一、说明
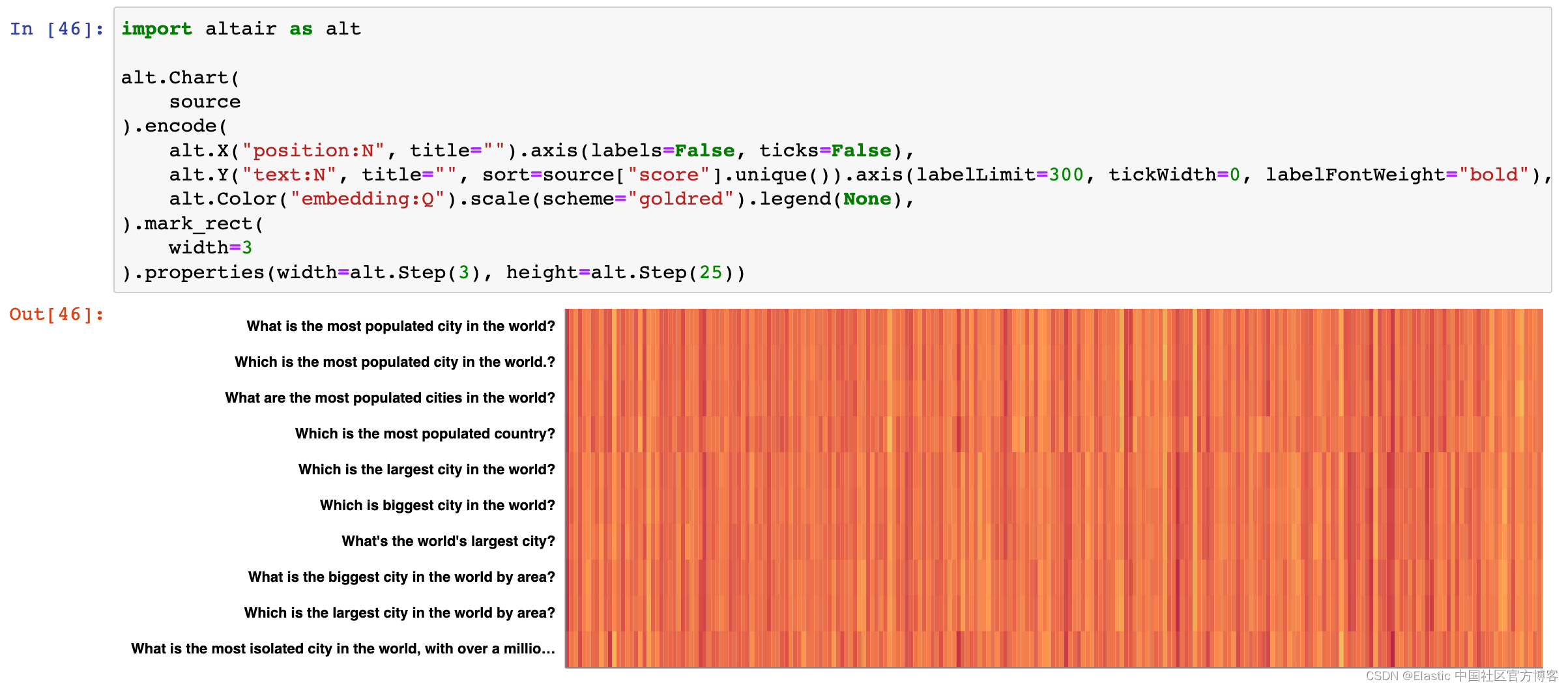
在 10年的深度学习中,进步是多么迅速!早在 2012 年,Alexnet 在 ImageNet 上的准确率就达到了 63.3% 的 Top-1。现在,我们超过90%的EfficientNet架构和师生训练(teacher-student)。
如果我们在 Imagenet 上绘制所有报告作品的准确性,我们会得到这样的结果:
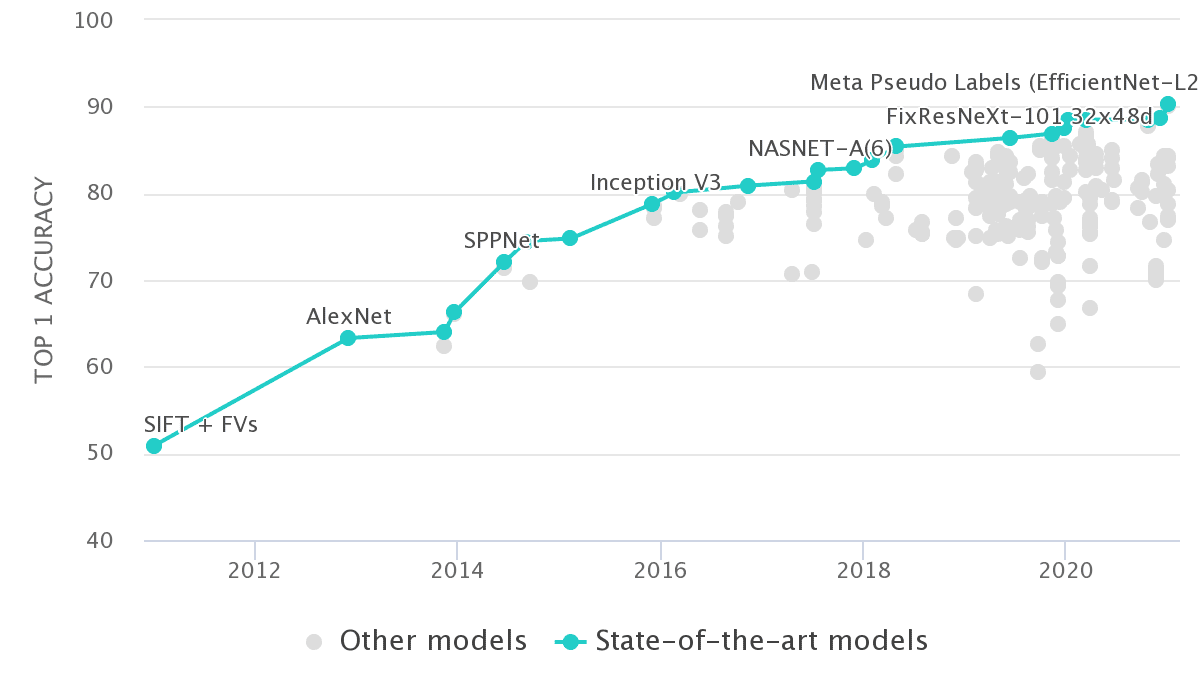
来源:Papers with Code - Imagenet Benchmark
在本文中,我们将重点介绍卷积神经网络(CNN)架构的演变。我们将专注于基本原则,而不是报告简单的数字。为了提供另一种视觉概览,可以在单个图像中捕获2018年之前表现最佳的CNN:
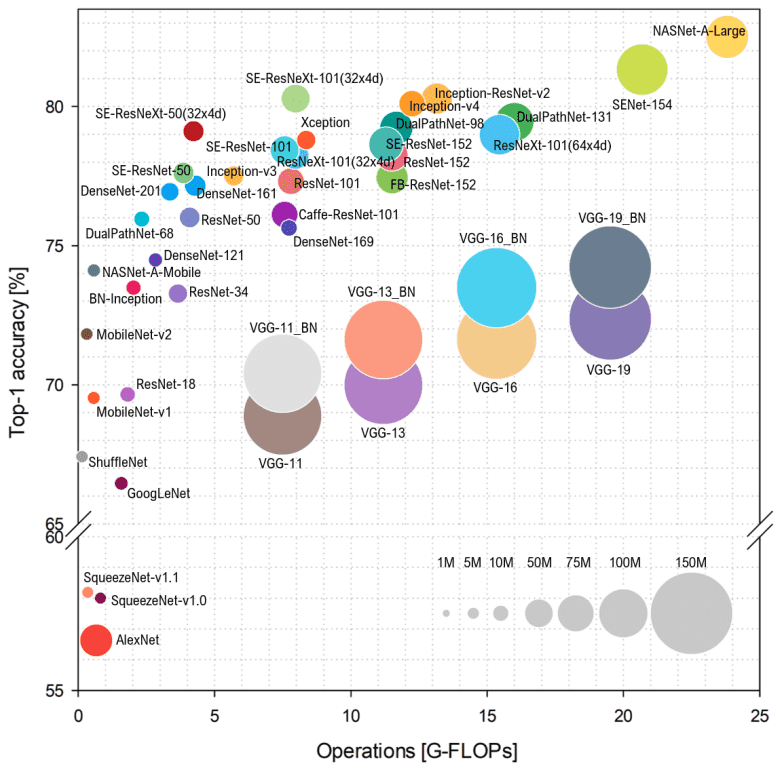
截至 2018 年的架构概述。资料来源:Simone Bianco et al. 2018
不要惊慌失措。所有描述的体系结构都基于我们将要描述的概念。
请注意,每秒浮点运算数 (FLOP) 表示模型的复杂性,而在垂直轴上,我们有 Imagenet 精度。圆的半径表示参数的数量。
从上图中可以看出,更多的参数并不总是能带来更好的准确性。我们将尝试对CNN进行更广泛的思考,看看为什么这是正确的。
如果您想从头开始了解卷积的工作原理,请推荐 Andrew 的 Ng 课程。
二、第一阶段:CNN架构的递进
2.1 术语解释
但首先,我们必须定义一些术语:
-
更宽的网络意味着卷积层中更多的特征图(过滤器)
-
更深的网络意味着更多的卷积层
-
具有更高分辨率的网络意味着它处理具有更大宽度和深度(空间分辨率)的输入图像。这样,生成的特征图将具有更高的空间维度。
