作在OSI模型应用层的安全协议。SSL由Netscape于1994年开发,广泛应用于基于万维网的各种网络…

grafana新增email告警
选择一个面板 比如cpu
新增一个临界点表达式 input选A 就是A的值达到某个临界点 触发告警 我这边IS ABOVE0.15就是cpu大于0.15%就触发报警,这个值怎么填看指标的值显示
这里要设置一下报警条件 这边随便配置下 配置标签和通知,选择你的邮件 看下告警…

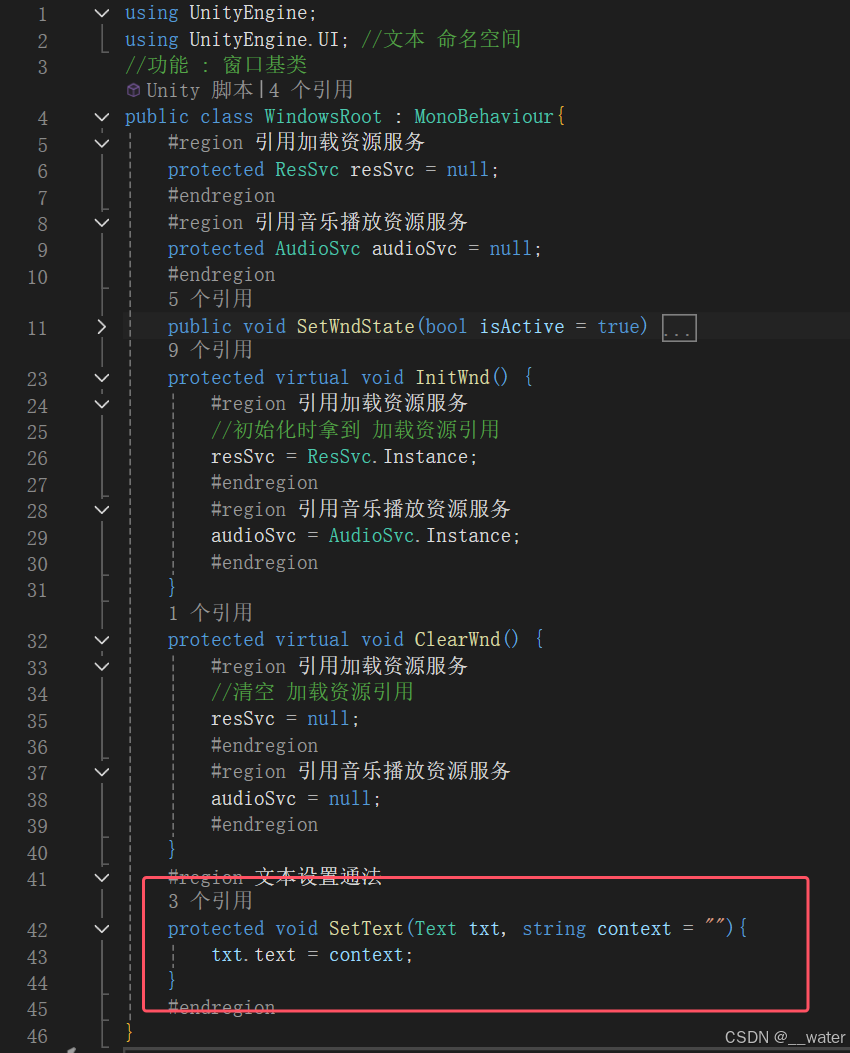
24_游戏启动逻辑梳理总结
首先这个项目从游戏根入口GameRoot.cs的初始化开始 分为 服务层初始化Svc.cs 与 业务系统层初始化Sys.cs 而服务层 分为 资源加载服务层ResSvc.cs 与 音乐播放服务层AudioSvc.cs
而在 资源加载服务层ResSvc.cs中 初始化了 名字的 配置文件 而音乐播放服务层AudioSvc.cs 暂时没…

UE求职Demo开发日志#8 强化前置条件完善,给物品加图标
1 强化前置条件完善
StrengthManager里实现一个Check前置的函数
bool CheckPreAllIsActive(int index),所有的前置都已经激活就返回true,否则返回false
之后在强化的时候加入条件检查:
1.所有前置技能全部激活
2.本身没有强化过
最后测…

QT:tftp client 和 Server
1.TFTP简介
TFTP(Trivial File Transfer Protocol,简单文件传输协议)是TCP/IP协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为69。
FTP是一个传输文件的简单协议,…

dm8在Linux环境安装精简步骤说明(2024年12月更新版dm8)
dm8在Linux环境安装详细步骤 - - 2025年1月之后dm8 环境介绍1 修改操作系统资源限制2 操作系统创建用户3 操作系统配置4 数据库安装5 初始化数据库6 实例参数优化7 登录数据库配置归档与备份8 配置审计9 创建用户10 屏蔽关键字与数据库兼容模式11 jdbc连接串配置12 更多达梦数据…

24年总结 -- 共赴心中所向往的未来
一、前言
我又回来了,前阵子忙着期末考试的东西,也是快半个月没更新了,刚好前几天报名了博客之星的评选,也很幸运的入围了,也借此机会来回顾一下关于2024年的个人成长、创作经历等。
二、个人 本人是一个双非学校的软…

