Redis面试题-2
10、统计高并发网站每个网页每天的 UV 数据,结合Redis你会如何实现?
选用方案:HyperLogLog
如果统计 PV 那非常好办,给每个网页一个独立的 Redis 计数器就可以了,这个计数器的 key 后缀加上当天的日期。这样来一个请求,incrby 一次,最终就可以统计出所有的 PV 数据。
但是 UV 不一样,它要去重,同一个用户一天之内的多次访问请求只能计数一次。这就要求每一个网页请求都需要带上用户的 ID,无论是登陆用户还是未登陆用户都需要一个唯一 ID 来标识。
一个简单的方案,那就是为每一个页面一个独立的 set 集合来存储所有当天访问过此页面的用户 ID。当一个请求过来时,我们使用 sadd 将用户 ID 塞进去就可以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面的 UV 数据。
但是,如果你的页面访问量非常大,比如一个爆款页面几千万的 UV,你需要一个很大的 set集合来统计,这就非常浪费空间。如果这样的页面很多,那所需要的存储空间是惊人的。为这样一个去重功能就耗费这样多的存储空间,值得么?其实需要的数据又不需要太精确,105w 和 106w 这两个数字对于老板们来说并没有多大区别,So,有没有更好的解决方案呢?
这就是HyperLogLog的用武之地,Redis 提供了 HyperLogLog 数据结构就是用来解决这种统计问题的。HyperLogLog 提供不精确的去重计数方案,虽然不精确但是也不是非常不精确,Redis官方给出标准误差是0.81%,这样的精确度已经可以满足上面的UV 统计需求了。
HyperLogLog与集合方案对比
百万级用户访问网站

HyperLogLog使用
操作命令
HyperLogLog提供了3个命令: pfadd、pfcount、pfmerge。
pfadd
pfadd key element [element …]
pfadd用于向HyperLogLog 添加元素,如果添加成功返回1:
pfadd u-9-30 u1 u2 u3 u4 u5 u6 u7 u8

pfcount
pfcount key [key …]
pfcount用于计算一个或多个HyperLogLog的独立总数,例如u-9-30 的独立总数为8:

如果此时向插入一些用户,用户并且有重复

如果我们继续往里面插入数据,比如插入100万条用户记录。内存增加非常少,但是pfcount 的统计结果会出现误差。
pfmerge
pfmerge destkey sourcekey [sourcekey … ]
pfmerge可以求出多个HyperLogLog的并集并赋值给destkey,请自行测试。
可以看到,HyperLogLog内存占用量小得惊人,但是用如此小空间来估算如此巨大的数据,必然不是100%的正确,其中一定存在误差率。前面说过,Redis官方给出的数字是0.81%的失误率。
HyperLogLog原理概述
基本原理
HyperLogLog基于概率论中伯努利试验并结合了极大似然估算方法,并做了分桶优化。
实际上目前还没有发现更好的在大数据场景中准确计算基数的高效算法,因此在不追求绝对准确的情况下,使用概率算法算是一个不错的解决方案。概率算法不直接存储数据集合本身,通过一定的概率统计方法预估值,这种方法可以大大节省内存,同时保证误差控制在一定范围内。目前用于基数计数的概率算法包括:
举个例子来理解HyperLogLog
算法,有一天李瑾老师和马老师玩打赌的游戏。
规则如下: 抛硬币的游戏,每次抛的硬币可能正面,可能反面,没回合一直抛,直到每当抛到正面回合结束。
然后我跟马老师说,抛到正面最长的回合用到了7次,你来猜一猜,我用到了多少个回合做到的?
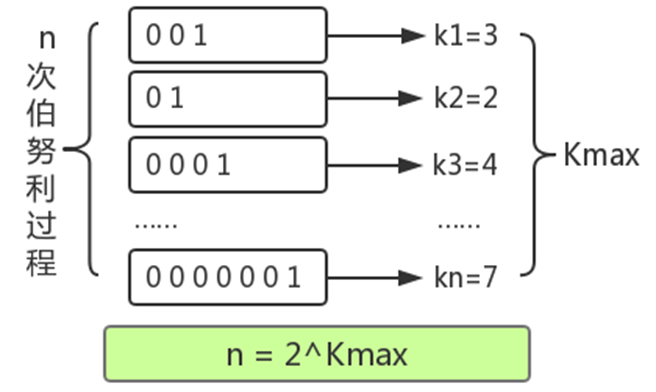
进行了n次实验,比如上图:
第一次试验: 抛了3次才出现正面,此时 k=3,n=1
第二次试验: 抛了2次才出现正面,此时 k=2,n=2
第三次试验: 抛了4次才出现正面,此时 k=4,n=3
…………
第n 次试验:抛了7次才出现正面,此时我们估算,k=7
马老师说大概你抛了128个回合。这个是怎么算的。
k是每回合抛到1所用的次数,我们已知的是最大的k值,可以用kmax表示。由于每次抛硬币的结果只有0和1两种情况,因此,能够推测出kmax在任意回合出现的概率 ,并由kmax结合极大似然估算的方法推测出n的次数n =
2^(k_max) 。概率学把这种问题叫做伯努利实验。
但是问题是,这种本身就是概率的问题,我跟马老师说,我只用到12次,并且有视频为证。
所以这种预估方法存在较大误差,为了改善误差情况,HLL中引入分桶平均的概念。
同样举抛硬币的例子,如果只有一组抛硬币实验,显然根据公式推导得到的实验次数的估计误差较大;如果100个组同时进行抛硬币实验,受运气影响的概率就很低了,每组分别进行多次抛硬币实验,并上报各自实验过程中抛到正面的抛掷次数的最大值,就能根据100组的平均值预估整体的实验次数了。
