目录
1. 使用一个二维网格和二维块的矩阵加法
1.1 关键代码
1.2 完整代码
1.3 运行时间
2. 使用一维网格和一维块的矩阵加法
2.1 关键代码
2.2 完整代码
2.3 运行时间
3. 使用二维网格和一维块的矩阵矩阵加法
3.1 关键代码
3.2 完整代码
3.3 运行时间
1. 使用一个二维网格和二维块的矩阵加法
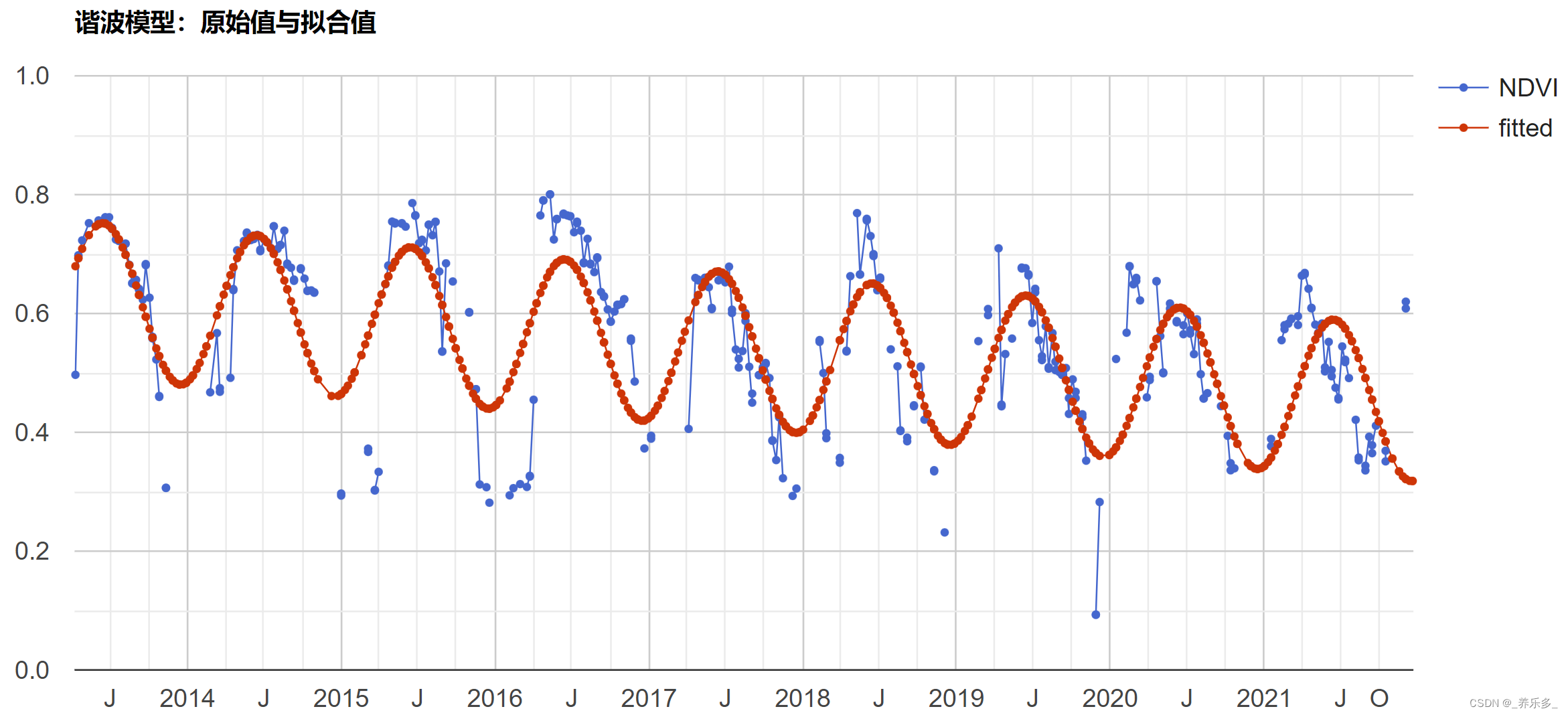
这里建立二维网格(2,3)+二维块(4,2)为例,使用其块和线程索引映射矩阵索引。
(1)第一步,可以用以下公式把线程和块索引映射到矩阵坐标上;
![]()
(2)第二步,可以用以下公式把矩阵坐标映射到全局内存中的索引/存储单元上;
![]()
比如要获取矩阵元素(col,row) = (2,4) ,其全局索引是34,映射到矩阵坐标上,
ix = 2 + 0*3=2; iy = 0 + 2*2=4. 然后再映射到全局内存idx = 4*8 + 2 = 34.
