文章目录
- ELK搜索
- 1.简介
- 1.1 内容
- 1.2 面向
- 2.Elastic Stack
- 2.1 简介
- 2.2 特色
- 2.3 组件介绍
- 3.Elasticsearch
- 3.1 搜索是什么
- 3.2 数据库搜索
- 3.3 全文检索
- 3.4 倒排索引
- 3.5 Lucene
- 3.6 Elasticsearch
- 3.6.1 Elasticsearch的功能
- 3.6.2 Elasticsearch使用场景
- 3.6.3 Elasticsearch的特点
- 3.7 elasticsearch核心概念
- 3.7.1 lucene和elasticsearch
- 3.7.2 elasticsearch核心概念
- 3.7.3 elasticsearch概念 vs 数据库概念
- 4.Elasticsearch相关软件安装
- 4.1 Windows安装elasticsearch
- 4.1.1 配置文件
- 4.1.2 启动Elasticsearch
- 4.2 Windows安装Kibana
- 4.3 Windows安装postman
- 4.4 Windows安装head插件
- 5.es快速入门
- 5.1 文档的数据格式
- 5.2 商品管理案例
- 5.3 简单的集群管理
- 5.3.1 检查集群健康状况
- 5.3.2 查看集群中的索引
- 5.3.3 简单的索引操作
- 5.4 商品的CRUD操作
- 5.4.1 新建图书索引
- 5.4.2 新增图书 : 新增文档
- 5.4.3 查询图书 : 检索文档
- 5.4.4 修改图书 : 替换操作
- 5.4.5 修改图书 : 更新文档
- 5.4.6 删除图书 : 删除文档
- 6.文档document入门
- 6.1 默认自带字段解析
- 6.2 生成文档id
- 6.3 _source 字段
- 6.4 文档的替换与删除
- 6.4.1 全量替换
- 6.4.2 强制创建
- 6.4.3 删除
- 6.4.4 局部替换
- 6.5 使用脚本更新
- 6.5.1 内置脚本
- 6.5.2 外部脚本
- 6.6 es的并发问题
- 6.7 悲观锁与乐观锁
- 6.8 _version乐观锁控制
- 6.9 基于_version并发操作
- 6.10 手动控制版本号
- 6.11 更新时参数
- 6.12 批量查询 mget
- 6.13 批量增删改 bulk
- 6.14 文档概念学习总结
ELK搜索
1.简介
1.1 内容
ELK是包含但不限于Elasticsearch(简称es)、Logstash、Kibana 三个开源软件的组成的一个整体。这三个软件合成ELK。是用于数据抽取(Logstash)、搜索分析(Elasticsearch)、数据展现(Kibana)的一整套解决方案,所以也称作ELK stack。
分别对三个组件经行详细介绍,尤其是Elasticsearch,因为它是elk的核心。从es底层对文档、索引、搜索、聚合、集群经行介绍,从搜索和聚合分析实例来展现es的魅力。Logstash从内部如何采集数据到指定地方来展现它数据采集的功能。Kibana则从数据绘图展现数据可视化的功能。
1.2 面向
- java工程师:深入研究es,使得java工程师向搜索工程师迈进。
- 运维工程师:搭建整体elk集群。不需写代码,仅需配置即可收集服务器指标、日志文件、数据库数据,并在前端华丽展现。
- 数据分析人员:不需写代码,仅需配置kibana图表,即可完成数据可视化工作,得到想要的数据图表。
- 大厂架构师:完成数据中台的搭建。对公司数据流的处理得心应手,对接本公司大数据业务。
2.Elastic Stack
2.1 简介
ELK是一个免费开源的日志分析架构技术栈总称,官网https://www.elastic.co/cn。包含三大基础组件,分别是Elasticsearch、Logstash、Kibana。但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据搜索、分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。下面是ELK架构:


随着elk的发展,又有新成员Beats、elastic cloud的加入,所以就形成了Elastic Stack。ELK是旧的称呼,Elastic Stack是新的名字。

2.2 特色
-
处理方式灵活:elasticsearch是目前最流行的准实时全文检索引擎,具有高速检索大数据的能力。
-
配置简单:安装elk的每个组件,仅需配置每个组件的一个配置文件即可。修改处不多,因为大量参数已经默认配在系统中,修改想要修改的选项即可。
-
接口简单:采用json形式RESTFUL API接受数据并响应,无关语言。
-
性能高效:elasticsearch基于优秀的全文搜索技术Lucene,采用倒排索引,可以轻易地在百亿级别数据量下,搜索出想要的内容,并且是秒级响应。
-
灵活扩展:elasticsearch和logstash都可以根据集群规模线性拓展,elasticsearch内部自动实现集群协作。
-
数据展现华丽:kibana作为前端展现工具,图表华丽,配置简单。
2.3 组件介绍
Elasticsearch
Elasticsearch 是使用 java开发,基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash
Logstash 基于 java开发,是一个数据抽取转化工具。一般工作方式为c/s架构,client端安装在需要收集信息的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch或其他组件上去。
Kibana
Kibana 基于nodejs,也是一个开源和免费的可视化工具。Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以汇总、分析和搜索重要数据日志。
Beats
Beats 平台集合了多种单一用途数据采集器。它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
Beats由如下组成:
-
Packetbeat:轻量型网络数据采集器,用于深挖网线上传输的数据,了解应用程序动态。Packetbeat 是一款轻量型网络数据包分析器,能够将数据发送至 Logstash 或 Elasticsearch。其支 持ICMP (v4 and v6)、DNS、HTTP、Mysql、PostgreSQL、Redis、MongoDB、Memcache等协议。
-
Filebeat:轻量型日志采集器。当要面对成百上千、甚至成千上万的服务器、虚拟机和容器生成的日志时,请告别 SSH 吧。Filebeat 将为您提供一种轻量型方法,用于转发和汇总日志与文件,让简单的事情不再繁杂。
-
Metricbeat :轻量型指标采集器。Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据,从 CPU 到内存,从 Redis 到 Nginx。可定期获取外部系统的监控指标信息,其可以监控、收集 Apache http、HAProxy、MongoDB、MySQL、Nginx、PostgreSQL、Redis、System、Zookeeper等服务。
-
Winlogbeat:轻量型 Windows 事件日志采集器。用于密切监控基于 Windows 的基础设施上发生的事件。Winlogbeat 能够以一种轻量型的方式,将 Windows 事件日志实时地流式传输至 Elasticsearch 和 Logstash。
-
Auditbeat:轻量型审计日志采集器。收集您 Linux 审计框架的数据,监控文件完整性。Auditbeat 实时采集这些事件,然后发送到 Elastic Stack 其他部分做进一步分析。
-
Heartbeat:面向运行状态监测的轻量型采集器。通过主动探测来监测服务的可用性。通过给定 URL 列表,Heartbeat 仅仅询问:网站运行正常吗?Heartbeat 会将此信息和响应时间发送至 Elastic 的其他部分,以进行进一步分析。
-
Functionbeat:面向云端数据的无服务器采集器。在作为一项功能部署在云服务提供商的功能即服务 (FaaS) 平台上后,Functionbeat 即能收集、传送并监测来自您的云服务的相关数据。
Elastic cloud
基于 Elasticsearch 的软件即服务(SaaS)解决方案。通过 Elastic 的官方合作伙伴使用托管的 Elasticsearch 服务。

3.Elasticsearch
3.1 搜索是什么
概念:用户输入想要的关键词,返回含有该关键词的所有信息。
场景:
1 互联网搜索:谷歌、百度、各种新闻首页
2 站内搜索(垂直搜索):企业OA查询订单、人员、部门,电商网站内部搜索商品(淘宝、京东)场景
3.2 数据库搜索
站内搜索(垂直搜索):数据量小,简单搜索,可以使用数据库。

存在问题:
| 存储问题:电商网站商品上亿条时,涉及到单表数据过大必须拆分表,数据库磁盘占用过大必须分库(mycat)
| 性能问题:查询 “笔记本电脑”等关键词时,上亿条数据的商品名字段逐行扫描,性能跟不上
| 不能分词。如搜索 “笔记本电脑”,只能搜索完全和关键词一样的数据,那么数据量小时,搜索“笔记电脑”,“电脑”数据要不要给用户
互联网搜索:肯定不会使用数据库搜索,数据量太大,PB级。
3.3 全文检索

3.4 倒排索引
倒排索引。数据存储时,经行分词建立term索引库。
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
3.5 Lucene
一个jar包,里面封装了全文检索的引擎、搜索的算法代码。开发时,引入lucen的jar包,通过api开发搜索相关业务。底层会在磁盘建立索引库。
3.6 Elasticsearch

官网:https://www.elastic.co/cn/products/elasticsearch

3.6.1 Elasticsearch的功能
- 分布式的搜索引擎和数据分析引擎
搜索:互联网搜索、电商网站站内搜索、OA系统查询
数据分析:电商网站查询近一周哪些品类的图书销售前十;新闻网站,最近3天阅读量最高的十个关键词。
- 全文检索,结构化检索,数据分析
全文检索:搜索商品名称包含java的图书select * from books where book_name like “%java%”
结构化检索:搜索商品分类为spring的图书都有哪些,select * from books where category_id=‘spring’
数据分析:分析每一个分类下有多少种图书,select category_id,count(*) from books group by category_id
- 对海量数据进行近实时的处理
分布式:ES自动可以将海量数据分散到多台服务器上去存储和检索,经行并行查询,提高搜索效率。相对的Lucene是单机应用。
近实时:数据库上亿条数据查询,搜索一次耗时几个小时,是批处理(batch-processing)。而es只需秒级即可查询海量数据,所以叫近实时。
3.6.2 Elasticsearch使用场景
国外:
-
维基百科,类似百度百科,“网络七层协议”的维基百科,全文检索,高亮,搜索推荐
-
Stack Overflow(国外的程序讨论论坛),相当于程序员的贴吧。
-
GitHub(开源代码管理),搜索上千亿行代码。
-
电商网站,检索商品
-
日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
-
商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅《java编程思想》的监控,如果价格低于27块钱,就通知我,我就去买。
-
BI系统,商业智能(Business Intelligence)。大型连锁超市,分析全国网点传回的数据,分析各个商品在什么季节的销售量最好、利润最高。成本管理,店面租金、员工工资、负债等信息进行分析。从而部署下一个阶段的战略目标。
国内:
-
百度搜索,第一次查询,使用es。
-
OA、ERP系统站内搜索。
3.6.3 Elasticsearch的特点
-
可拓展性:大型分布式集群(数百台服务器)技术,处理PB级数据,大公司可以使用。小公司数据量小,也可以部署在单机,大数据领域使用广泛。
-
技术整合:将全文检索、数据分析、分布式相关技术整合在一起:lucene(全文检索),商用的数据分析软件(BI软件),分布式数据库(mycat)
-
部署简单:开箱即用,很多默认配置不需关心,解压完成直接运行即可。拓展时,只需多部署几个实例即可,负载均衡、分片迁移集群内部自己实施。
-
接口简单:使用restful api经行交互,跨语言。
-
功能强大:Elasticsearch作为传统数据库的一个补充,提供了数据库所不不能提供的很多功能,如全文检索,同义词处理,相关度排名。