分桶平均的基本原理是将统计数据划分为m个桶,每个桶分别统计各自的kmax,并能得到各自的基数预估值,最终对这些基数预估值求平均得到整体的基数估计值。LLC中使用几何平均数预估整体的基数值,但是当统计数据量较小时误差较大;HLL在LLC基础上做了改进,采用调和平均数过滤掉不健康的统计值。
什么叫调和平均数呢?举个例子
求平均工资:A的是1000/月,B的30000/月。采用平均数的方式就是:
(1000 + 30000) / 2 = 15500
采用调和平均数的方式就是:
2/(1/1000 + 1/30000) ≈ 1935.484
可见调和平均数比平均数的好处就是不容易受到大的数值的影响,比平均数的效果是要更好的。
结合Redis的实现理解原理
现在我们和前面的业务场景进行挂钩:统计网页每天的 UV 数据。
从前面的知识我们知道,伯努利实验就是如果是出现1的时机越晚,就说明你要做更多的实验,这个就好比你要中500万的双色球,你大概要买2000万张不同的彩票(去重),而如果是换成 二进制来算,可能是 第几十次才出现1。而你买一个中奖只有500块的排列3(3个10进制数),而如果是换成 二进制来算,你只需要10次左右出现1。
1.转为比特串
这里很重要的一点:hash函数,可以把不同的数据转成尽量不重复的数据,这点就有点像去重。
如果是64位的二进制,是不是hash函数可以把 2的64次方个不同的数据转成不一样的二进制。这里就跟放入了2的64次方个元素一样。
那么基于上面的估算结论,我们可以通过多次抛硬币实验的最大抛到正面的次数来预估总共进行了多少次实验(多少个不同的数据),同样存储的时候也可以优化,每次add一个元素时,只要算法最后出现1的位数,把这个位数做一个最大的替换久可以。(如果添加的元素比 记录之前位数小则不记录,只要大才记录)
2.分桶
分桶就是分多少轮。抽象到计算机存储中去,就是存储的是一个以单位是比特(bit),长度为 L 的大数组 S ,将 S 平均分为 m 组,注意这个 m 组,就是对应多少轮,然后每组所占有的比特个数是平均的,设为 P。容易得出下面的关系:
比如有4个桶的话,那么可以截取低2位作为分桶的依据。
比如
10010000 进入0号桶
10010001 进入1号桶
10010010 进入2号桶
10010011 进入3号桶
Redis 中的 HyperLogLog 实现
pfadd

当我们执行这个操作时,lijin这个字符串就会被转化成64个bit的二进制比特串。
这里很重要的一点:hash函数,可以把不同的数据转成尽量不重复的数据,这点就有点像去重。
如果是64位的二进制,是不是hash函数可以把 2的64次方个不同的数据转成不一样的二进制。这里就跟放入了2的64次方个元素一样。
那么基于上面的估算结论,我们可以通过多次抛硬币实验的最大抛到正面的次数来预估总共进行了多少次实验(多少个不同的数据),同样存储的时候也可以优化,每次add一个元素时,只要算法最后出现1的位数,把这个位数做一个最大的替换久可以。(如果添加的元素比 记录之前位数小则不记录,只要大才记录)
0010…0001 64位
然后在Redis中要分到16384个桶中(为什么是这么多桶:第一降低误判,第二,用到了14位二进制:2的14次方=16384)
怎么分?根据得到的比特串的后14位来做判断即可。

根据上述的规则,我们知道这个数据要分到 1号桶,同时从左往右(低位到高位)计算第1个出现的1的位置,这里是第4位,那么就往这个1号桶插入4的数据(转成二进制)
如果有第二个数据来了,按照上述的规则进行计算。
那么问题来了,如果分到桶的数据有重复了(这里比大小,大的替换小的):
规则如下,比大小(比出现位置的大小),比如有个数据是最高位才出现1,那么这个位置算出来就是50,50比4大,则进行替换。1号桶的数据就变成了50(二进制是110010)
所以这里可以看到,每个桶的数据一般情况下6位存储即可。
所以我们这里可以推算一下一个key的HyperLogLog只占据多少的存储。
16384*6 /8/1024=12k。并且这里最多可以存储多少数据,因为是64位吗,所以就是2的64次方的数据,这个存储的数据非常非常大的,一般用户用long来定义,最大值也只有这么多。
pfcount
进行统计的时候,就是把16384桶,把每个桶的值拿出来,比如取出是 n,那么访问次数(里面)就是2的n次方。

然后把每个桶的值做调和平均数,就可以算出一个算法值。
同时,在具体的算法实现上,HLL还有一个分阶段偏差修正算法。我们就不做更深入的了解了。
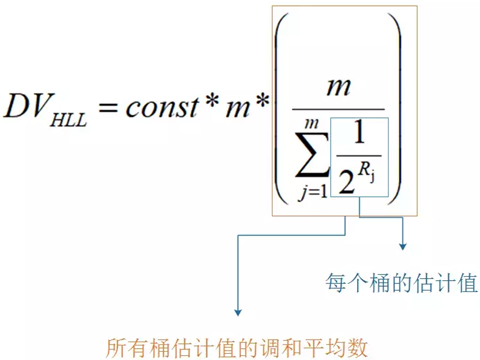
const和m都是Redis里面根据数据做的调和平均数。
11、说一说Redis的Key和Value的数据结构组织?
