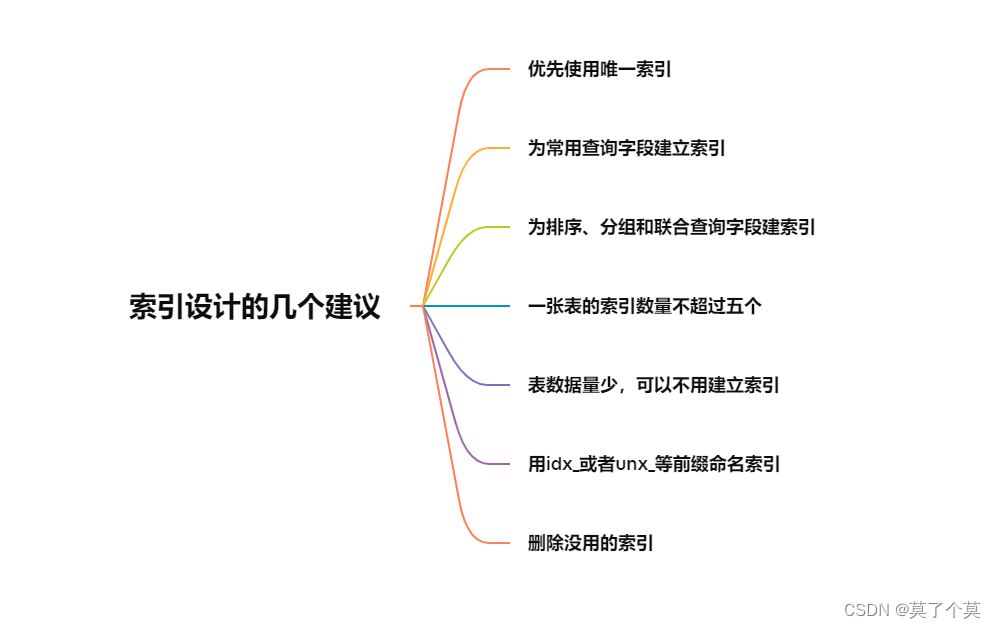
pg_prewarm
pg_prewarm 直接利用系统缓存的代码,对操作系统发出异步prefetch请求,在应用中,尤其在OLAP的情况下,对于大表的分析等等是非常耗费查询的时间的,而即使我们使用select table的方式,这张表也并不可能将所有的数据都装载到内存中,而pg_prewarm的功能就是完成一个张表全部进入到内存中的功能。
按照官方文档 PostgreSQL 13的说明,预热有两种方式,一种是手动调用pg_prewarm函数,用于将当前所需的数据装入内存。另一个选择是自动执行,要要设置shared_preload_libraries参数。设置完毕后,系统将自动运行一个后台工作进程,它定期将shared_buffer中的内容写入到文件 autoprewarm. blocks中,以便在重新启动数据库后,快速加载该文件内部的数据块,实现预热功能。
安装与使用方式
create extension pg_prewarm;
-- t1为表名
SELECT pg_prewarm('t1');参数
函数体为
CREATE FUNCTION pg_prewarm(regclass,
mode text default buffer,
fork text default main,
first_block int8 default null,
last_block int8 default null)
RETURNS int8
AS MODULE_PATHNAME, pg_prewarm
LANGUAGE C
- regclass:要做prewarm的表名
- mode:prewarm模式。prefetch表示异步预取到os cache;read表示同步预取;buffer表示同步读入PG的shared buffer
- fork:relation fork的类型。一般用main,其他类型有visibilitymap和fsm
- first_block & last_block:开始和结束块号。表的first_block=0,last_block可通过pg_class的relpages字段获得
- RETURNS int8:函数返回pg_prewarm处理的block数目(整型)
因为对于大小超过shared_buffer/4的表进行全表扫描时,pg一般不会使用全部的shared_buffer,而是只使用很少一部分的shared_buffer。所以,将大表加载到缓存中不能用一个查询来直接实现的,而pg_prewarm正好可以满足这个需求。
性能测试
在一个3363786记录数的业务表中,添加缓存之前的
explain (analyze,buffers) select * from t1;
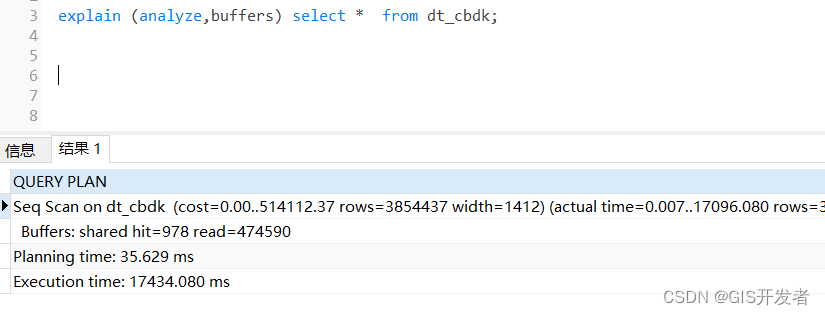
添加缓存后
create extension pg_prewarm
SELECT pg_prewarm('t1');
explain (analyze,buffers) select * from t1;
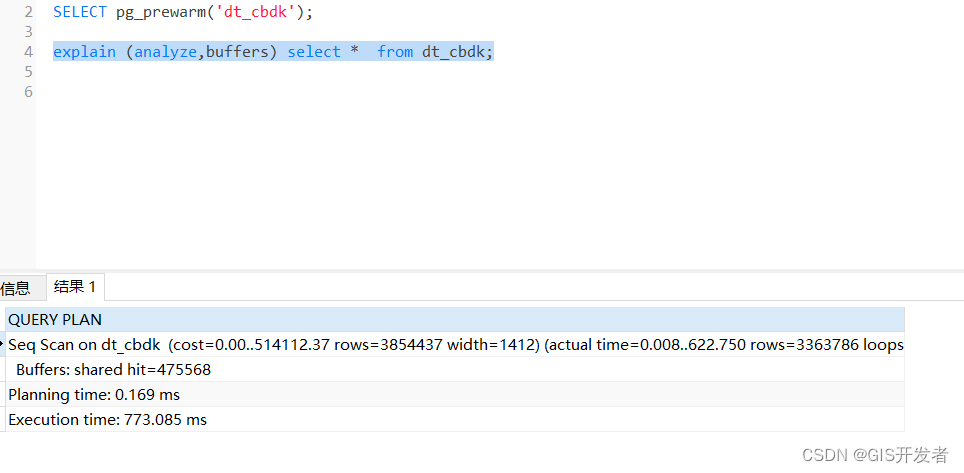
对比上面2图,可以看出,时间大幅度下降.






![[Docker实现测试部署CI/CD----Jenkins集成相关服务器(3)]](https://img-blog.csdnimg.cn/a403a6ebee2949b2bec1f6a16de79589.png)