1. requests 模块post 函数
1.1 post 函数的参数 (简单版)
参数1: url 网络地址
参数2: data 请求数据 (一般数据是 账号,密码)
参数3: headers 头请求 (User-Agent: 第一章讲过)
1.2 post 请求中 url 参数的获取
1.2.1 首先 打开一个 登录界面 。(这里以淘宝的登录界面为样例)
1.2.2 打开控制界面 。(点击F12 ,或者右键检查)
1.2.3 点击网络。 再点击下一行的 全部(all)
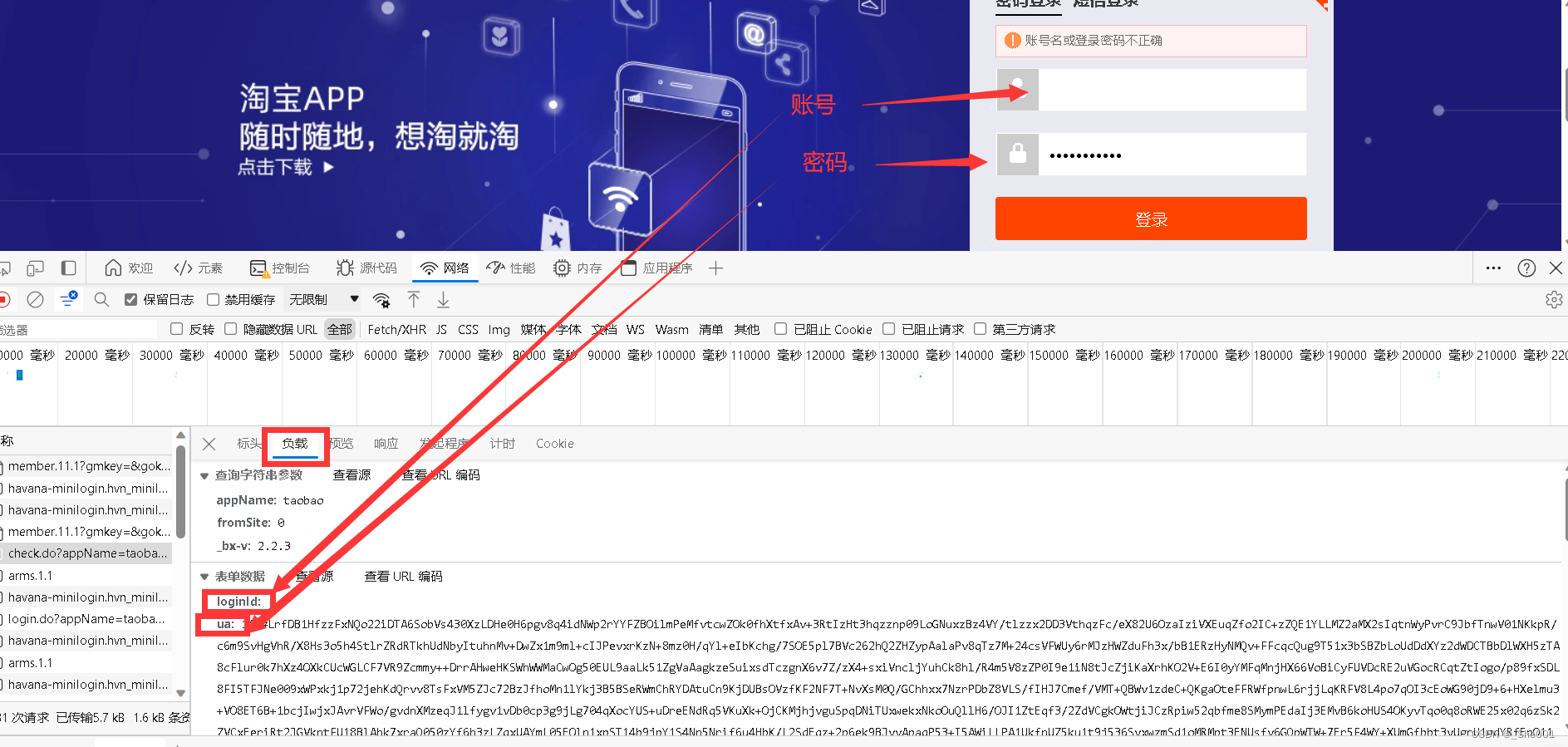
1.2.4 点击登录界面的 账号输入的地方,获取一个 Ping 。
1.2.5 点击网络下面的链接,进入post 数据界面。
1.2.6 观看和获取 URL 数据。

1.3 post 请求中 data参数的 名字命名 (或者说是 data字典类型数据的 key 名字)
1. 在淘宝登录界面输入账号密码
2. 点击登录界面。
3. 打开控制界面 -> 网络 --> 点击包含check 的链接 --> 点击负载 -- > 观看参数的名字
2.lxml 模块
2.1 lxml 模块的简介
lxml模块 是python的一个解析库,支持HTML和XML解析,同时支持XPath解析方式。Lxml的解析速率相较BeautifulSoup更高,后者学习相较更简单。
功能:用于解析HTML与XML文件;进行文件读取;etree和Xpath的配合使用
2.2 lxml 模块的使用
主要是 Xpath 对于 HTML的解析
推荐文章:Python爬虫基础教程——lxml爬取入门 - 知乎 (zhihu.com)
参考文章: lxml模块详解_手工&自动化测试开发小白的博客-CSDN博客
参考文章:XPath用法及常用函数_xpath 函数_SeeUa的博客-CSDN博客
