©PaperWeekly 原创 · 作者 | 张燚钧
单位 | 中国移动云能力中心
研究方向 | 预训练大模型

引言
近年来,大语言模型(Large language model, LLM)取得了显著进展。以 ChatGPT 为代表的 LLM 在自然语言任务上展现出惊人的智能涌现能力。尽管 LLM 在很多推理任务上表现出前所未有的接近人类的性能,但是单纯的LLM只能处理文本类任务。
如图 1、2、3 所示,GPT-4 在技术报告中展示了惊艳的多模态能力。但是 GPT-4 的多模态能力接口还没有开放。与此同时,在大规模数据集上预训练的视觉基础模型也在快速发展。尽管在视觉领域还没有出现“ChatGPT 时刻”,但是预训练视觉基础模型已经可以在很多真实视觉场景、数据集上表现出优秀的零样本、少样本性能。如何将两者在各自领域的优秀性能结合起来,实现在视觉-语言领域具有推理能力的通用大模型是当前一个热门研究课题。
传统计算机视觉任务可以分为三个层次:
1. Close-set:在闭集问题中,算法仅需要处理已知类别的样本。在训练和测试数据集中,所有的类别都是已知的。这意味着算法不需要处理未知类别的数据。闭集问题通常更容易处理,因为在训练期间,我们可以获取所有类别的代表性样本。例如,在手写数字识别任务中,如果我们的目标仅仅是识别数字 0 到 9,那么这就是一个闭集问题。
2. Open-set:在开放集问题中,算法可能需要处理未知类别的样本。这意味着训练数据集中的类别并不完整,测试数据集中可能包含未知类别。在实际应用中,开放集问题更具挑战性,因为算法需要能够区分已知类别和未知类别的样本。
3. In the wild:这个术语指的是算法在现实世界中的应用,即在各种未受控制的环境下处理数据。这与在受控环境下(如实验室环境)进行的计算机视觉任务相反。在实际应用中,数据可能包含各种噪声、光照变化、遮挡等问题,这使得 in the wild 任务在技术上更具挑战性。例如,面部识别算法在实际生活中需要处理各种姿势、表情、光照条件和遮挡等问题。
通过视觉-语言对齐技术,代表性的如 CLIP [1],可以解决开放集的零样本识别问题。谢凌曦在《通向通用人工智能的计算机视觉》一文中提到,LLM 辅助视觉理解用以加强 CV 问题的逻辑性、多模态对话用以促进视觉语言交互,这些工作显示出了视觉通用模型统一的前景 [2]。

模型介绍
下面以发布时间为顺序,介绍主流的融合 LLM 的多模态模型各自的一些特点,以此窥见此类技术的发展趋势。
2.1 主要多模态语言大模型

▲ 图1 让 GPT-4 描述图中有趣的地方。GPT-4 可以识别出 VGA 接口和 lightning 接口,而且判断出 VGA 接口与手机是不匹配的。

▲ 图2 GPT-4 既可以识别出熨烫衣服,也能够识别出租车在行驶,最终识别出这两个场景出现在一个画面中是不正常的。

