论文信息
题目:DeepVO Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks
作者:Sen Wang, Ronald Clark, Hongkai Wen and Niki Trigoni
代码地址:http://senwang.gitlab.io/DeepVO/ (原作者并没有开源)
pytorch版本代码地址:https://github.com/ChiWeiHsiao/DeepVO-pytorch
时间:2017年
Abstract
大多数现有的单目视觉里程计(VO)算法都是在标准流程下开发的,包括特征提取、特征匹配、运动估计、局部优化等。虽然其中一些算法已经表现出优越的性能,但它们通常需要仔细设计和专门微调才能正常工作在不同的环境中。恢复单眼 VO 的绝对尺度还需要一些先验知识。
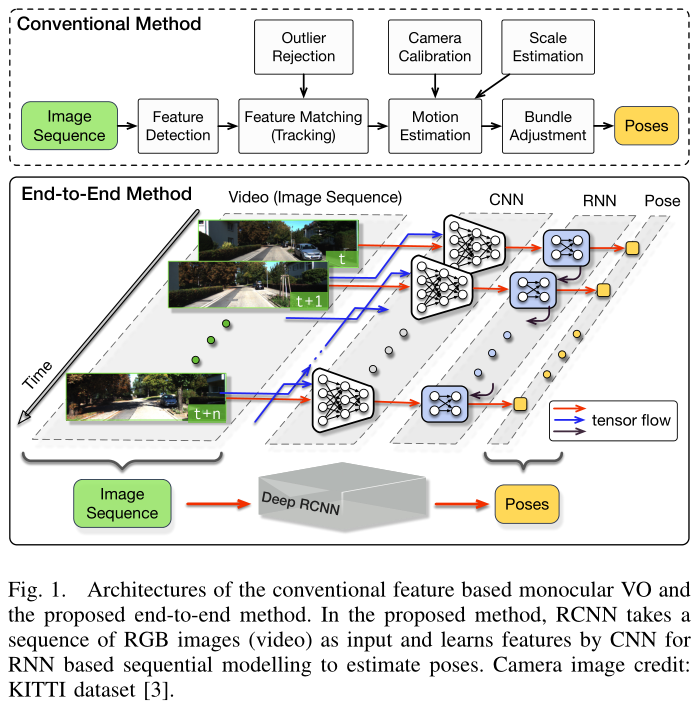
本文通过使用深度循环卷积神经网络 (RCNNs) ,提出了一种新颖的单目 VO 端到端框架。由于它是以端到端的方式进行训练和部署的,因此它可以直接从一系列原始RGB图像(视频)数据中推断出相机姿态,无需采用传统VO管道中的任何模块。
基于 RCNN,它不仅通过卷积神经网络自动学习 VO 问题的有效特征表示,而且还使用深度循环神经网络隐式建模顺序动态和关系。
Introduction
在本文中,我们利用深度循环卷积神经网络(RCNN)提出了一种基于深度学习的新型单目 VO 算法 。由于它是以端到端的方式实现的,因此它不需要经典 VO 管道中的任何模块(甚至相机校准)。
主要贡献有三方面:
1)我们证明单目VO问题可以通过基于深度学习的端到端方式解决,即直接从原始 RGB 图像估计姿势。恢复绝对尺度既不需要先验知识也不需要参数。
2)我们提出了一种 RCNN 架构,通过使用 CNN 学习的几何特征表示,能够将基于 DL 的 VO 算法推广到全新的环境。
3) 图像序列的序列依赖性和复杂的运动动力学对于 VO 很重要,但人类无法显式或轻松地建模,但它们可以由深度递归神经网络 (RNN) 隐式封装和自动学习。
Related Work
基于几何的方法
(这部分不多解释)
1)基于稀疏特征的方法:
2)直接方法:
基于学习的方法
由于 CNN 无法对顺序信息进行建模,因此之前的工作都没有考虑图像序列或视频进行顺序学习。在这项工作中,我们通过利用 RNN 来解决这个问题。
通过 RCNN 进行端到端视觉里程计
提出的RCNN框架
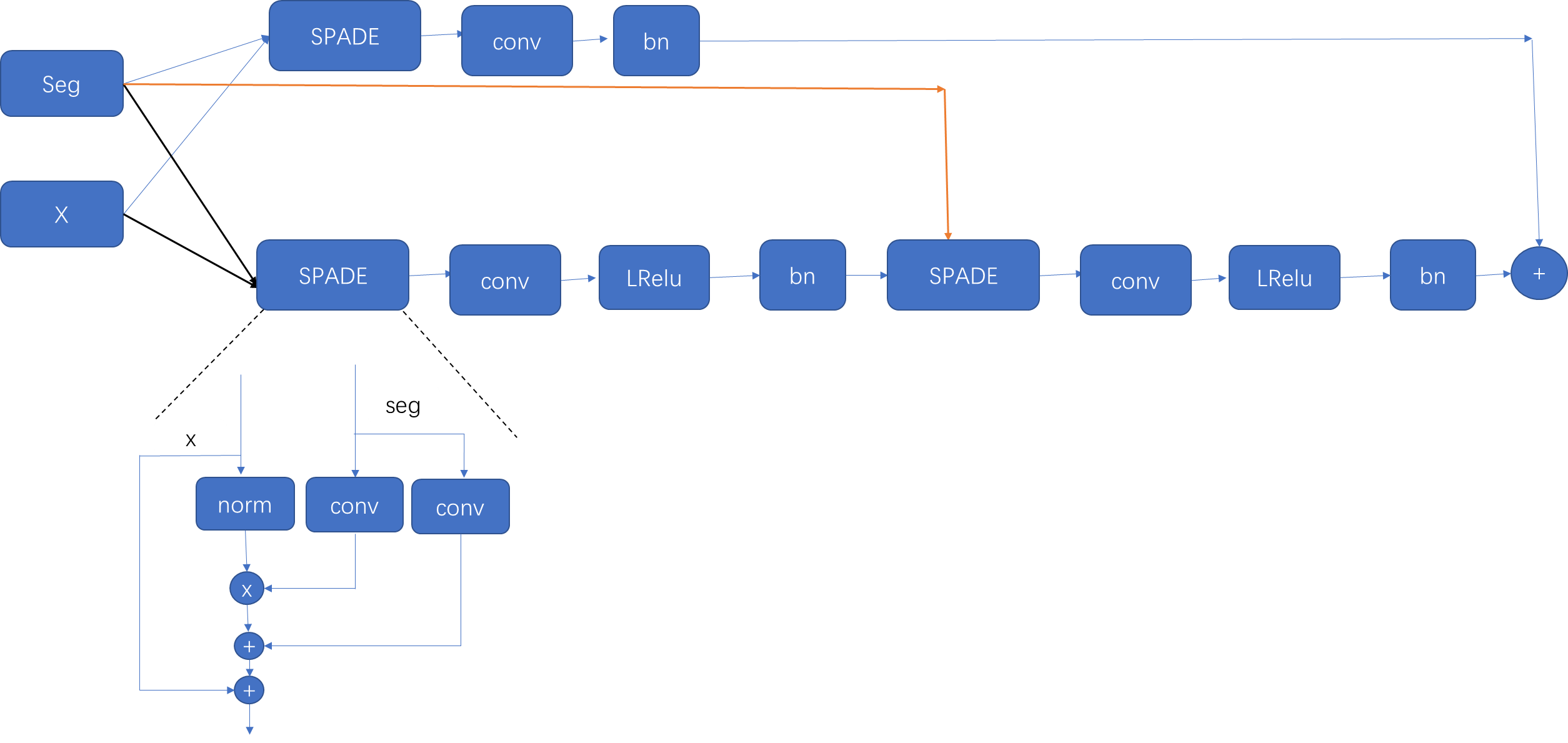
所提出的端到端 VO 系统的架构如图 所示。它以视频剪辑或单目图像序列作为输入。在每个时间步,通过减去训练集的平均 RGB 值来对 RGB 图像帧进行预处理,并且可以选择将其大小调整为 64 倍数的新大小。两个连续图像堆叠在一起以形成张量深度 RCNN 学习如何提取运动信息和估计姿势。具体来说,图像张量被输入 CNN,为单目 VO 生成有效特征,然后通过 RNN 进行顺序学习。每个图像对都会在网络的每个时间步产生一个姿态估计。 VO 系统随着时间的推移而发展,并在捕获图像时估计新的姿势。
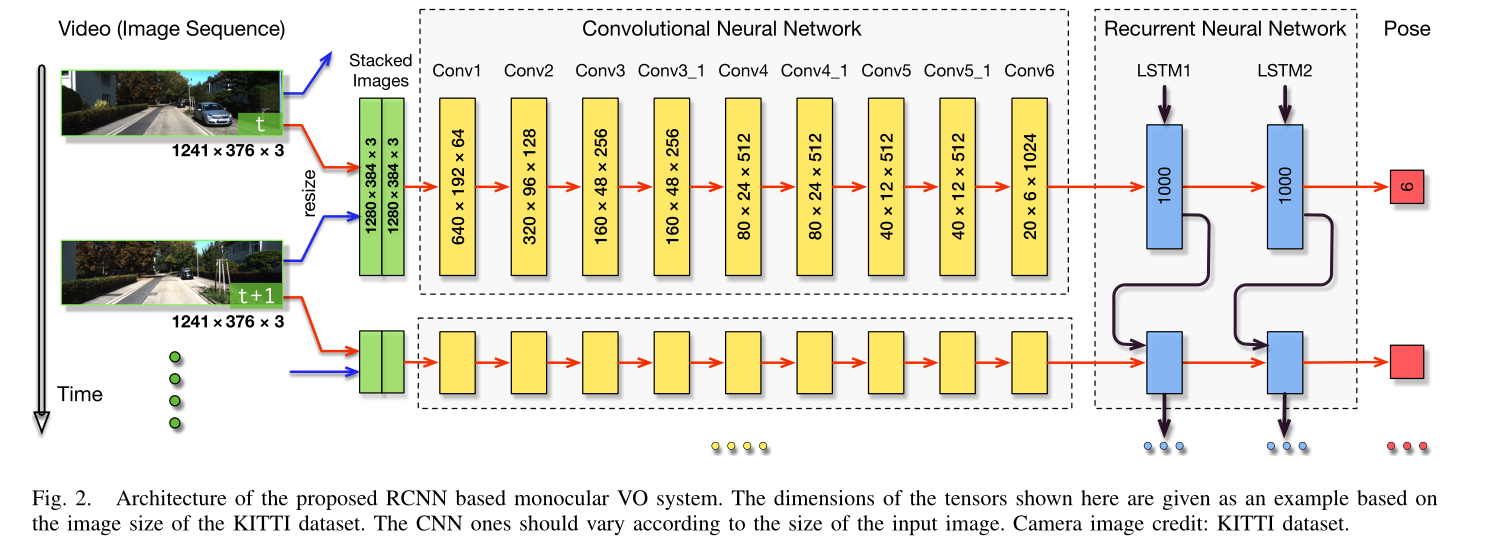
基于CNN的特征提取
