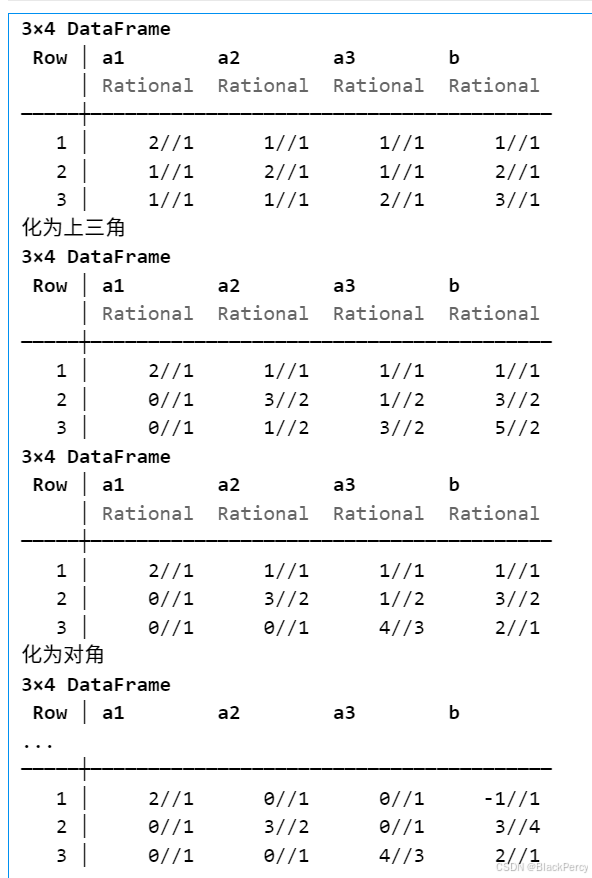
npm install时报UNMET PEER DEPENDENCY
现象
npm install时报UNMET PEER DEPENDENCY,且执行npm install好几遍仍报这个。
原因
不是真的缺少某个包,而是安装的依赖版本不对,警告你应该安装某一个版本。
真的缺少某个包。
解决
看了下package.json文件,我的react是有的,只不过不是15.6.2的版本(也就是原因1)如果你不想切换更高版本,那么这个就是一个警告忽略即可。
看底下的警告代码可以发现这里的jquery和popper是bootscrap需要的依赖,项目基本没有用到bootscrap框架,所以我也就直接忽略了。
不过如果想要解决这个警告信息,网上查了方案可供参考:
方案一
npm -rf node_modules/ # 删除已安装的模块
npm cache clean # 清除 npm 内部缓存
npm install # 重新安装
方案二
npm -rf node_modules/ # 删除已安装的模块
npm update -g npm # 更新 npm
npm install # 重新安装
npm install
现象

npm install时抛出警告:无效名称,进而导致install无效,node_modules文件中没有下载下来相应的依赖。
原因
leader单词之后的空格导致的
网上检索一些网友也抛出和我一样的警告,只不过他的name字段中添加的是中文





![2025.1.21——八、[HarekazeCTF2019]Avatar Uploader 2(未完成) 代码审计|文件上传](https://i-blog.csdnimg.cn/direct/2ed2898343e04e32b561c201cb7d5cf5.png)