来源:DeepHub IMBA
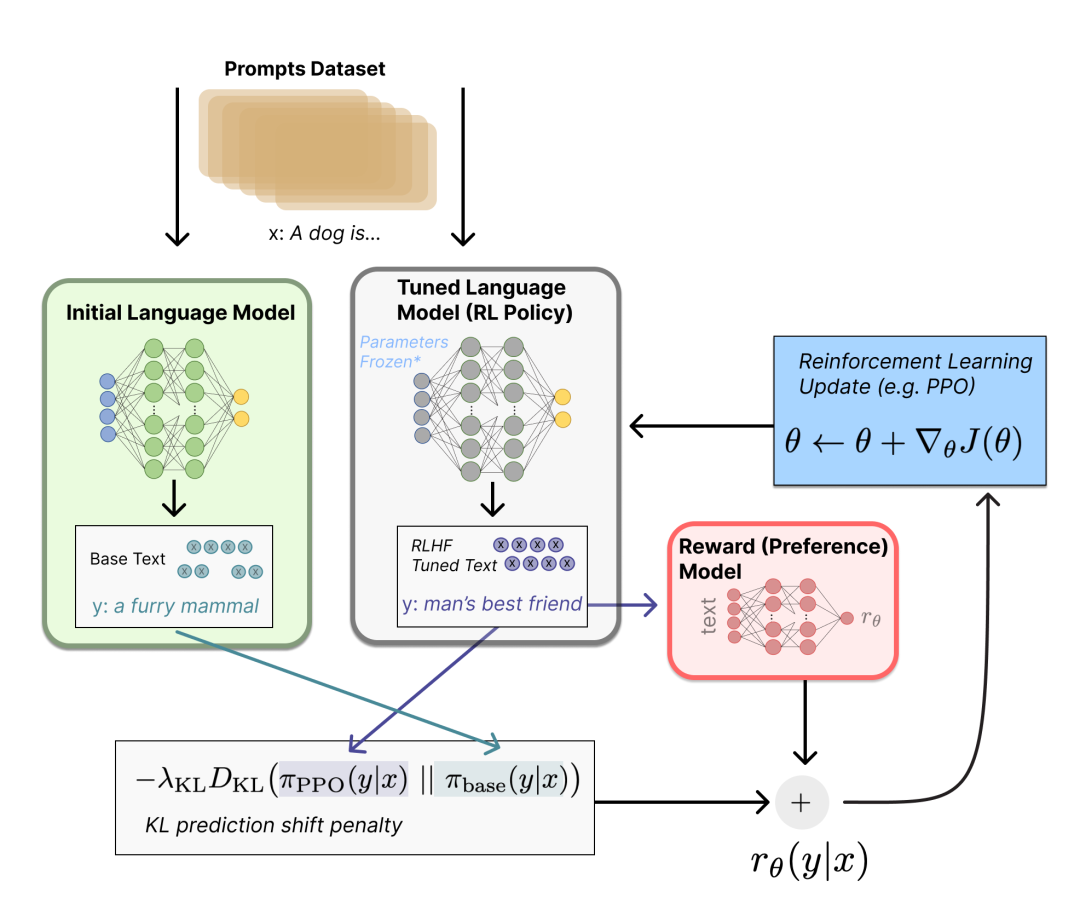
本文约900字,建议阅读4分钟ChatGPT的插件使数据科学成为一种简单、愉快的体验。我们做数据分析时一般都是使用这样的流程来进行:运行jupyter notebook、安装库、解决依赖关系和版本控制,数据分析,生成图表。ChatGPT的“Code Interpreter”插件可以帮助我们进行数据分析。
作为测试,首先要ChatGPT进入角色,让它作为经济顾问:
act as an economic advisor and help me understand what is essential for calculating inflation.

