Windows下安装Hive
- Hive与Hadoop的版本选择很关键,千万不能选错,否则各种报错。
- 一、Hive下载
- 1.1、官网下载Hive
- 1.2、网盘下载Hive
- 二、解压安装包,配置Hive环境变量
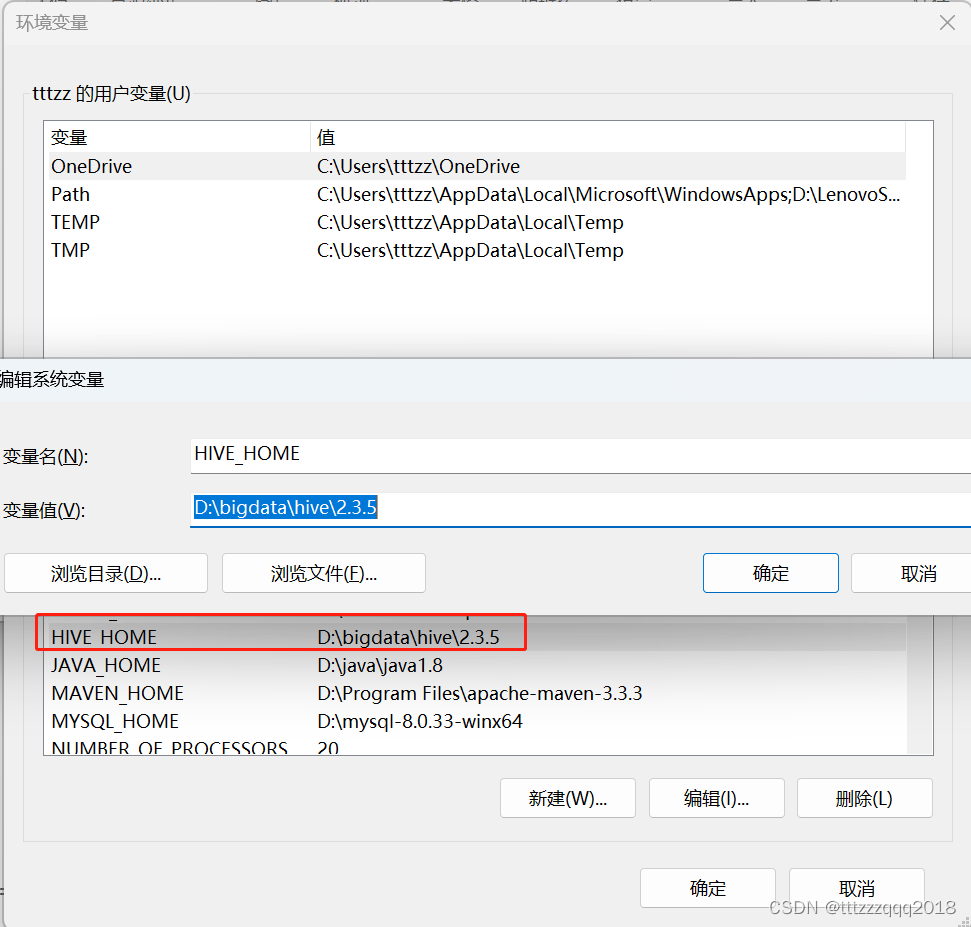
- 2.1、环境变量新增:HIVE_HOME
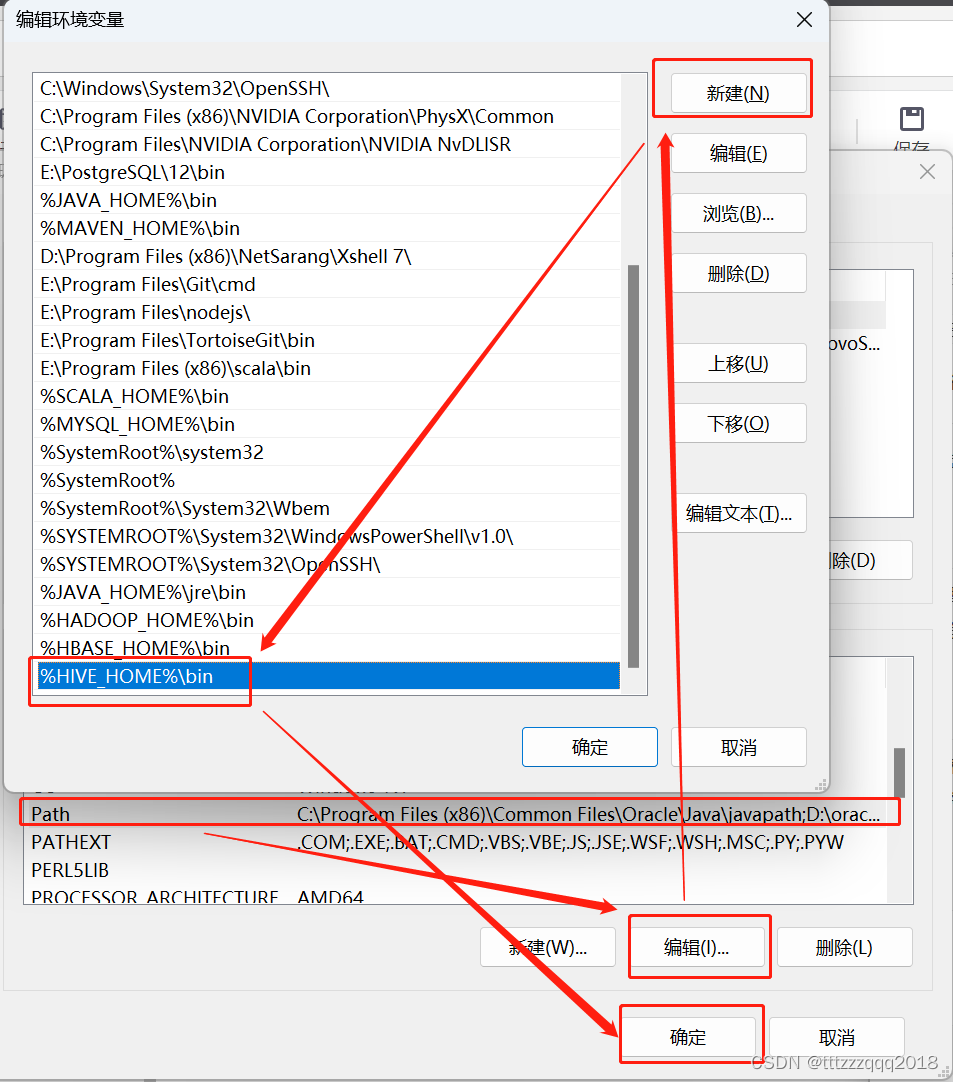
- 2.2、修改Path环境变量,增加Hive的bin路径
- 三、解决“Windows环境中缺少Hive的执行文件和运行程序”的问题
- 3.1、下载低版本Hive(apache-hive-2.0.0-src)
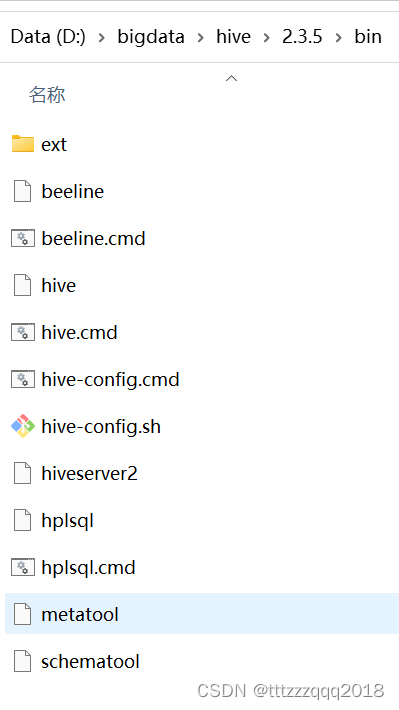
- 3.2、将低版本Hive的bin目录替换Hive原有的bin目录(D:\bigdata\hive\2.3.5\bin)
- 四、给Hive添加MySQL的jar包
- 4.1、下载连接MySQL的依赖jar包“mysql-connector-java-5.1.47-bin.jar”
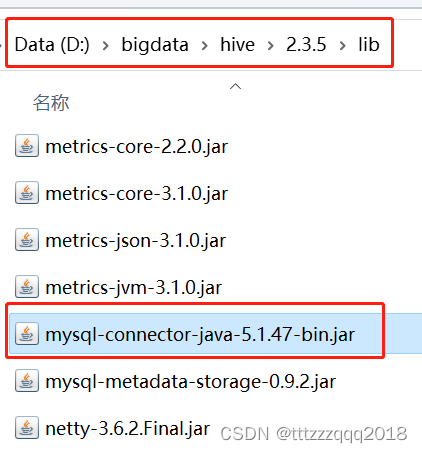
- 4.2、拷贝到$HIVE_HOME/lib目录下
- 五、创建Hive配置文件(hive-site.xml、hive-env.sh、hive-log4j2.properties、hive-exec-log4j2.properties)
- 六、新建Hive本地目录
- 七、修改Hive配置文件
- 7.1、修改Hive配置文件 hive-env.sh