1.1 关键代码
(1) 先固定二维线程块尺寸,再利用矩阵尺寸结合被分块尺寸,推导出二维网格尺寸。
// config
int dimx = 32;
int dimy = 32;
dim3 block(dimx, dimy); // 二维线程块(x,y)=(4,2)
dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y); // 二维网格(2,3)
// 直接nx/block.x = 8/4=2. (8+4-1)/4=2. (9+4-1)/4=3(2) 前面建立好了二维网格和二维线程块,根据公式去求矩阵索引。
// 去掉了循环
// 利用公式,使用二维网格、二维线程块映射矩阵索引。
__global__ void sumMatrixOnDevice2D(float* d_a, float* d_b, float* d_c, const int nx, const int ny)
{// 二维网格和二维块,映射到矩阵坐标unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;// 由矩阵坐标, 映射到全局坐标(都是线性存储的)unsigned int idx = iy * nx + ix; // 坐标(ix, iy),前面由iy行,每行有nx个元素// 相加if (ix < nx && iy < ny) // 配置线程的可能过多,这里防止越界。{d_c[idx] = d_a[idx] + d_b[idx];}
}1.2 完整代码
#include "cuda_runtime.h"
#include "device_launch_parameters.h" // threadIdx#include <stdio.h> // io
#include <time.h> // time_t clock_t
#include <stdlib.h> // rand
#include <memory.h> //memset#define CHECK(call) \
{ \const cudaError_t error_code = call; \if (error_code != cudaSuccess) \{ \printf("CUDA Error:\n"); \printf(" File: %s\n", __FILE__); \printf(" Line: %d\n", __LINE__); \printf(" Error code: %d\n", error_code); \printf(" Error text: %s\n", \cudaGetErrorString(error_code)); \exit(1); \} \
}/// <summary>
/// 矩阵相加,线性存储的二维矩阵
/// </summary>
/// <param name="h_a"></param>
/// <param name="h_b"></param>
/// <param name="h_c"></param>
/// <param name="nx"></param>
/// <param name="ny"></param>
void sumMatrixOnHost(float* h_a, float* h_b, float* h_c, const int nx, const int ny)
{float* ia = h_a;float* ib = h_b;float* ic = h_c;for (int iy = 0; iy < ny; iy++){for (int ix = 0; ix < nx; ix++) // 处理当前行{ic[ix] = ia[ix] + ib[ix];}ia += nx; ib += nx; ic += nx; // 移动到下一行,ia下一行的第一个索引变成了0.}
}// 去掉循环
__global__ void sumMatrixOnDevice2D(float* d_a, float* d_b, float* d_c, const int nx, const int ny)
{// 二维网格和二维块,映射到矩阵坐标unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;// 由矩阵坐标, 映射到全局坐标(都是线性存储的)unsigned int idx = iy * nx + ix; // 坐标(ix, iy),前面由iy行,每行有nx个元素// 相加if (ix < nx && iy < ny) // 配置线程的可能过多,这里防止越界。{d_c[idx] = d_a[idx] + d_b[idx];}
}void initialData(float* p, const int N)
{//generate different seed from random numbertime_t t;srand((unsigned int)time(&t)); // 生成种子for (int i = 0; i < N; i++){p[i] = (float)(rand() & 0xFF) / 10.0f; // 随机数}
}void checkResult(float* hostRef, float* deviceRef, const int N)
{double eps = 1.0E-8;int match = 1;for (int i = 0; i < N; i++){if (hostRef[i] - deviceRef[i] > eps){match = 0;printf("\nArrays do not match\n");printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i], deviceRef[i], i);break;}}if (match)printf("\nArrays match!\n");