全局哈希表
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。一个哈希表,其实就是一个数组,数组的每个元素称为一个哈希桶。所以,我们常说,一个哈希表是由多个哈希桶组成的,每个哈希桶中保存了键值对数据。
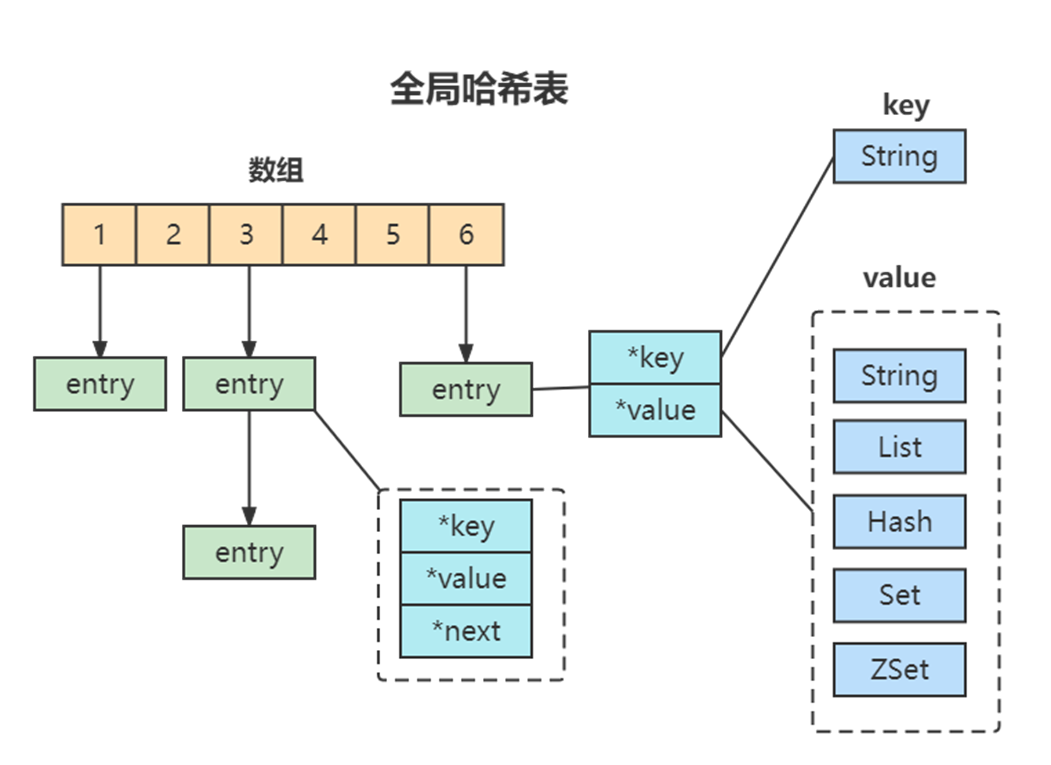
哈希桶中的 entry 元素中保存了key和value指针,分别指向了实际的键和值,这样一来,即使值是一个集合,也可以通过*value指针被查找到。因为这个哈希表保存了所有的键值对,所以,我也把它称为全局哈希表。
哈希表的最大好处很明显,就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对:我们只需要计算键的哈希值,就可以知道它所对应的哈希桶位置,然后就可以访问相应的 entry 元素。
但当你往 Redis 中写入大量数据后,就可能发现操作有时候会突然变慢了。这其实是因为你忽略了一个潜在
的风险点,那就是哈希表的冲突问题和 rehash 可能带来的操作阻塞。
当你往哈希表中写入更多数据时,哈希冲突是不可避免的问题。这里的哈希冲突,两个 key 的哈希值和哈希桶计算对应关系时,正好落在了同一个哈希桶中。
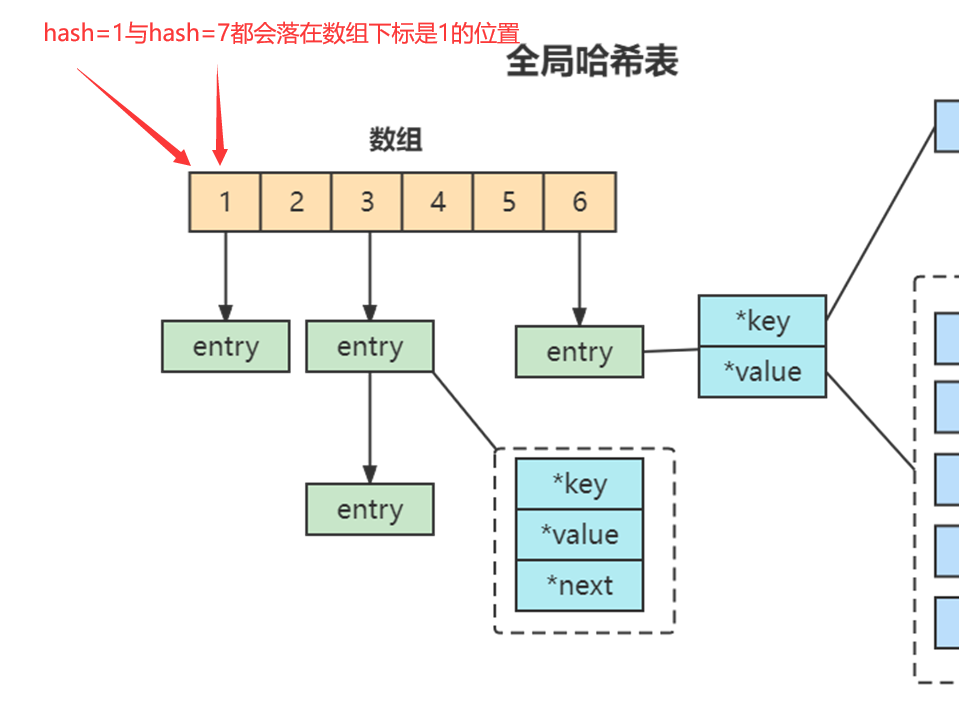
Redis 解决哈希冲突的方式,就是链式哈希。链式哈希也很容易理解,就是指同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
12、渐进式rehash听过没?讲一讲!