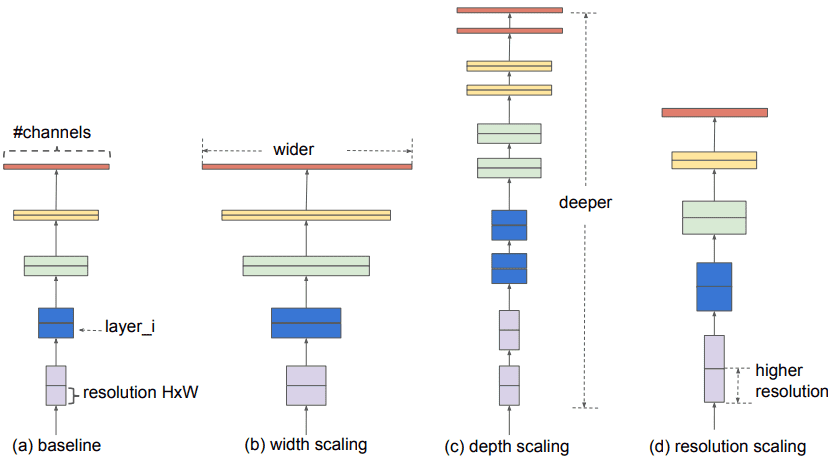
架构扩展。来源:谭明兴,Quoc V. Le 2019
架构工程就是关于扩展的。我们将彻底使用这些术语,因此在继续之前请务必理解它们。
2.2 AlexNet: ImageNet Classification with Deep Convolutional Neural Networks (2012)
Alexnet [1] 由 5 个从 11x11 内核开始的卷积层组成。它是第一个采用最大池化层、ReLu 激活函数和 3 个巨大线性层的 dropout 的架构。该网络用于具有 1000 个可能类的图像分类,这在当时是疯狂的。现在,您可以在 35 行 PyTorch 代码中实现它:
class AlexNet(nn.Module):def __init__(self, num_classes: int = 1000) -> None:super(AlexNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(64, 192, kernel_size=5, padding=2),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),nn.Conv2d(192, 384, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=3, stride=2),)self.avgpool = nn.AdaptiveAvgPool2d((6, 6))self.classifier = nn.Sequential(nn.Dropout(),nn.Linear(256 * 6 * 6, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Linear(4096, num_classes),)def forward(self, x: torch.Tensor) -> torch.Tensor:x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return x这是第一个在 Imagenet 上成功训练的卷积模型,当时在 CUDA 中实现这样的模型要困难得多。Dropout 在巨大的线性变换中大量使用,以避免过度拟合。在 2015-2016 年自动微分出现之前,在 GPU 上实现反向传播需要几个月的时间。
2.3 VGG (2014)
著名的论文“用于大规模图像识别的非常深度卷积网络”[2]使深度一词病毒式传播。这是第一项提供不可否认证据的研究,证明简单地添加更多层可以提高性能。尽管如此,这一假设在一定程度上是正确的。为此,他们只使用3x3内核,而不是AlexNet。该架构使用 224 × 224 个 RGB 图像进行训练。
主要原理是一叠三3×3 转换层类似于单个7×7 层。甚至可能更好!因为它们在两者之间使用三个非线性激活(而不是一个),这使得函数更具鉴别性。
其次,这种设计减少了参数的数量。具体来说,您需要 权重,与7×7 需要的转换层
参数(增加 81%)。
直观地,它可以被视为对7×7 转换过滤器,限制它们具有 3x3 非线性分解。最后,这是规范化开始成为一个相当成问题的架构。
尽管如此,预训练的VGG仍然用于生成对抗网络中的特征匹配损失,以及神经风格转移和特征可视化。
以我的拙见,检查凸网相对于输入的特征非常有趣,如以下视频所示:
最后,在Alexnet旁边进行视觉比较:
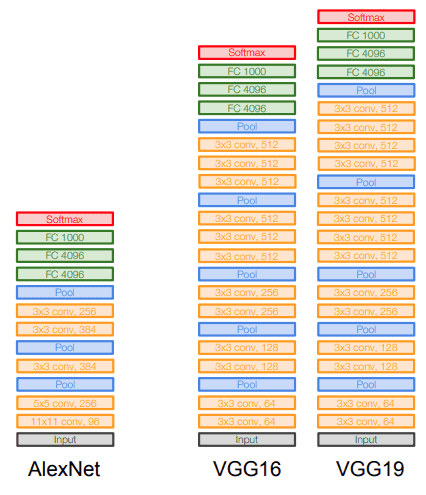
来源:斯坦福大学2017年深度学习讲座:CNN架构