3.7 elasticsearch核心概念
3.7.1 lucene和elasticsearch
Lucene:最先进、功能最强大的搜索库,直接基于lucene开发,非常复杂,api复杂

Elasticsearch:基于lucene,封装了许多lucene底层功能,提供简单易用的restful api接口和许多语言的客户端,如java的高级客户端(Java High Level REST Client)和底层客户端(Java Low Level REST Client)

起源:Shay Banon。2004年失业,陪老婆去伦敦学习厨师。失业在家帮老婆写一个菜谱搜索引擎。封装了lucene的开源项目,compass。找到工作后,做分布式高性能项目,再封装compass,写出了elasticsearch,使得lucene支持分布式。现在是Elasticsearch创始人兼Elastic首席执行官。
3.7.2 elasticsearch核心概念

1 NRT(Near Realtime):近实时
两方面:
-
写入数据时,过1秒才会被搜索到,因为内部在分词、录入索引。
-
es搜索时:搜索和分析数据需要秒级出结果。
2 Cluster:集群
包含一个或多个启动着es实例的机器群。通常一台机器起一个es实例。同一网络下,集名一样的多个es实例自动组成集群,自动均衡分片等行为。默认集群名为“elasticsearch”。
3 Node:节点
每个es实例称为一个节点。节点名自动分配,也可以手动配置。
4 Index:索引
包含一堆有相似结构的文档数据。
索引创建规则:
-
仅限小写字母
-
不能包含\、/、 *、?、"、<、>、|、#以及空格符等特殊符号
-
从7.0版本开始不再包含冒号
-
不能以-、_或+开头
-
不能超过255个字节(注意它是字节,因此多字节字符将计入255个限制)
5 Document:文档
es中的最小数据单元。一个document就像数据库中的一条记录。通常以json格式显示。多个document存储于一个索引(Index)中。
book document
{"book_id": "1","book_name": "java编程思想","book_desc": "从Java的基础语法到最高级特性(深入的[面向对象](https://baike.baidu.com/item/面向对象)概念、多线程、自动项目构建、单元测试和调试等),本书都能逐步指导你轻松掌握。","category_id": "2","category_name": "java"
}
6 Field:字段
就像数据库中的列(Columns),定义每个document应该有的字段。
7 Type:类型
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field。
6.0之前的版本有type(类型)概念,type相当于关系数据库的表,ES官方将在ES9.0版本中彻底删除type。本教程typy都为_doc。
8 shard:分片
index数据过大时,将index里面的数据,分为多个shard,分布式的存储在各个服务器上面。可以支持海量数据和高并发,提升性能和吞吐量,充分利用多台机器的cpu。
9 replica:副本
在分布式环境下,任何一台机器都会随时宕机,如果宕机,index的一个分片没有,导致此index不能搜索。为了保证数据的安全,将每个index的分片经行备份,存储在另外的机器上。保证少数机器宕机es集群仍可以搜索。
能正常提供查询和插入的分片我们叫做主分片(primary shard),其余的叫做备份的分片(replica shard)
es6默认新建索引时,5分片,2副本,也就是一主一备,共10个分片。所以,es集群最小规模为两台。
3.7.3 elasticsearch概念 vs 数据库概念
| 关系型数据库(比如Mysql) | 非关系型数据库(Elasticsearch) |
|---|---|
| 数据库Database | 索引Index |
| 表Table | 索引Index(原为Type) |
| 数据行Row | 文档Document |
| 数据列Column | 字段Field |
| 约束 Schema | 映射Mapping |
4.Elasticsearch相关软件安装
4.1 Windows安装elasticsearch
1、安装JDK,至少1.8.0_73以上版本,验证:java -version
2、下载和解压缩Elasticsearch安装包,查看目录结构
https://www.elastic.co/cn/downloads/elasticsearch
-
bin:脚本目录,包括:启动、停止等可执行脚本
-
config:配置文件目录
-
data:索引目录,存放索引文件的地方
-
logs:日志目录
-
modules:模块目录,包括了es的功能模块
-
plugins:插件目录,es支持插件机制
4.1.1 配置文件
ES的配置文件的地址根据安装形式的不同而不同:
-
使用zip、tar安装,配置文件的地址在安装目录的config下。
-
使用RPM安装,配置文件在/etc/elasticsearch下。
-
使用MSI安装,配置文件的地址在安装目录的config下,并且会自动将config目录地址写入环境变量ES_PATH_CONF。
elasticsearch.yml
配置格式是YAML,可以采用如下两种方式:
方式1:层次方式
path:data: /var/lib/elasticsearchlogs: /var/log/elasticsearch
方式2:属性方式
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
常用的配置项如下
cluster.name: 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。
node.name:节点名,通常一台物理服务器就是一个节点,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理一个或多个节点组成一个cluster集群,集群是一个逻辑的概念,节点是物理概念,后边章节会详细介绍。
path.conf: 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch
path.data:设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开。
path.logs:设置日志文件的存储路径,默认是es根目录下的logs文件夹
path.plugins: 设置插件的存放路径,默认是es根目录下的plugins文件夹
bootstrap.memory_lock: true设置为true可以锁住ES使用的内存,避免内存与swap分区交换数据。
network.host: 设置绑定主机的ip地址,设置为0.0.0.0表示绑定任何ip,允许外网访问,生产环境建议设置为具体的ip。
http.port: 9200设置对外服务的http端口,默认为9200。
transport.tcp.port: 9300 集群结点之间通信端口
node.master: 指定该节点是否有资格被选举成为master结点,默认是true,如果原来的master宕机会重新选举新的master。
node.data: 指定该节点是否存储索引数据,默认为true。
discovery.zen.ping.unicast.hosts: ["host1:port", "host2:port", "..."]设置集群中master节点的初始列表。
discovery.zen.ping.timeout: 3s设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些。
discovery.zen.minimum_master_nodes:主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2。
node.max_local_storage_nodes: 单机允许的最大存储结点数,通常单机启动一个结点建议设置为1,开发环境如果单机启动多个节点可设置大于1。
jvm.options
设置最小及最大的JVM堆内存大小
在jvm.options中设置 -Xms和-Xmx
-
两个值设置为相等
-
将Xmx 设置为不超过物理内存的一半
log4j2.properties
日志文件设置,ES使用log4j,注意日志级别的配置。
4.1.2 启动Elasticsearch
bin\elasticsearch.bat,es的特点就是开箱即,无需配置,启动即可。
注意:es7 windows版本不支持机器学习,所以elasticsearch.yml中添加如下几个参数:
node.name: node-1
cluster.initial_master_nodes: ["node-1"]
xpack.ml.enabled: false
http.cors.enabled: true
http.cors.allow-origin: /.*/
检查ES是否启动成功:浏览器访问http://localhost:9200/?Pretty
{"name": "node-1","cluster_name": "elasticsearch","cluster_uuid": "HqAKQ_0tQOOm8b6qU-2Qug","version": {"number": "7.3.0","build_flavor": "default","build_type": "zip","build_hash": "de777fa","build_date": "2019-07-24T18:30:11.767338Z","build_snapshot": false,"lucene_version": "8.1.0","minimum_wire_compatibility_version": "6.8.0","minimum_index_compatibility_version": "6.0.0-beta1"},"tagline": "You Know, for Search"
}
解释:
name: node名称,取自机器的hostname
cluster_name: 集群名称(默认的集群名称就是elasticsearch)
version.number: 7.3.0,es版本号
version.lucene_version:封装的lucene版本号
浏览器访问:http://localhost:9200/_cluster/health 查询集群状态
{"cluster_name": "elasticsearch","status": "green","timed_out": false,"number_of_nodes": 1,"number_of_data_nodes": 1,"active_primary_shards": 0,"active_shards": 0,"relocating_shards": 0,"initializing_shards": 0,"unassigned_shards": 0,"delayed_unassigned_shards": 0,"number_of_pending_tasks": 0,"number_of_in_flight_fetch": 0,"task_max_waiting_in_queue_millis": 0,"active_shards_percent_as_number": 100
}
解释:
Status:集群状态。
- Green 所有分片可用
- Yellow 所有主分片可用
- Red 主分片不可用,集群不可用
4.2 Windows安装Kibana
1、kibana是es数据的前端展现,数据分析时,可以方便地看到数据,方便访问es
2、下载,解压kibana
3、启动Kibana:bin\kibana.bat
4、浏览器访问 http://localhost:5601 进入Dev Tools界面
5、发送get请求,查看集群状态GET _cluster/health。相当于浏览器访问

