源自:机器人大讲堂
导 语

缘 起


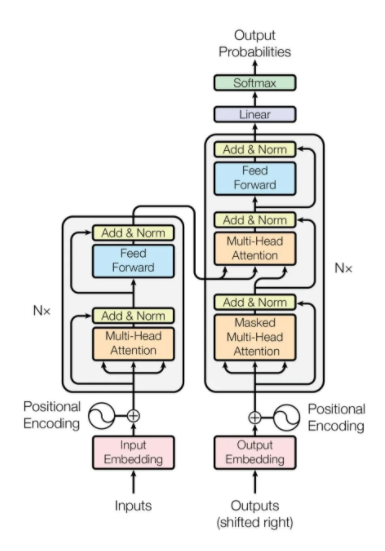
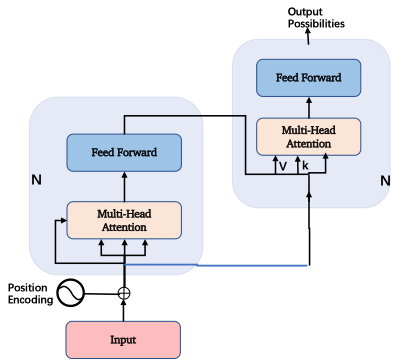
论文介绍






这两个向量存在于两个不同的向量空间,主要的区别就是前者多了一个向量特征:“年薪”。可以思考一下如果判断一个人的信用额度,“年薪”是不是一个很重要的影响因子?
以上例子还是很简单的,只是增加了一个特征值,在transformer里就复杂很多,它是要把多个向量信息通过矩阵加减乘除综合计算,从而赋予一个向量新的含义。
好,理解了向量的重要性,我们看回transformer的三步走,这三步走分别是:1.编码(Embedding)2. 定位 (onal encoding)3. 自注意力机制(Self-Attention)。
举个例子,比如,翻译句子Smart John is singing到中文。
首先,要对句子每个词进行向量化。
我们先看“John”这个词,需要先把“John”这个字母排列的表达转换成一个512维度的向量John,这样计算机可以开始认识它。说明John是在这个512维空间的一个点,这是第一步:编码(Embedding)。
再次,第二步: 定位(Positional encoding),利用以下公式(这是这篇论文的创新)
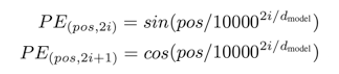
微调一个新的高维空间,生成一个新的向量。




计算过程
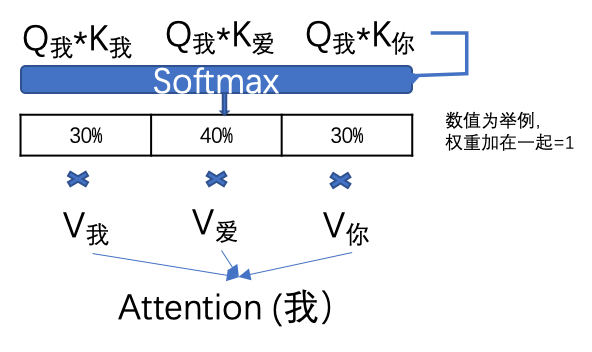
具体的计算过程,用翻译句子“我爱你”到“I love you”举例(这句更简单一些)。首先进行向量化并吸收句子位置信息,得到一个句子的初始向量组。





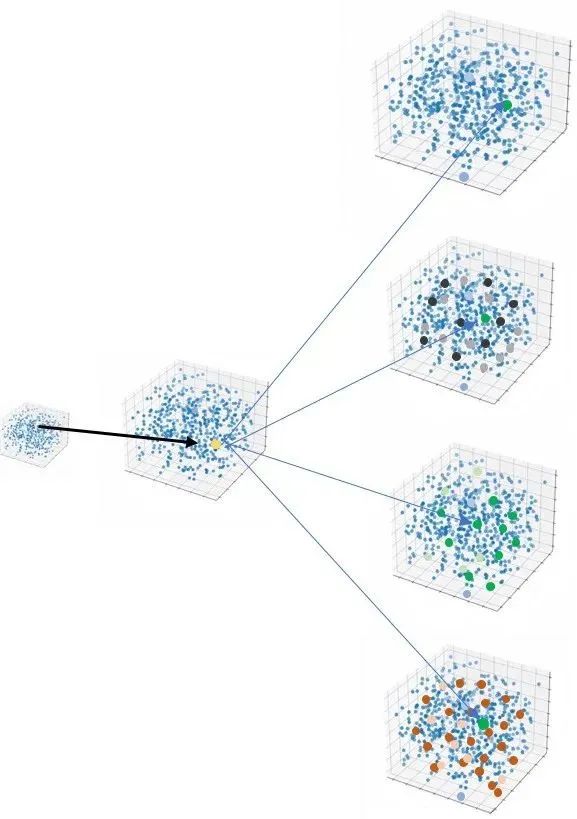

启发收获




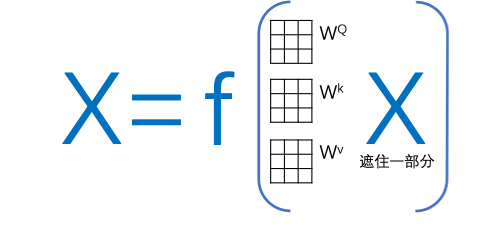


本文仅用于学习交流,如有侵权,请联系删除 !!