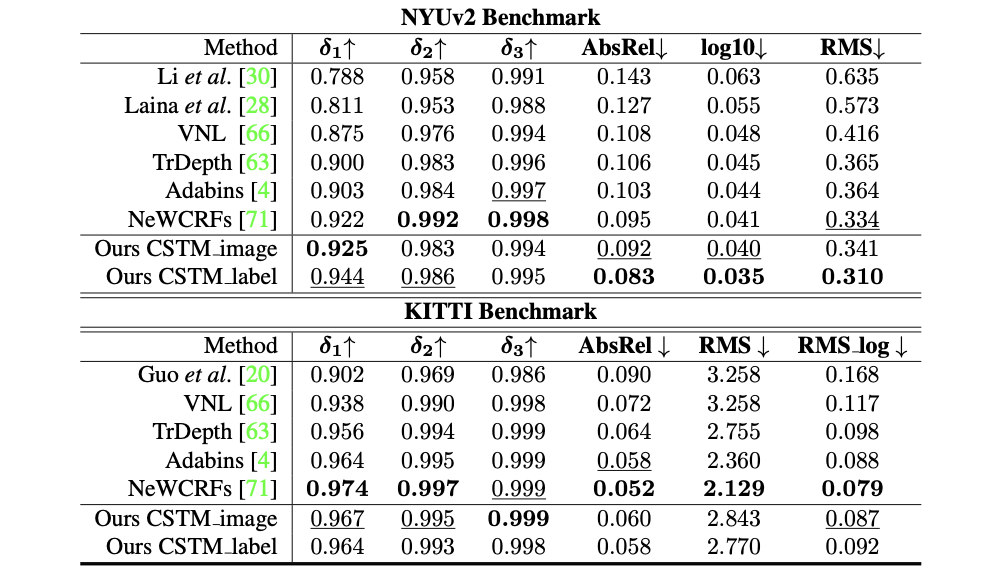
在上一篇博文《基于facenet+faiss开发构建人脸识别系统》中,我们实践了基于facenet和faiss的人脸识别系统开发,基于facenet后续提出来很多新的改进的网络模型,arcFace就是其中一款优秀的网络模型,本文的整体开发实现流程与前文相同,只是在深度学习模型节点上将facenet替换为了arcFace网络模型,整体流程示意图如下所示:
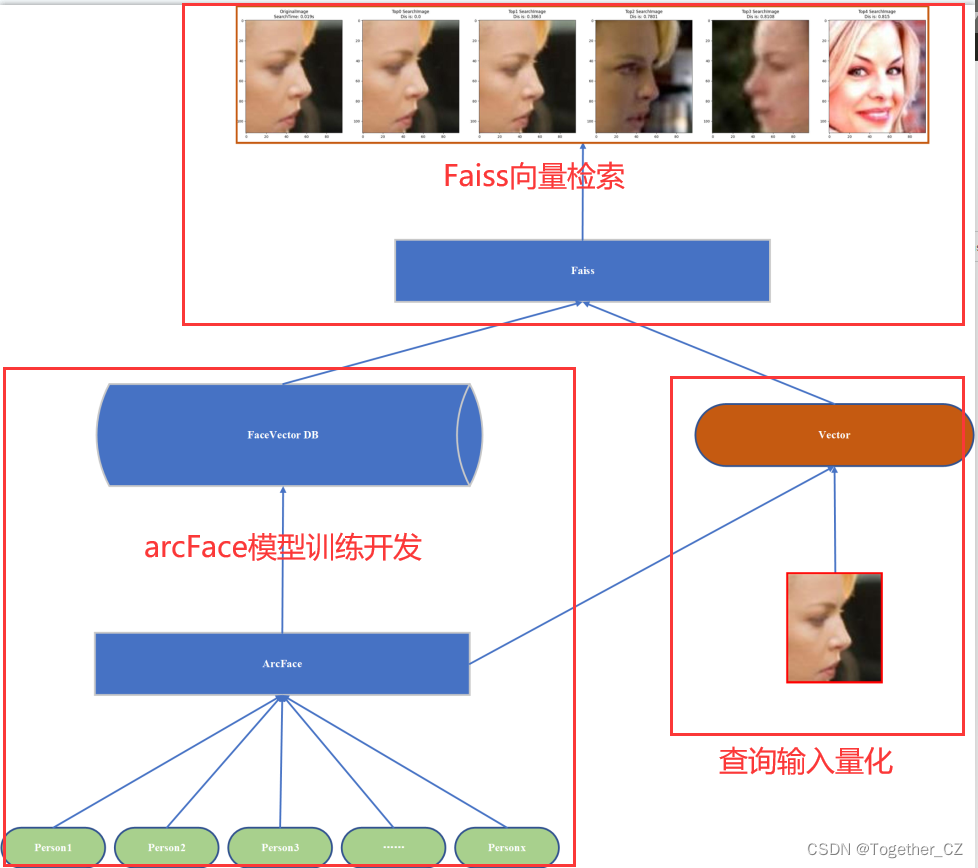
整体的思路还是比较清晰明了的。
接下来先简单回顾一下相关技术原理。
ArcFace是一种人脸识别模型,它是基于深度学习的卷积神经网络构建的。ArcFace模型在人脸识别领域具有很高的准确性和可靠性,广泛应用于人脸识别技术和安全系统中。
ArcFace模型的核心思想是通过学习将人脸图像映射到一个高维特征空间中的稠密特征表示。它采用余弦距离作为判别指标,使得同一个人的人脸特征向量之间的余弦距离较小,不同人的人脸特征向量之间的余弦距离较大。通过训练过程,模型可以学习到人脸的判别性特征,实现人脸之间的区分和识别。
ArcFace模型的优点有以下几个方面:
-
准确性高:ArcFace在常见的人脸识别任务中取得了非常好的性能,能够实现高准确性的人脸匹配和识别。
-
抗干扰能力强:ArcFace模型在面对光照变化、表情变化、遮挡等干扰因素时,仍能保持较高的稳定性和可靠性,对人脸图像的变化有较好的适应性。
-
特征嵌入明显:ArcFace模型通过学习得到的人脸特征向量在高维空间中有较明显的嵌入效果,同一个人的人脸特征向量距离较近,不同人的特征向量距离较远,增加了模型的判别力。
然而,ArcFace模型也存在一些缺点:
-
复杂性高:ArcFace模型相比其他简单的人脸识别模型,比如FaceNet,模型结构更加复杂,需要更大的计算资源和更长的训练时间。
-
数据依赖性强:ArcFace模型的性能与训练数据的质量和数量密切相关,需要大规模的人脸数据集进行训练,从而使模型具有更好的泛化能力。
-
隐私问题:由于ArcFace模型具有较强的人脸识别能力,潜在的隐私问题也随之出现。在应用和部署过程中,需要遵循隐私保护的原则和规定。
ArcFace模型以其高准确性和鲁棒性在人脸识别领域占据重要地位,但在实际应用中也需要考虑到模型复杂性、数据依赖性和隐私问题。
Faiss是一种用于高效相似性搜索的库,由Facebook人工智能研究实验室开发。它基于近似最近邻(Approximate Nearest Neighbor, ANN)算法,旨在解决大规模数据集的相似性搜索问题。Faiss可以在GPU和CPU上运行,并提供了多种近似搜索算法和索引结构。
Faiss的主要构建原理是使用索引结构对数据进行预处理,以便于在搜索时快速定位到相似的数据点。下面是Faiss的主要特点和优势:
高效:Faiss通过高度优化的算法和索引结构,实现了非常高效的相似性搜索。它可以处理包含数百万或上亿个数据点的大规模数据集。
支持多种索引算法:Faiss提供多种索引算法,包括快速扫描、k-means、倒排文件等等。这些算法可以针对不同的数据特点和搜索需求选择最合适的索引结构,以提高搜索性能。
可扩展性:Faiss可以在单个GPU或多个GPU上运行,并且支持分布式计算。这使得它能够有效地处理大规模数据集并实现快速搜索。
索引更新和存储:Faiss允许动态地更新索引结构,可以添加、删除或修改数据点。此外,Faiss还提供了存储和加载索引结构的功能,方便在不同环境中使用。
多种语言支持:Faiss支持多种编程语言接口,如C++、Python等,使得它在不同的开发环境下都易于使用和集成。
Faiss算法的一些缺点包括:
近似性:Faiss提供的是近似最近邻搜索,并不保证精确的最近邻搜索结果。虽然近似搜索能够在处理大规模数据时显著提高搜索速度,但在对结果的准确性有严格要求的应用中,可能需要使用精确搜索算法。