2.3 函数 Xpath的使用 (看参考文章)
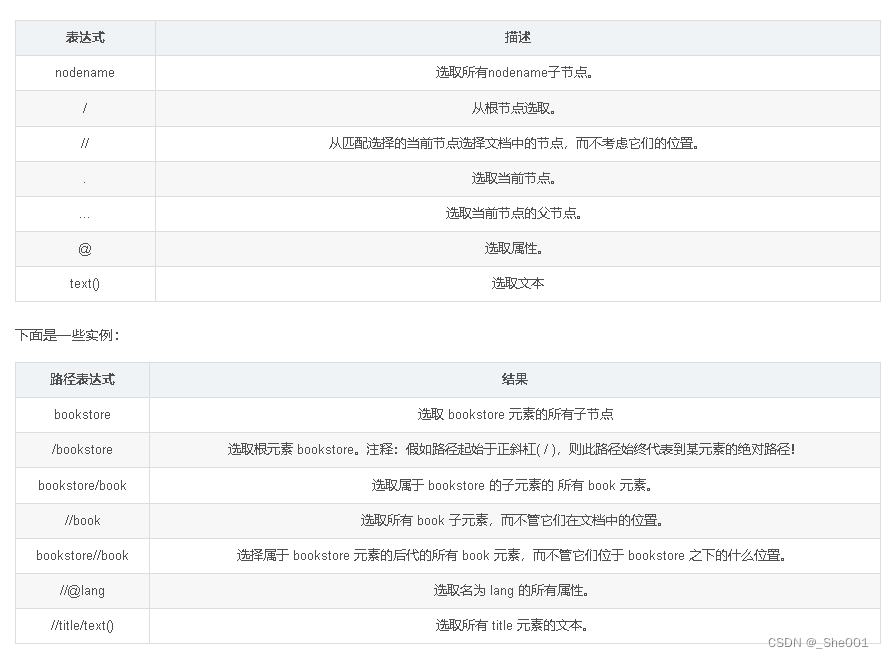
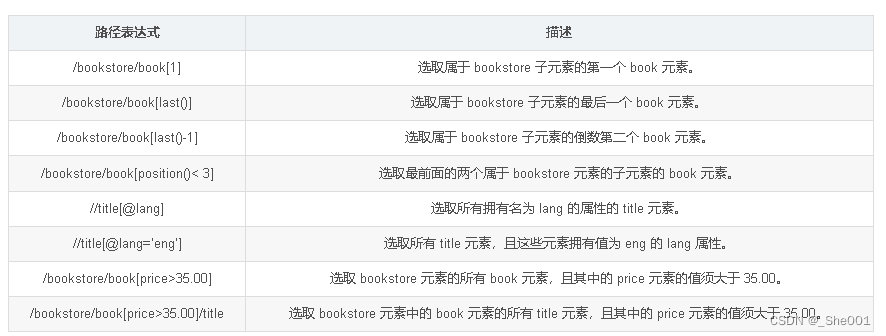
参考文章:Xpath 用法总结_xpath //_free_xiaochen的博客-CSDN博客
参考文章:Xpath 用法总结_xpath //_free_xiaochen的博客-CSDN博客
2.4 样例代码 (帮我找找 bug ,我的 xpath没有找到所有的数据)
import requests # http 请求函数的库
import chardet #chardet 支持检测中文、日文、韩文等多种语言 和 字符串编码 函数库
from lxml import etreeheaders1 = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.188"}
url = 'https://cn.bing.com/images/search?q=%E5%9B%BE%E7%89%87&form=IQFRBA&id=4929EB0212CFAC8CB6AB59DB53A9D2D99C54FF6A&first=1&disoverlay=1' #图片的网站
response = requests.get(url)
#print(response)
selector =etree.HTML(response.text)
s = selector.xpath('//img/@src')
for x in s:print(x)

![综合与新综合与新型交通发展趋势[75页PPT]](https://img-blog.csdnimg.cn/img_convert/701650afebe9fab3ab719faca4524a6e.jpeg)