}int main(void)
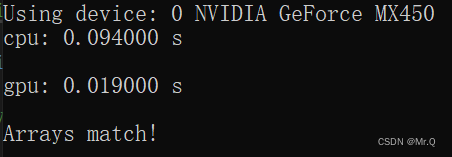
{// get device infoint device = 0;cudaDeviceProp deviceProp;CHECK(cudaGetDeviceProperties(&deviceProp, device));printf("Using device: %d %s", device, deviceProp.name); // 卡号0的显卡名称。CHECK(cudaSetDevice(device)); // 设置显卡号// set matrix dimension. 2^14 = 16384行列数int nx = 1 << 13, ny = 1 << 13, nxy = nx * ny;int nBytes = nxy * sizeof(float);// malloc host memoryfloat* h_a, * h_b, * hostRef, * gpuRef;h_a = (float*)malloc(nBytes);h_b = (float*)malloc(nBytes);hostRef = (float*)malloc(nBytes); // 主机端求得的结果gpuRef = (float*)malloc(nBytes); // 设备端拷回的数据// init datainitialData(h_a, nxy);initialData(h_b, nxy);memset(hostRef, 0, nBytes);memset(gpuRef, 0, nBytes);clock_t begin = clock();// add matrix on host side for result checks.sumMatrixOnHost(h_a, h_b, hostRef, nx, ny);printf("\ncpu: %f s\n", (double)(clock() - begin) / CLOCKS_PER_SEC);// malloc device memoryfloat* d_mat_a, * d_mat_b, * d_mat_c;cudaMalloc((void**)&d_mat_a, nBytes);cudaMalloc((void**)&d_mat_b, nBytes);cudaMalloc((void**)&d_mat_c, nBytes);// transfer data from host to devicecudaMemcpy(d_mat_a, h_a, nBytes, cudaMemcpyHostToDevice);cudaMemcpy(d_mat_b, h_b, nBytes, cudaMemcpyHostToDevice);// configint dimx = 32;int dimy = 32;dim3 block(dimx, dimy); // 二维线程块(x,y)=(4,2)dim3 grid((nx + block.x - 1) / block.x, (ny + block.y - 1) / block.y); // 二维网格(2,3)// 直接nx/block.x = 8/4=2. (8+4-1)/4=2.// invoke kernelbegin = clock();sumMatrixOnDevice2D << <grid, block >> > (d_mat_a, d_mat_b, d_mat_c, nx, ny);CHECK(cudaDeviceSynchronize());printf("\ngpu: %f s\n", (double)(clock() - begin) / CLOCKS_PER_SEC);// check kernel errorCHECK(cudaGetLastError());// copy kernel result back to host sidecudaMemcpy(gpuRef, d_mat_c, nBytes, cudaMemcpyDeviceToHost);// check resultcheckResult(hostRef, gpuRef, nxy);// free memorycudaFree(d_mat_a);cudaFree(d_mat_b);cudaFree(d_mat_c);free(h_a);free(h_b);free(hostRef);free(gpuRef);// reset devicecudaDeviceReset();return 0;
}1.3 运行时间

加法运行速度提高了8倍。数据量越大,提升越明显。
2. 使用一维网格和一维块的矩阵加法

为了使用一维网格和一维块,需要写一个新的核函数,其中每个线程处理ny个数据元素。如上图,一维网格是水平方向的一维,一维块是水平方向的一维。
2.1 关键代码
(1) 建立垂直方向的一维块,再是水平方向一维网格
// config
int dimx = 32;
int dimy = 1;
dim3 block(dimx, dimy); // 一维线程块(x,y)=(32,1),其中每一个线程都处理ny个元素。
// 一维网格((nx+block.x-1)/block.x,1)
dim3 grid((nx + block.x - 1) / block.x, 1);
(2) 前面建立好了一维网格和一维线程块,根据公式去求矩阵索引。