Redis是当然如果这个数组一直不变,那么hash冲突会变很多,这个时候检索效率会大打折扣,所以Redis就需要把数组进行扩容(一般是扩大到原来的两倍),但是问题来了,扩容后每个hash桶的数据会分散到不同的位置,这里设计到元素的移动,必定会阻塞IO,所以这个ReHash过程会导致很多请求阻塞。
渐进式rehash
为了避免这个问题,Redis 采用了渐进式 rehash。
首先、Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash。
1、给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍
2、把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中
3、释放哈希表 1 的空间
在上面的第二步涉及大量的数据拷贝,如果一次性把哈希表 1 中的数据都迁移完,会造成 Redis 线程阻塞,无法服务其他请求。此时,Redis 就无法快速访问数据了。
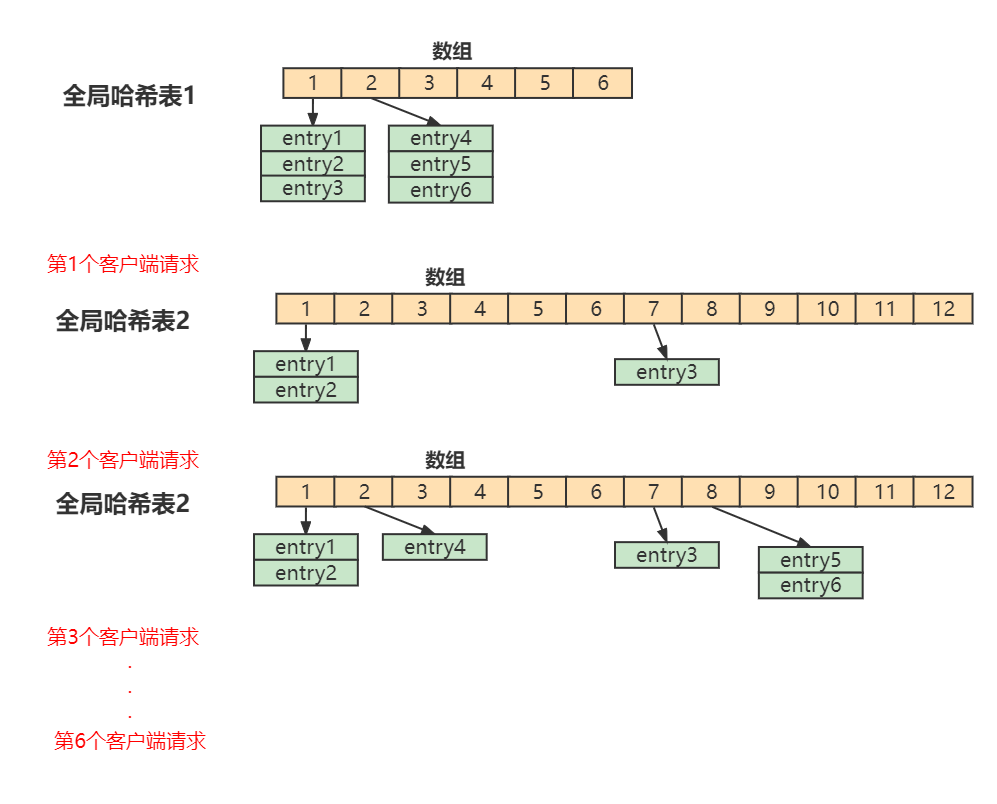
在Redis 开始执行 rehash,Redis仍然正常处理客户端请求,但是要加入一个额外的处理:
处理第1个请求时,把哈希表 1中的第1个索引位置上的所有 entries 拷贝到哈希表 2 中
处理第2个请求时,把哈希表 1中的第2个索引位置上的所有 entries 拷贝到哈希表 2 中
如此循环,直到把所有的索引位置的数据都拷贝到哈希表 2 中。
这样就巧妙地把一次性大量拷贝的开销,分摊到了多次处理请求的过程中,避免了耗时操作,保证了数据的快速访问。
所以这里基本上也可以确保根据key找value的操作在O(1)左右。
13、讲一讲Redis分布式锁的实现
Redis分布式锁最简单的实现
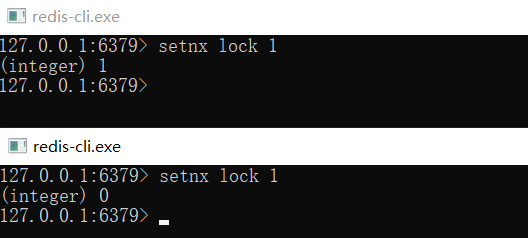
想要实现分布式锁,必须要求 Redis 有「互斥」的能力,我们可以使用 SETNX 命令,这个命令表示SET if Not Exists,即如果 key 不存在,才会设置它的值,否则什么也不做。
两个客户端进程可以执行这个命令,达到互斥,就可以实现一个分布式锁。
客户端 1 申请加锁,加锁成功:
客户端 2 申请加锁,因为它后到达,加锁失败:
此时,加锁成功的客户端,就可以去操作「共享资源」,例如,修改 MySQL 的某一行数据,或者调用一个 API 请求。
操作完成后,还要及时释放锁,给后来者让出操作共享资源的机会。如何释放锁呢?