参数调优:Faiss中的索引算法有多个参数需要调整,以获得最佳的搜索性能。对于不熟悉Faiss的用户来说,可能需要一些实验和调优才能找到最优的配置。
存储需求:基于索引结构的相似性搜索常常需要占用较大的存储空间,尤其是当数据集非常大时。这可能对存储资源造成压力。
接下来我们来实现自己的想法,arcFace模型可以直接使用官方开源项目即可,这里我就不再自己训练了,直接使用了网上开源的模型,自己搜索就有很多的,选择合适自己使用的即可,接下来就是要实现人脸向量数据库的构建,核心实现如下所示:
def batch2Vec(picDir="datasets/", saveDir="vector/"):"""批量数据向量化处理"""if not os.path.exists(saveDir):os.makedirs(saveDir)feature=[]person={}count=0for one_person in os.listdir(picDir):oneDir=picDir+one_person+"/"print("one_person: ", one_person, ", one_num: ", len(os.listdir(oneDir)), ", count: ", count)for one_pic in os.listdir(oneDir):one_path=oneDir+one_picone_vec=sinleImg2Vec(pic_path=one_path)if one_person in person:person[one_person].append([one_pic, one_vec])else:person[one_person]=[[one_pic, one_vec]]feature.append([one_path, one_vec])count+=1print("feature_length: ", len(feature))with open(saveDir+"faceDB.json", "w") as f:f.write(json.dumps(feature))with open(saveDir+"person.json", "w") as f:f.write(json.dumps(person))终端计算输出如下所示:
向量数据计算完成如下所示:
之后我们就可以基于人脸向量数据库来构建faiss索引,输入单个查询向量来进行计算了,核心实现如下所示:
#检索计算
start=time.time()
distances, indexs = index.search(query, topK)
print("distances_shape: ", distances.shape)
print("indexs_shape: ", indexs.shape)
end=time.time()
delta=round(end-start, 4)
#对比可视化
plt.clf()
plt.figure(figsize=(36,6))
plt.subplot(1,6,1)
plt.imshow(Image.open(pic_path))
plt.title("OriginalImage\nSearchTime: "+str(delta)+"s")
indexs=indexs.tolist()[0]
print("indexs: ", indexs)
for i in range(len(indexs)):one_ind=indexs[i]plt.subplot(1,6,i+2)plt.imshow(Image.open(images[one_ind]))one_dis= distance(query, vectors[one_ind])plt.title("Top"+str(i)+" SearchImage\nDis is: "+str(round(one_dis, 4)))
plt.savefig("compare.jpg")同前文是一致的,这里也是保证了接口数据的一致,所以faiss模块的逻辑可以复用。
接下来看下实际检索效果:
【查询输入】

