遇到一个还不错的使用Xgboost训练模型的githubhttps://github.com/MachineLP/Spark-/tree/master/pyspark-xgboost
1、这是一个跑通的代码实例,使用的是泰坦尼克生还数据,分类模型。
这里使用了Pipeline来封装特征处理和模型训练步骤,保存为pipelineModel。
注意这里加载xgboost依赖的jar包和zip包的方法。
#这是用 pipeline 包装了XGBOOST的例子。 此路通!import os
import sys
import time
import pandas as pd
import numpy as np
import pyspark.sql.types as typ
import pyspark.ml.feature as ft
from pyspark.sql.functions import isnan, isnullfrom pyspark.sql.types import StructType, StructFieldfrom pyspark.sql.types import *
from pyspark.ml.feature import StringIndexer, VectorAssembler
from pyspark.ml import Pipeline
from pyspark.sql.functions import col
from pyspark.sql import SparkSessionos.environ['PYSPARK_PYTHON'] = 'Python3.7/bin/python'
os.environ['PYSPARK_SUBMIT_ARGS'] = '--jars xgboost4j-spark-0.90.jar,xgboost4j-0.90.jar pyspark-shell'spark = SparkSession \.builder \.appName("PySpark XGBOOST Titanic") \.config('spark.driver.allowMultipleContexts', 'true') \.config('spark.pyspark.python', 'Python3.7/bin/python') \.config('spark.yarn.dist.archives', 