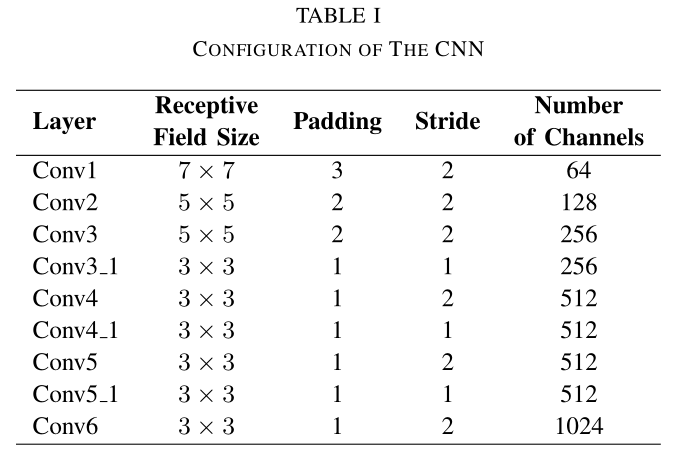
KITTI 数据集上的张量示例。它有 9 个卷积层,除了 Conv6 之外,每层后面都有一个修正线性单元 (ReLU) 激活,即:共17层。网络中感受野的大小逐渐从 7 × 7 减小到 5 × 5,然后减小到 3 × 3,以捕获小的有趣特征。引入零填充是为了适应感受野的配置或在卷积后保留张量的空间维度。通道的数量,即用于特征检测的滤波器的数量,增加以学习各种特征。
CNN的构成:
基于RNN的序列建模
RNN 与 CNN 的不同之处在于,它随着时间的推移保持其隐藏状态的记忆,并且它们之间具有反馈循环,这使得其当前隐藏状态成为先前隐藏状态的函数,如图 2 所示的 RNN 部分。因此, RNN 可以找出输入与序列中先前状态之间的联系。给定时间 k k k 的卷积特征 x k x_k xk,RNN 在时间步 k k k 更新为:
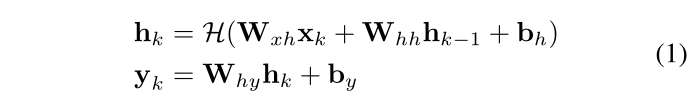
where h k h_k hk and y k y_k yk are the hidden state and output at time k k k respectively, W terms denote corresponding weight matrices, b b b terms denote bias vectors, and H H H is an element-wise non- linear activation function, such as sigmoid or hyperbolic tangent.
