前置条件:
安装有chrome谷歌浏览器的电脑
使用步骤:
1.打开chrome扩展插件
2.点击管理扩展程序
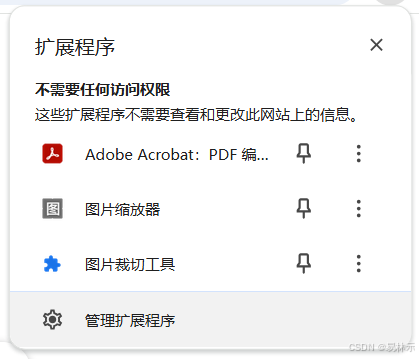
3.加载已解压的扩展程序
4.选择对应文件夹
5.成功后会出现一个扩展小程序
6.点击对应小程序
7.使用小程序

8.拖拽成功后会自动保存到下载
代码:
1.manifest.json
{"manifest_version": 3,"name": "图片缩放器","version": "1.0","description": "将图片缩放至128x128像素","permissions": ["contextMenus","downloads"],"background": {"service_worker": "background.js"},"action": {"default_popup": "popup.html"}
} 2.popup.js
document.addEventListener('DOMContentLoaded', function() {const dropZone = document.getElementById('dropZone');const fileInput = document.getElementById('fileInput');const preview = document.getElementById('preview');// 点击上传区域触发文件选择dropZone.addEventListener('click', () => {fileInput.click();});// 处理拖拽事件dropZone.addEventListener('dragover', (e) => {e.preventDefault();dropZone.classList.add('dragover');});dropZone.addEventListener('dragleave', () => {dropZone.classList.remove('dragover');});dropZone.addEventListener('drop', (e) => {e.preventDefault();dropZone.classList.remove('dragover');const files = e.dataTransfer.files;if (files.length > 0) {handleImage(files[0]);}});// 处理文件选择fileInput.addEventListener('change', (e) => {if (e.target.files.length > 0) {handleImage(e.target.files[0]);}});// 处理图片function handleImage(file) {if (!file.type.startsWith('image/')) {alert('请选择图片文件!');return;}const reader = new FileReader();reader.onload = function(e) {const img = new Image();img.onload = function() {// 创建canvas进行缩放const canvas = document.createElement('canvas');canvas.width = 128;canvas.height = 128;const ctx = canvas.getContext('2d');ctx.drawImage(img, 0, 0, 128, 128);// 显示预览preview.src = canvas.toDataURL();preview.style.display = 'block';// 下载图片canvas.toBlob((blob) => {const filename = 'resized_' + file.name;chrome.downloads.download({url: URL.createObjectURL(blob),filename: filename});});};img.src = e.target.result;};reader.readAsDataURL(file);}
}); 3.popup.html
<!DOCTYPE html>
<html>
<head><meta charset="UTF-8"><style>body {width: 300px;padding: 10px;}#dropZone {width: 280px;height: 150px;border: 2px dashed #ccc;text-align: center;padding: 20px;margin: 10px 0;}#dropZone.dragover {background: #e1e1e1;border-color: #999;}#preview {max-width: 280px;margin-top: 10px;}</style>
</head>
<body><h3>图片缩放器</h3><div id="dropZone">拖拽图片到这里或点击上传<input type="file" id="fileInput" accept="image/*" style="display: none;"></div><img id="preview" style="display: none;"><script src="popup.js"></script>
</body>
</html> 4.background.js
chrome.runtime.onInstalled.addListener(() => {chrome.contextMenus.create({id: "resizeImage",title: "缩放至128x128",contexts: ["image"]});
});chrome.contextMenus.onClicked.addListener((info, tab) => {if (info.menuItemId === "resizeImage") {const imgUrl = info.srcUrl;// 创建一个临时的图片元素const img = new Image();img.crossOrigin = "Anonymous";img.onload = function() {// 创建canvasconst canvas = new OffscreenCanvas(128, 128);const ctx = canvas.getContext("2d");// 绘制缩放后的图片ctx.drawImage(img, 0, 0, 128, 128);// 转换为blobcanvas.convertToBlob().then(blob => {// 下载文件,移除 saveAs 选项使其自动下载const filename = "resized_" + imgUrl.split("/").pop();chrome.downloads.download({url: URL.createObjectURL(blob),filename: filename});});};img.src = imgUrl;}
});