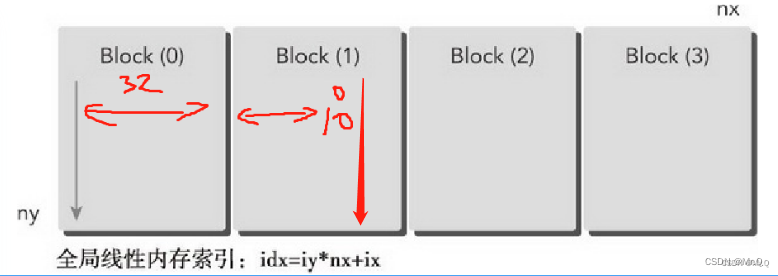
假设blockDim = (32,1). gridDim = (1024,1). 比如当前的threadIdx.x = 10, 由于前面有一个块,当前的位置映射矩阵索引
ix = threadIdx.x + blockIdx.x * blockDim.x = 10 + 1 * 32 = 42
由于一个线程处理ny个元素(所以这里有一个循环,ix不变,iy从第一行开始到ny行)。
__global__ void sumMatrixOnDevice1D(float* d_a, float* d_b, float* d_c, const int nx, const int ny)
{unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;// 一个线程处理ny个数据if (ix < nx){for (int iy = 0; iy < ny; iy++) // 处理ix这一列元素。{int idx = iy * nx + ix; // 第iy行前面有iy*nx个元素,再加上当前行第ix个d_c[idx] = d_a[idx] + d_b[idx];}}
}2.2 完整代码
#include "cuda_runtime.h"
#include "device_launch_parameters.h" // threadIdx#include <stdio.h> // io
#include <time.h> // time_t clock_t
#include <stdlib.h> // rand
#include <memory.h> //memset#define CHECK(call) \
{ \const cudaError_t error_code = call; \if (error_code != cudaSuccess) \{ \printf("CUDA Error:\n"); \printf(" File: %s\n", __FILE__); \printf(" Line: %d\n", __LINE__); \printf(" Error code: %d\n", error_code); \printf(" Error text: %s\n", \cudaGetErrorString(error_code)); \exit(1); \} \
}/// <summary>
/// 矩阵相加,线性存储的二维矩阵
/// </summary>
/// <param name="h_a"></param>
/// <param name="h_b"></param>
/// <param name="h_c"></param>
/// <param name="nx"></param>
/// <param name="ny"></param>
void sumMatrixOnHost(float* h_a, float* h_b, float* h_c, const int nx, const int ny)
{float* ia = h_a;float* ib = h_b;float* ic = h_c;for (int iy = 0; iy < ny; iy++){for (int ix = 0; ix < nx; ix++) // 处理当前行{ic[ix] = ia[ix] + ib[ix];}ia += nx; ib += nx; ic += nx; // 移动到下一行,ia下一行的第一个索引变成了0.}
}// 去掉了循环
__global__ void sumMatrixOnDevice2D(float* d_a, float* d_b, float* d_c, const int nx, const int ny)
{// 二维网格和二维块,映射到矩阵坐标unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;// 由矩阵坐标, 映射到全局坐标(都是线性存储的)unsigned int idx = iy * nx + ix; // 坐标(ix, iy),前面由iy行,每行有nx个元素// 相加if (ix < nx && iy < ny) // 配置线程的可能过多,这里防止越界。{d_c[idx] = d_a[idx] + d_b[idx];}
}__global__ void sumMatrixOnDevice1D(float* d_a, float* d_b, float* d_c, const int nx, const int ny)
{unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;// 一个线程处理ny个数据if (ix < nx){for (int iy = 0; iy < ny; iy++){int idx = iy * nx + ix; // 第iy行前面有iy*nx个元素,再加上当前行第ix个d_c[idx] = d_a[idx] + d_b[idx];}}
}void initialData(float* p, const int N)
{//generate different seed from random numbertime_t t;srand((unsigned int)time(&t)); // 生成种子for (int i = 0; i < N; i++){p[i] = (float)(rand() & 0xFF) / 10.0f; // 随机数}
}void checkResult(float* hostRef, float* deviceRef, const int N)