2.4 InceptionNet/GoogleNet (2014)
在VGG之后,Christian Szegedy等人的论文“Go Deep with Convolutions”[3]是一个巨大的突破。
动机:增加深度(层数)并不是使模型变大的唯一方法。如何增加网络的深度和宽度,同时将计算保持在恒定的水平?
这一次的灵感来自人类视觉系统,其中信息在多个尺度上进行处理,然后在本地聚合[3]。如何在不发生记忆爆炸的情况下实现这一目标?
答案是1×1 卷 积!主要目的是通过减少每个卷积块的输出通道来减小尺寸。然后我们可以处理具有不同内核大小的输入。只要填充输出,它就与输入相同。
要找到具有单步幅且无扩张的合适填充,请填充p和内核k被定义为(输入和输出空间调光):
,这意味着
.在 Keras 中,您只需指定 padding='same'。这样,我们可以连接与不同内核卷积的特征。
然后我们需要1×1 卷积层将特征“投影”到更少的通道,以赢得计算能力。有了这些额外的资源,我们可以添加更多的层。实际上,1×1 convs 的工作方式类似于低维嵌入。
有关 1x1 转换的快速概述,请推荐来自著名 Coursera 课程的以下视频:
这反过来又允许通过使用Inception模块不仅增加深度,而且增加著名的GoogleNet的宽度。核心构建块称为 inception 模块,如下所示:
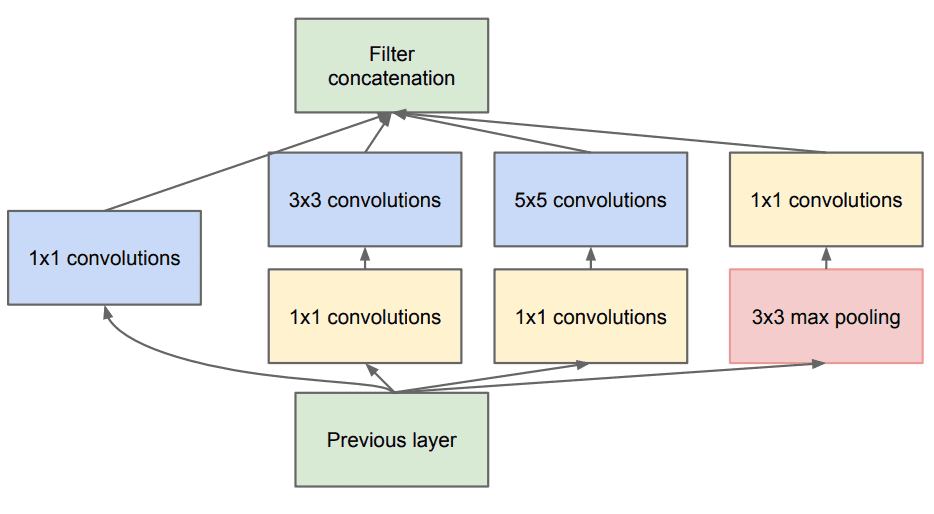
整个架构被称为GoogLeNet或InceptionNet。从本质上讲,作者声称他们试图用正常的密集层近似稀疏的凸网(如图所示)。
为什么?因为他们相信只有少数神经元是有效的。这符合Hebbian原则:“一起放电的神经元,连接在一起”。
此外它使用不同内核大小的卷积(5×55×5,3×33×3,1×11×1) 以捕获多个比例下的细节.
通常,对于驻留在全局的信息,首选较大的内核,对于本地分发的信息,首选较小的内核。
此外1×1 卷积用于在计算成本高昂的卷积(3×3 和 5×5)之前计算约简。
InceptionNet/GoogLeNet架构由9个堆叠在一起的初始模块组成,其间有最大池化层(将空间维度减半)。它由 22 层组成(27 层带有池化层)。它在上次启动模块之后使用全局平均池化。
我写了一个非常简单的 Inception 块实现,可能会澄清一些事情:
import torch
import torch.nn as nnclass InceptionModule(nn.Module):def __init__(self, in_channels, out_channels):super(InceptionModule, self).__init__()relu = nn.ReLU()self.branch1 = nn.Sequential(nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0),relu)conv3_1 = nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)conv3_3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)self.branch2 = nn.Sequential(conv3_1, conv3_3,relu)conv5_1 = nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)conv5_5 = nn.Conv2d(out_channels, out_channels, kernel_size=5, stride=1, padding=2)self.branch3 = nn.Sequential(conv5_1,conv5_5,relu)max_pool_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)conv_max_1 = nn.Conv2d(in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0)self.branch4 = nn.Sequential(max_pool_1, conv_max_1,relu)def forward(self, input):output1 = self.branch1(input)output2 = self.branch2(input)output3 = self.branch3(input)output4 = self.branch4(input)return torch.cat([output1, output2, output3, output4], dim=1)model = InceptionModule(in_channels=3,out_channels=32)
inp = torch.rand(1,3,128,128)
print(model(inp).shape)
torch.Size([1, 128, 128, 128])当然,您可以在激活函数之前添加规范化层。但由于归一化技术不是很成熟,作者引入了两个辅助分类器。原因是:梯度消失问题)。
2.5 Inception V2, V3 (2015)
