论文阅读
题目:Last-Mile Embodied Visual Navigation
作者:JustinWasserman, Karmesh Yadav
来源:CoRL
时间:2023
代码地址:https://jbwasse2.github.io/portfolio/SLING
Abstract
现实的长期任务(例如图像目标导航)涉及探索和利用阶段。
分配有目标图像后,具体代理必须探索以发现目标,即使用学习到的先验进行有效搜索。一旦发现目标,代理必须准确校准到目标的最后一英里导航。与任何强大的系统一样,探索性目标发现和利用性最后一英里导航之间的切换可以更好地从错误中恢复。
遵循这些直观的导轨,我们提出 SLING 来提高现有图像目标导航系统的性能。完全补充现有方法,我们专注于最后一英里导航,并通过神经描述符利用问题的底层几何结构。通过简单但有效的开关,我们可以轻松地将 SLING 与启发式、强化学习和神经模块化策略连接起来。
在标准化图像目标导航基准 [1] 上,我们提高了策略、场景和情节复杂性的性能,将最先进的成功率从 45% 提高到 55%。
Introduction
我们将导航到可见对象或区域的后一个问题称为最后一英里导航。
最后一英里导航的非结构化本地策略要么是
(a)样本效率低下(强化学习框架中的数十亿帧[11]),要么是
(b)在从离线演示中学习时存在偏差且泛化能力较差(由于分布式)移位 [12, 13])
我们的主要贡献是:
(1)通用的最后一英里导航系统和开关,我们将其与五种不同的目标发现方法连接起来,从而实现全面改进。
(2) 在最广泛测试的折叠上,新的最先进技术取得了 54.8% 的成功,即与已发表的作品相比大幅跃升了 21.8% [5],与并发预印本相比跃升了 9.2%(Gibson -curved)AI Habitat 图像目标导航基准 ;
(3) 在具有挑战性的环境中进行广泛的图像目标导航机器人实验,其性能优于在真实世界数据 [14] 上训练的神经模块化策略 [1]。
Related Work
Embodied navigation
Anderson 等人 [15] 正式提出了评估具体代理的不同目标定义和指标。
在点目标导航中,目标的相对坐标是可用的(在所有步骤 [16,11,17,18,19] 或仅在剧集开始时 [9,20,21])。成功导航到点目标可以在没有语义场景理解的情况下完成,正如竞争性的仅深度代理所看到的那样 [16, 11]。语义导航需要通过图像(图像目标 [1, 2, 22])、声音提示(音频目标 [23, 24])或类别标签(对象目标 [8, 9])来识别目标。
导航的几个扩展包括语言条件导航[25,26,27,28],社交导航[29,30,31,32,33]和多代理任务[34,35,36,37,38] 39]。然而,这些都建立在单代理导航的基础上,并受益于相关的进步。对于更具体的任务和范例,我们建议读者参考最近的一项调查[40]。在这项工作中,我们专注于视觉丰富的环境中的图像目标导航。
Image-goal navigation
Chaplot 等人 [3] 引入了一种模块化和分层的方法,用于利用拓扑图存储器导航到图像目标。 Kwon 等人 [41] 引入了一种基于图像相似性的记忆表示,该记忆表示又以无监督的方式从未标记的数据和代理观察到的图像中学习。