- 7.2、修改Hive配置文件 hive-site.xml
- 八、启动Hadoop
- 8.1、启动Hadoop
- 8.2、在Hadoop上创建HDFS目录并给文件夹授权(选做,可不做)
- 九、启动Hive服务
Hive与Hadoop的版本选择很关键,千万不能选错,否则各种报错。
本篇
Hadoop版本为:2.7.2
Hive版本为:2.3.5
请严格按照版本来安装。
一、Hive下载
1.1、官网下载Hive
https://dlcdn.apache.org/hive/
1.2、网盘下载Hive
如果嫌慢,可以网盘下载:链接:
https://pan.baidu.com/s/1axk8C4Zw7CUuP1b1SGPyPg?pwd=yyds
二、解压安装包,配置Hive环境变量
解压安装包到(D:\bigdata\hive\2.3.5),注意路径不要有空格。
2.1、环境变量新增:HIVE_HOME
2.2、修改Path环境变量,增加Hive的bin路径
三、解决“Windows环境中缺少Hive的执行文件和运行程序”的问题
Hive 的Hive_x.x.x_bin.tar.gz 高版本在windows 环境中缺少 Hive的执行文件和运行程序。
解决方法:
3.1、下载低版本Hive(apache-hive-2.0.0-src)
下载地址:http://archive.apache.org/dist/hive/hive-2.0.0/apache-hive-2.0.0-bin.tar.gz
或者网盘下载:https://pan.baidu.com/s/1exyrc51P4a_OJv2XHYudCw?pwd=yyds