▲ 图3 GPT-4 在这个画面的识别中展现出了较为强大的推理能力。GPT-4 指出这张图中的主体是按照世界地图形状摆放的鸡块。而文字部分的描述是“从太空俯视地球的照片”。这种文字和图片内容的反差形成了一个幽默的笑话。
BLIP2 [3] 是较早提出 “LLM + 视觉编码器“这种多模态模型构想的工作。这个工作主要提出了 Q-former 这个跨视觉语言模态的连接结构。Q-former 结构设计包括了 image-text matching, image-grounded text generation,image-text contrastive learning。这些对齐语言和视觉特征的设计主要来源于 BLIP1 [4] 工作。BLIP2 中使用的 image encoder 是 ViT-L/g。BLIP2 原文中使用的 LLM 是 OPT 和 FlanT5 语言模型,这些模型在语言生成方面的能力不是特别强。
BLIP2 的预训练分为两阶段,第一阶段 Q-former 与一个冻结参数的 image encoder 训练,学习视觉语言表征;第二阶段 Q-former 与冻结的 LLM 训练,学习视觉到文本的生成能力。在进行一些下游任务,如 image caption,visual question answering(VQA),BLIP2 模型仍需要微调 Q-former 和 image-encoder的模型权重。BLIP2 模型的一个缺陷是,没有 in context learning 能力,上下文关联对话能力较差。作者认为原因是 BLIP2 的训练数据是单对的图文对,数据本身就缺少多轮对话相关性。
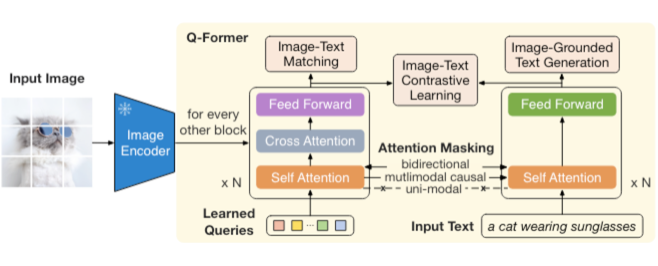
▲ 图4 Q-former 结构
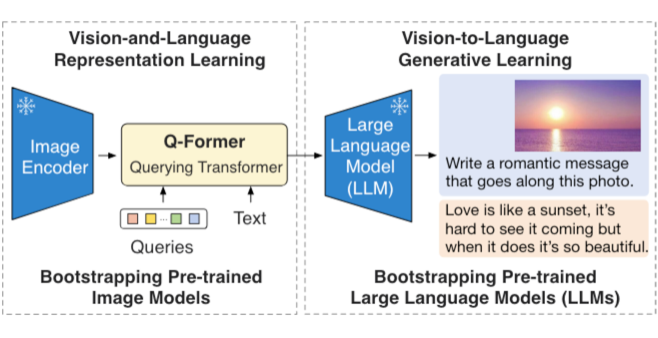
▲ 图5 Q-former 两阶段预训练
MiniGPT-4 是作者场景复现 GPT-4 强大的多模态能力提出的工作。MiniGPT-4 将 Q-former & ViT 视为一个参数冻结的整体。LLM 也保持参数冻结。如图所示,MiniGPT-4 通过一个线性层来跨模态连接这两个部分。Mini-GPT4 使用语言生成能力较强的 Vicuna 模型(基于开源 LLaMA 模型构建)作为 LLM,生成文本质量进一步提高。MiniGPT-4 性能表现的提高也得益于训练数据的质量。作者表示只使用来自公开数据集的图文对数据是无法训练出优秀的多模态语言模型的。
MiniGPT-4 使用了 3500 对高质量图文数据对模型进行微调。MiniGPT-4 模型的训练分为两阶段,第一阶段是在大量图文对数据集上预训练,获得视觉语言对齐能力。第二阶段是在高质量图文数据上微调以获得较强的对话能力。这种两阶段的训练方法也成为了未来一些工作的主流训练范式。