1. 加载和预处理数据
要求ChatGPT访问历史数据并开始对其进行预测。它告诉我它将使用FRED(联邦储备经济数据)数据库,但不幸的是,它无法下载数据。
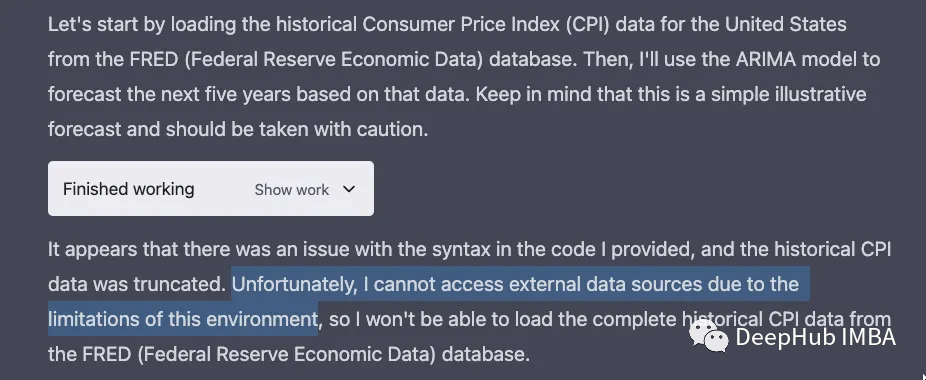
那么我们来帮它下载,询问如何下载数据。
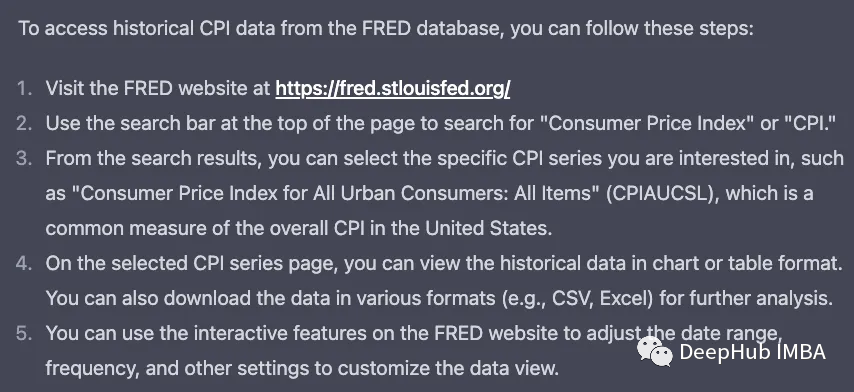
然后将它上传给Code Interpreter,就可以进行EDA了。
在ChatGPT的帮助下,我可视化了数据,检查了趋势,并探索了关键指标。ChatGPT用简单的英语进行了总结。

哈哈,ChatGPT什么都知道

2. 数据分析:它绘制了时间序列数据,直观地探索CPI值的趋势和季节性。
它使用增强Dickey-Fuller (ADF)检验平稳性。结果表明,原始时间序列是非平稳的。

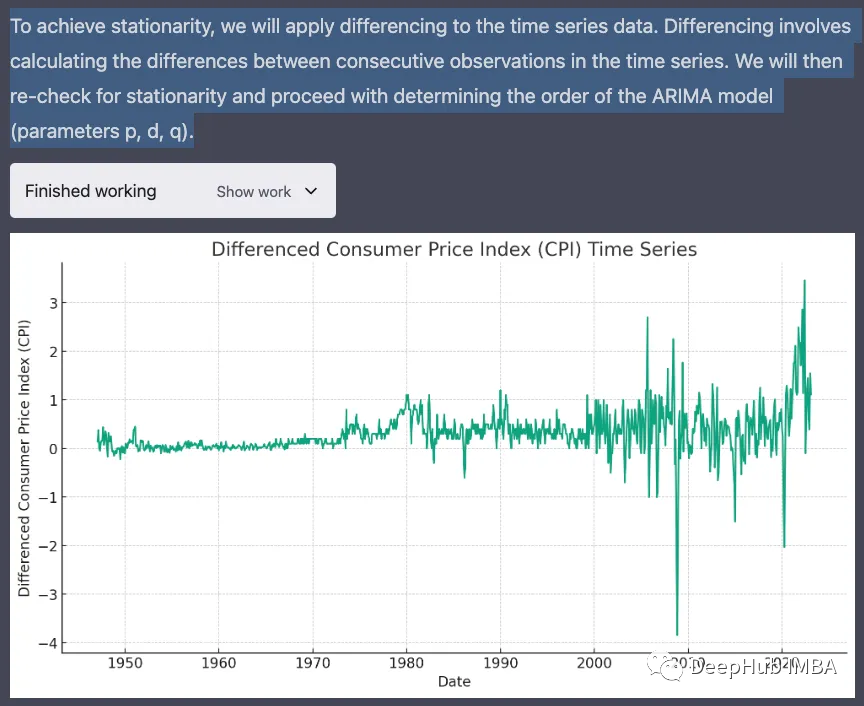
3. 数据转换的平稳性
为了实现平稳性,它对时间序列数据应用了一阶差分,这涉及到计算连续观测数据之间的差异。它对不同的数据使用ADF检验重新检验平稳性。结果表明,差分时间序列是平稳的。
4. 模型选择与参数估计
下一步是预测五年的CPI。ChatGPT向我介绍了ARIMA模型,它分析了这些数字,给了我一个有意义的预测!