总览

Dev Tools界面

监控集群界面

集群状态(搜索速率、索引速率等)
4.3 Windows安装postman
postman是一个模拟http请求的工具,能够非常细致地定制化各种http请求。如get]\post\pu\delete,携带body参数等。在没有kibana时,可以使用postman调试。
怎么用:get http://localhost:9200/

测试一下get方式查询集群状态http://localhost:9200/_cluster/health

4.4 Windows安装head插件
head插件是ES的一个可视化管理插件,用来监视ES的状态,并通过head客户端和ES服务进行交互,比如创建映射、创建索引等,head的项目地址在https://github.com/mobz/elasticsearch-head
从ES6.0开始,head插件支持使得node.js运行。
- 安装node.js
- 下载head并运行
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
浏览器打开 http://localhost:9100/
- 运行

打开浏览器调试工具发现报错:
Origin null is not allowed by Access-Control-Allow-Origin.
原因是:head插件作为客户端要连接ES服务(localhost:9200),此时存在跨域问题,elasticsearch默认不允许跨域访问。
解决方案:
设置elasticsearch允许跨域访问。
在config/elasticsearch.yml 后面增加以下参数:
# 开启cors跨域访问支持,默认为false
http.cors.enabled: true
# 跨域访问允许的域名地址,(允许所有域名)以上使用正则
http.cors.allow-origin: /.*/
注意:将config/elasticsearch.yml另存为utf-8编码格式。
成功连接ES