也很简单,直接使用 DEL 命令删除这个 key 即可,这个逻辑非常简单。
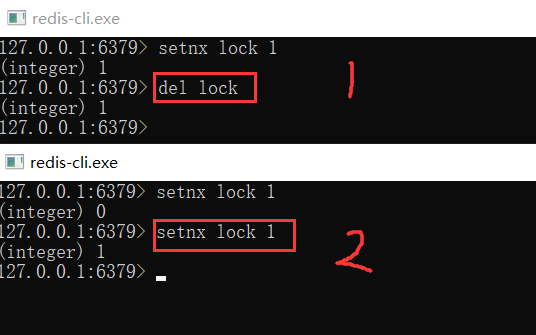
但是,它存在一个很大的问题,当客户端 1 拿到锁后,如果发生下面的场景,就会造成「死锁」:
1、程序处理业务逻辑异常,没及时释放锁
2、进程挂了,没机会释放锁
这时,这个客户端就会一直占用这个锁,而其它客户端就「永远」拿不到这把锁了。怎么解决这个问题呢?
如何避免死锁?
我们很容易想到的方案是,在申请锁时,给这把锁设置一个「租期」。
在 Redis 中实现时,就是给这个 key 设置一个「过期时间」。这里我们假设,操作共享资源的时间不会超过 10s,那么在加锁时,给这个 key 设置 10s 过期即可:
SETNX lock 1 // 加锁
EXPIRE lock 10 // 10s后自动过期

这样一来,无论客户端是否异常,这个锁都可以在 10s 后被「自动释放」,其它客户端依旧可以拿到锁。
但现在还是有问题:
现在的操作,加锁、设置过期是 2 条命令,有没有可能只执行了第一条,第二条却「来不及」执行的情况发生呢?例如:
- SETNX 执行成功,执行EXPIRE 时由于网络问题,执行失败
- SETNX 执行成功,Redis 异常宕机,EXPIRE 没有机会执行
- SETNX 执行成功,客户端异常崩溃,EXPIRE也没有机会执行
总之,这两条命令不能保证是原子操作(一起成功),就有潜在的风险导致过期时间设置失败,依旧发生「死锁」问题。
在 Redis 2.6.12 之后,Redis 扩展了 SET 命令的参数,用这一条命令就可以了:
SET lock 1 EX 10 NX

锁被别人释放怎么办?
上面的命令执行时,每个客户端在释放锁时,都是「无脑」操作,并没有检查这把锁是否还「归自己持有」,所以就会发生释放别人锁的风险,这样的解锁流程,很不「严谨」!如何解决这个问题呢?
解决办法是:客户端在加锁时,设置一个只有自己知道的「唯一标识」进去。
例如,可以是自己的线程 ID,也可以是一个 UUID(随机且唯一),这里我们以UUID 举例:
SET lock $uuid EX 20 NX
之后,在释放锁时,要先判断这把锁是否还归自己持有,伪代码可以这么写:
if redis.get("lock") == $uuid:redis.del("lock")
这里释放锁使用的是 GET + DEL 两条命令,这时,又会遇到我们前面讲的原子性问题了。这里可以使用lua脚本来解决。
安全释放锁的 Lua 脚本如下:
if redis.call("GET",KEYS[1]) == ARGV[1]
thenreturn redis.call("DEL",KEYS[1])
elsereturn 0
end
好了,这样一路优化,整个的加锁、解锁的流程就更「严谨」了。
这里我们先小结一下,基于 Redis 实现的分布式锁,一个严谨的的流程如下:
1、加锁
SET lock_key $unique_id EX $expire_time NX
2、操作共享资源
3、释放锁:Lua 脚本,先 GET 判断锁是否归属自己,再DEL 释放锁
Java代码实现分布式锁
package com.msb.redis.lock;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.params.SetParams;import java.util.Arrays;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;/*** 分布式锁的实现*/
@Component
public class RedisDistLock implements Lock {private final static int LOCK_TIME = 5*1000;private final static String RS_DISTLOCK_NS = "tdln:";/*if redis.call('get',KEYS[1])==ARGV[1] thenreturn redis.call('del', KEYS[1])else return 0 end*/private final static String RELEASE_LOCK_LUA ="if redis.call('get',KEYS[1])==ARGV[1] then\n" +" return redis.call('del', KEYS[1])\n" +" else return 0 end";/*保存每个线程的独有的ID值*/private ThreadLocal<String> lockerId = new ThreadLocal<>();/*解决锁的重入*/private Thread ownerThread;private String lockName = "lock";@Autowiredprivate JedisPool jedisPool;public String getLockName() {return lockName;}public void setLockName(String lockName) {this.lockName = lockName;}public Thread getOwnerThread() {return ownerThread;}public void setOwnerThread(Thread ownerThread) {this.ownerThread = ownerThread;}@Overridepublic void lock() {while(!tryLock()){try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}}}@Overridepublic void lockInterruptibly() throws InterruptedException {throw new UnsupportedOperationException("不支持可中断获取锁!");}@Overridepublic boolean tryLock() {Thread t = Thread.currentThread();if(ownerThread==t){/*说明本线程持有锁*/return true;}else if(ownerThread!=null){/*本进程里有其他线程持有分布式锁*/return false;}Jedis jedis = null;try {String id = UUID.randomUUID().toString();SetParams params = new SetParams();params.px(LOCK_TIME);params.nx();synchronized (this){/*线程们,本地抢锁*/if((ownerThread==null)&&"OK".equals(jedis.set(RS_DISTLOCK_NS+lockName,id,params))){lockerId.set(id);setOwnerThread(t);return true;}else{return false;}}} catch (Exception e) {throw new RuntimeException("分布式锁尝试加锁失败!");} finally {jedis.close();}}@Overridepublic boolean tryLock(long time, TimeUnit unit) throws InterruptedException {throw new UnsupportedOperationException("不支持等待尝试获取锁!");}@Overridepublic void unlock() {if(ownerThread!=Thread.currentThread()) {throw new RuntimeException("试图释放无所有权的锁!");}Jedis jedis = null;try {jedis = jedisPool.getResource();Long result = (Long)jedis.eval(RELEASE_LOCK_LUA,Arrays.asList(RS_DISTLOCK_NS+lockName),Arrays.asList(lockerId.get()));if(result.longValue()!=0L){System.out.println("Redis上的锁已释放!");}else{System.out.println("Redis上的锁释放失败!");}} catch (Exception e) {throw new RuntimeException("释放锁失败!",e);} finally {if(jedis!=null) jedis.close();lockerId.remove();setOwnerThread(null);System.out.println("本地锁所有权已释放!");}}@Overridepublic Condition newCondition() {throw new UnsupportedOperationException("不支持等待通知操作!");}}锁过期时间不好评估怎么办?
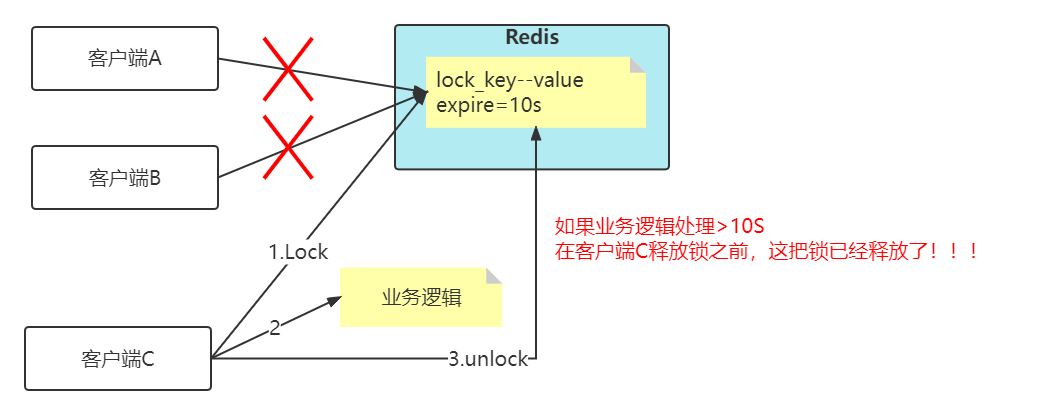
看上面这张图,加入key的失效时间是10s,但是客户端C在拿到分布式锁之后,然后业务逻辑执行超过10s,那么问题来了,在客户端C释放锁之前,其实这把锁已经失效了,那么客户端A和客户端B都可以去拿锁,这样就已经失去了分布式锁的功能了!!!
比较简单的妥协方案是,尽量「冗余」过期时间,降低锁提前过期的概率,但是这个并不能完美解决问题,那怎么办呢?
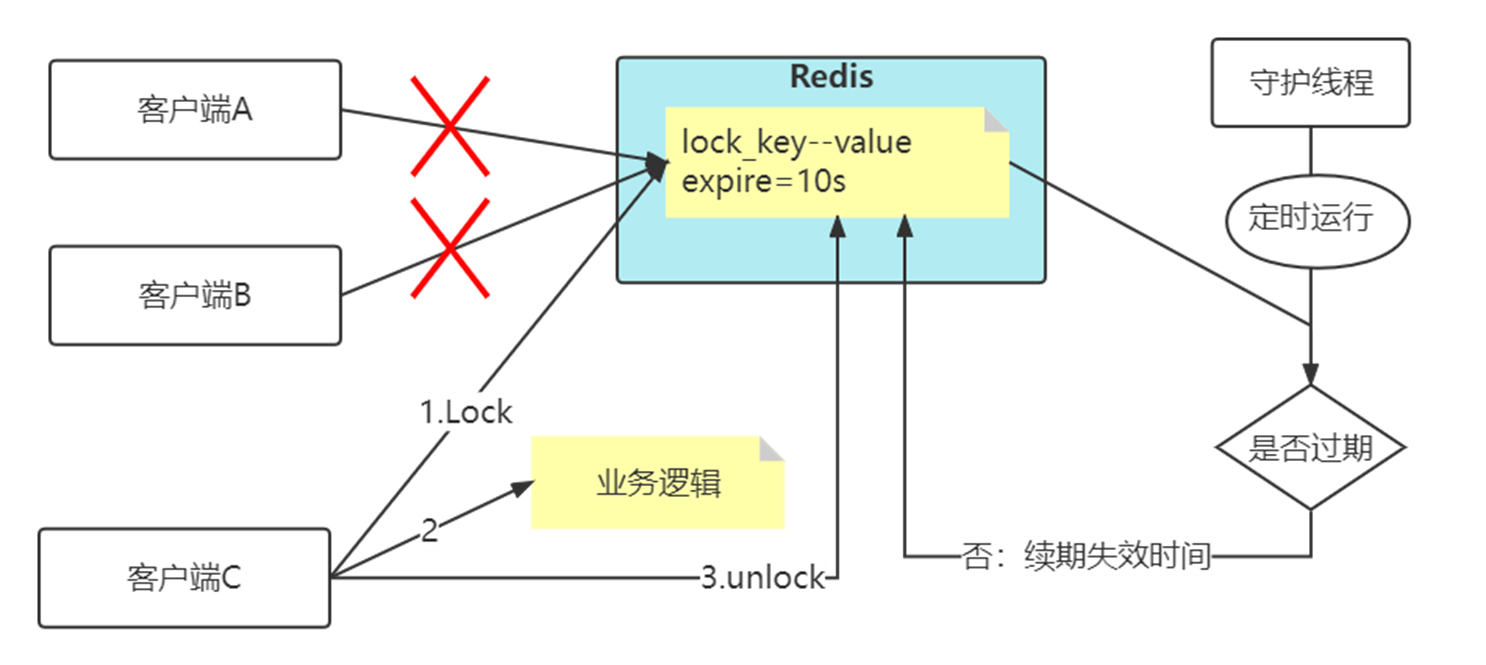
分布式锁加入看门狗
加锁时,先设置一个过期时间,然后我们开启一个「守护线程」,定时去检测这个锁的失效时间,如果锁快要过期了,操作共享资源还未完成,那么就自动对锁进行「续期」,重新设置过期时间。
这个守护线程我们一般也把它叫做「看门狗」线程。
为什么要使用守护线程:
分布式锁加入看门狗代码实现

运行效果:

Redisson中的分布式锁
Redisson把这些工作都封装好了
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.12.3</version></dependency>
package com.msb.redis.config;import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class MyRedissonConfig {/*** 所有对Redisson的使用都是通过RedissonClient*/@Bean(destroyMethod="shutdown")public RedissonClient redisson(){//1、创建配置Config config = new Config();config.useSingleServer().setAddress("redis://127.0.0.1:6379");//2、根据Config创建出RedissonClient实例RedissonClient redisson = Redisson.create(config);return redisson;}
}package com.msb.redis.redisbase.adv;import com.msb.redis.lock.rdl.RedisDistLockWithDog;
import org.junit.jupiter.api.Test;
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;@SpringBootTest
public class TestRedissionLock {private int count = 0;@Autowiredprivate RedissonClient redisson;@Testpublic void testLockWithDog() throws InterruptedException {int clientCount =3;RLock lock = redisson.getLock("RD-lock");CountDownLatch countDownLatch = new CountDownLatch(clientCount);ExecutorService executorService = Executors.newFixedThreadPool(clientCount);for (int i = 0;i<clientCount;i++){executorService.execute(() -> {try {lock.lock(10, TimeUnit.SECONDS);System.out.println(Thread.currentThread().getName()+"准备进行累加。");Thread.sleep(2000);count++;} catch (InterruptedException e) {e.printStackTrace();} finally {lock.unlock();}countDownLatch.countDown();});}countDownLatch.await();System.out.println(count);}
}https://github.com/redisson/redisson/
https://redisson.org/
锁过期时间不好评估怎么办?
14、Redlock听过没?讲一讲!
Redis 作者提出的 Redlock方案,是如何解决主从切换后,锁失效问题的。
Redlock 的方案基于一个前提:
不再需要部署从库和哨兵实例,只部署主库;但主库要部署多个,官方推荐至少 5 个实例。
注意:不是部署 Redis Cluster,就是部署 5 个简单的 Redis 实例。它们之间没有任何关系,都是一个个孤立的实例。
做完之后,我们看官网代码怎么去用的:
8. 分布式锁和同步器 · redisson/redisson Wiki · GitHub
8.4. 红锁(RedLock)
基于Redis的Redisson红锁 RedissonRedLock对象实现了Redlock介绍的加锁算法。该对象也可以用来将多个 RLock对象关联为一个红锁,每个 RLock对象实例可以来自于不同的Redisson实例。
RLock lock1 = redissonInstance1.getLock("lock1");
RLock lock2 = redissonInstance2.getLock("lock2");
RLock lock3 = redissonInstance3.getLock("lock3");RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);
// 同时加锁:lock1 lock2 lock3
// 红锁在大部分节点上加锁成功就算成功。
lock.lock();
...
lock.unlock();
大家都知道,如果负责储存某些分布式锁的某些Redis节点宕机以后,而且这些锁正好处于锁住的状态时,这些锁会出现锁死的状态。为了避免这种情况的发生,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期。默认情况下,看门狗的检查锁的超时时间是30秒钟,也可以通过修改Config.lockWatchdogTimeout来另行指定。
另外Redisson还通过加锁的方法提供了 leaseTime的参数来指定加锁的时间。超过这个时间后锁便自动解开了。
RedissonRedLock lock = new RedissonRedLock(lock1, lock2, lock3);
// 给lock1,lock2,lock3加锁,如果没有手动解开的话,10秒钟后将会自动解开
lock.lock(10, TimeUnit.SECONDS);// 为加锁等待100秒时间,并在加锁成功10秒钟后自动解开
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
...
lock.unlock();
Redlock实现整体流程
1、客户端先获取「当前时间戳T1」
2、客户端依次向这 5 个 Redis 实例发起加锁请求
3、如果客户端从 >=3 个(大多数)以上Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败。
4、加锁成功,去操作共享资源
5、加锁失败/释放锁,向「全部节点」发起释放锁请求。
所以总的来说:客户端在多个 Redis 实例上申请加锁;必须保证大多数节点加锁成功;大多数节点加锁的总耗时,要小于锁设置的过期时间;释放锁,要向全部节点发起释放锁请求。
我们来看 Redlock 为什么要这么做?
- 为什么要在多个实例上加锁?
本质上是为了「容错」,部分实例异常宕机,剩余的实例加锁成功,整个锁服务依旧可用。
- 为什么大多数加锁成功,才算成功?
多个 Redis 实例一起来用,其实就组成了一个「分布式系统」。在分布式系统中,总会出现「异常节点」,所以,在谈论分布式系统问题时,需要考虑异常节点达到多少个,也依旧不会影响整个系统的「正确性」。
这是一个分布式系统「容错」问题,这个问题的结论是:如果只存在「故障」节点,只要大多数节点正常,那么整个系统依旧是可以提供正确服务的。
- 为什么步骤 3 加锁成功后,还要计算加锁的累计耗时?
因为操作的是多个节点,所以耗时肯定会比操作单个实例耗时更久,而且,因为是网络请求,网络情况是复杂的,有可能存在延迟、丢包、超时等情况发生,网络请求越多,异常发生的概率就越大。
所以,即使大多数节点加锁成功,但如果加锁的累计耗时已经「超过」了锁的过期时间,那此时有些实例上的锁可能已经失效了,这个锁就没有意义了。
- 为什么释放锁,要操作所有节点?
在某一个 Redis 节点加锁时,可能因为「网络原因」导致加锁失败。
例如,客户端在一个 Redis 实例上加锁成功,但在读取响应结果时,网络问题导致读取失败,那这把锁其实已经在 Redis 上加锁成功了。
所以,释放锁时,不管之前有没有加锁成功,需要释放「所有节点」的锁,以保证清理节点上「残留」的锁。
好了,明白了 Redlock 的流程和相关问题,看似Redlock 确实解决了 Redis 节点异常宕机锁失效的问题,保证了锁的「安全性」。
但事实真的如此吗?
RedLock的是是非非
一个分布式系统,更像一个复杂的「野兽」,存在着你想不到的各种异常情况。
这些异常场景主要包括三大块,这也是分布式系统会遇到的三座大山:NPC。
N:Network Delay,网络延迟
P:Process Pause,进程暂停(GC)
C:Clock Drift,时钟漂移
比如一个进程暂停(GC)的例子
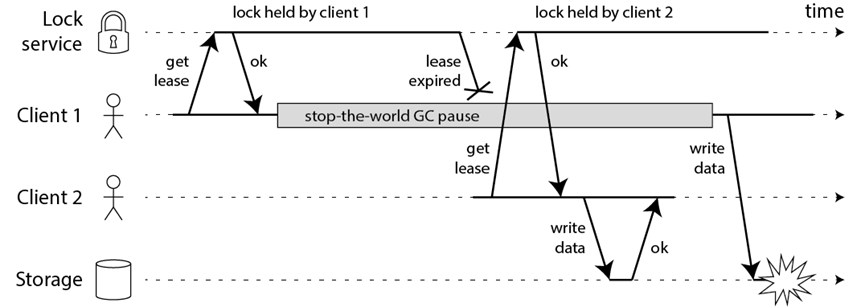
1)客户端 1 请求锁定节点 A、B、C、D、E
2)客户端 1 的拿到锁后,进入 GC(时间比较久)
3)所有 Redis 节点上的锁都过期了
4)客户端 2 获取到了 A、B、C、D、E 上的锁
5)客户端 1 GC 结束,认为成功获取锁
6)客户端 2 也认为获取到了锁,发生「冲突」
GC 和网络延迟问题:这两点可以在红锁实现流程的第3步来解决这个问题。
但是最核心的还是时钟漂移,因为时钟漂移,就有可能导致第3步的判断本身就是一个BUG,所以当多个 Redis 节点「时钟」发生问题时,也会导致 Redlock 锁失效。
RedLock总结
Redlock 只有建立在「时钟正确」的前提下,才能正常工作,如果你可以保证这个前提,那么可以拿来使用。
但是时钟偏移在现实中是存在的:
第一,从硬件角度来说,时钟发生偏移是时有发生,无法避免。例如,CPU 温度、机器负载、芯片材料都是有可能导致时钟发生偏移的。
第二,人为错误也是很难完全避免的。
所以,Redlock尽量不用它,而且它的性能不如单机版 Redis,部署成本也高,优先考虑使用主从+ 哨兵的模式
实现分布式锁(只会有很小的记录发生主从切换时的锁丢失问题)。