ChatGPT原理剖析
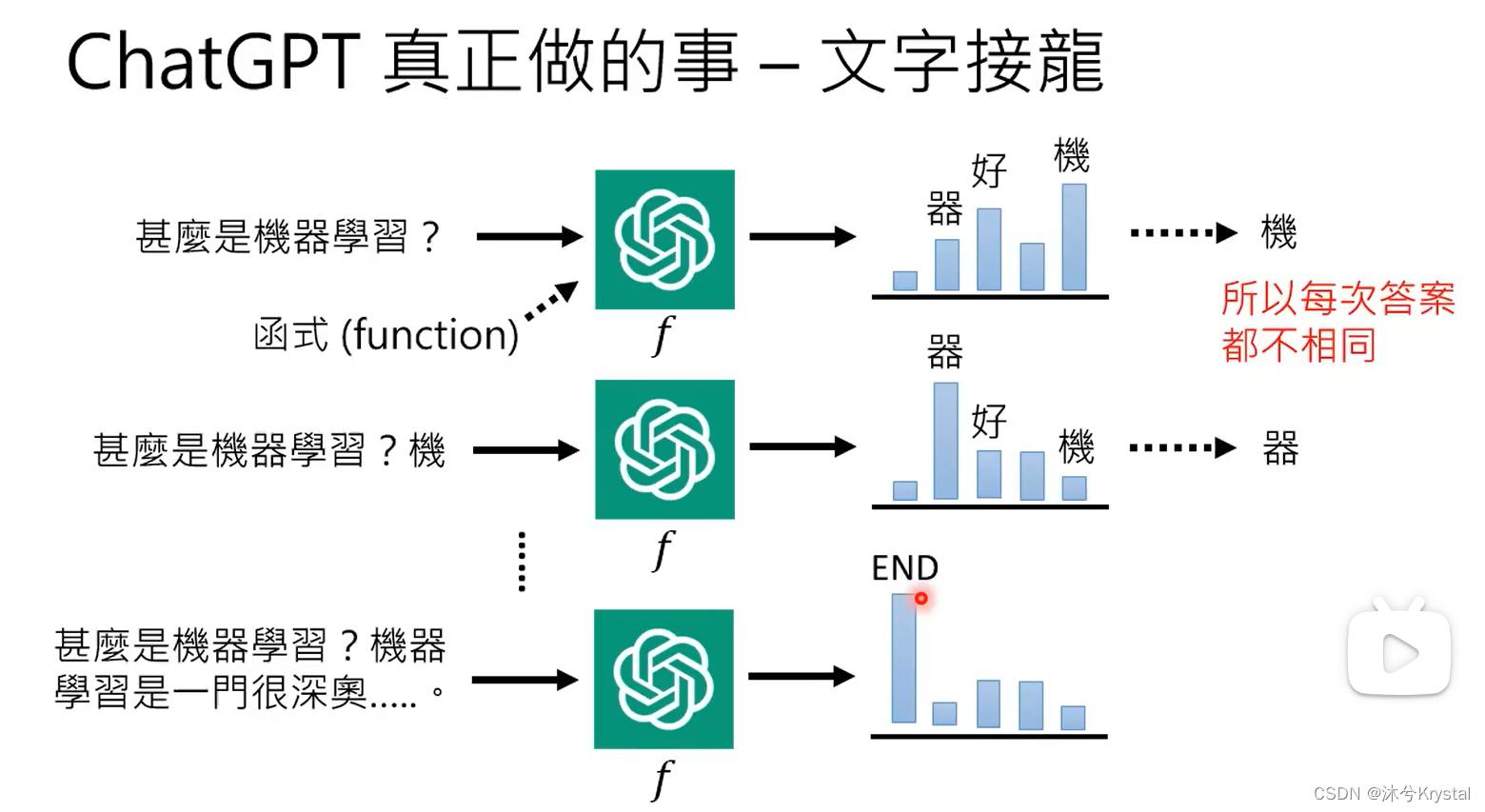
- 语言模型 == 文字接龙
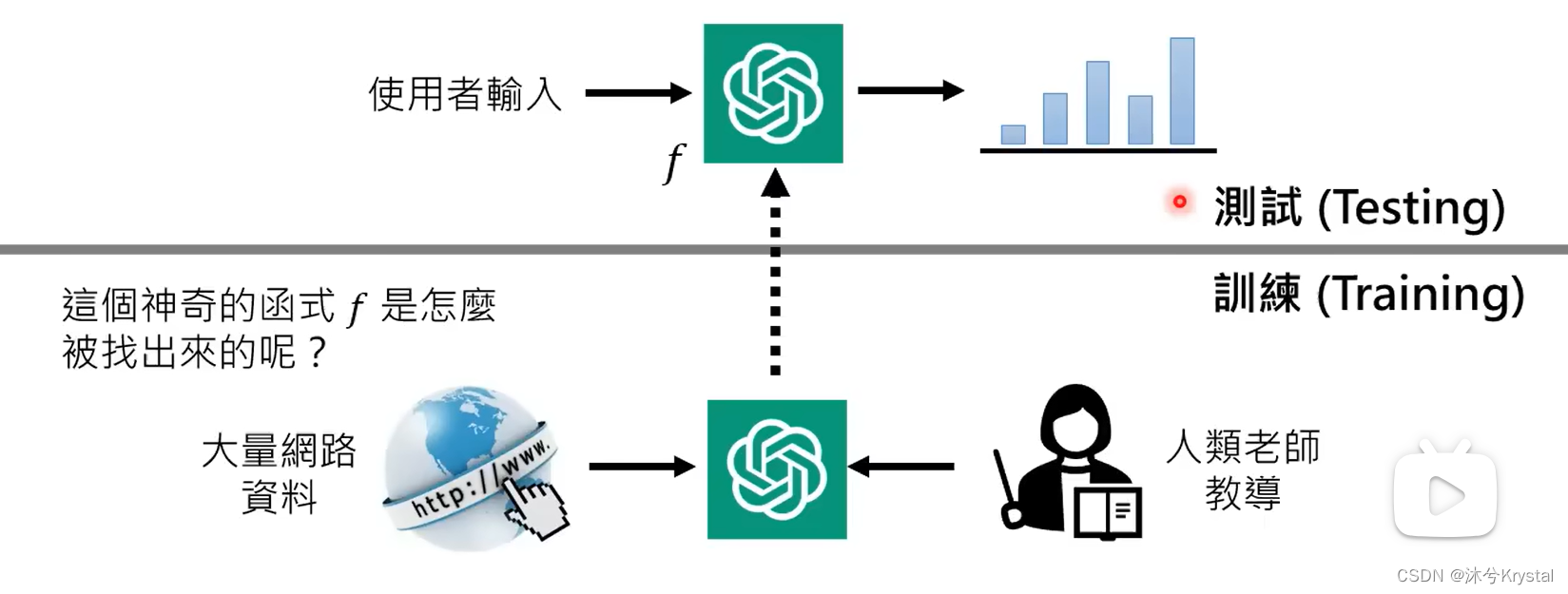