后来,在论文“重新思考计算机视觉的初始体系结构”中,作者基于以下原则改进了Inception模型:
-
将 5x5 和 7x7(在 InceptionV3 中)卷积分别分解为两个和三个 3x3 顺序卷积。这提高了计算速度。这与 VGG 的原理相同。
-
他们使用了空间上可分的卷积。简单地说,一个 3x3 内核被分解为两个较小的内核:一个 1x3 和一个 3x1 内核,它们按顺序应用。
-
初始模块变得更宽(更多特征图)。
-
他们试图在网络的深度和宽度之间以平衡的方式分配计算预算。
-
他们添加了批量规范化。
inception 模型的更高版本是 InceptionV4 和 Inception-Resnet。
2.6 ResNet:用于图像识别的深度残差学习(2015)
所有预先描述的问题(例如梯度消失)都通过两个技巧得到解决:
-
批量归一化和
-
短跳跃连接
而不是 ,我们要求他们模型学习差异(残差)
,这意味着
将是剩余部分 [4]。

来源:斯坦福大学2017年深度学习讲座:CNN架构
通过这个简单但有效的模块,作者设计了从18层(Resnet-18)到150层(Resnet-150)的更深层次的架构。
对于最深的模型,他们采用了 1x1 卷积,如右图所示:

图片来源:何开明等人,2015年。来源:用于图像识别的深度残差学习
瓶颈层(1×1)层首先减小然后恢复通道尺寸,使3×3层具有较少的输入和输出通道。
总的来说,这里是整个架构的草图:
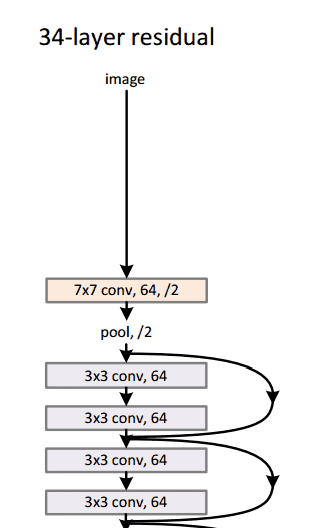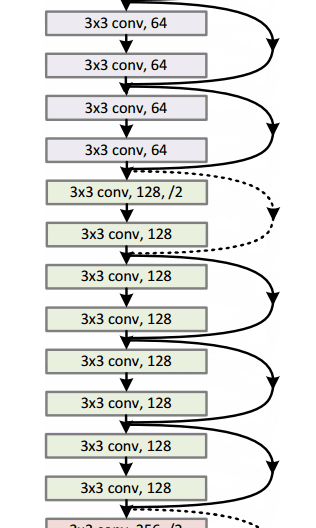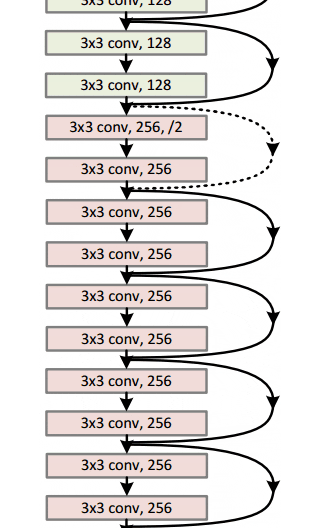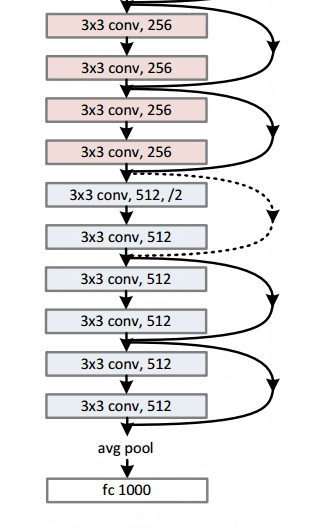
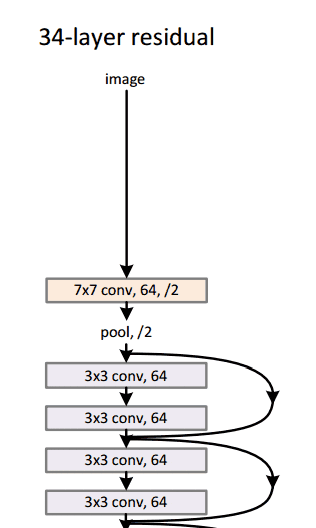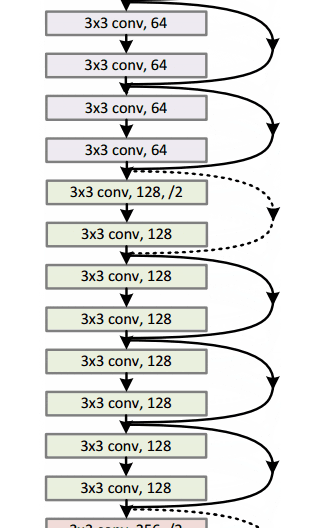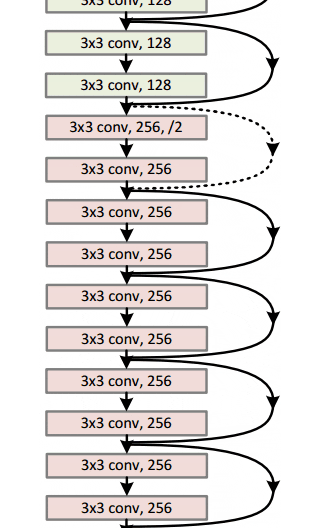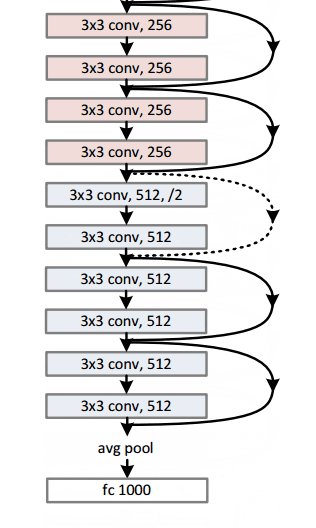
有关更多详细信息,您可以在ResNets上观看Henry AI Labs的精彩视频:
你可以通过直接从Torchvision导入一堆ResNet来玩它们:
import torchvision
pretrained = True# A lot of choices :P
model = torchvision.models.resnet18(pretrained)
model = torchvision.models.resnet34(pretrained)
model = torchvision.models.resnet50(pretrained)
model = torchvision.models.resnet101(pretrained)
model = torchvision.models.resnet152(pretrained)
model = torchvision.models.wide_resnet50_2(pretrained)
model = torchvision.models.wide_resnet101_2(pretrained)n.models.wide_resnet101_2(pretrained)
试试吧!