'hdfs://ns62007/user/dmc_adm/_PYSPARK_ENV/Python3.7.zip#Python3.7') \.config('spark.executorEnv.PYSPARK_PYTHON', 'Python3.7/bin/python') \.config('spark.sql.autoBroadcastJoinThreshold', '-1') \.enableHiveSupport() \.getOrCreate()spark.sparkContext.addPyFile("sparkxgb.zip")schema = StructType([StructField("PassengerId", DoubleType()),StructField("Survived", DoubleType()),StructField("Pclass", DoubleType()),StructField("Name", StringType()),StructField("Sex", StringType()),StructField("Age", DoubleType()),StructField("SibSp", DoubleType()),StructField("Parch", DoubleType()),StructField("Ticket", StringType()),StructField("Fare", DoubleType()),StructField("Cabin", StringType()),StructField("Embarked", StringType())])upload_file = "titanic/train.csv"
hdfs_path = "hdfs://tmp/gao/dev_data/dmb_upload_data/"
file_path = os.path.join(hdfs_path, upload_file.split("/")[-1])df_raw = spark\.read\.option("header", "true")\.schema(schema)\.csv(file_path)df_raw.show(20)
df = df_raw.na.fill(0)sexIndexer = StringIndexer()\.setInputCol("Sex")\.setOutputCol("SexIndex")\.setHandleInvalid("keep")cabinIndexer = StringIndexer()\.setInputCol("Cabin")\.setOutputCol("CabinIndex")\.setHandleInvalid("keep")embarkedIndexer = StringIndexer()\.setInputCol("Embarked")\.setHandleInvalid("keep")# .setOutputCol("EmbarkedIndex")\vectorAssembler = VectorAssembler()\.setInputCols(["Pclass", "Age", "SibSp", "Parch", "Fare"])\.setOutputCol("features")from sparkxgb import XGBoostClassifier
xgboost = XGBoostClassifier(maxDepth=3,missing=float(0.0),featuresCol="features",labelCol="Survived"
)pipeline = Pipeline(stages=[vectorAssembler, xgboost])trainDF, testDF = df.randomSplit([0.8, 0.2], seed=24)
trainDF.show(2)
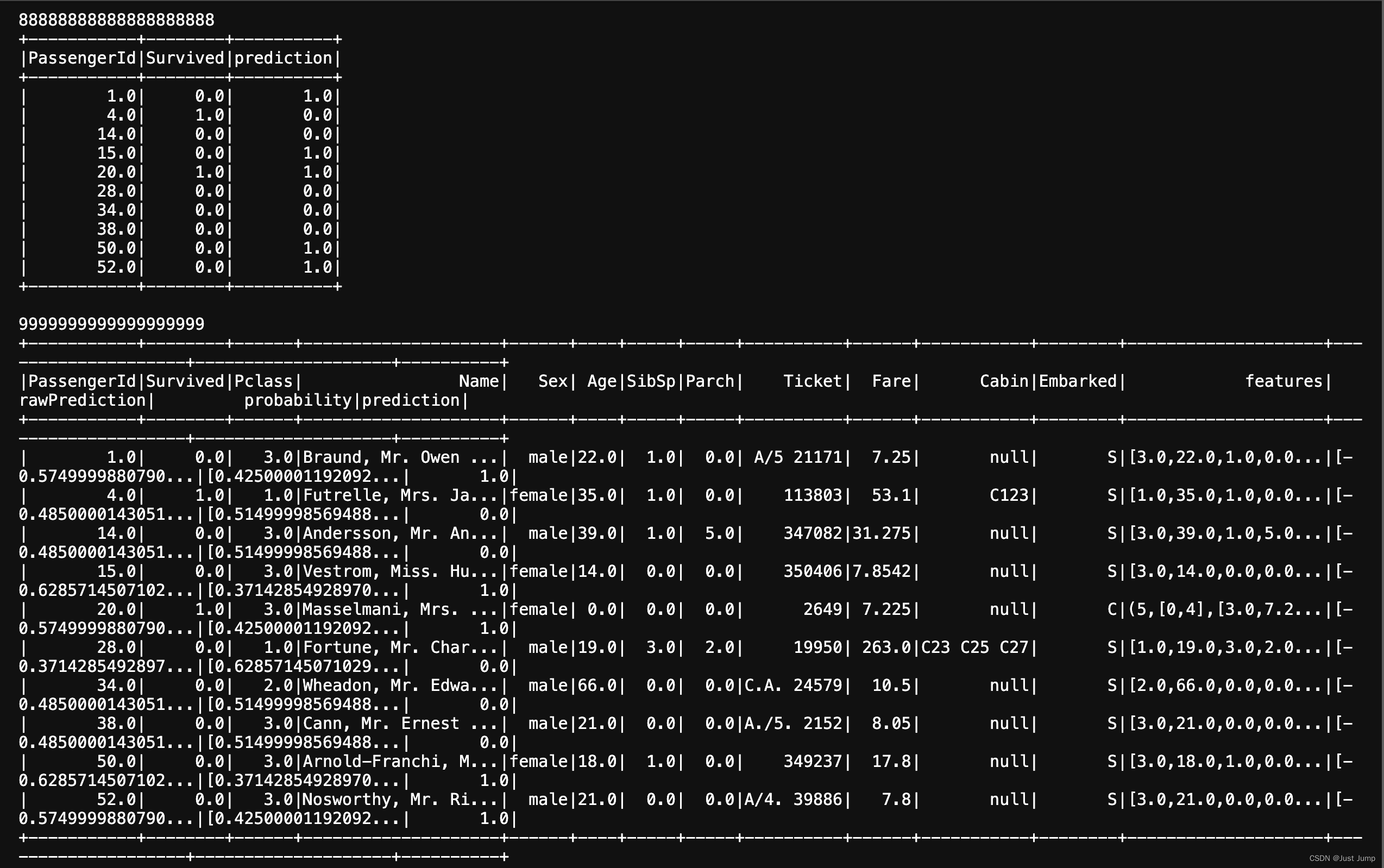
model = pipeline.fit(trainDF)print (88888888888888888888)
model.transform(testDF).select(col("PassengerId"), col("Survived"), col("prediction")).show()
print (9999999999999999999)# Write model/classifier
model.write().overwrite().save(os.path.join(hdfs_path,"xgboost_class_test"))from pyspark.ml import PipelineModel
model1 = PipelineModel.load(os.path.join(hdfs_path,"xgboost_class_test"))
model1.transform(testDF).show()
这是执行结果:

2、当然也可以不用pipeline封装,直接训练xgboost模型,并保存。
但这里遇到无法加载训练好的xgb模型的问题。