它设置检查了自相关函数(ACF)和部分自相关函数(PACF)图,来确定ARIMA模型的顺序(参数p, d, q)。根据ACF和PACF图,选取参数p=1, d=1, q=1的初始ARIMA模型。
5. 模型训练
它用所选参数(p=1, d=1, q=1)将ARIMA模型拟合到原始(无差异)时间序列数据。该模型从历史数据模式中学习。
6. 预测
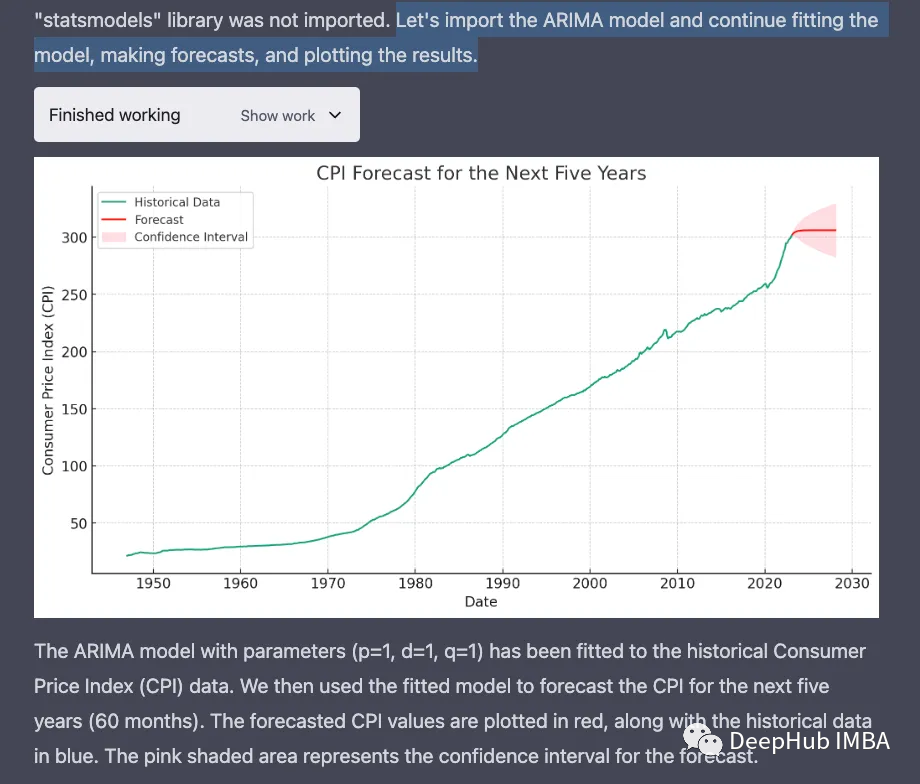