【检索输出】

【查询输入】

【检索输出】

【查询输入】

【检索输出】

【查询输入】

【检索输出】
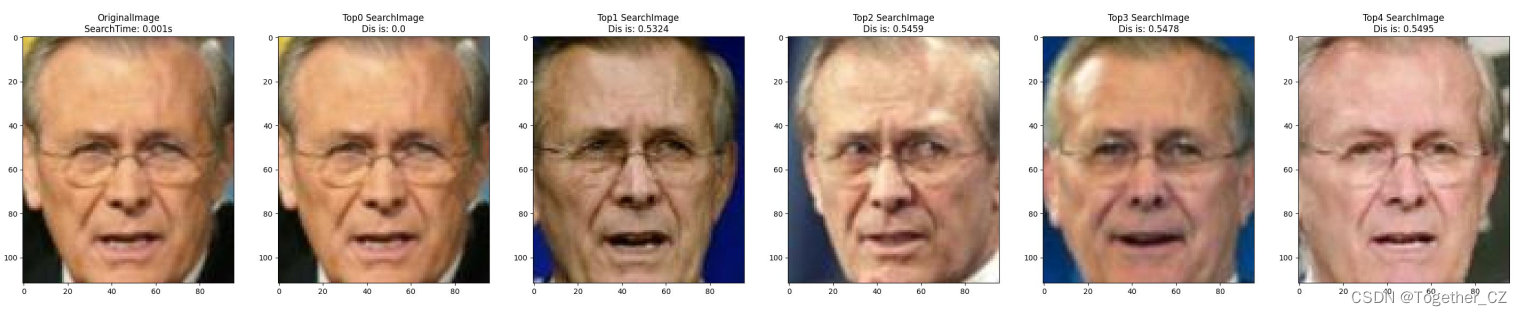
【查询输入】

【检索输出】

整体来看效果还是非常不错的,而且整体的时耗也是很出色的。
下一篇文章中,我会对faiss的时耗进行实验分析。

![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)](https://img-blog.csdnimg.cn/9220d7cfb95244bc8d7053d6e4cf36d7.png)