# Train a xgboost model
from pyspark.ml.feature import VectorAssembler, StringIndexer, OneHotEncoder, StandardScaler
from pyspark.ml import Pipeline
from sparkxgb import XGBoostClassifierassembler = VectorAssembler(inputCols=[ 'Pclass', 'Age', 'SibSp', 'Parch','Fare'],outputCol="features", handleInvalid="skip")xgboost = XGBoostClassifier(maxDepth=3,missing=float(0.0),featuresCol="features", labelCol="Survived")# pipeline = Pipeline(stages=[assembler, xgboost])
# trained_model = pipeline.fit(data)td = assembler.transform(data)
trained_raw_model = xgboost.fit(td)result = trained_raw_model.transform(td)
result.select(["Survived", "rawPrediction", "probability", "prediction"]).show()# save trained model to local disk
trained_raw_model.nativeBooster.saveModel("outputmodel.xgboost")# 无法加载已经训练好的XGB模型
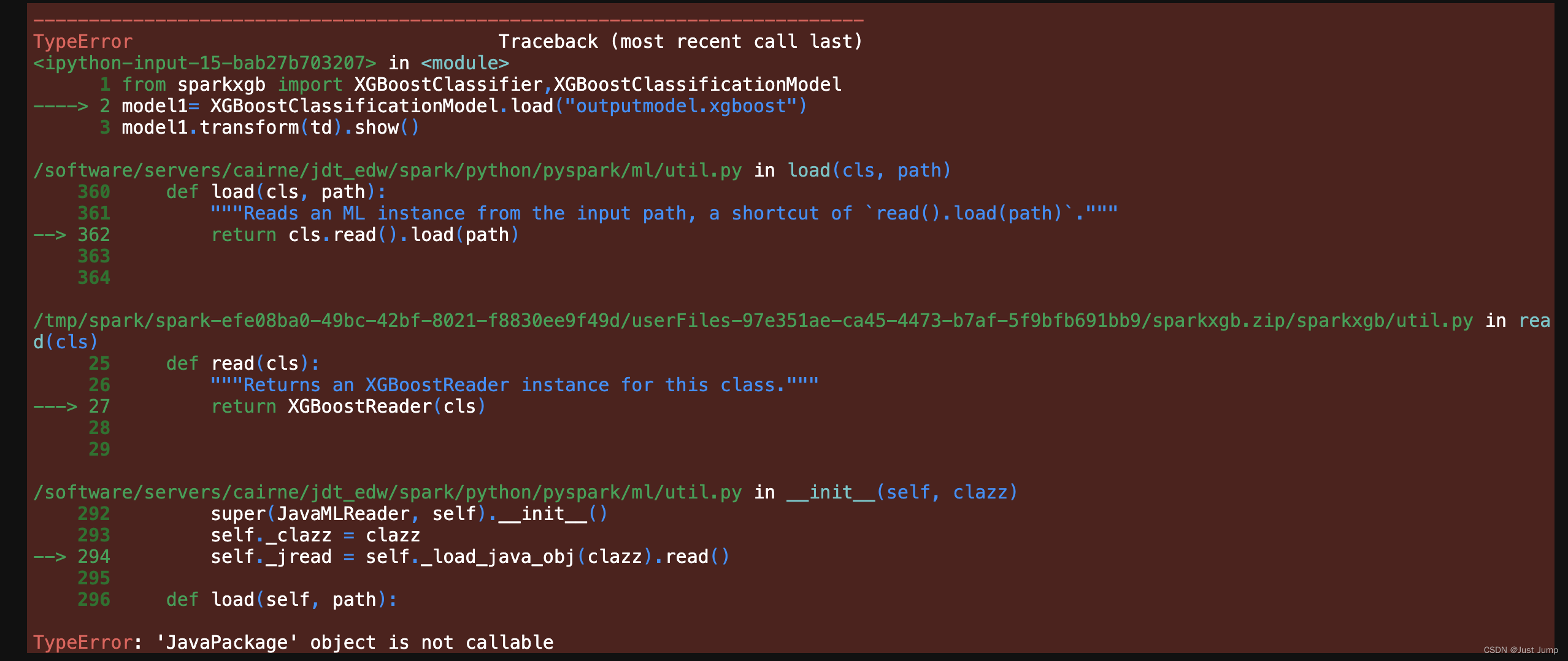
from sparkxgb import XGBoostClassifier,XGBoostClassificationModel
model1= XGBoostClassificationModel.load("outputmodel.xgboost")
model1.transform(td).show()这是运行结果:
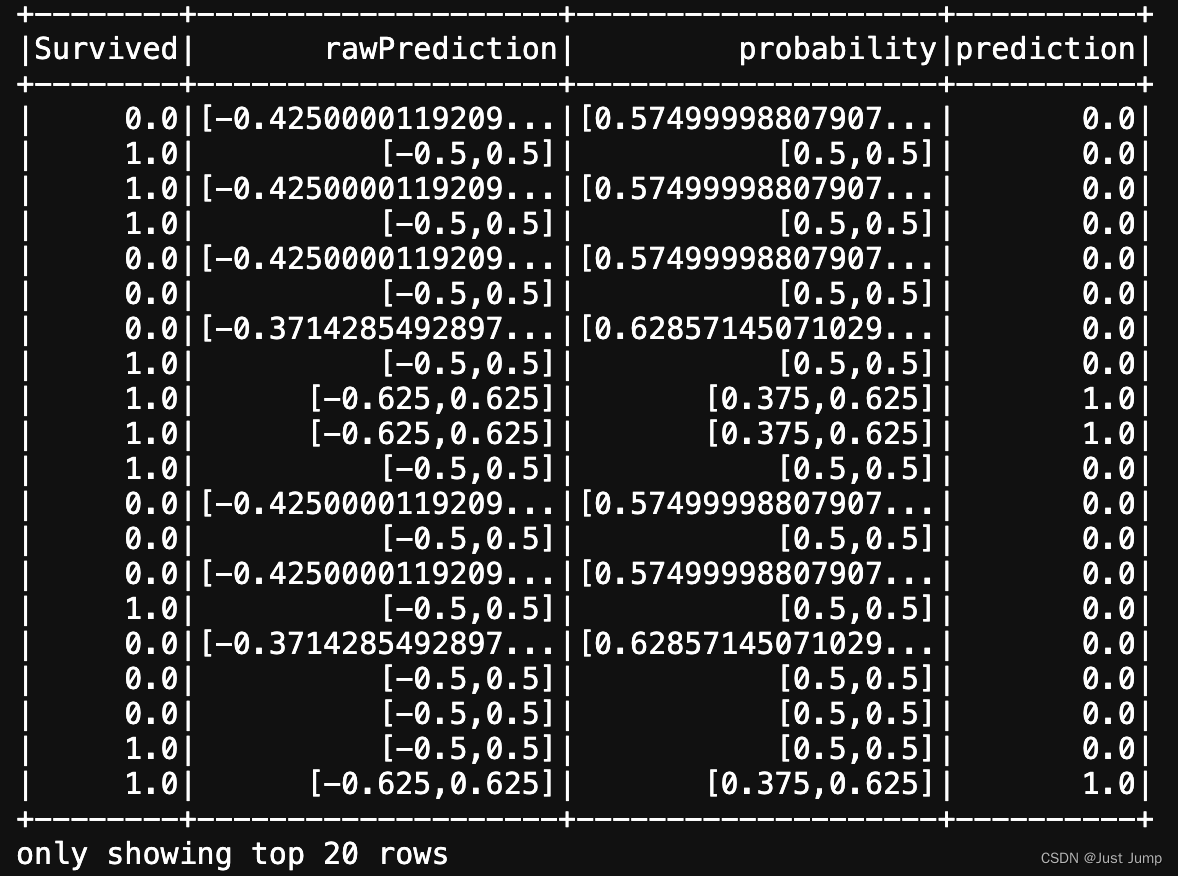
这里报错,无法使用 XGBoostClassificationModel加载已经训练好的XGB模型。