{double eps = 1.0E-8;int match = 1;for (int i = 0; i < N; i++){if (hostRef[i] - deviceRef[i] > eps){match = 0;printf("\nArrays do not match\n");printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i], deviceRef[i], i);break;}}if (match)printf("\nArrays match!\n");
}int main(void)
{// get device infoint device = 0;cudaDeviceProp deviceProp;CHECK(cudaGetDeviceProperties(&deviceProp, device));printf("Using device: %d %s", device, deviceProp.name); // 卡号0的显卡名称。CHECK(cudaSetDevice(device)); // 设置显卡号// set matrix dimension. 2^14 = 16384行列数int nx = 1 << 13, ny = 1 << 13, nxy = nx * ny;int nBytes = nxy * sizeof(float);// malloc host memoryfloat* h_a, * h_b, * hostRef, * gpuRef;h_a = (float*)malloc(nBytes);h_b = (float*)malloc(nBytes);hostRef = (float*)malloc(nBytes); // 主机端求得的结果gpuRef = (float*)malloc(nBytes); // 设备端拷回的数据// init datainitialData(h_a, nxy);initialData(h_b, nxy);memset(hostRef, 0, nBytes);memset(gpuRef, 0, nBytes);clock_t begin = clock();// add matrix on host side for result checks.sumMatrixOnHost(h_a, h_b, hostRef, nx, ny);printf("\ncpu: %f s\n", (double)(clock() - begin) / CLOCKS_PER_SEC);// malloc device memoryfloat* d_mat_a, * d_mat_b, * d_mat_c;cudaMalloc((void**)&d_mat_a, nBytes);cudaMalloc((void**)&d_mat_b, nBytes);cudaMalloc((void**)&d_mat_c, nBytes);// transfer data from host to devicecudaMemcpy(d_mat_a, h_a, nBytes, cudaMemcpyHostToDevice);cudaMemcpy(d_mat_b, h_b, nBytes, cudaMemcpyHostToDevice);// configint dimx = 32;int dimy = 1;dim3 block(dimx, dimy); // 一维线程块(x,y)=(32,1),其中每一个线程都处理ny个元素。dim3 grid((nx + block.x - 1) / block.x, 1); // 一维网格((nx+block.x-1)/block.x,1)// invoke kernelbegin = clock();//sumMatrixOnDevice2D << <grid, block >> > (d_mat_a, d_mat_b, d_mat_c, nx, ny);sumMatrixOnDevice1D << <grid, block >> > (d_mat_a, d_mat_b, d_mat_c, nx, ny);CHECK(cudaDeviceSynchronize());printf("\ngpu: %f s\n", (double)(clock() - begin) / CLOCKS_PER_SEC);// check kernel errorCHECK(cudaGetLastError());// copy kernel result back to host sidecudaMemcpy(gpuRef, d_mat_c, nBytes, cudaMemcpyDeviceToHost);// check resultcheckResult(hostRef, gpuRef, nxy);// free memorycudaFree(d_mat_a);cudaFree(d_mat_b);cudaFree(d_mat_c);free(h_a);free(h_b);free(hostRef);free(gpuRef);// reset devicecudaDeviceReset();return 0;
}2.3 运行时间

3. 使用二维网格和一维块的矩阵矩阵加法
当使用一个包含一维块的二维网格时,每个线程都只关注一个数据元素并且网格的第二个维数等于ny。比如块的维度是(32,1),网格的维度是((nx+32-1)/32, (ny+1-1)/1) = ((nx+32-1)/32, ny).
这可以看作是含有一个二维块的二维网格的特殊情况,其中块的第二个维数是1.