注意:kibana\postman\head插件选择自己喜欢的一种使用即可。
本教程使用kibana的dev tool,因为地址栏省略了http://localhost:9200
5.es快速入门
5.1 文档的数据格式
(1)应用系统的数据结构都是面向对象的,具有复杂的数据结构
(2)对象存储到数据库,需要将关联的复杂对象属性插到另一张表,查询时再拼接起来
(3)es面向文档,文档中存储的数据结构,与对象一致。所以一个对象可以直接存成一个文档
(4)es的document用json数据格式来表达
例如:班级和学生关系
public class Student {private String id;private String name;private String classInfoId;
}private class ClassInfo {private String id;private String className;
。。。。。}
数据库中要设计所谓的一对多,多对一的两张表,外键等。查询出来时还要关联,mybatis写映射文件。
而在es中,一个学生存成文档如下:
{"id":"1","name": "张三","last_name": "zhang","classInfo": {"id": "1","className": "三年二班",}
}
5.2 商品管理案例
有一个售卖图书的网站,需要为其基于ES构建一个后台系统,提供以下功能:
(1)对商品信息进行CRUD(增删改查)操作
(2)执行简单的结构化查询
(3)可以执行简单的全文检索,以及复杂的phrase(短语)检索
(4)对于全文检索的结果,可以进行高亮显示
(5)对数据进行简单的聚合分析
5.3 简单的集群管理
5.3.1 检查集群健康状况
es提供了一套api,叫做cat api,可以查看es中各种各样的数据
GET /_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1568635460 12:04:20 elasticsearch green 1 1 4 4 0 0 0 0 - 100.0%
如何快速了解集群的健康状况?green、yellow、red?
green:每个索引的primary shard和replica shard都是active状态的
yellow:每个索引的primary shard都是active状态的,部分replica shard不是active状态,处于不可用的状态
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
5.3.2 查看集群中的索引
GET /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana_task_manager JBMgpucOSzenstLcjA_G4A 1 0 2 0 45.5kb 45.5kb
green open .monitoring-kibana-7-2019.09.16 LIskf15DTcS70n4Q6t2bTA 1 0 433 0 218.2kb 218.2kb
green open .monitoring-es-7-2019.09.16 RMeUN3tQRjqM8xBgw7Zong 1 0 3470 1724 1.9mb 1.9mb
green open .kibana_1 1cRiyIdATya5xS6qK5pGJw 1 0 4 0 18.2kb 18.2kb
5.3.3 简单的索引操作
创建索引:PUT /demo_index?pretty
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "demo_index"
}
删除索引:DELETE /demo_index?pretty
5.4 商品的CRUD操作
5.4.1 新建图书索引
首先建立图书索引 book
语法:put /index
PUT /book

5.4.2 新增图书 : 新增文档
语法:PUT /index/type/id
PUT /book/_doc/1
{
"name": "Bootstrap开发",
"description": "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price":38.6,
"timestamp":"2019-08-25 19:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "bootstrap", "dev"]
}
PUT /book/_doc/2
{
"name": "java编程思想",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel": "201001",
"price":68.6,
"timestamp":"2019-08-25 19:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "java", "dev"]
}
PUT /book/_doc/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"price":88.6,
"timestamp":"2019-08-24 19:11:35",
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [ "spring", "java"]
}
结果
{"_index" : "book","_type" : "_doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1
}
5.4.3 查询图书 : 检索文档
语法:GET /index/type/id
查看图书:GET /book/_doc/1 就可看到json形式的文档。
{"_index" : "book","_type" : "_doc","_id" : "1","_version" : 4,"_seq_no" : 5,"_primary_term" : 1,"found" : true,"_source" : {"name" : "Bootstrap开发","description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。","studymodel" : "201002","price" : 38.6,"timestamp" : "2019-08-25 19:11:35","pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg","tags" : ["bootstrap","开发"]}
}
为方便查看索引中的数据,kibana可以如下操作
Kibana-discover- Create index pattern- Index pattern填book

下一步,再点击discover就可看到数据。

点击json还可以看到原始数据

为方便查看索引中的数据,head可以如下操作
点击数据浏览,点击book索引。

5.4.4 修改图书 : 替换操作
PUT /book/_doc/1
{"name": "Bootstrap开发教程1","description": "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。","studymodel": "201002","price":38.6,"timestamp":"2019-08-25 19:11:35","pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg","tags": [ "bootstrap", "开发"]
}
替换操作是整体覆盖,要带上所有信息。
5.4.5 修改图书 : 更新文档
语法:POST /{index}/type /{id}/_update
或者POST /{index}/_update/{id}
POST /book/_update/1/
{"doc": {"name": " Bootstrap开发教程高级"}
}
返回:
{"_index" : "book","_type" : "_doc","_id" : "1","_version" : 10,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 11,"_primary_term" : 1
}
5.4.6 删除图书 : 删除文档
语法:
DELETE /book/_doc/1
返回:
{"_index" : "book","_type" : "_doc","_id" : "1","_version" : 11,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 12,"_primary_term" : 1}
6.文档document入门
6.1 默认自带字段解析
{"_index" : "book","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 10,"_primary_term" : 1,"found" : true,"_source" : {"name" : "Bootstrap开发教程1","description" : "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。","studymodel" : "201002","price" : 38.6,"timestamp" : "2019-08-25 19:11:35","pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg","tags" : ["bootstrap","开发"]}
}
_index
- 含义:此文档属于哪个索引
- 原则:类似数据放在一个索引中。数据库中表的定义规则。如图书信息放在book索引中,员工信息放在employee索引中,各个索引存储和搜索时互不影响。
- 定义规则:英文小写。尽量不要使用特殊字符。order user
_type
- 含义:类别。book java node
- 注意:以后的es9将彻底删除此字段,所以当前版本在不断弱化type,见到_type都为doc。
_id
含义:文档的唯一标识。就像表的id主键,结合索引可以标识和定义一个文档。
生成:手动(put /index/_doc/id)、自动
创建索引时,不同数据放到不同索引中