动态规划一> 让字符串成为回文串的最少插入次数
题目: 解析: 状态表示状态转移方程: 初始化填表顺序返回值: 代码: public int minInsertions(String ss) {char[] s ss.toCharArray();int n s.length; int[][] dp new int[n][n]; for(int i n-1; i > 0;…
![2025.1.21——八、[HarekazeCTF2019]Avatar Uploader 2(未完成) 代码审计|文件上传](https://i-blog.csdnimg.cn/direct/2ed2898343e04e32b561c201cb7d5cf5.png)
2025.1.21——八、[HarekazeCTF2019]Avatar Uploader 2(未完成) 代码审计|文件上传
题目来源:buuctf [HarekazeCTF2019]Avatar Uploader 2 一、打开靶机,整理信息
跟Avatar Uploader 1 题目长得一样,先上传相同文件看看情况,另外这道题还有源码,可以看看
二、解题思路
step 1:上传同类…

Elementor Pro 3.27 汉化版 2100套模板 安装教程 wordpress主题中文编辑器插件免费下载
插件下载地址 https://a5.org.cn/a5ziyuan/732506.html 转载请注明出处!
Elementor Pro 是流行的 Elementor 的付费扩展 WordPress 页面构建器插件. 它为免费的 Elementor 插件添加了许多附加功能和增强功能,使其成为创建美丽的更强大的工具 WordPress 网站。
如果…

深入理解动态规划(dp)--(提前要对dfs有了解)
前言:对于动态规划:该算法思维是在dfs基础上演化发展来的,所以我不想讲的是看到一个题怎样直接用动态规划来解决,而是说先用dfs搜索,一步步优化,这个过程叫做动态规划。(该文章教你怎样一步步的…

0基础跟德姆(dom)一起学AI 自然语言处理19-输出部分实现
1 输出部分介绍
输出部分包含: 线性层softmax层 2 线性层的作用
通过对上一步的线性变化得到指定维度的输出, 也就是转换维度的作用.
3 softmax层的作用
使最后一维的向量中的数字缩放到0-1的概率值域内, 并满足他们的和为1.
3.1 线性层和softmax层的代码分析
# 解码器类…

uart iic spi三种总线的用法
1、uart串口通信 这种连接方式抗干扰能力弱,旁边有干扰源就会对收发的电平数据造成干扰,进而导致数据失真 这种连接方式一般适用于一块板子上面的两个芯片之间进行数据传输 ,属于异步全双工模式。 1.空闲位:当不进行数据收发时&am…


三元组抽取在实际应用中如何处理语义模糊性?
在实际应用中,三元组抽取面临语义模糊性的问题,这主要体现在输入文本的非规范描述、复杂句式以及多义性等方面。为了有效处理这种模糊性,研究者们提出了多种方法和技术,以下是一些关键策略: 基于深度学习的方法 深度学…
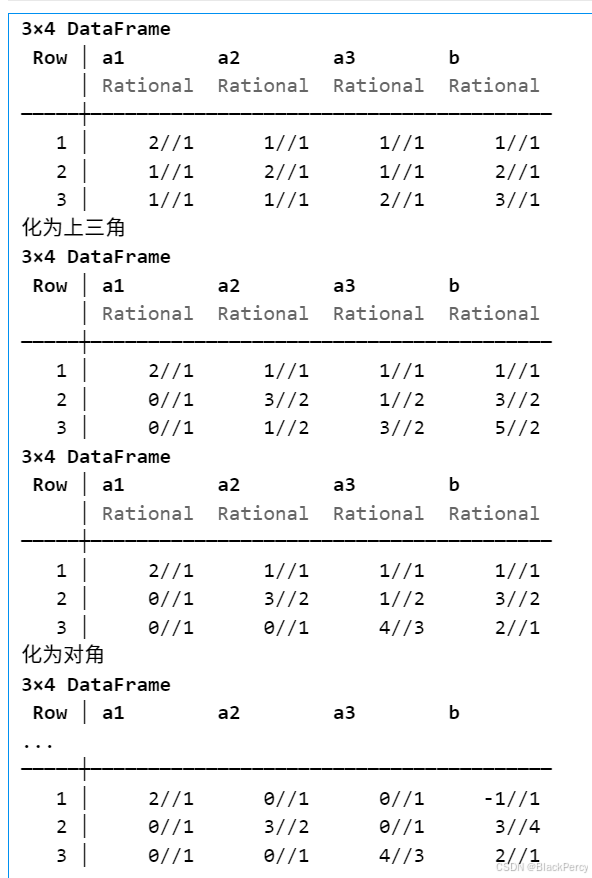
【线性代数】基础版本的高斯消元法
[精确算法] 高斯消元法求线性方程组 线性方程组
考虑线性方程组, 已知 A ∈ R n , n , b ∈ R n A\in \mathbb{R}^{n,n},b\in \mathbb{R}^n A∈Rn,n,b∈Rn, 求未知 x ∈ R n x\in \mathbb{R}^n x∈Rn A 1 , 1 x 1 A 1 , 2 x 2 ⋯ A 1 , n x n b 1…
推荐文章
- .NET9增强OpenAPI规范,不再内置swagger
- @Autowired和@Resource的区别是?
- [250217] x-cmd 发布 v0.5.3:新增 DeepSeek AI 模型支持及飞书/钉钉群机器人 Webhook 管理
- [Lc滑动窗口_1] 长度最小的数组 | 无重复字符的最长子串 | 最大连续1的个数 III | 将 x 减到 0 的最小操作数
- [Linux]在vim中批量注释与批量取消注释
- [ProtoBuf] 介绍 | 保姆级win/linux安装教程
- [Web 安全] PHP 反序列化漏洞 —— PHP 魔术方法
- [特殊字符]1.2.1 新型基础设施建设
- “推理”(Inference)在深度学习和机器学习的语境
- 《白帽子讲 Web 安全》之移动 Web 安全
- 「清华大学、北京大学」DeepSeek 课件PPT专栏
- 【12】Word:张老师学术论文❗