利用块和网格索引,映射矩阵索引,如上图,blockIdx.y等于矩阵索引iy:
ix = threadIdx.x + blockIdx.x * blockDim.x;
iy = threadIdx.y + blockIdx.y * blockDim.y = threadIdx.y + 0 * 1 = threadIdx.y
再利用矩阵索引,映射全局内存索引:
idx = iy * nx + ix; // 当前行iy,块外的前面有iy * nx个元素,块内索引是ix
3.1 关键代码
(1) 建立一维线程块和二维网格
// config
int dimx = 32;
int dimy = 1;
dim3 block(dimx, dimy); // 一维线程块(x,y)=(32,1),其中每一个线程都处理一个元素。
// ((nx+32-1)/32, (ny+1-1)/1) = ((nx+32-1)/32, ny)
dim3 grid((nx + block.x - 1) / block.x, ny);(2)利用块和网格索引,映射矩阵索引,再映射全局内存索引
__global__ void sumMatrixOnDevice2DGrid1DBlock(float* d_a, float* d_b, float* d_c, const int nx, const int ny)
{unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;unsigned int iy = blockIdx.y; // threadIdx.y + blockIdx.y * blockDim.y = threadIdx.y + 0 * 1unsigned int idx = iy * nx + ix;if (ix < nx && iy < ny){d_c[idx] = d_a[idx] + d_b[idx];}
}3.2 完整代码
#include "cuda_runtime.h"
#include "device_launch_parameters.h" // threadIdx#include <stdio.h> // io
#include <time.h> // time_t clock_t
#include <stdlib.h> // rand
#include <memory.h> //memset#define CHECK(call) \
{ \const cudaError_t error_code = call; \if (error_code != cudaSuccess) \{ \printf("CUDA Error:\n"); \printf(" File: %s\n", __FILE__); \printf(" Line: %d\n", __LINE__); \printf(" Error code: %d\n", error_code); \printf(" Error text: %s\n", \cudaGetErrorString(error_code)); \exit(1); \} \
}/// <summary>
/// 矩阵相加,线性存储的二维矩阵
/// </summary>
/// <param name="h_a"></param>
/// <param name="h_b"></param>
/// <param name="h_c"></param>
/// <param name="nx"></param>
/// <param name="ny"></param>
void sumMatrixOnHost(float* h_a, float* h_b, float* h_c, const int nx, const int ny)
{float* ia = h_a;float* ib = h_b;float* ic = h_c;for (int iy = 0; iy < ny; iy++){for (int ix = 0; ix < nx; ix++) // 处理当前行{ic[ix] = ia[ix] + ib[ix];}ia += nx; ib += nx; ic += nx; // 移动到下一行,ia下一行的第一个索引变成了0.}
}// 去掉了循环
__global__ void sumMatrixOnDevice2D(float* d_a, float* d_b, float* d_c, const int nx, const int ny)
{// 二维网格和二维块,映射到矩阵坐标unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;unsigned int iy = threadIdx.y + blockIdx.y * blockDim.y;// 由矩阵坐标, 映射到全局坐标(都是线性存储的)unsigned int idx = iy * nx + ix; // 坐标(ix, iy),前面由iy行,每行有nx个元素// 相加if (ix < nx && iy < ny) // 配置线程的可能过多,这里防止越界。{d_c[idx] = d_a[idx] + d_b[idx];}
}__global__ void sumMatrixOnDevice1D(float* d_a, float* d_b, float* d_c, const int nx, const int ny)
{unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;// 一个线程处理ny个数据if (ix < nx){for (int iy = 0; iy < ny; iy++){int idx = iy * nx + ix; // 第iy行前面有iy*nx个元素,再加上当前行第ix个d_c[idx] = d_a[idx] + d_b[idx];}}
}__global__ void sumMatrixOnDevice2DGrid1DBlock(float* d_a, float* d_b, float* d_c, const int nx, const int ny)