6.2 生成文档id

手动生成id
场景:数据从其他系统导入时,本身有唯一主键。如数据库中的图书、员工信息等。
用法:put /index/_doc/id
PUT /test_index/_doc/1
{"test_field": "test"
}
自动生成id
用法:POST /index/_doc
POST /test_index/_doc
{"test_field": "test1"
}
返回:
{"_index" : "test_index","_type" : "_doc","_id" : "x29LOm0BPsY0gSJFYZAl","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1
}
自动id特点:长度为20个字符,URL安全,base64编码,GUID,分布式生成不冲突。
6.3 _source 字段
_source
含义:插入数据时的所有字段和值。在get获取数据时,在_source字段中原样返回。
GET /book/_doc/1
定制返回字段
就像sql不要select *,而要select name,price from book …一样。
GET /book/_doc/1?__source_includes=name,price
{"_index" : "book","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 10,"_primary_term" : 1,"found" : true,"_source" : {"price" : 38.6,"name" : "Bootstrap开发教程1"}
}
6.4 文档的替换与删除
6.4.1 全量替换

执行两次,返回结果中版本号(_version)在不断上升。此过程为全量替换。
PUT /test_index/_doc/1
{"test_field": "test"
}
实质:旧文档的内容不会立即删除,只是标记为deleted。适当的时机,集群会将这些文档删除。
6.4.2 强制创建
为防止覆盖原有数据,我们在新增时,设置为强制创建,不会覆盖原有文档。
语法:
PUT /index/_doc/id/_create
PUT /test_index/_doc/1/_create
{"test_field": "test"
}
返回
{"error": {"root_cause": [{"type": "version_conflict_engine_exception","reason": "[2]: version conflict, document already exists (current version [1])","index_uuid": "lqzVqxZLQuCnd6LYtZsMkg","shard": "0","index": "test_index"}],"type": "version_conflict_engine_exception","reason": "[2]: version conflict, document already exists (current version [1])","index_uuid": "lqzVqxZLQuCnd6LYtZsMkg","shard": "0","index": "test_index"},"status": 409
}
6.4.3 删除
DELETE /index/_doc/id
DELETE /test_index/_doc/1/
实质:旧文档的内容不会立即删除,只是标记为deleted。适当的时机,集群会将这些文档删除。
lazy delete
6.4.4 局部替换
使用 PUT /index/type/id 为文档全量替换,需要将文档所有数据提交。
partial update局部替换则只修改变动字段。
用法:
post /index/type/id/_update
{"doc": {"field":"value"}
}
图解内部原理
内部与全量替换是一样的,旧文档标记为删除,新建一个文档。

演示
插入文档
PUT /test_index/_doc/5
{"test_field1": "itcst","test_field2": "itheima"
}
修改字段1
POST /test_index/_doc/5/_update
{"doc": {"test_field2": " itheima 2"}
}
6.5 使用脚本更新
es可以内置脚本执行复杂操作,例如painless脚本。
注意:groovy脚本在es6以后就不支持了。原因是耗内存,不安全远程注入漏洞。
6.5.1 内置脚本
需求1:修改文档6的num字段,+1
插入数据
PUT /test_index/_doc/6
{"num": 0,"tags": []
}
执行脚本操作
POST /test_index/_doc/6/_update
{"script" : "ctx._source.num+=1"
}
查询数据
GET /test_index/_doc/6
返回
{"_index" : "test_index","_type" : "_doc","_id" : "6","_version" : 2,"_seq_no" : 23,"_primary_term" : 1,"found" : true,"_source" : {"num" : 1,"tags" : [ ]}
}
需求2:搜索所有文档,将num字段乘以2输出
插入数据
PUT /test_index/_doc/7
{"num": 5
}
查询
GET /test_index/_search
{"script_fields": {"my_doubled_field": {"script": {"lang": "expression","source": "doc['num'] * multiplier","params": {"multiplier": 2}}}}
}
返回
{"_index" : "test_index","_type" : "_doc","_id" : "7","_score" : 1.0,"fields" : {"my_doubled_field" : [10.0]}}
6.5.2 外部脚本
Painless是内置支持的。脚本内容可以通过多种途径传给 es,包括 rest 接口,或者放到 config/scripts目录等,默认开启。
注意:脚本性能低下,且容易发生注入,本教程忽略。
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-scripting-using.html
6.6 es的并发问题
如同秒杀,多线程情况下,es同样会出现并发冲突问题。