NRNS [1] 改进了基于拓扑图的架构,并开源了 AI Habitat 内的公共数据集以及 IL 和 RL 基线 [11, 3]。该数据集已用于标准化评估[5, 6]。
ZER [5] 专注于将图像目标导航策略转移到其他导航任务。在并发预印本中,Y adav 等人 [6] 利用自监督预训练 [42] 来改进图像目标导航基准的端到端视觉 RL 策略 [11]。
Last-mile navigation
上述作品主要关注目标发现。相比之下,最近的研究还发现了当目标在智能体的视野中或附近时发生的“最后一英里”错误。对于多目标导航,Wani 等人 [46, 47] 在允许最终“找到”或“停止”操作的错误预算时观察到了两倍的改进。 Chattopadhyay 等人 [48] 发现导航的最后一步很脆弱,即小的扰动会导致严重的故障。 Ye 等人 [10] 将最后一英里错误确定为目标-目标导航中的一个突出错误模式(占失败的 10%)。
Connections to 3D vision
我们最后一英里导航系统的目标是预测两个图像之间的相对相机姿势,即代理的视图和图像目标。为此,根据 3D 到 2D 点对应关系对校准相机进行位姿估计,将我们的具体导航任务与几何 3D 计算机视觉联系起来。
SLING
我们遵循 Hahn 等人 [1] 的图像目标导航任务基准(类似于之前的公式 [2, 3])。代理观察 RGB 图像 I a I_a Ia、深度图 D a D_a Da 和图像目标 I g I_g Ig。代理可以从 A = { m o v e f o r w a r d , t u r n r i g h t , t u r n l e f t , s t o p } A = \{move\space forward, turn\space right, turn\space left, stop\} A={move forward,turn right,turn left,stop}中采样动作。停止动作终止该情节。
如图 1a 所示,我们将图像目标导航分为目标发现和最后一英里导航阶段。
在目标发现阶段,代理负责发现目标,即导航足够近,使目标占据以自我为中心的观察的很大一部分(“发现目标”图像)。图 1b 显示了我们系统之间的控制流。如果没有触发 explore )exploit 开关,基于学习的探索将继续。否则,如果探索)利用开关触发,代理的观察现在与图像目标重叠,并且控制流到最后一英里导航系统。我们发现来自探索的单向流程(如[1, 3]中所尝试的)利用过于乐观。因此,我们引入对称开关,包括将控制流回目标发现的开关。
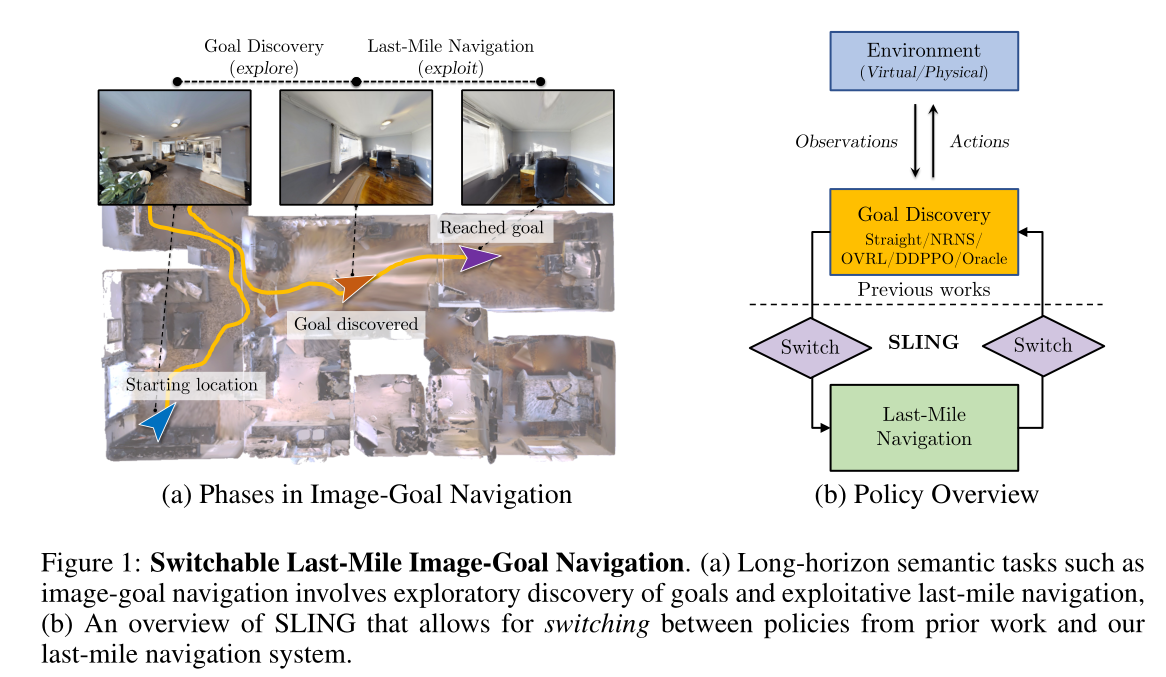
Goal Discovery
我们可以将我们的多功能最后一英里导航系统和切换机制与任何现有方法结合起来。这些现有方法是先前建议的图像目标导航解决方案。我们通过五种不同的目标发现 (GD) 实现来证明这一点
直[61]Straight 。一种简单的启发式探索,代理向前移动,如果卡住了,可以通过右转来解锁自身(类似于[61]中的有效探索基线)。