{unsigned int ix = threadIdx.x + blockIdx.x * blockDim.x;unsigned int iy = blockIdx.y; // threadIdx.y + blockIdx.y * blockDim.y = threadIdx.y + 0 * 1unsigned int idx = iy * nx + ix;if (ix < nx && iy < ny){d_c[idx] = d_a[idx] + d_b[idx];}
}void initialData(float* p, const int N)
{//generate different seed from random numbertime_t t;srand((unsigned int)time(&t)); // 生成种子for (int i = 0; i < N; i++){p[i] = (float)(rand() & 0xFF) / 10.0f; // 随机数}
}void checkResult(float* hostRef, float* deviceRef, const int N)
{double eps = 1.0E-8;int match = 1;for (int i = 0; i < N; i++){if (hostRef[i] - deviceRef[i] > eps){match = 0;printf("\nArrays do not match\n");printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i], deviceRef[i], i);break;}}if (match)printf("\nArrays match!\n");
}int main(void)
{// get device infoint device = 0;cudaDeviceProp deviceProp;CHECK(cudaGetDeviceProperties(&deviceProp, device));printf("Using device: %d %s", device, deviceProp.name); // 卡号0的显卡名称。CHECK(cudaSetDevice(device)); // 设置显卡号// set matrix dimension. 2^14 = 16384行列数int nx = 1 << 13, ny = 1 << 13, nxy = nx * ny;int nBytes = nxy * sizeof(float);// malloc host memoryfloat* h_a, * h_b, * hostRef, * gpuRef;h_a = (float*)malloc(nBytes);h_b = (float*)malloc(nBytes);hostRef = (float*)malloc(nBytes); // 主机端求得的结果gpuRef = (float*)malloc(nBytes); // 设备端拷回的数据// init datainitialData(h_a, nxy);initialData(h_b, nxy);memset(hostRef, 0, nBytes);memset(gpuRef, 0, nBytes);clock_t begin = clock();// add matrix on host side for result checks.sumMatrixOnHost(h_a, h_b, hostRef, nx, ny);printf("\ncpu: %f s\n", (double)(clock() - begin) / CLOCKS_PER_SEC);// malloc device memoryfloat* d_mat_a, * d_mat_b, * d_mat_c;cudaMalloc((void**)&d_mat_a, nBytes);cudaMalloc((void**)&d_mat_b, nBytes);cudaMalloc((void**)&d_mat_c, nBytes);// transfer data from host to devicecudaMemcpy(d_mat_a, h_a, nBytes, cudaMemcpyHostToDevice);cudaMemcpy(d_mat_b, h_b, nBytes, cudaMemcpyHostToDevice);// configint dimx = 32;int dimy = 1;dim3 block(dimx, dimy); // 一维线程块(x,y)=(32,1),其中每一个线程都处理一个元素。// ((nx+32-1)/32, (ny+1-1)/1) = ((nx+32-1)/32, ny)dim3 grid((nx + block.x - 1) / block.x, ny);// invoke kernelbegin = clock();//sumMatrixOnDevice2D << <grid, block >> > (d_mat_a, d_mat_b, d_mat_c, nx, ny); //sumMatrixOnDevice1D << <grid, block >> > (d_mat_a, d_mat_b, d_mat_c, nx, ny);sumMatrixOnDevice2DGrid1DBlock << <grid, block >> > (d_mat_a, d_mat_b, d_mat_c, nx, ny);CHECK(cudaDeviceSynchronize());printf("\ngpu: %f s\n", (double)(clock() - begin) / CLOCKS_PER_SEC);// check kernel errorCHECK(cudaGetLastError());// copy kernel result back to host sidecudaMemcpy(gpuRef, d_mat_c, nBytes, cudaMemcpyDeviceToHost);// check resultcheckResult(hostRef, gpuRef, nxy);// free memorycudaFree(d_mat_a);cudaFree(d_mat_b);cudaFree(d_mat_c);free(h_a);free(h_b);free(hostRef);free(gpuRef);// reset devicecudaDeviceReset();return 0;
}3.3 运行时间