- ChatGPT在测试阶段是不联网的。
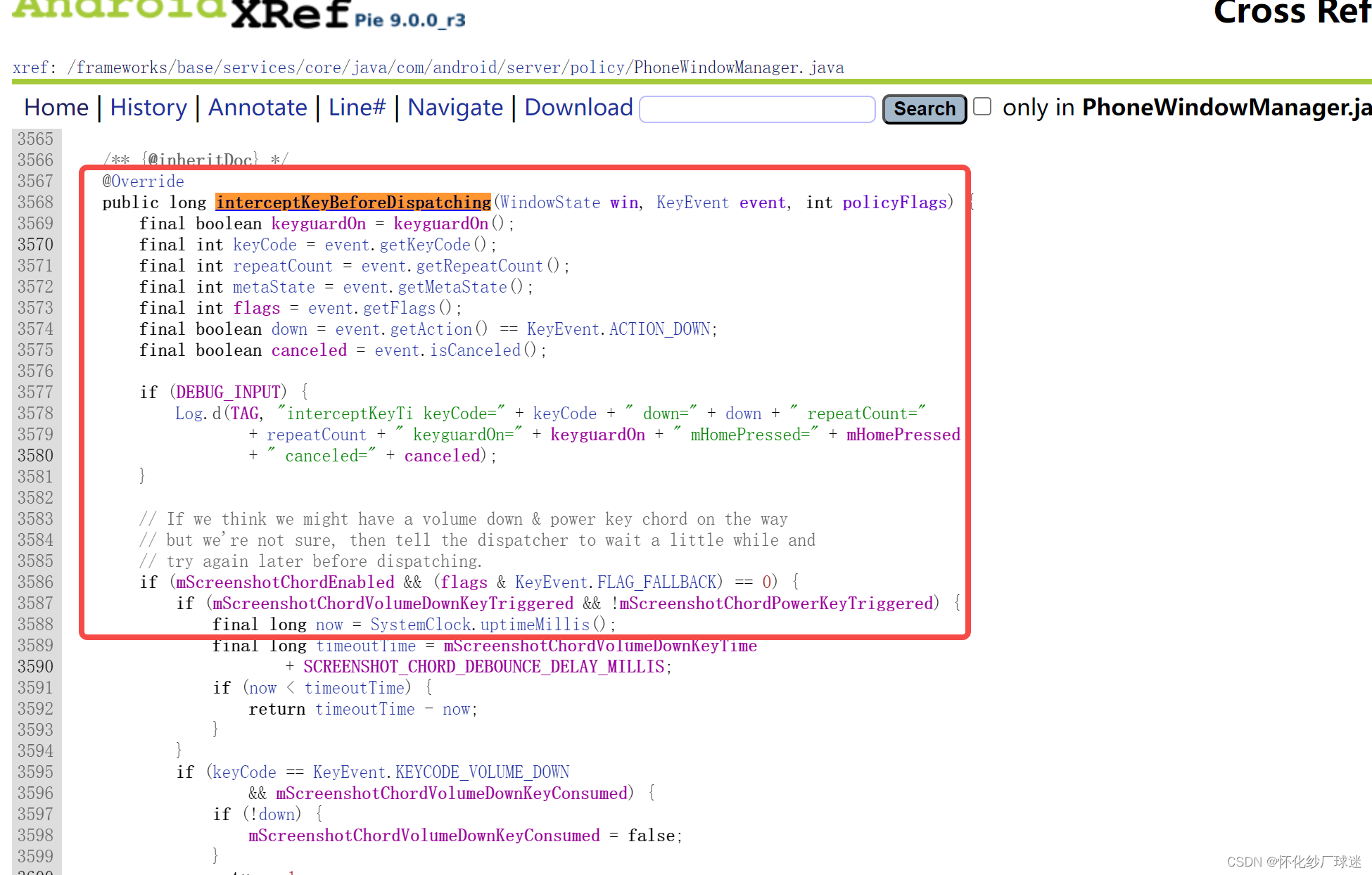
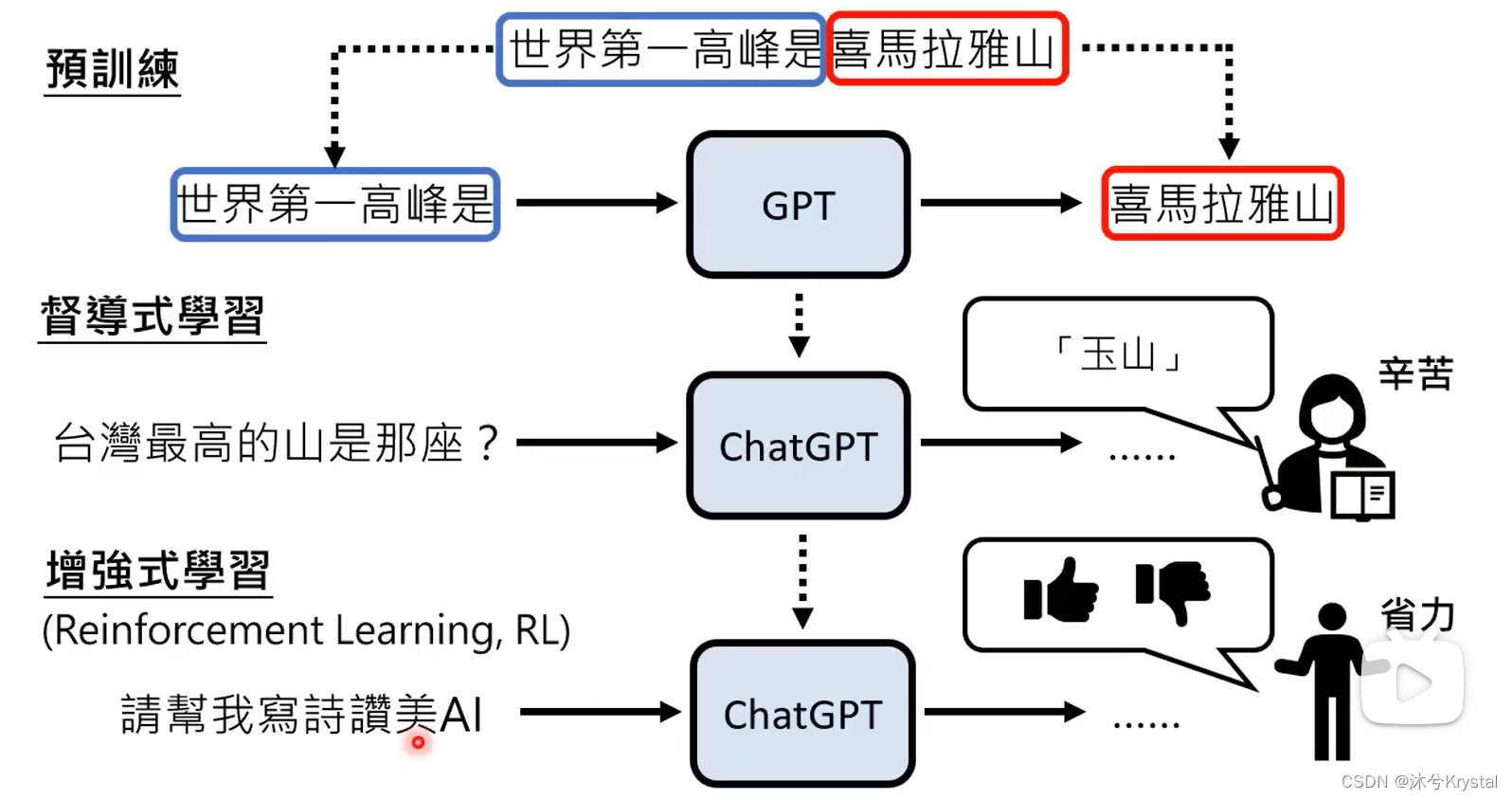
ChatGPT背后的关键技术:预训练(Pre-train)