距离预测网络(Distance Prediction Network, NRNS-GD)[1]。探索性导航是通过在可导航区域中提出路径点(利用代理的深度掩模确定)来完成的,使用拓扑图维护历史记录,并使用图神经网络进行处理。利用距离预测网络的输出来选择最小成本航路点。附录 B 和 [1] 中给出了更多详细信息。
去中心化分布式 PPO(Decentralized Distributed PPO, DDPPO-GD)[11]。用于真实感模拟器的 PPO [62] 实现,其中渲染是计算瓶颈。这是之前跨任务工作中的标准端到端深度强化学习基线 [18,1,5,6,63]。
离线视觉表示学习(Offline Visual Representation Learning, OVRL-GD)[6]。 DDPPO 网络,其视觉编码器使用自监督借口任务 [42] 对从 3D 扫描 [64] 获得的图像进行预训练。
环境-状态距离预测 (Environment-State Distance Prediction, Oracle-GD)。为了量化目标发现阶段错误的影响,我们设计了一个上限。这是 NRNS-GD 的一个特权变体,可获取距环境的地面真实距离,专门用于目标发现阶段。
Last-Mile Navigation
Neural Feature Extractor:我们首先将智能体的 RGB I a I_a Ia 转换为局部特征 ( X ^ a \hat{X}_a X^a, F a F_a Fa),其中 X ^ a ∈ R n a × 2 \hat{X}_a ∈ \mathbb{R}^{n_a×2} X^a∈Rna×2 是位置, F a ∈ R n a × k F_a ∈ \mathbb{R}^{n_a×k} Fa∈Rna×k 是智能体图像中的视觉描述符。这里, n a n_a na是检测到的局部特征的数量, k k k是每个描述符的长度。
类似地, I g I_g Ig 导致特征 ( X ^ g \hat{X}_g X^g, F g F_g Fg),其中 X ^ g ∈ R n g × 2 \hat{X}_g ∈ \mathbb{R}^{n_g×2} X^g∈Rng×2 且 F g ∈ R n g × k F_g ∈ \mathbb{R}^{n_g×k} Fg∈Rng×k,图像目标中具有 n g n_g ng 局部特征。
继 DeTone 等人[65]之后,我们采用兴趣点检测器,对合成数据进行预训练,然后进行跨域单应性适应(此处,k = 256)。
Matching Module:根据提取的特征 ( X ^ a \hat{X}_a X^a, F a F_a Fa) 和( X ^ g \hat{X}_g X^g, F g F_g Fg),我们预测匹配的子集 X ^ a ∈ R n a × 2 \hat{X}_a ∈ \mathbb{R}^{n_a×2} X^a∈Rna×2 和 X ^ g ∈ R n g × 2 \hat{X}_g ∈ \mathbb{R}^{n_g×2} X^g∈Rng×2 。匹配被优化以使 X a X_a Xa和 X g X_g Xg对应于同一点。
我们利用基于注意力的图神经网络(GNN),遵循 Sarlin 等人 [52],使用最佳传输公式很好地解决部分匹配和遮挡问题。上述神经特征提取器和基于 GNN 的匹配器有助于享受基于学习的方法的好处,特别是那些在大型离线视觉数据上进行预训练的方法,而无需在线、端到端微调。