3.2、将低版本Hive的bin目录替换Hive原有的bin目录(D:\bigdata\hive\2.3.5\bin)
替换后:
四、给Hive添加MySQL的jar包
下载和拷贝一个 mysql-connector-java-5.1.47-bin.jar 到 $HIVE_HOME/lib 目录下。
4.1、下载连接MySQL的依赖jar包“mysql-connector-java-5.1.47-bin.jar”
官网下载地址:https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java-5.1.47.zip
或者网盘下载:https://pan.baidu.com/s/1X6ZGyy3xNYI76nDoAjfVVA?pwd=yyds
4.2、拷贝到$HIVE_HOME/lib目录下
五、创建Hive配置文件(hive-site.xml、hive-env.sh、hive-log4j2.properties、hive-exec-log4j2.properties)
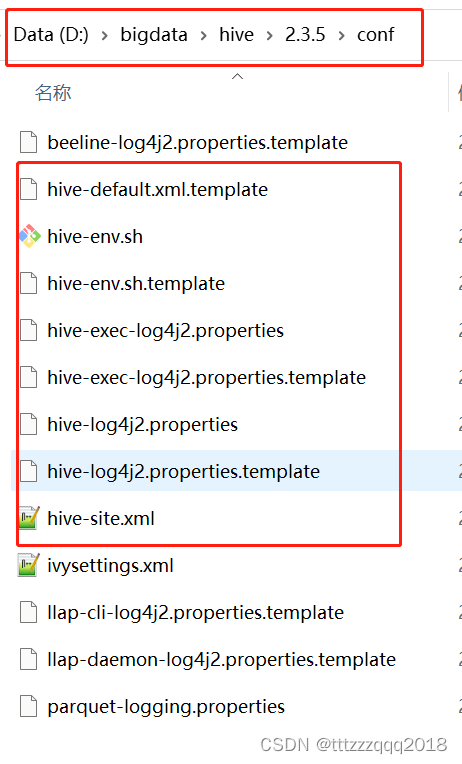
配置文件目录(%HIVE_HOME%\conf)有4个默认的配置文件模板拷贝成新的文件名
| 原文件名 | 拷贝后的文件名 |
|---|---|
| hive-log4j.properties.template | hive-log4j2.properties |
| hive-exec-log4j.properties.template | hive-exec-log4j2.properties |