- 又叫自监督式学习(Self-supervised Learning),得到的模型叫做基石模型(Foundation Model)。在自监督学习中,用一些方式“无痛”生成成对的学习资料。
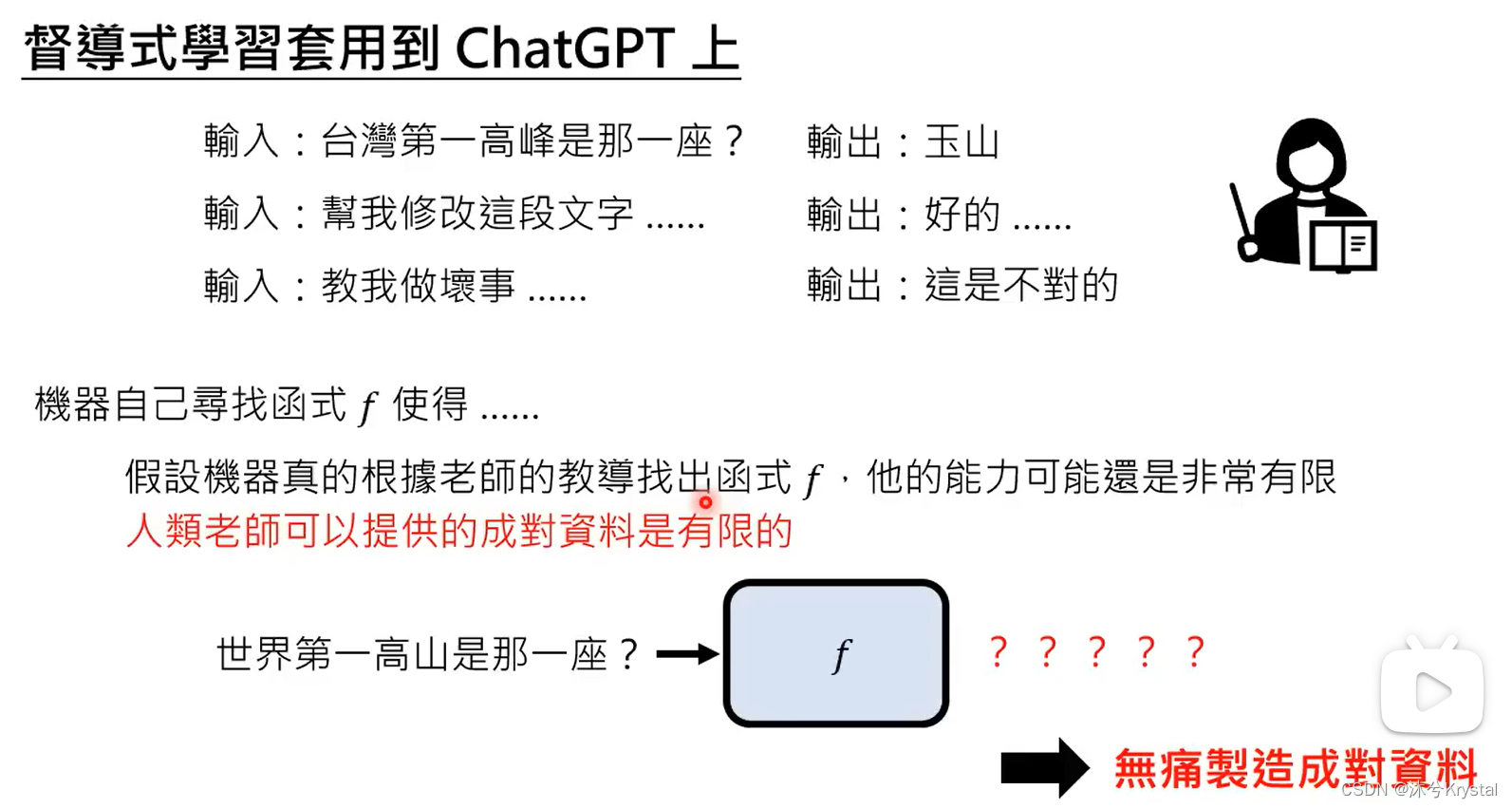
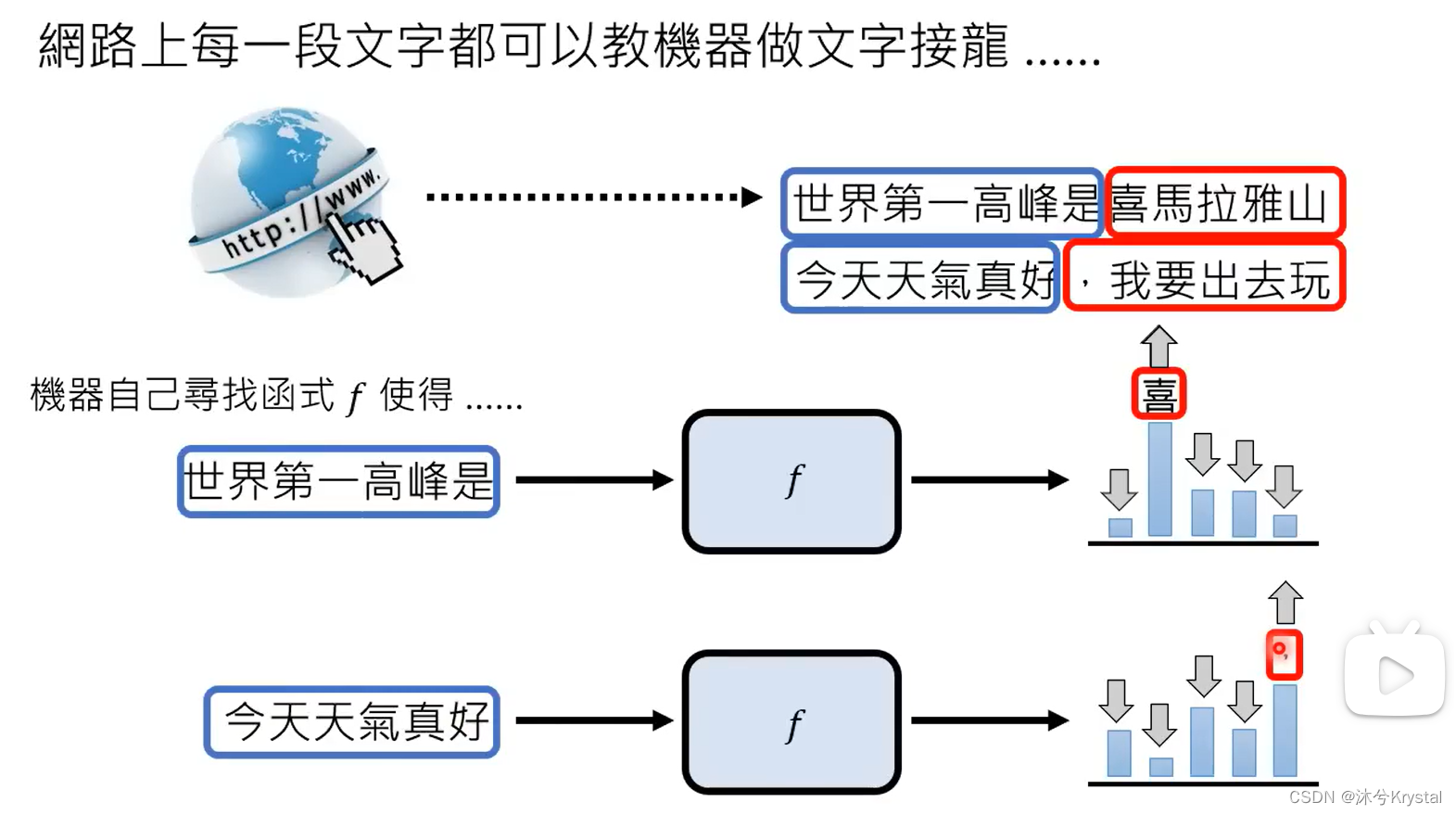
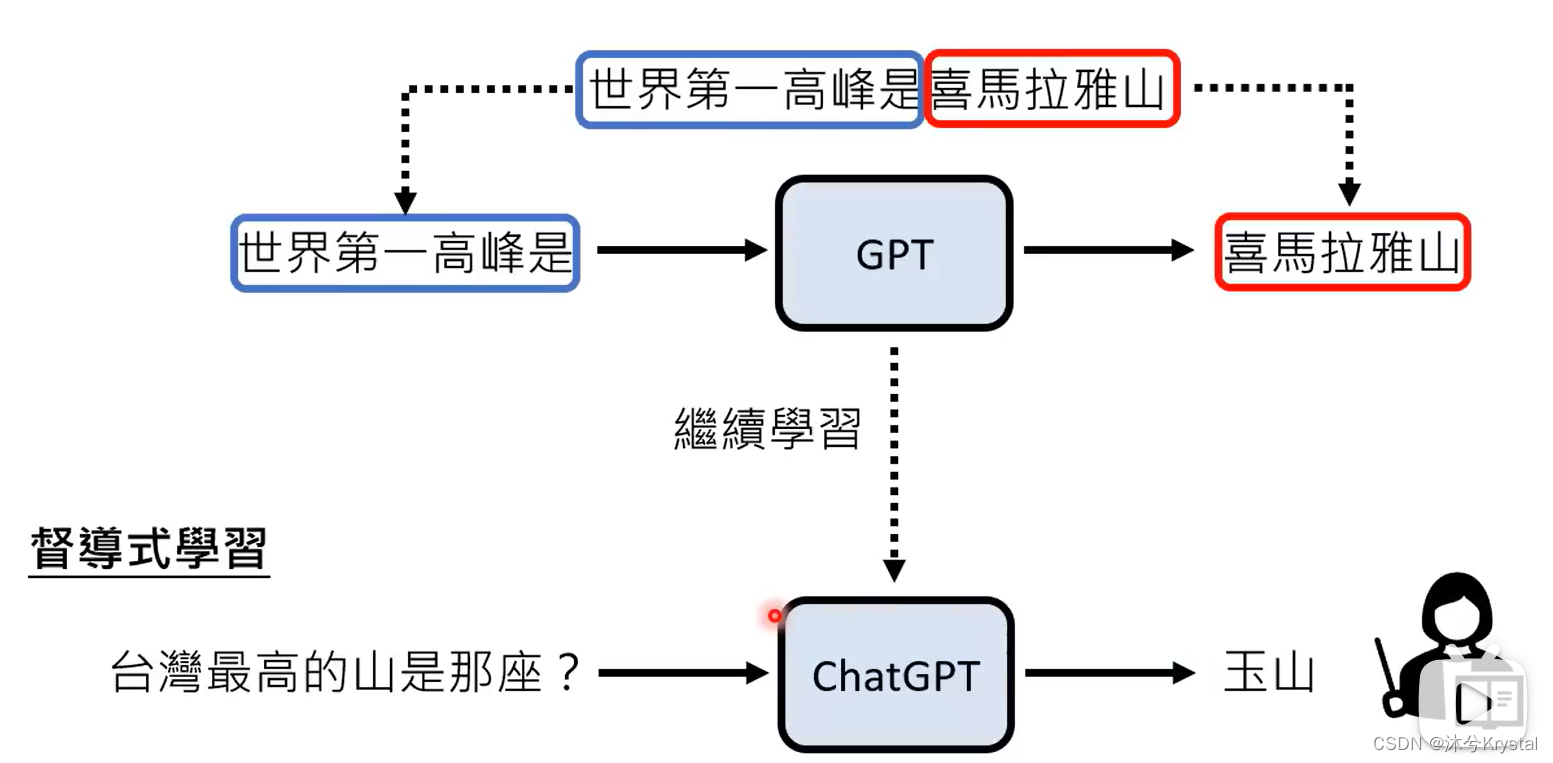
- GPT1 -> GPT2 -> GPT3 (参数量增加,通过大量网络资料学习,这一过程称为预训练),GPT -> ChatGPT (增加人类老师提供的资料学习),GPT到ChatGPT增加的继续学习的过程就叫做 微调 (finetune)。
预训练多有帮助呢?
