文章目录
- 构造url
- 分析页面结构
- 爬取多页数据
- 最后
构造url
第一页url
https://s.taobao.com/search?q="面膜"
第二页url
https://s.taobao.com/search?q="面膜"&bcoffset=4&p4ppushleft=2%2C48&s=44&ntoffset=4
第三页url
https://s.taobao.com/search?q="面膜"&bcoffset=1&p4ppushleft=2%2C48&ntoffset=1&s=88
这里没有发现很明显的规律,看到了bcoffset和s其实都是不一样的;这种情况就需要大胆尝试了;
//1.去掉s只留bcoffset
https://s.taobao.com/search?q="面膜"&bcoffset=4&p4ppushleft=2%2C48&ntoffset=4
发现访问不了;换另一种思路
//2.去掉bcoffsets只留s
https://s.taobao.com/search?q="面膜"&s=44
访问到的就是淘宝中第二页的界面,在试一下s=88,发现就是第三页的界面
https://s.taobao.com/search?q="面膜"&s=88
所以,得出结论,淘宝上每页商品的url链接就是
https://s.taobao.com/search?q="面膜"&s=44*i
分析页面结构
先试一下爬取某一个页面,这里就以第一页为例
https://s.taobao.com/search?q="面膜"
我们先进该网页看一下网页结构,一进去发现需要登录,这里需要注意爬取的时候可能也需要登录;

登录后进入面膜首页

尝试先爬取首页来分析网页结构,很多网站浏览器检查出来的结构和我们看到的结构并不一致
import requests
url = 'https://s.taobao.com/search?q="面膜"'
# 模拟浏览器,不会的后面会讲
header = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36" }
response = requests.get(url,headers=header)
print(response.text)
可以看到输出的都是登录信息,所以这里引入cookie(需要之前登录过)