| hive-env.sh.template | hive-env.sh |
| hive-default.xml.template | hive-site.xml |
六、新建Hive本地目录
后面Hive的配置文件用到下面这些目录:
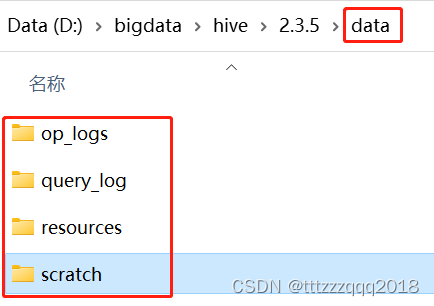
先在Hive安装目录下建立 data 文件夹,
然后再到在这个文件夹下建
op_logs
query_log
resources
scratch 这四个文件夹,建完后如下图所示:
七、修改Hive配置文件
7.1、修改Hive配置文件 hive-env.sh
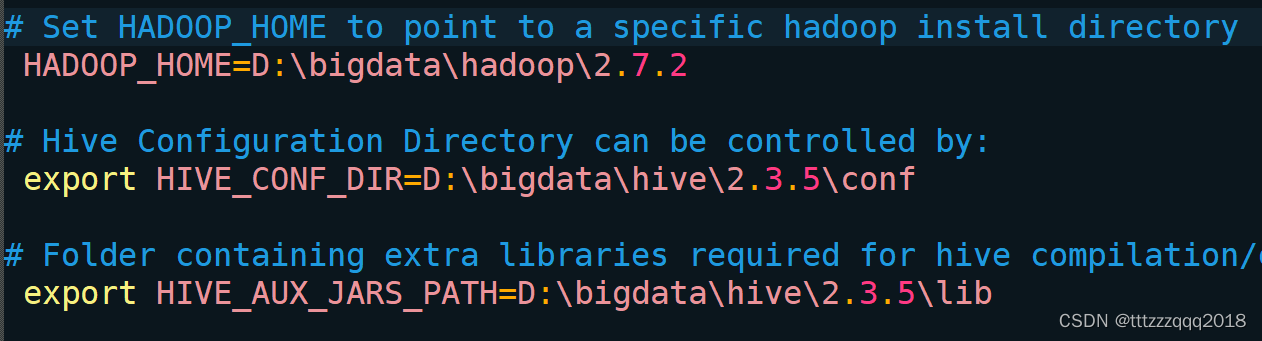
编辑 conf\hive-env.sh 文件:
根据自己的Hive安装路径(D:\hive-3.1.3),添加三条配置信息:
# Set HADOOP_HOME to point to a specific hadoop install directoryHADOOP_HOME=D:\bigdata\hadoop\2.7.2# Hive Configuration Directory can be controlled by:export HIVE_CONF_DIR=D:\bigdata\hive\2.3.5\conf# Folder containing extra libraries required for hive compilation/execution can be controlled by:export HIVE_AUX_JARS_PATH=D:\bigdata\hive\2.3.5\lib
7.2、修改Hive配置文件 hive-site.xml