为了能够发现和利用长轨迹拍摄的图像之间的相关性,我们采用长短期记忆(LSTM)作为我们的 RNN,它能够通过引入记忆门和单元来学习长期依赖性。它明确确定要丢弃或保留哪些先前的隐藏状态以更新当前状态,并期望在姿势估计期间学习运动。
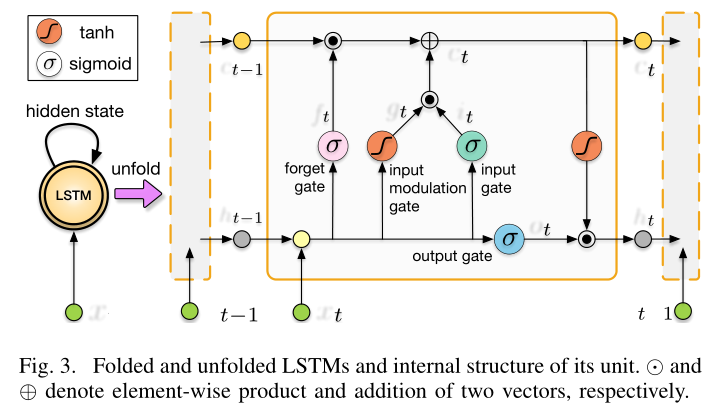
图 3 显示了折叠的 LSTM 及其随时间的展开版本以及 LSTM 单元的内部结构。可以看到,展开LSTM后,每个LSTM单元都与一个时间步相关联。给定时间 k k k 处的输入 x k x_k xk 以及前一个 LSTM 单元的隐藏状态 h k − 1 h_{k−1} hk−1 和存储单元 c k − 1 c_{k−1} ck−1 ,LSTM 根据以下公式在时间步 k k k 处更新:
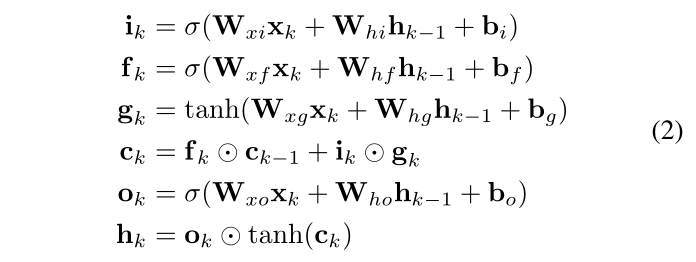
where ⊙ \odot ⊙ is element-wise product of two vectors, σ is sigmoid non-linearity, t a n h tanh tanh is hyperbolic tangent non-linearity, W terms denote corresponding weight matrices, b b b terms denote bias vectors, i k , f k , g k , c k i_k, f_k, g_k, c_k ik,fk,gk,ck and o k o_k ok are input gate, forget gate, input modulation gate, memory cell and output gate at time k k k, respectively
尽管 LSTM 可以处理长期依赖性并具有深层时间结构,但它仍然需要网络层的深度来学习高级表示和对复杂动态进行建模。
在我们的例子中,深度 RNN 是通过堆叠两个 LSTM 层来构建的,其中一个 LSTM 的隐藏状态是另一个 LSTM 层的输入,如图 2 所示。在我们的网络中,每个 LSTM 层都有 1000 个隐藏状态。
成本函数和优化