接下来描述依赖于这些神经特征的几何组件。
Lifting Points from 2D --> 3D。代理的 2D 局部特征相对于代理的坐标系提升为 3D,即 P a ∈ R n × 3 P_a ∈ \mathbb{R}^{n×3} Pa∈Rn×3。这是通过利用相机固有矩阵 K(特别是主点 px、py 和焦距 fx、fy)以及 Xa 中每个位置的相应深度值(例如 d a ∈ R n d_a ∈ R^n da∈Rn)来完成的。 P a P_a Pa 的第 i 行计算为:
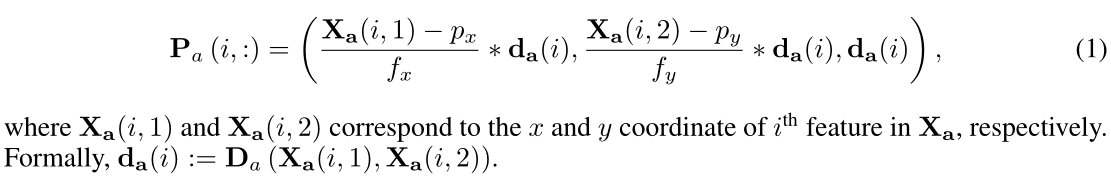
Perspective-n-Point:下一步的目标,即透视 n 点 (PnP) 是找到代理和目标相机姿势之间的旋转和平移,以最小化重投影误差。
具体来说,对于给定的旋转矩阵 R ∈ R 3 × 3 \textbf{R} ∈ R^{3×3} R∈R3×3 和平移向量 t ∈ R 3 \textbf{t} ∈ R^3 t∈R3,局部特征的 3D 位置 Pa 可以从代理的坐标系重新投影到目标相机的坐标系:

Easimating Distance and Heading to Goal: 预测的平移 t 可以帮助计算从智能体到目标的距离 ρ = ∥ t ∥ 2 ρ = \|t\|_2 ρ=∥t∥2。类似地,从智能体到目标的航向 ϕ \phi ϕ 可以通过沿光轴(智能体视图)的单位向量与 t 的点积获得。具体来说, ϕ = sgn ( t [ 1 ] ) ∗ arccos ( t ⋅ o a / ∥ t ∥ 2 ∥ o a ∥ 2 ) \phi=\operatorname{sgn}(t[1]) * \arccos \left(\mathbf{t} \cdot \mathbf{o}_{a} /\|\mathbf{t}\|_{2}\left\|\mathbf{o}_{a}\right\|_{2}\right) ϕ=sgn(t[1])∗arccos(t⋅oa/∥t∥2∥oa∥2)。该符号来自 t [ 1 ] t[1] t[1],它沿着垂直于智能体光轴但平行于地面的轴指向。在计算航向时,该标志特别重要,因为它区分了代理向右转还是向左转
Local police: 最后,利用智能体当前位置到估计目标之间的距离 ρ ρ ρ 和航向 ϕ \phi ϕ 来估计动作空间 A 中达到目标的动作。在准确实现[66, 1]之后,我们采用局部度量地图来允许代理启发式避开障碍物并朝着目标移动
Switches
我们定义了目标发现(探索)和最后一英里导航(利用)两个阶段之间简单但有效的切换。
如果对应数量 n > n t h n > n_{th} n>nth,则触发 explore --> exploit 开关,其中 n t h n_{th} nth 是设定阈值。这表明代理的图像与图像目标有显着重叠,因此控制可以流向最后一英里的导航阶段。我们发现这个简单的开关比训练特定的深度网络来实现相同的效果更好([1,3,4]中尝试的变体)。对于explore,如果R、t(参见方程(2))的优化失败或者预测距离大于 d t h d_{th} dth(调整为4m),则智能体返回到目标发现阶段。
Experiments