编辑 conf\hive-site.xml 文件:
根据自己的Hive安装路径(D:/hive-3.1.3),修改下面几个参数的配置:
<property><name>hive.exec.local.scratchdir</name><value>D:/bigdata/hive/2.3.5/data/scratch</value><description>Local scratch space for Hive jobs</description></property><property><name>hive.server2.logging.operation.log.location</name><value>D:/bigdata/hive/2.3.5/data/op_logs</value><description>Top level directory where operation logs are stored if logging functionality is enabled</description></property><property><name>hive.downloaded.resources.dir</name><value>D:/bigdata/hive/2.3.5/data/resources/${hive.session.id}_resources</value><description>Temporary local directory for added resources in the remote file system.</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>Username to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value><description>password to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3307/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value><description>JDBC connect string for a JDBC metastore.To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.</description></property>
修改后的 hive-site.xml 下载地址:https://pan.baidu.com/s/1ycOGYzh7t3np2Qfy5A_rLg?pwd=yyds
八、启动Hadoop
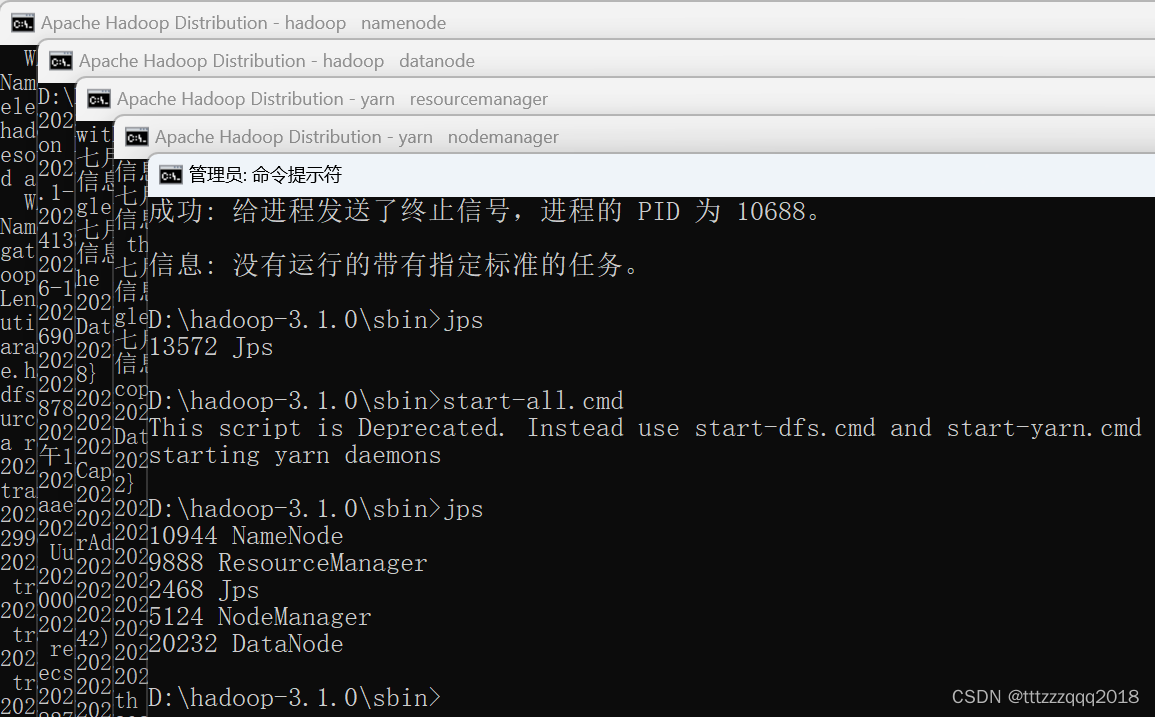
8.1、启动Hadoop
Hadoop安装及启动,请看这篇博文:Windows下安装Hadoop(手把手包成功安装)
可以通过访问namenode和HDFS的Web UI界面(http://localhost:50070)
以及resourcemanager的页面(http://localhost:8088)