右键检查,network,刷新一下界面,找到network的第一个search开头的,右边找到cookie,复制(浏览器header也在这里可以查看)
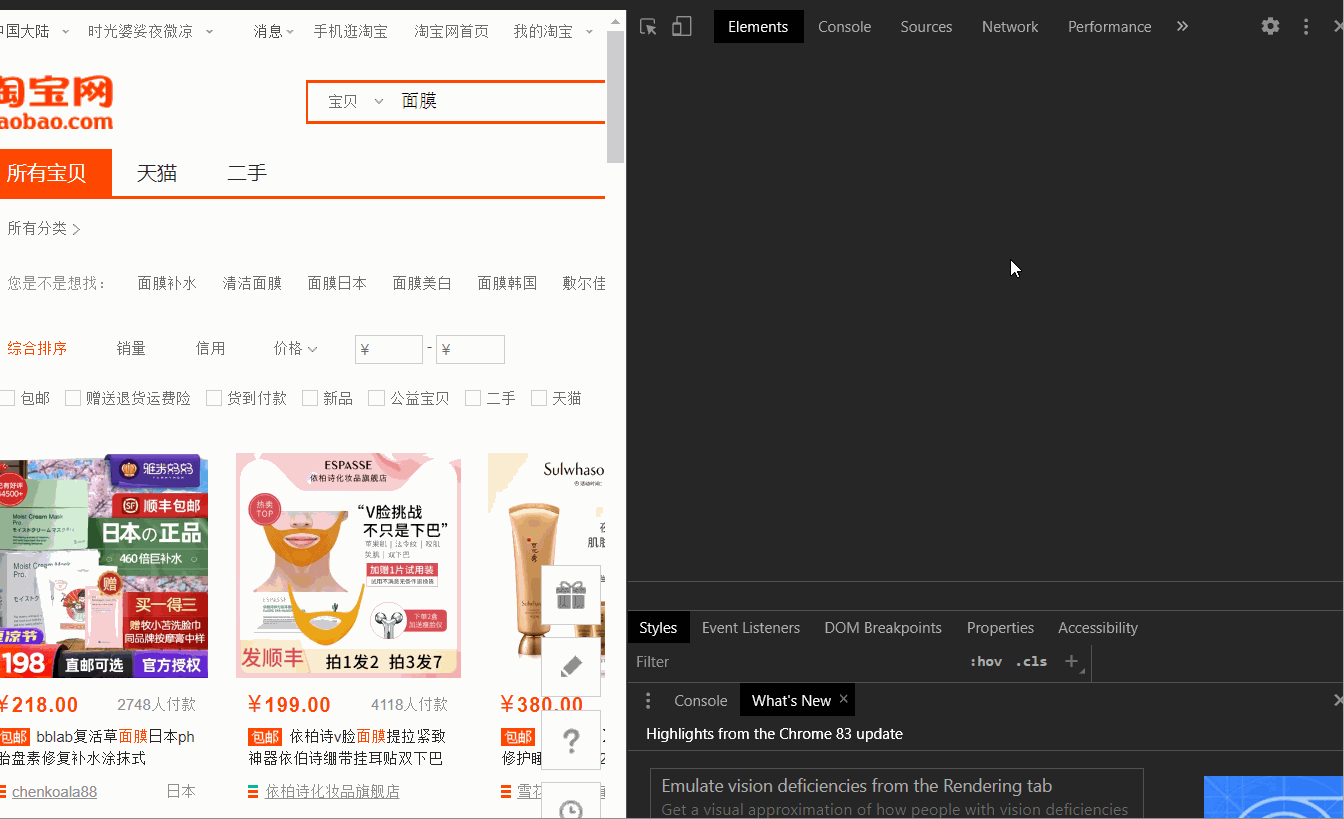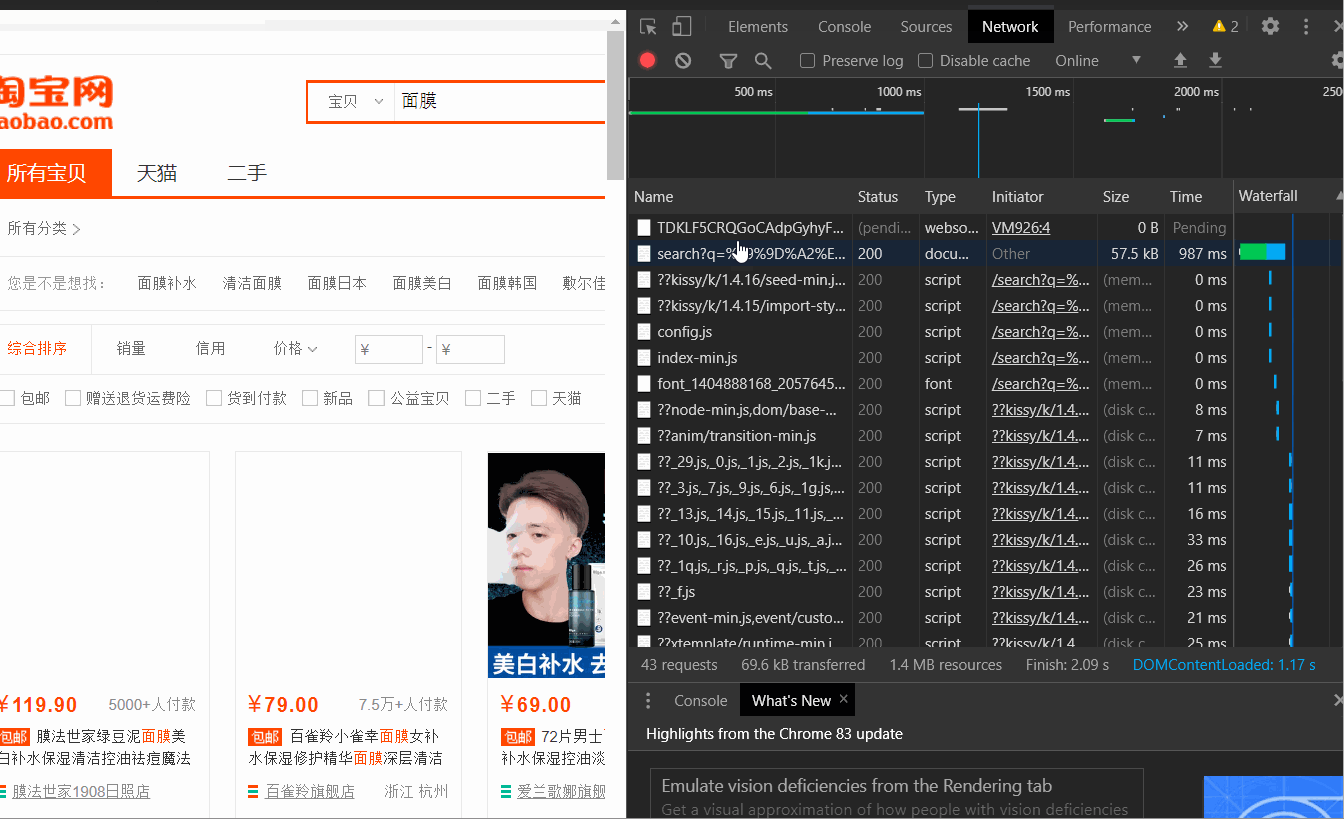