MiniGPT-4 使用的 3500 对高质量数据集是来源于作者使用第一阶段预训练完成的模型,通过提示工程的方法为每张图片生成长度更长,描述信息更加丰富、细节的文本。这些文本通常具有很多噪声和内容错误,作者利用 ChatGPT 对第一阶段的生成文本进行再优化。MiniGPT4 这个工作进一步说明了数据质量对于模型对话能力的重要性。
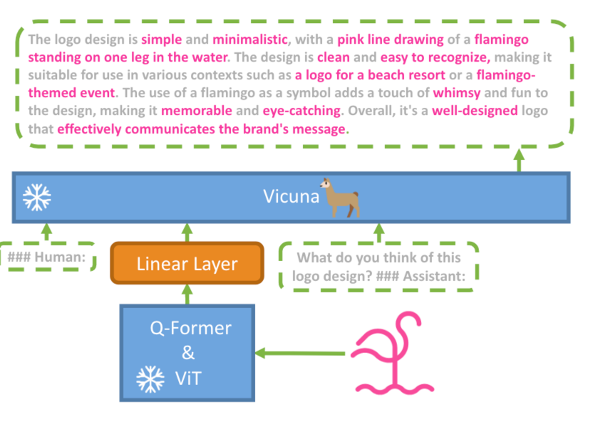
▲ 图6 MiniGPT-4模型结构
微软团队在 MiniGPT-4 发布相近的时间点提出了 LLaVA 模型这篇工作。两篇工作都提升了多模态语言模型在复杂对话方面的能力,具有一定相似性,实现技术方案各有特点。LLaVA 使用线性层连接连接 image encoder 的视觉特征和语言指令,共同送入到 LLM 的输入。LLaVA 没有保留 Q-former这种比较重型的结构,直接使用线性层连接视觉语言模态,第一次将跨模态连接结构简化至这个程度。LLaVA 模型的训练也分为两个阶段。
第一阶段使用图文对数据进行训练,这一阶段是为了对齐视觉和图像特征,这个阶段视觉编码器和 LLM 的参数均冻结,仅训练连接层。第二阶段使用多轮对话图文数据进行训练,在这个阶段训练连接层和 LLM 的参数。LLaVA 在多模态推理评测数据集 Science QA 上达到了最高水平。
LLaVA 强大的性能来自于作者构造的一套指令跟随数据集(instruction-following)。与 MiniGPT-4 主要利用一阶段训练模型进行微调数据生成,还需要进行文本噪声、错误后处理不同,LLaVA 调用 GPT-4 接口,结合人类标注的图文信息,进行高质量的多轮对话图文数据生成。作者将这个高质量图文对话数据集命名为 LLaVA-150K 并且开源。LLaVA-150K 包含了基于图像信息构造的“对话、细节描述、复杂推理”三种类型的文本内容。
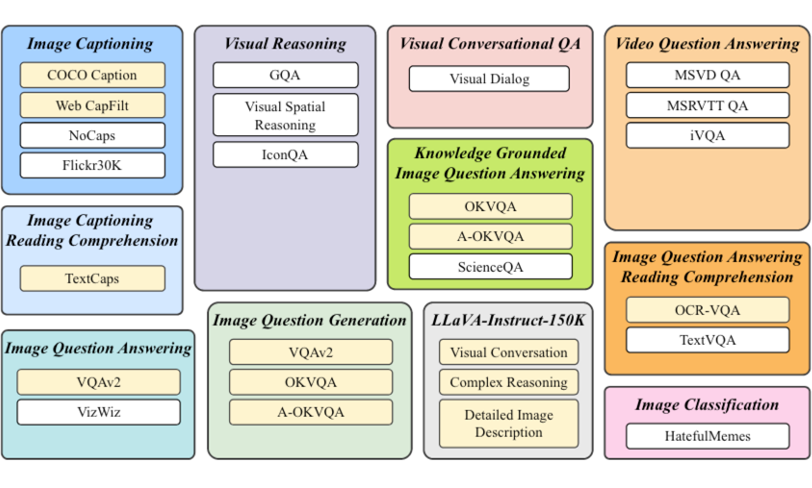
▲ 图7 InstructBLIP使用的多种数据集及其任务类型
BLIP2 团队后来推出了 InstructBLIP 这个工作 [5],通过指令微调的方式解决 BLIP2 模型的一些缺陷。相比 BLIP2,InstructBLIP 已经具有较强的多轮对话能力。InstructBLIP 复用了 BLIP2 的模型架构,即模型由 LLM,visual encoder,Q-former 组成。
相比 BLIP2,InstructBLIP 使用了较新的 T5、Vicuna 语言模型。在指令微调过程中,模型中的视觉编码器和 LLM 参数冻结,只训练 Q-former 参数。InstructBLIP 使用的数据类型非常广泛,一共包括 11 个任务场景、26 个数据集。这些数据集包含的内容特别广,经过微调训练后,InstructBLIP 可以回答单选、多选、短答案、长答案等多种形式的类型问题。
2.2 具有目标定位能力的多模态语言大模型
目标检测是传统计算机视觉领域的核心任务之一,研究者们也思考如何把目标定位的能力引入到多模态语言大模型中。在 LLaVA 工作中,作者们在生成数据时已经将图像中的目标定位信息通过 box 标注的形式给到模型。多模态语言大模型具备目标定位能力,是实现通用视觉模型的必由之路。在这方面目前有几个工作进行了探索。

▲ 图8 LLaVA模型的目标位置信息标注
DetGPT 是通过系统加上开放集目标检测模型实现的,实现比较清晰简单 [6]。在整个系统中,从 LLM 的输出中提取目标词汇,然后放入 Grounding DINO 模型中,在图像中检索定位目标。这种方法松解耦,方便替换检测模型,但是并没有真正充分发掘 LLM 的生成能力。
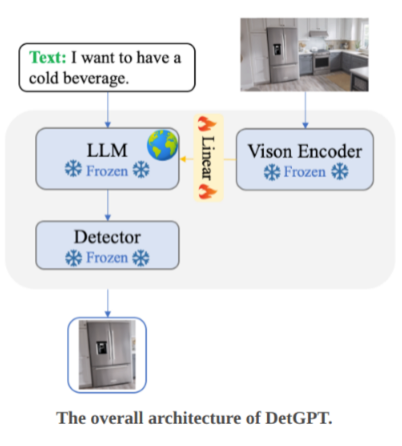
▲ 图9 DetGPT系统框架
商汤科技提出的 VisionLLM 模型,也具有视觉目标定位功能 [7]。VisionLLM 是集成在商汤 InternGPT 多模态模型中,模型主体是共享参数的通才模型,通过语言指令切换不同任务。模型使用了两种 image backbone:ResNet 和 InternImage-H。language-guided image tokenizer 是 BERT + Deformable DETR。LLM 用的是 Alpaca-7B(LLaMA 衍生)。
这里跟大多数多模态语言大模型是不一样的,从论文中看,没有使用全连接层或者是 Q-former 来连接多模态,而是通过 Language-guided image tokenizer 连接多模态,然后接入 LLM。整体的训练过程也是分为两阶段,第一阶段训练 visual backbone 和 image tokenizer,LLM只训练一小部分 LoRA 参数,这一阶段主要关注目标检测任务和任务描述。第二阶段冻结 visual backbone,训练模型其他部分参数。
VisionLLM 在处理视觉任务时,使用了特定的物体类别标志位和位置标志位(location token)进行标注处理,相对更复杂。此外,对于图片中目标位置,使用目标在图像中的绝对坐标,没有使用相对坐标。
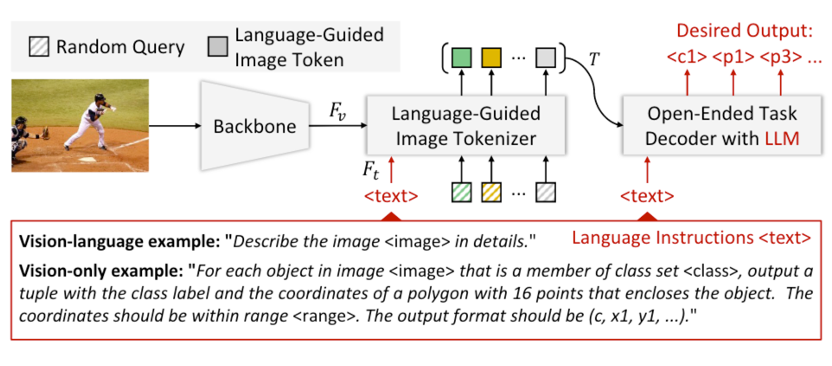
▲ 图10 VisionLLM整体模型结构

▲ 图11 VisionLLM的目标检测能力
最近,商汤团队提出了一个具有目标定位能力的多模态语言模型 Shikra。Shikra 使用两种方式来表示目标坐标:四个坐标点表示 bounding box 或者两个坐标点表示目标中心点。
Shikra 的做法与 VisionLLM 有两个较大的不同点。第一,使用自然语言表示坐标。VisionLLM 使用专用的 location tokens 表示坐标,Shikra 则不作任何特殊处理,就按照与普通文字一致的方法处理坐标文字。第二,VisionLLM 使用目标在图像中的绝对坐标表示,Shikra 使用相对坐标表示,把坐标范围统一在 0 到 1 范围内。
Shikra 的训练过程类似 LLaVA,也是两阶段训练,但是在两个阶段中,LLM 和连接层的参数都随训练改变。Shikra 的方法设置相对 VisionLLM 简单了不少,对于数据处理和模型调整都便利了许多。这种方法的缺点是,通过自然语言处理坐标字符,会占用较多 token,LLM 处理起来速度较慢。

▲ 图12 Shikra模型目标定位效果
2.3 多模态语言大模型评测基准
对于传统的多模态模型来说,已经有了很多相关的下游任务评测数据集。但当大语言模型时代来临时,过去的评测方向已经无法有效评价多模态语言大模型的能力。目前也有很研究者投入了相关领域的研究。LAMM 和 MMBench 目前影响力较大的两个已发布的多模态大模型评测基准。
LAMM 测试基准主要分为两部分,LAMM-Dataset 和 LAMM-Benchmark。LAMM-Dataset 包括 2D 图像和 3D 点云理解。LAMM 通过公开数据集中收集、self-Instruction method 和 GPT API 生成等方法,构造了 4 种类型一共 18 万指令-响应对数据。LAMM-Benchmark 包括了 9 种常见图像任务、共 6 万条样本的 11 个数据集。LAMM 也提供了 LAMM-Framework,一个可以较为通用地实现多模态大语言模型的框架。
最近上海人工智能实验室提出 MMBench 评测体系,提出了 “CircularEval” 评测概念。如图 13 所示,MMBench 将多模态大模型的能力根据难度层级分为 L1-L3。
具体来说,MMBench 包含了 3000 个选择题,从 20 个细分能力的角度对多模态模型能力进行较为细致的评测。值得注意的是,目前多模态大模型的推理能力依赖于 LLM,所以同样存在 LLM 的幻觉和输出鲁棒性问题。MMBench 提出使用 ChatGPT 来辅助“提炼”多模态大模型的输出,以此保证参与测评的大模型输出结果可以应对选择题场景。
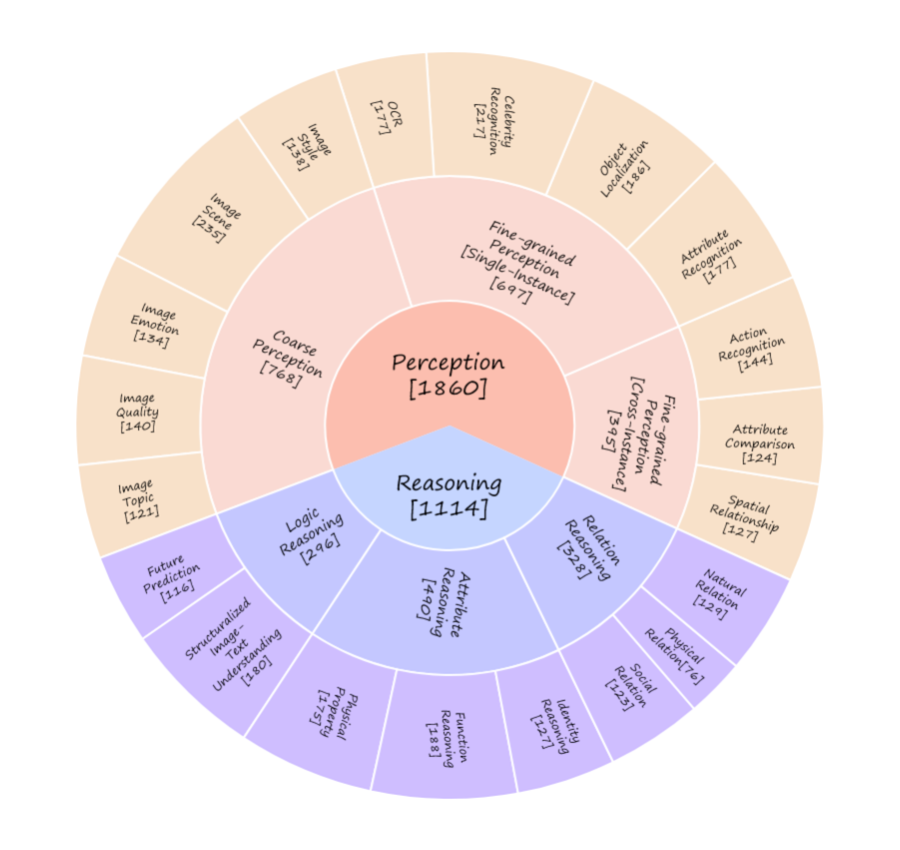
▲ 图13 MMBench的Circular评测图谱

结语
从以上这些融合了 LLM 的多模态模型,我们可以得到一些发现。可能是受 GPT4 所展示的多模态能力的启发,主要的多模态大模型工作主要都是集中在 23 年。目前融合 LLM 和视觉模型的方式还相对简单粗暴,多数是依赖已有的 LLM 和 Visual encoder,并通过简单的线性层或者 Q-former 结构连接。此类模型的训练范式也基本为二阶段训练,着重于提升语言视觉对齐和多轮对话能力。
尽管如此,目前的多模态大模型已经展现出了优秀的效果,未来多模态通用模型可能成为人工智能的下一个发展目标。视觉研究者和语言大模型研究者的研究范式呈现出越来越相近的趋势。

参考文献
[1] A. Radford et al., “Learning Transferable Visual Models From Natural Language Supervision,” in Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, M. Meila and T. Zhang, Eds., in Proceedings of Machine Learning Research, vol. 139. PMLR, 2021, pp. 8748–8763. Accessed: Jul. 25, 2023. [Online]. Available: http://proceedings.mlr.press/v139/radford21a.html
[2] L. Xie et al., “Towards AGI in Computer Vision: Lessons Learned from GPT and Large Language Models.” arXiv, Jun. 14, 2023. doi: 10.48550/arXiv.2306.08641.
[3] J. Li, D. Li, S. Savarese, and S. Hoi, “BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models.” arXiv, May 01, 2023. doi: 10.48550/arXiv.2301.12597.
[4] J. Li, D. Li, C. Xiong, and S. Hoi, “BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation.” arXiv, Feb. 15, 2022. doi: 10.48550/arXiv.2201.12086.
[5] W. Dai et al., “InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning.” arXiv, May 10, 2023. doi: 10.48550/arXiv.2305.06500.
[6] “DetGPT: Detect What You Need via Reasoning.” OptimalScale, Jul. 27, 2023. Accessed: Jul. 28, 2023. [Online]. Available: https://github.com/OptimalScale/DetGPT
[7] W. Wang et al., “VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks.” arXiv, May 18, 2023. doi: 10.48550/arXiv.2305.11175.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·