- 在多种语言上做预训练后,只要教某一个语言的某一个任务,自动学会其他语言的同样任务。

- 当在104种语言上预训练,在英语数据上微调后在中文数据上测试的结果(78.8的F1值),和在中文数据上微调并在中文数据上测试的结果(78.1的F1值)相当。
ChatGPT带来的研究问题
- 1.如何精准提出需求
- 2.如何更正错误【Neural Editing】
- 3.侦测AI生成的物件
- 怎么用模型侦测一段文字是不是AI生成的
- 4.不小心泄露秘密?【Machine Unlearning】
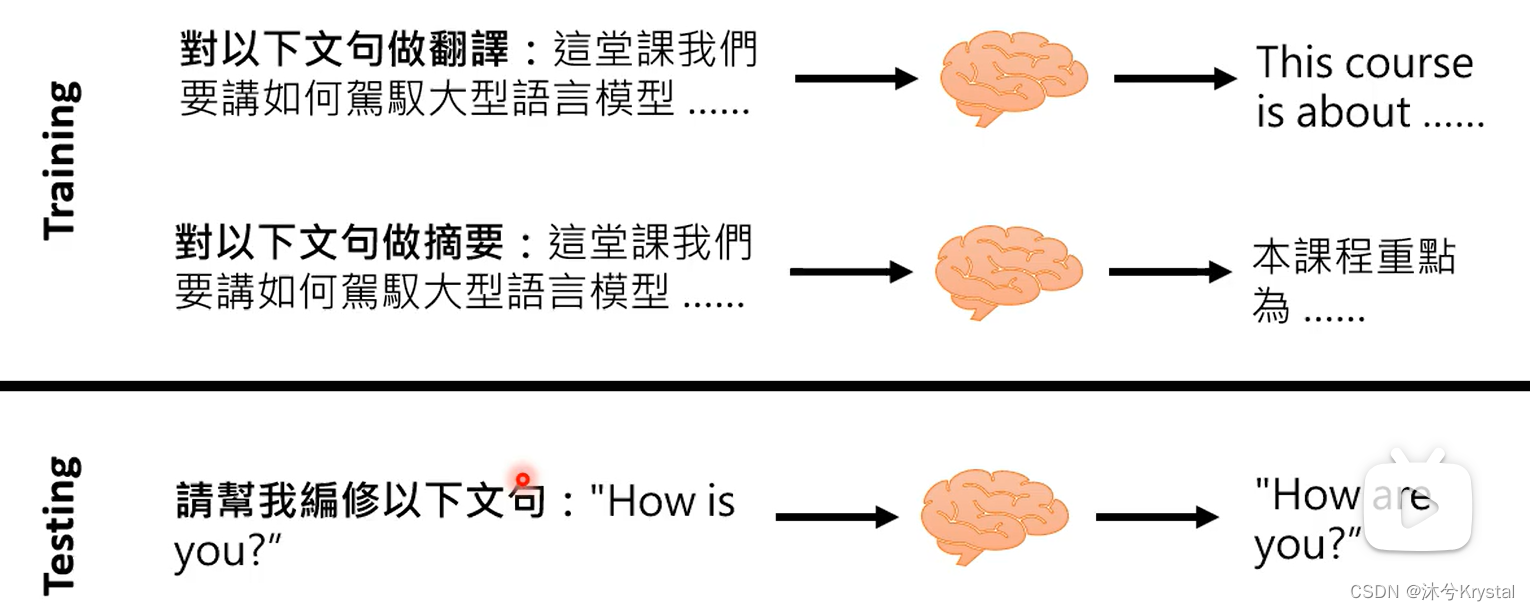
对于大型语言模型的两种不同期待 Finetune vs. Prompt
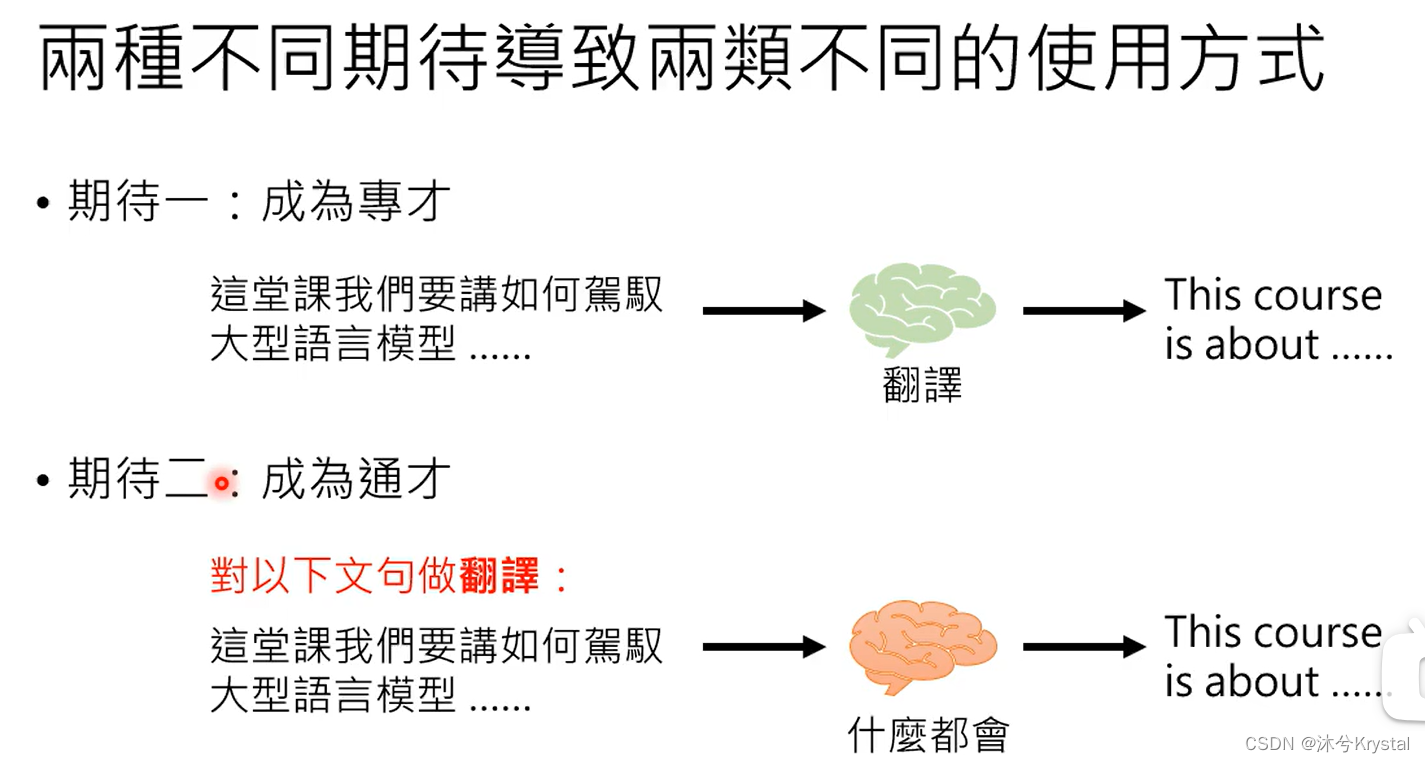
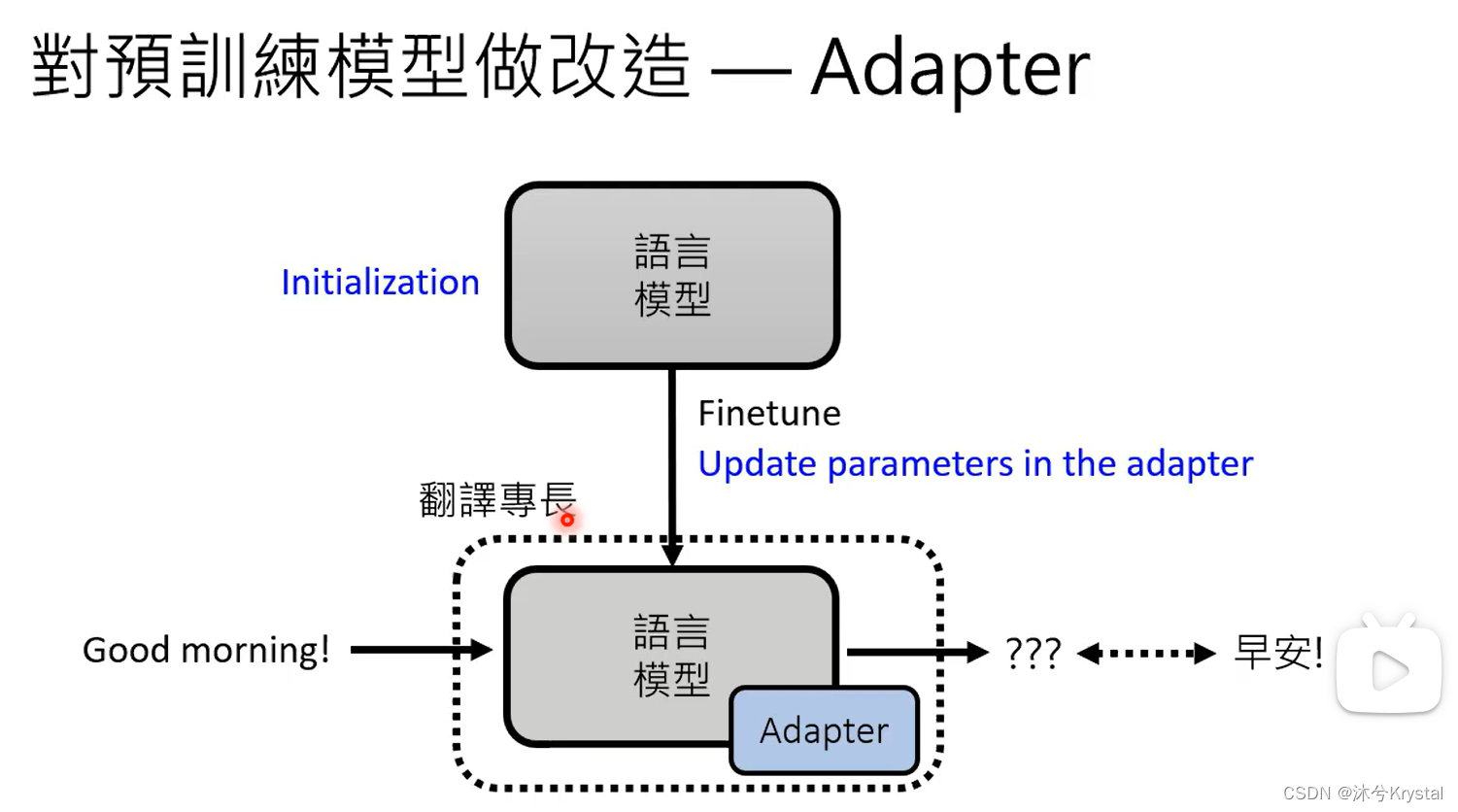
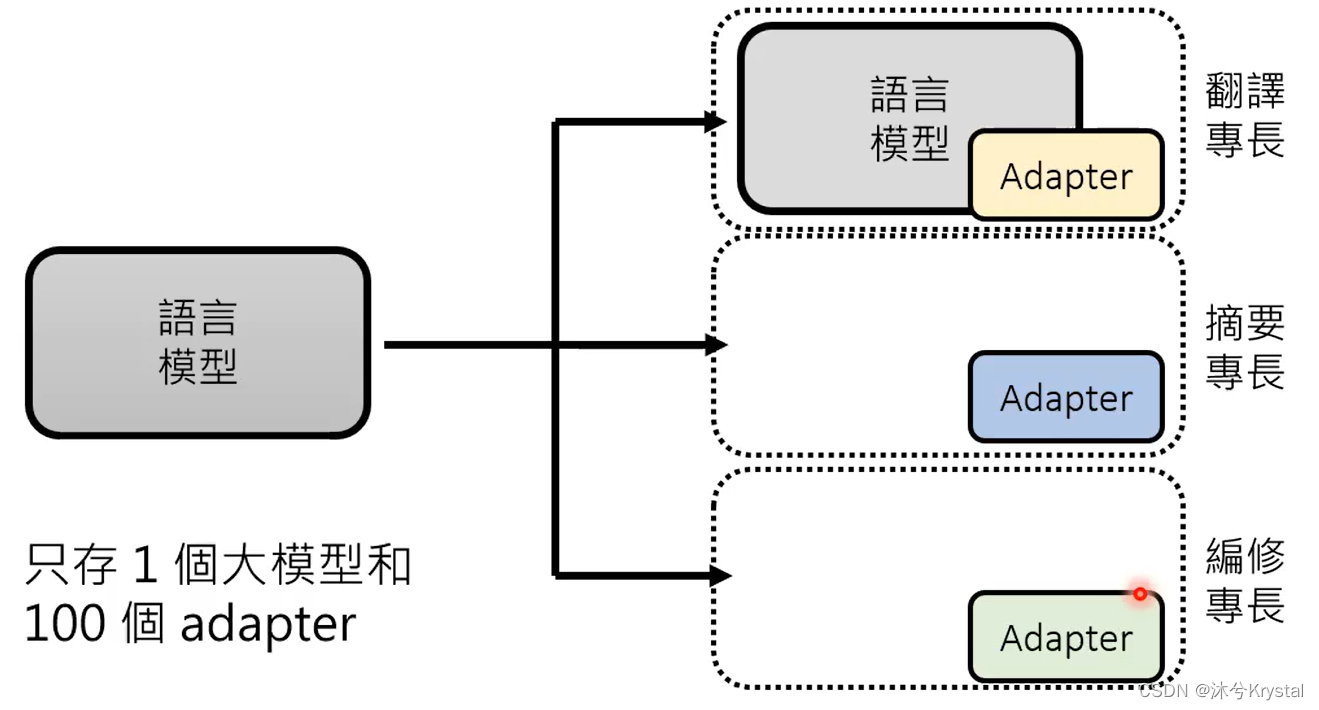
- 成为专才,对预训练模型做改造,加外挂和微调参数。
