Web Speech API有两个功能:语音合成(文本到语音)和语音识别(语音到文本)。在上一篇文章中,我解释了语音合成,但这次SpeechRecognition我将解释使用 API 的浏览器的语音识别和语音转录的方法。
识别用户发出的语音命令,可以提供比平时更沉浸的界面,更容易获得喜欢语音操作的用户。根据谷歌 2018 年的一份报告,全球 27% 的在线人口在移动设备上使用语音搜索。通过使用这次解释的浏览器的语音识别功能,您可以在您的 Web 应用程序中提供从基本语音搜索到交互式机器人的广泛功能。
让我们从下一节了解 API 的工作原理,看看您可以做什么。
必要的东西
准备以下工具来创建一个示例应用程序,让您可以实际体验 API。
- 谷歌浏览器
- 文本编辑器
这次我们将使用 HTML、CSS 和 JavaScript 创建一个应用程序。创建一个新的工作目录并将起始 HTML和CSS保存在此目录中。当您在浏览器中打开保存的 HTML 文件时,您将看到与以下屏幕截图相同的屏幕。
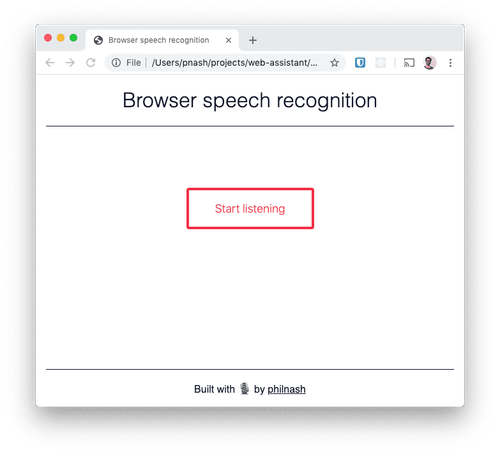
让我们从下一节中了解如何在浏览器中听到和识别音频。
语音识别API
在向示例应用程序添加语音识别功能之前,让我们使用浏览器提供的开发人员工具检查可用性。打开 Chrome 开发者工具并在控制台中输入以下代码。
speechRecognition = new webkitSpeechRecognition();
speechRecognition.onresult = console.log;
speechRecognition.start();
当您运行此代码时,Chrome 会请求使用麦克风的权限。如果您在 Web 服务器上托管页面,请记住您在浏览器中的权限。允许使用麦克风并说话。当您结束对话时,它将SpeechRecognitionEvent被记录在控制台上。
这只是三行代码,但它做了很多工作。首先,SpeechRecognition创建 API 的一个实例(在开头添加供应商名称“webkit”)并告诉该实例记录您从语音识别服务收到的所有结果。最后,我们指导您开始聆听和识别。
此外,此实例也反映了标准设置。例如,当一个对象收到一个结果时,它就会停止监听。start您必须再次调用该方法才能继续转录。此外,您只会收到语音识别服务的最终结果。为此,您还可以启用连续语音识别并在通话时输出识别结果。设置方法将在后面解释。
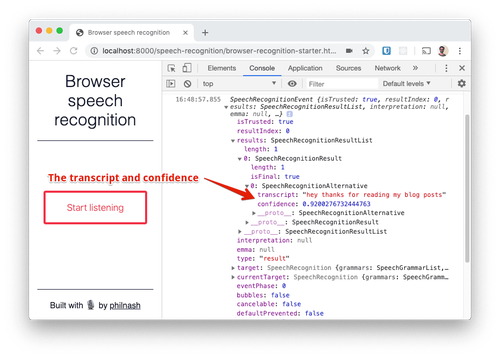
SpeechRecognitionEvent让我们检查输出到控制台的内容。最重要的属性是results。这是SpeechRecognitionResult包含的列表。在这个屏幕截图中,我在停止听之前只说了一个词,所以我只看到一个结果对象。此对象SpeechRecognitionAlternative包含一个包含更多内容的列表。在 SpeechRecgnitionAlternative 中包含的列表的顶部,显示语音识别的转录结果和可靠性(0 到 1)。默认情况下,只显示一个结果,但您可以将其配置为从语音识别服务接收更多结果。如果您希望用户选择与口语最相似的结果,这将非常有用。
这个怎么运作
在浏览器中调用此功能语音识别是不准确的。Chrome 现在获取音频并将其发送到 Google 的服务器以转换为文本。为此,Chrome 和一些基于 Chromium 的浏览器目前仅支持语音识别。
Mozilla 已经在 Firefox 中内置了语音识别支持。此功能仅当您在 Firefox Nightly 版本中启用该标志时才可用,因为我们正在协商使用 Google Cloud Speech API。Mozilla 正在开发自己的DeepSpeech 引擎,但由于专注于浏览器支持,我们决定也以这种方式使用 Google 的服务。
语音识别使用服务器端 API,因此用户必须在在线环境中使用该 API。离线本地语音识别将很快发布,但目前有限。
使用您之前下载的入门代码和开发工具代码创建一个小应用程序,让我们实时识别用户的声音。
Web 应用程序中的语音识别
打开您之前下载的 HTML<script>并在底部的标记之间执行该过程。首先DOMContentLoaded侦听事件并获取对要使用的 HTML 元素的引用。
<script> window.addEventListener("DOMContentLoaded", () => { const button = document.getElementById("button"); const result = document.getElementById("result"); const main = document.getElementsByTagName("main")[0]; });
</script>
检查浏览器是否支持SpeechRecognition或webkitSpeechRecognition支持该对象,如果不支持则显示无法继续的消息。
<script> window.addEventListener("DOMContentLoaded", () => { const button = document.getElementById("button"); const result = document.getElementById("result"); const main = document.getElementsByTagName("main")[0]; const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition if (typeof SpeechRecognition === "undefined") { button.remove(); const message = document.getElementById("message"); message.removeAttribute("hidden"); message.setAttribute("aria-hidden", "false"); } else { // good stuff to come here }
});
</script>
SpeechRecognition如果您可以访问,请准备使用。定义一个变量,指示您是否正在识别语音并创建语音识别对象的实例。此外,我们定义了启动、停止和响应新结果的三个函数。
} else { let listening = false; const recognition = new SpeechRecognition(); const start = () => {}; const stop = () => {}; const onResult = event => {};
}
start 函数启动语音识别并更改按钮文本。此外,向主元素添加一个类并启动一个动画,显示页面正在侦听。停止功能则相反。
const start = () => { recognition.start(); button.textContent = "Stop listening"; main.classList.add("speaking");
};
const stop = () => { recognition.stop(); button.textContent = "Start listening"; main.classList.remove("speaking");
};
然后,当它收到语音识别的结果时,它会在页面上呈现所有结果。在此示例中,我们将执行直接 DOM 操作并将前面描述的SpeechRecognitionResult对象<div>添加为一个段落以显示结果。在标记为 final 的结果中添加 CSS 类,以显示最终结果和中间结果之间的差异。
const onResult = event => { result.innerHTML = ""; for (const res of event.results) { const text = document.createTextNode(res[0].transcript); const p = document.createElement("p"); if (res.isFinal) { p.classList.add("final"); } p.appendChild(text); result.appendChild(p); } };
在开始语音识别之前,应用此应用程序使用的设置。在这个版本中,当检测到语音结束时,它不会结束并始终记录结果。也就是说,转录结果始终显示在页面上,直到按下停止按钮。此外,将其设置为在您说话时显示中间结果(就像在 Twilio 中使用<Gather>和partialResultCallback在语音通话期间始终能够识别您的声音一样)。并添加一个结果监听器。
const onResult = event => {// onResult code} recognition.continuous = true; recognition.interimResults = true; recognition.addEventListener("result", onResult);
}
最后,向按钮添加一个侦听器,以便您可以启动和停止语音识别。
const onResult = event => { // onResult code } recognition.continuous = true; recognition.interimResults = true; recognition.addEventListener("result", onResult); button.addEventListener("click", () => { listening ? stop() : start(); listening = !listening; });
}
请重新加载浏览器并尝试操作。
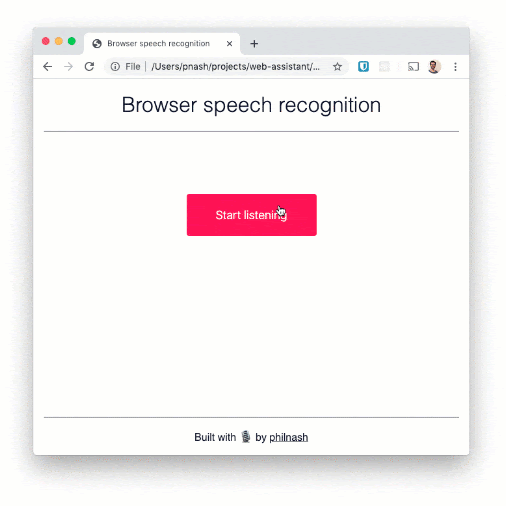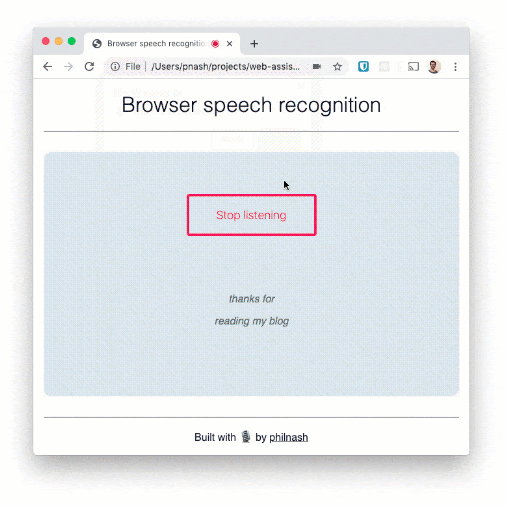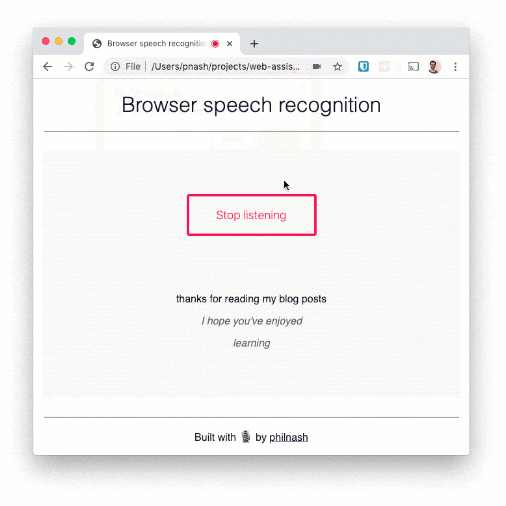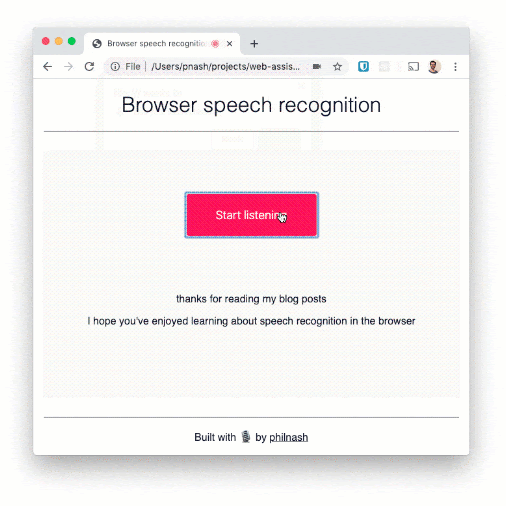
阅读几句话并确保它们出现在页面上。这种语音识别虽然有很高的单词识别能力,但在标点符号方面并不是很擅长。例如,如果您想将其用于听写,则需要多做一点开发。
与您的浏览器交谈
在这篇文章中,我解释了浏览器的语音识别。另外,在上一篇文章中,我介绍了如何设置浏览器的阅读功能。如果您将这些步骤与使用 Twilio Autopilot 的助手结合起来,您将能够构建有趣的项目。
如果您想试用本文中的示例,可以在Glitch 中查看它们。如果您需要源代码,可以从GitHub 上的网络助手存储库中获取。