6.7 悲观锁与乐观锁
为控制并发问题,通常采用锁机制。分为悲观锁和乐观锁两种机制。

6.8 _version乐观锁控制
es对于文档的增删改都是基于版本号。
1 新增多次文档
PUT /test_index/_doc/3
{"test_field": "test"
}
返回版本号递增
2 删除此文档
DELETE /test_index/_doc/3
返回
DELETE /test_index/_doc/3
{"_index" : "test_index","_type" : "_doc","_id" : "2","_version" : 6,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 7,"_primary_term" : 1
}
3 再新增
PUT /test_index/_doc/3
{"test_field": "test"
}
可以看到版本号依然递增,验证延迟删除策略。
如果删除一条数据立马删除的话,所有分片和副本都要立马删除,对es集群压力太大。
图解es内部并发控制
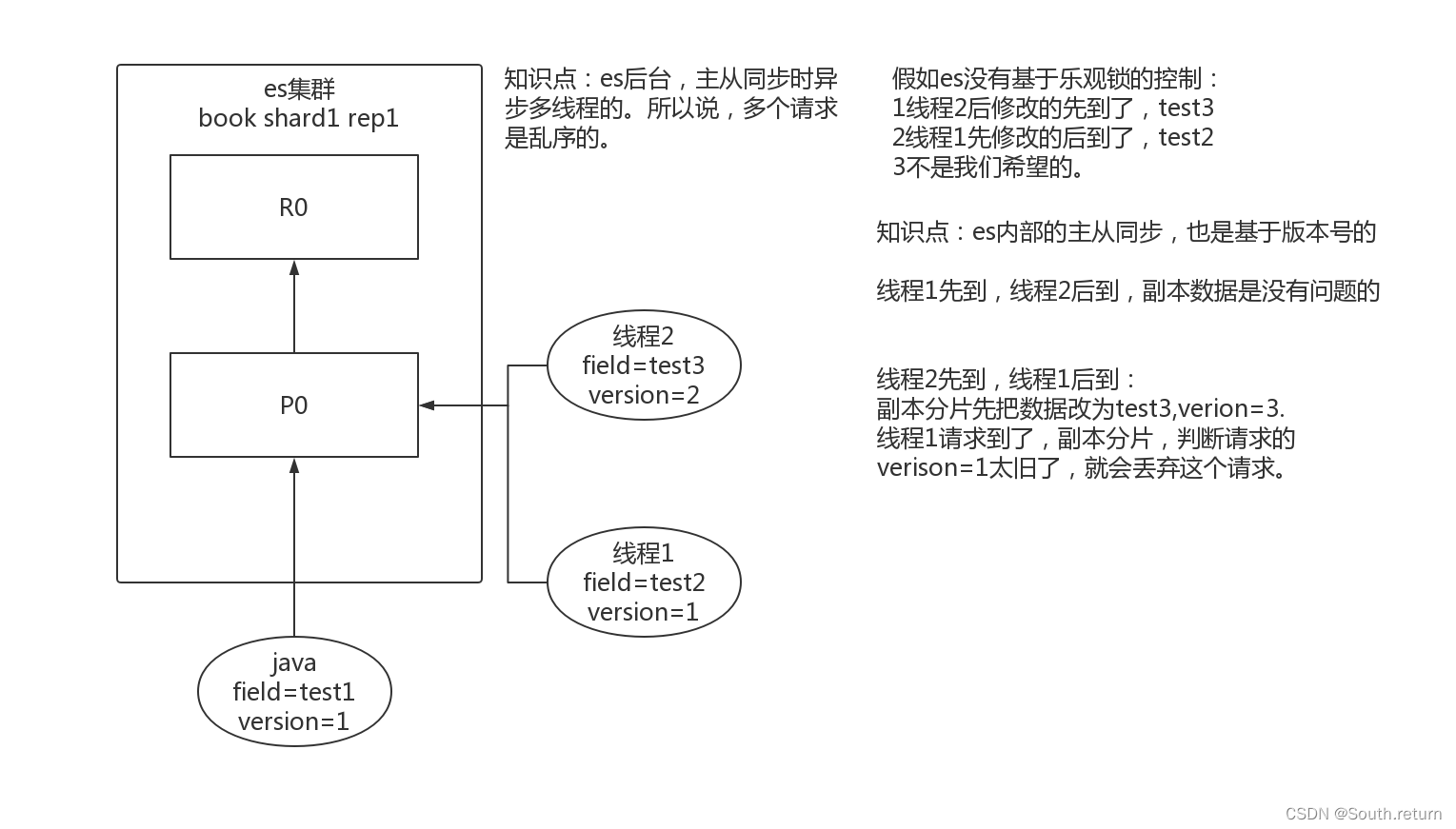
es内部主从同步时,是多线程异步。乐观锁机制。
6.9 基于_version并发操作
java python客户端更新的机制。
新建文档
PUT /test_index/_doc/5
{"test_field": "itcast"
}
返回:
{"_index" : "test_index","_type" : "_doc","_id" : "3","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 8,"_primary_term" : 1
}
客户端1修改。带版本号1。
首先获取数据的当前版本号
GET /test_index/_doc/5
更新文档
PUT /test_index/_doc/5?version=1
{"test_field": "itcast1"
}
PUT /test_index/_doc/5?if_seq_no=21&if_primary_term=1
{"test_field": "itcast1"
}
客户端2并发修改。带版本号1。
PUT /test_index/_doc/5?version=1
{"test_field": "itcast2"
}
PUT /test_index/_doc/5?if_seq_no=21&if_primary_term=1
{"test_field": "itcast1"
}
报错。
客户端2重新查询。得到最新版本为2。seq_no=22
GET /test_index/_doc/4
客户端2并发修改。带版本号2。
PUT /test_index/_doc/4?version=2
{"test_field": "itcast2"
}
es7
PUT /test_index/_doc/5?if_seq_no=22&if_primary_term=1
{"test_field": "itcast2"
}
修改成功。
6.10 手动控制版本号
背景:已有数据是在数据库中,有自己手动维护的版本号的情况下,可以使用external version控制。hbase。
要求:修改时external version要大于当前文档的_version
对比:基于_version时,修改的文档version等于当前文档的版本号。
使用?version=1&version_type=external
新建文档
PUT /test_index/_doc/4
{"test_field": "itcast"
}
更新文档:
客户端1修改文档
PUT /test_index/_doc/4?version=2&version_type=external
{"test_field": "itcast1"
}
客户端2同时修改
PUT /test_index/_doc/4?version=2&version_type=external
{"test_field": "itcast2"
}
返回:
{"error": {"root_cause": [{"type": "version_conflict_engine_exception","reason": "[4]: version conflict, current version [2] is higher or equal to the one provided [2]","index_uuid": "-rqYZ2EcSPqL6pu8Gi35jw","shard": "1","index": "test_index"}],"type": "version_conflict_engine_exception","reason": "[4]: version conflict, current version [2] is higher or equal to the one provided [2]","index_uuid": "-rqYZ2EcSPqL6pu8Gi35jw","shard": "1","index": "test_index"},"status": 409
}
客户端2重新查询数据