- 成为通才,机器要学会读题目描述或者题目范例
- 题目叙述–Instruction Learning
- 范例–In-context Learning
- In-context Learning
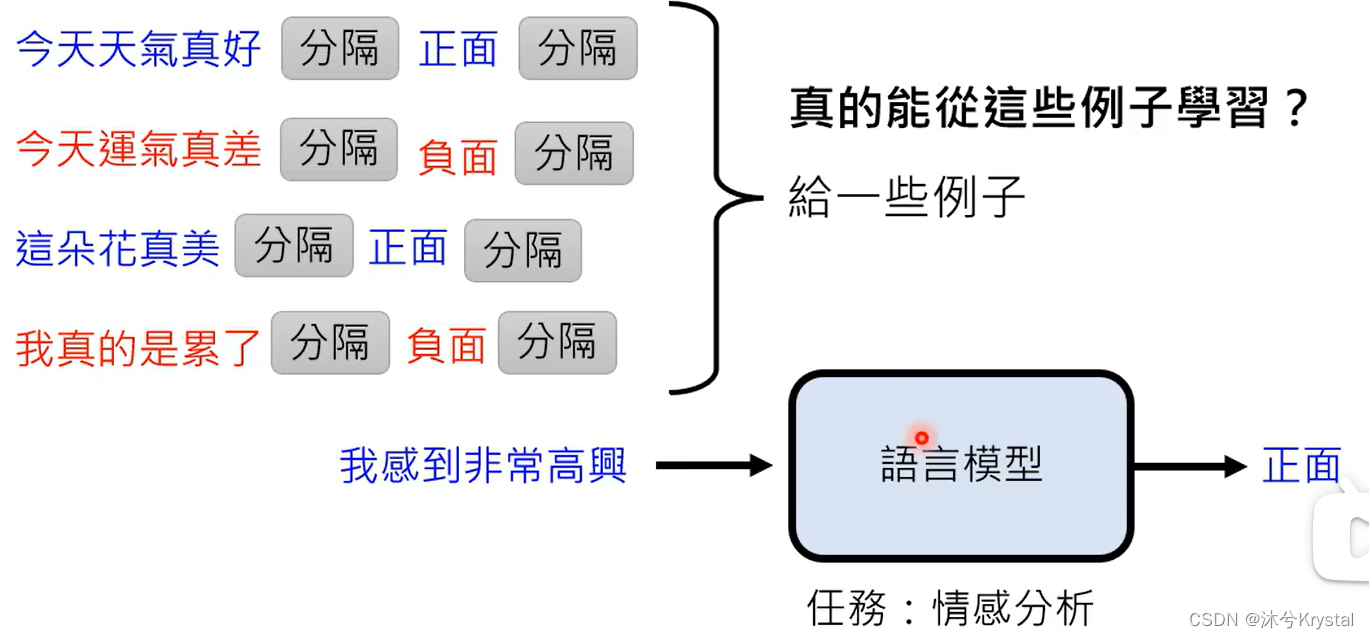
- 给机器的范例的domain是很重要的;范例的数量并不需要很多,并不是通过范例进行学习,范例的作用只是唤醒模型的记忆;也就是说,语言模型本来就会做情感分析,只是需要被指出需要做情感任务。
- Instruction-tuning