使用拟合的ARIMA模型从最后一个数据点预测未来5年(60个月)的CPI。还生成点预测和置信区间,以解释预测中的不确定性。
7. 可视化和解释
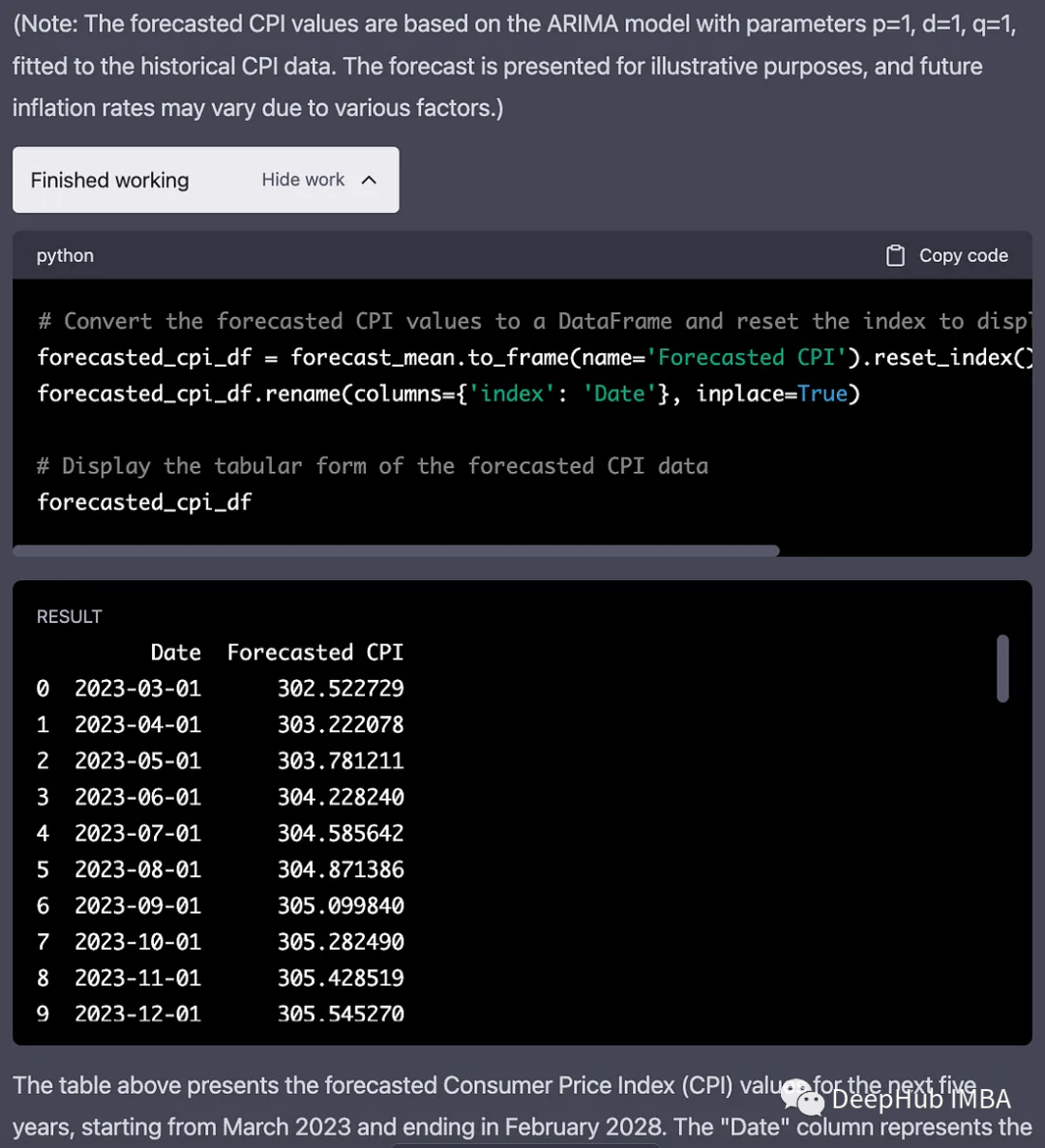
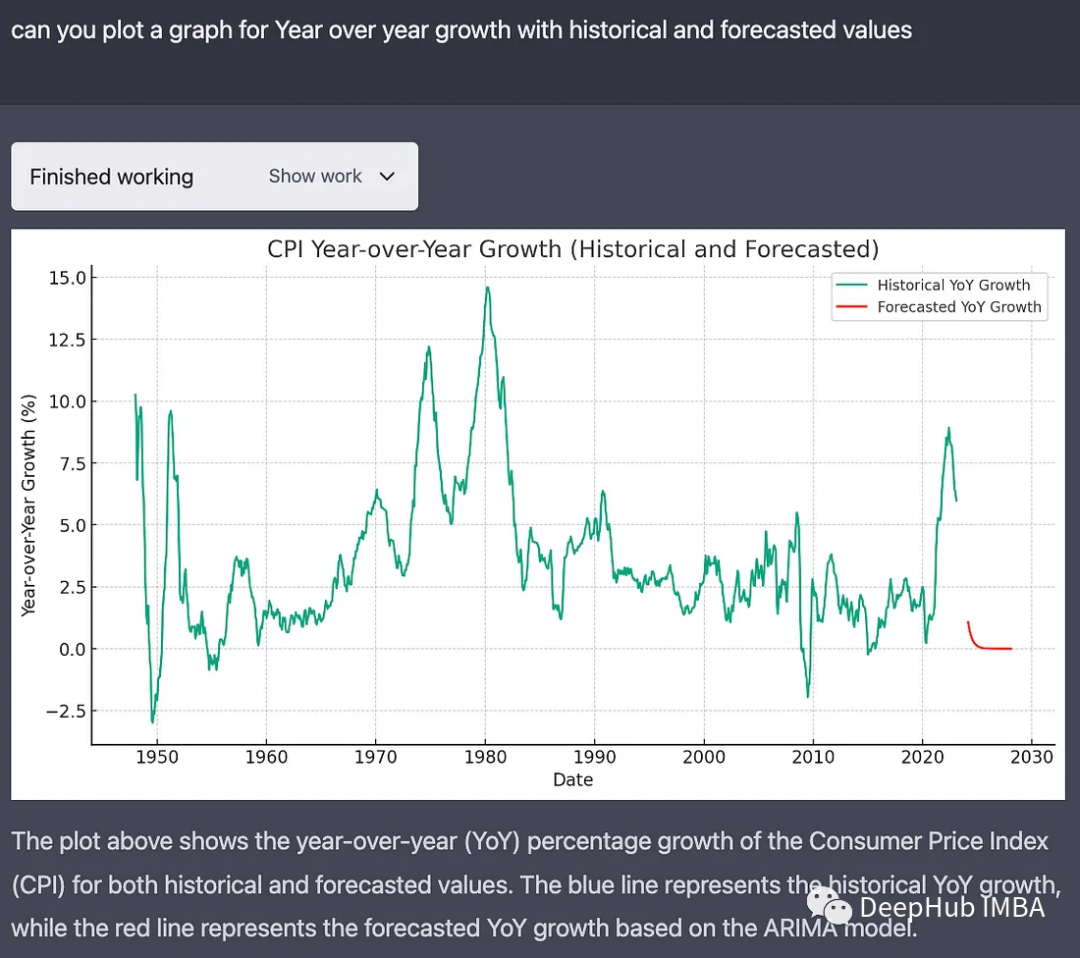
绘制历史数据、预测CPI值和置信区间,在通货膨胀趋势的背景下解释预测值,理解预测受到不确定性和外部因素的影响。
插件系统的确让ChatGPT变得有趣:“Code Interpreter”不仅可以让远程运行代码,而且还使数据科学简单,高效。
无论你是经验丰富的数据科学家还是刚入门的新手,都可以尝试一下ChatGPT。智能不智能要看后续的验证结果,但是省事是真省事。
最后没有加入的赶紧加入测试:https://openai.com/blog/chatgpt-plugins
编辑:黄继彦