所提出的基于 RCNN 的 VO 系统可以被认为是计算相机姿势的条件概率 Y t = ( y 1 , . . . , y t ) Y_t = (y_1, ..., y_t) Yt=(y1,...,yt) 给定一系列单目 RGB 图像 X t = ( x 1 , . . . , x t ) X_t = (x_1, ..., x_t) Xt=(x1,...,xt) 直到时间 t t t从概率的角度来看:
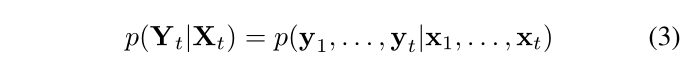
建模和概率推理在深度 RCNN 中进行。为了找到 VO 的最佳参数 θ*,DNN 最大化 (3):
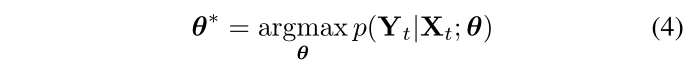
为了学习 DNN 的超参数 θ,时间 k 时的地面真实姿势 ( p k , ϕ k ) (p_k, \phi_k) (pk,ϕk) 与其估计姿势 ( p ^ k , ϕ ^ k ) (\hat{p}_k, \hat{\phi}_k) (p^k,ϕ^k)之间的欧几里德距离被最小化。损失函数由所有位置 p 和方向 ϕ \phi ϕ的均方误差 (MSE) 组成:
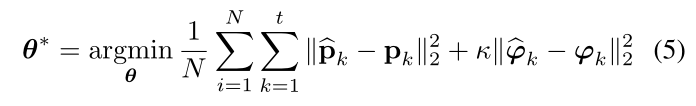
其中 ∥ ⋅ ∥ \left \| \cdot \right \| ∥⋅∥ 是 2-范数,κ(实验中为 100)是平衡位置和方向权重的比例因子,N 是样本数。方向 ϕ \phi ϕ 由欧拉角而不是四元数表示,因为四元数受到额外的单位约束,这阻碍了深度学习的优化问题。我们还发现,在实践中使用四元数会在一定程度上降低方向估计。
EXPERIMENTAL RESULTS
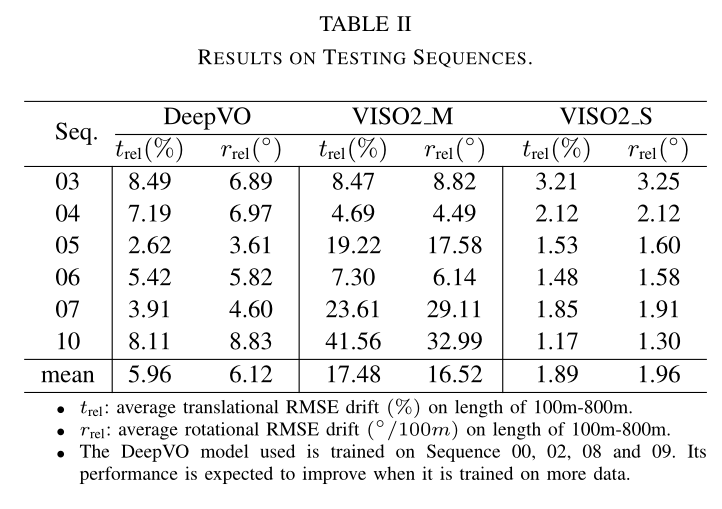
1)数据集:KITTI VO/SLAM基准[3]有22个图像序列,其中11个(序列00-10)与地面实况相关。其他 10 个序列(序列 11-21)仅提供原始传感器数据。
由于该数据集是在动态物体较多的城市地区行驶时以相对较低的帧率(10 fps)记录的,并且行驶速度高达90 km/h,因此对于单目VO算法来说非常具有挑战性。
2)训练和测试:进行两个单独的实验来评估所提出的方法。第一个是基于序列00-10,通过groundtruth定量分析其性能,因为groundtruth仅针对这些序列提供。为了有单独的数据集进行测试,仅使用相对较长的序列00、02、08和09进行训练。将轨迹分割成不同的长度,以生成大量的训练数据,总共产生 7410 个样本。训练好的模型在序列03、04、05、06、07和10上进行测试以进行评估。