8.2、在Hadoop上创建HDFS目录并给文件夹授权(选做,可不做)
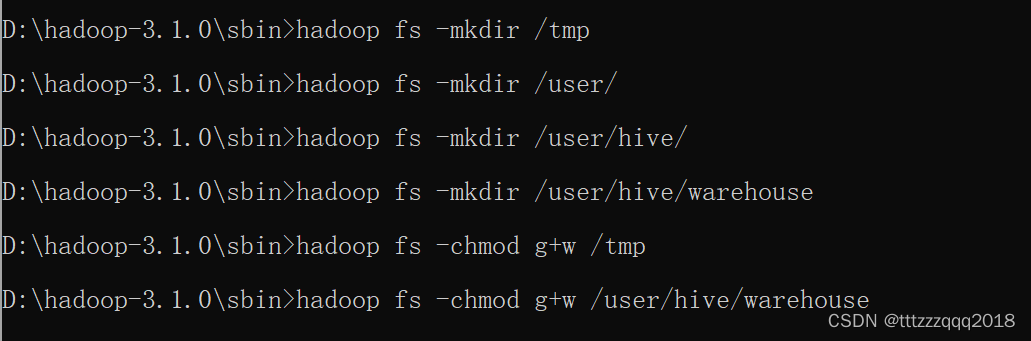
使用命令:
hadoop fs -mkdir /tmp
hadoop fs -mkdir /user/
hadoop fs -mkdir /user/hive/
hadoop fs -mkdir /user/hive/warehouse
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
或者使用命令:
hdfs dfs -mkdir /tmp
hdfs dfs -chmod -R 777 /tmp
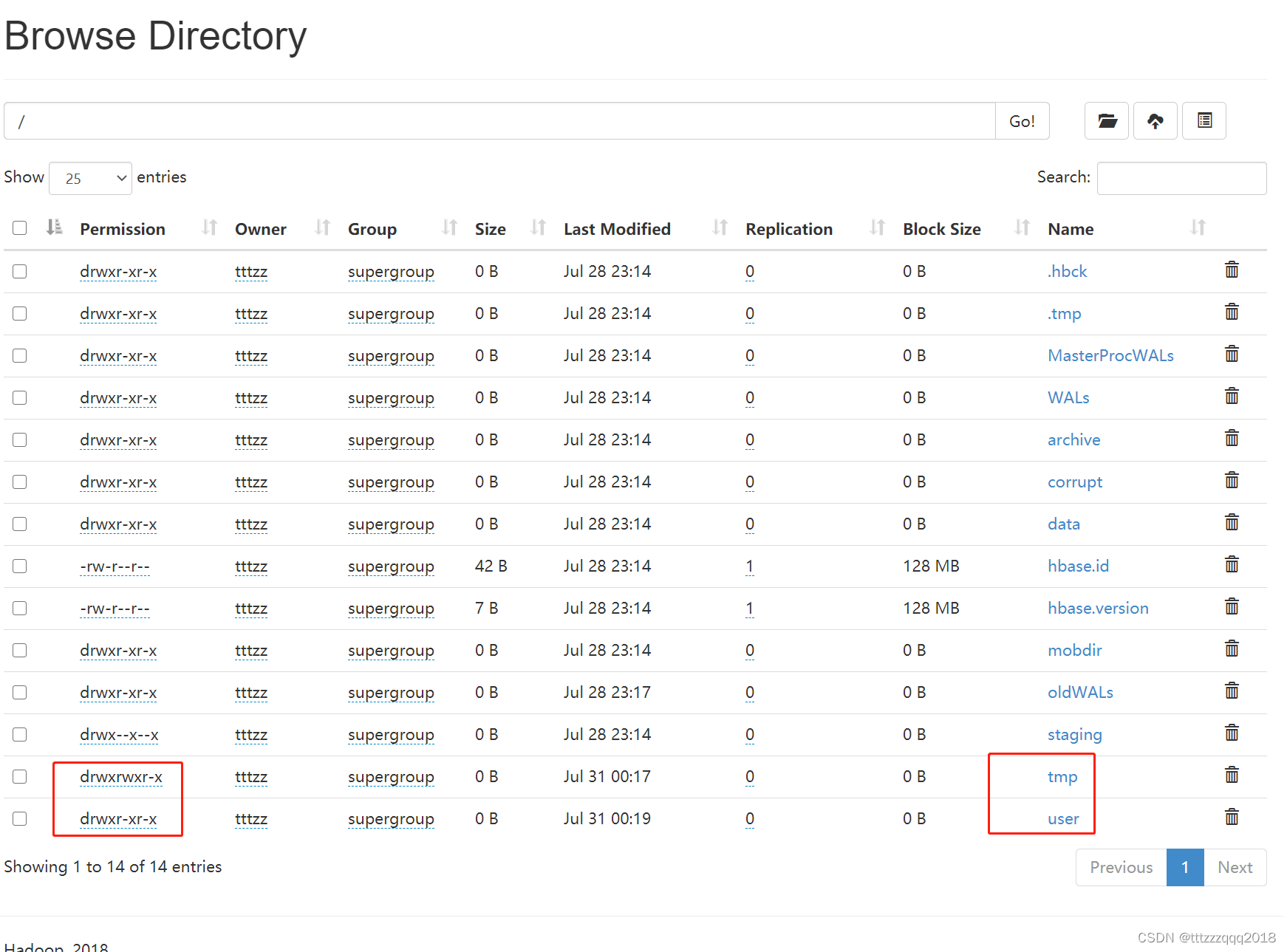
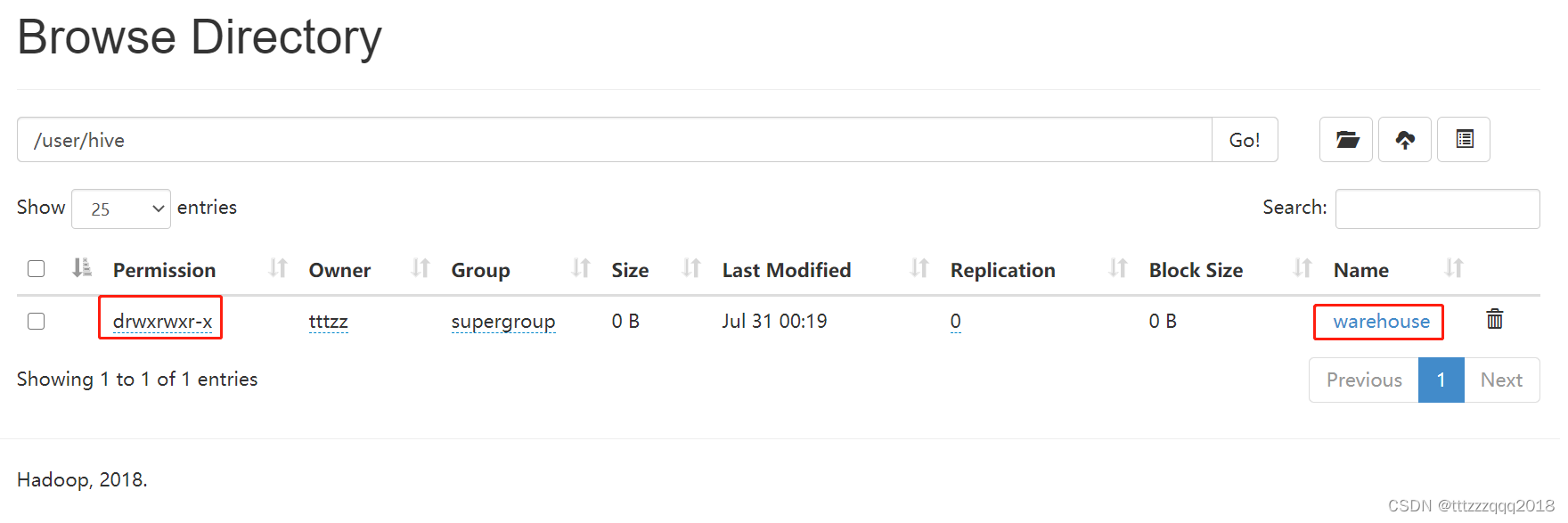
在Hadoop管理台(http://localhost:50070/explorer.html#/)可以看相应的情况:
九、启动Hive服务
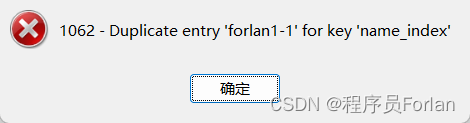
初始化Hive元数据库(修改为采用MySQL存储元数据)
在%HIVE_HOME%/bin目录下执行下面的脚本:
hive --service schematool -dbType mysql -initSchema
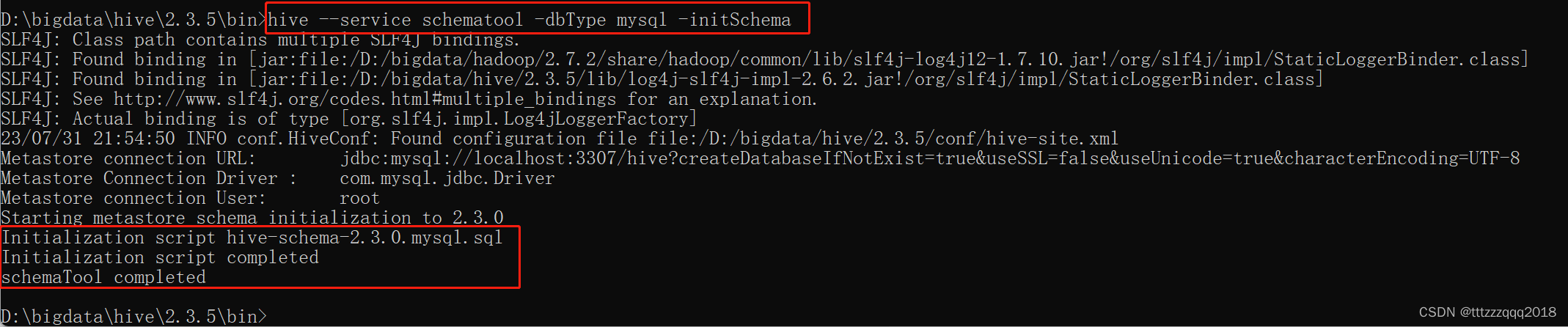
可以发现,Hive会自动连接MySQL去创建schema hive,并执行脚本。
输入hive,进入hive: