微服务架构已成为云数据中心的基本服务架构。但目前关于微服务系统弹性缩放的研究大多是基于服务或实例级别的水平缩放,忽略了能够充分利用单台服务器资源的细粒度垂直缩放,从而导致资源浪费。为此,本文设计了主动式微服务细粒度弹性缩放算法。算法通过预测请求到达率对系统进行资源预配置。基于预测结果,应用平方根配置规则计算需求资源数量,进而利用垂直缩放的细粒度资源控制特性和水平缩放的高可用性对微服务进行伸缩。最后应用基于微服务依赖关系的实例迁移算法进一步降低资源开销。实验表明,本文提出的算法在优化微服务系统时延和开销方面取得了显著效果。
目录
3 算法设计
3.3 微服务实例迁移与缩放
3.3.1 HABVH 算法整体架构
3.3.2 垂直扩展算法
3.3.3 水平扩展算法
3.3.5 实例迁移算法
3 算法设计
3.3 微服务实例迁移与缩放
根据 SR Rule 为每个微服务计算出需要缩放的核心数后,需要决定要扩展的核心具体的部署位置以及要回收的核心所属的实例。因此,本章提出了基于垂直和水 平 的 混 合 微 服 务 缩 放 算 法 ( Hybrid ScalingAlgorithm for Micro-Service Based on Vertical andHorizontal,HABVH )对微服务实例进行细粒度伸缩,旨在保证服务性能的同时减少使用的服务器数量。
3.3.1 HABVH 算法整体架构
HABVH 算法充分利用垂直缩放的细粒度控制和水平缩放的高可用性对微服务进行缩放。首先,根据 SRRule 计算得到的核心数判断微服务是否需要缩放,并将需要缩放的微服务加入集合𝑁 𝑡𝑑𝑎𝑚𝑓 中,进而对𝑁 𝑡𝑑𝑎𝑚𝑓中的微服务进行具体缩放操作。
HABVH 包含以下几个主要步骤:首先判断𝑁 𝑡𝑑𝑎𝑚𝑓中的微服务需要扩展还是收缩。对于需要扩展的微服务,优先执行垂直扩展算法( Vertical Scale-Out Algorithm,VSOA ),如果垂直扩展后仍然存在待部署核心,则将微服务加入水平扩展队列 𝑅 𝑝𝑣𝑢ℎ。当𝑁 𝑡𝑑𝑎𝑚𝑓 中所有需要扩展的微服务都执行完垂直扩展后,再对水平扩展队列中的微服务统一执行水平扩展算法( Horizontal Scale-Out Algorithm,HSOA )。对于需要收缩的微服务,调用延时实例收缩算法( Instance Scale-In Algorithm,ISIA )回收核心。当集合𝑁 𝑡𝑑𝑎𝑚𝑓 中所有微服务完成缩放后,为了进一步降低供应商租赁的服务器数目,本文提出了实例迁移算法( Instance Migration Algorithm,IMA ),IMA 可在保证服务性能不下降的前提下减少使用的服务器数目。
3.3.2 垂直扩展算法
垂直扩展算法充分利用已部署实例所属服务器上的资源对微服务进行细粒度扩展。垂直扩展算法具有两个优势:首先,垂直扩展利用已经启动的服务器上的资源进行扩展,不需要额外租赁服务器,因此避免增加供应商的成本开销。其次,根据定理 1,垂直扩展可将微服务实例集中部署,其性能优于拆分部署方案。但是,当对微服务已部署实例全部执行完垂直扩展后还存在待部署的核心,则需要将微服务加入水平扩展队列𝑅 𝑝𝑣𝑢ℎ,并在所有微服务执行完垂直扩展后调用水平扩展算法。
3.3.3 水平扩展算法
水平扩展算法将待扩展的实例分为大实例和小实例,并对大实例和小实例采用不同的部署方式,以快速得到部署方案。首先计算参数𝑣和𝑤的值:
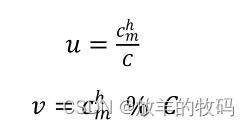
3.3.5 实例迁移算法
为了进一步减少使用的服务器数目,降低服务供应商的成本,本文设计了实例迁移算法 IMA。实例迁移算法的整体思想如下:将资源利用率低的服务器上的实例尽可能迁移到资源利用率较高的服务器上,然后将资源利用率低的服务器的实例列表清空,以减少租赁的服务器数量。为了尽量减小迁移过程对微服务系统性能的影响,本文定义服务器𝑗的评价函数𝐸 𝑗 ,𝐸 𝑗 用服务器𝑗上部署的微服务之间的依赖关系总和来计算。