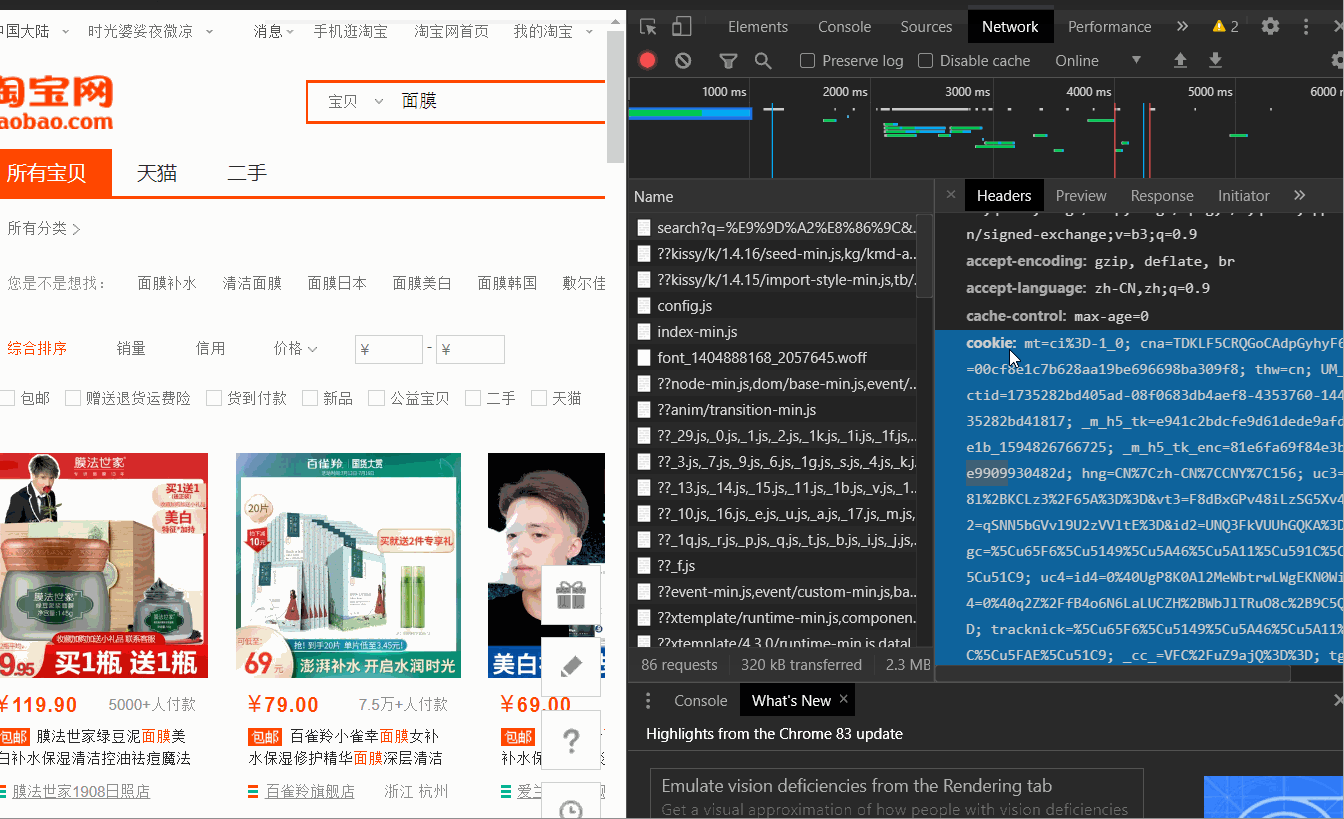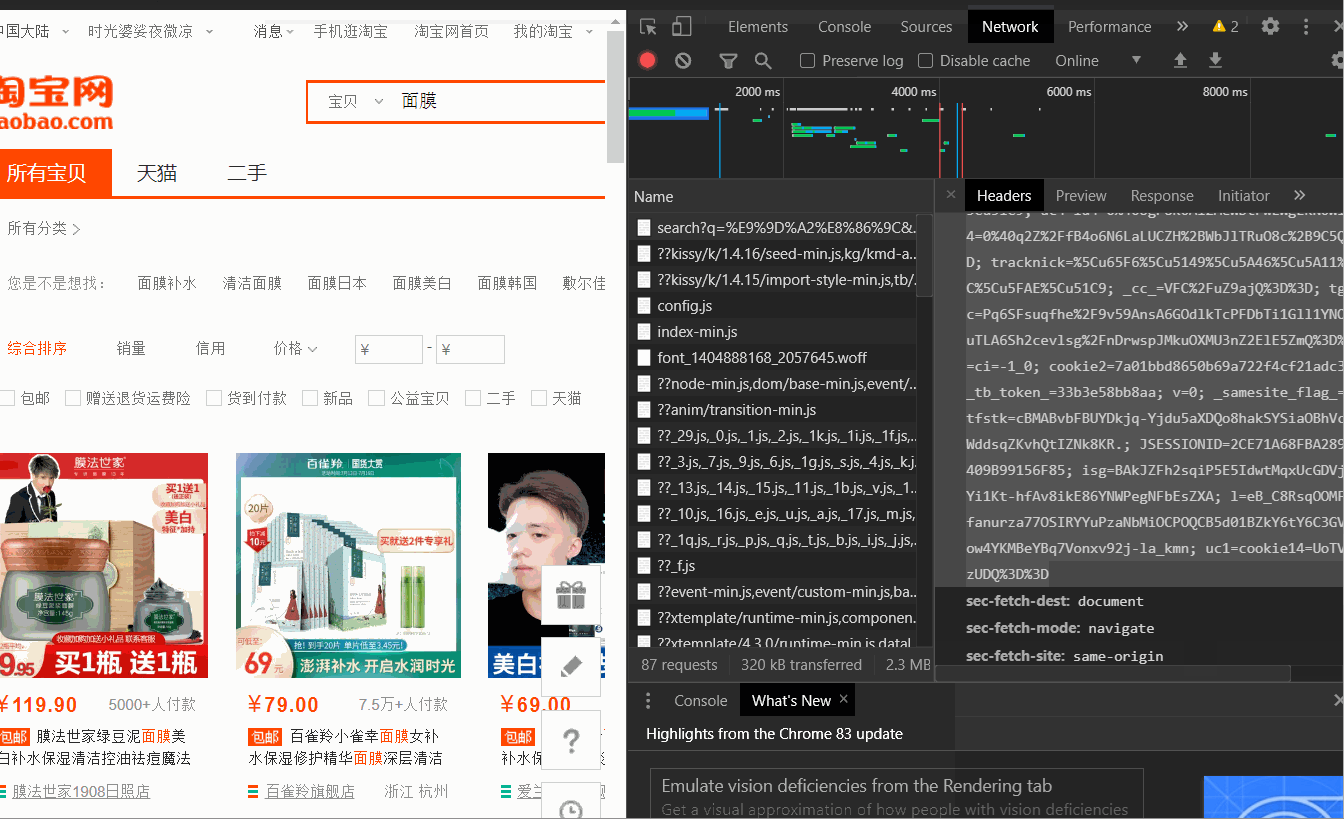
在requests中引入cookie;cookie太长了,我就不贴代码了

现在看到的就是,面膜首页结构了

稍微仔细观察一下,发现数据都是类似下面以键值对存储的,所以我们直接构造正则表达式匹配关心的内容即可。
"raw_title":"泰国海藻面膜小颗粒天然补水保湿嫩白男女士淡化祛痘印收缩毛孔斑"
"pic_url":"//g-search2.alicdn.com/img/bao/uploaded/i4/i3/709459503/O1CN01x0BiwS2K4QN8zB20v_!!709459503.jpg"
"detail_url":"//item.taobao.com/item.htm?id\u003d542945305681\u0026ns\u003d1\u0026abbucket\u003d13#detail"
"view_price":"179.00"
"view_fee":"0.00"
r’“view_price”:".*?"’ 匹配"view_price":加非贪婪匹配(尽可能少获取)
import re
price=re.findall(r'"view_price":".*?"',response.text)
print(price)
可以看到第一页的所有价格全在这

获取一下店铺名和商品图片url,简单修改一下正则表达式即可
nick=re.findall(r'"nick":".*?"',response.text)
pic_url=re.findall(r'"pic_url":".*?"',response.text)
print(nick,pic_url)

爬取多页数据
将之前的代码封装在一个函数里面,便于复用,代码前面也有,需要获取代码的微信公众号回复淘宝即可;

最后
可以关注一下我的公众号,最近开始写公众号,我会在上面分享一些资源和发布一些csdn上发布不了的干货;有问题也可以在公众号上留言

点个关注是对博主最大的支持
回复淘宝即可获取 爬取淘宝任意商品代码