GET /test_index/_doc/4
客户端2重新修改数据
PUT /test_index/_doc/4?version=3&version_type=external
{"test_field": "itcast2"
}
6.11 更新时参数
retry_on_conflict
指定重试次数
POST /test_index/_doc/5/_update?retry_on_conflict=3
{"doc": {"test_field": "itcast1"}
}
与 _version结合使用
POST /test_index/_doc/5/_update?retry_on_conflict=3&version=22&version_type=external
{"doc": {"test_field": "itcast1"}
}
6.12 批量查询 mget
单条查询 GET /test_index/_doc/1,如果查询多个id的文档一条一条查询,网络开销太大。
mget 批量查询
GET /_mget
{"docs" : [{"_index" : "test_index","_type" : "_doc","_id" : 1},{"_index" : "test_index","_type" : "_doc","_id" : 7}]
}
返回:
{"docs" : [{"_index" : "test_index","_type" : "_doc","_id" : "2","_version" : 6,"_seq_no" : 12,"_primary_term" : 1,"found" : true,"_source" : {"test_field" : "test12333123321321"}},{"_index" : "test_index","_type" : "_doc","_id" : "3","_version" : 6,"_seq_no" : 18,"_primary_term" : 1,"found" : true,"_source" : {"test_field" : "test3213"}}]
}
提示去掉type
GET /_mget
{"docs" : [{"_index" : "test_index","_id" : 2},{"_index" : "test_index","_id" : 3}]
}
同一索引下批量查询:
GET /test_index/_mget
{"docs" : [{"_id" : 2},{"_id" : 3}]
}
第三种写法:搜索写法
post /test_index/_doc/_search
{"query": {"ids" : {"values" : ["1", "7"]}}
}
6.13 批量增删改 bulk
Bulk 操作解释将文档的增删改查一些列操作,通过一次请求全都做完。减少网络传输次数。
语法:
POST /_bulk
{"action": {"metadata"}}
{"data"}
如下操作,删除5,新增14,修改2。
POST /_bulk
{ "delete": { "_index": "test_index", "_id": "5" }}
{ "create": { "_index": "test_index", "_id": "14" }}
{ "test_field": "test14" }
{ "update": { "_index": "test_index", "_id": "2"} }
{ "doc" : {"test_field" : "bulk test"} }
1 功能:
- delete:删除一个文档,只要1个json串就可以了
- create:相当于强制创建 PUT /index/type/id/_create
- index:普通的put操作,可以是创建文档,也可以是全量替换文档
- update:执行的是局部更新partial update操作
2 格式:每个json不能换行。相邻json必须换行。
3 隔离:每个操作互不影响。操作失败的行会返回其失败信息。
4 实际用法:bulk请求一次不要太大,否则一下积压到内存中,性能会下降。一次请求几千个操作、在几M正好。
6.14 文档概念学习总结
章节回顾
- 文档的增删改查
- 文档字段解析
- 内部锁机制
- 批量查询修改
es是什么
-
一个分布式的文档数据存储系统distributed document store。es看做一个分布式nosql数据库。如redis\mongoDB\hbase。
-
文档数据:es可以存储和操作json文档类型的数据,而且这也是es的核心数据结构。
-
存储系统:es可以对json文档类型的数据进行存储,查询,创建,更新,删除,等等操作。
应用场景
- 大数据。es的分布式特点,水平扩容承载大数据。
- 数据结构灵活。列随时变化。使用关系型数据库将会建立大量的关联表,增加系统复杂度。
- 数据操作简单。就是查询,不涉及事务。
举例
电商页面、传统论坛页面等。面向的对象比较复杂,但是作为终端,没有太复杂的功能(事务),只涉及简单的增删改查crud。这个时候选用ES这种NoSQL型的数据存储,比传统的复杂的事务强大的关系型数据库,更加合适一些。无论是性能,还是吞吐量,都会更好。