目录
- 一、前言
- 二、Numpy概述
- 三、生成Numpy数组
- 3.1 从已有数据中创建数组
- 3.2 利用random模块生成数组
- 3.3 创建特定形状的多维数组
- 3.4 利用arange和linspace函数生成数组
- 四、获取元素
- 五、Numpy的算术运算
- 5.1 对应元素相乘
- 5.2 点积运算
- 六、后记
本文的目标受众:
对机器学习、深度学习感兴趣的同学或从业人员,和对Python、PyTorch、TensorFlow等感兴趣并希望能再提升一下自己技术的相关人员。
一、前言
人工智能时代,人工智能的核心就是深度学习。但目前深度学习的框架有很多,像TensorFlow、PyTorch、FastAI等等,它们都各有各的优缺点。那该选择什么框架进行深度学习的快速入门呢?
如果你是个小白,或是和我一样因为时间所迫没工夫全部学完再开始动手,那么我建议选择PyTorch。在有了一定的基础之后,我们可以学习一些其他的架构,比如TensorFlow、CNTK等。
为什么首推PyTorch呢? 原因有以下几点:
(1)PyTorch需要手动定义网络层、参数更新等关键的步骤 ,这非常有助于帮助我们快速理解深度学习的核心。而Keras框架虽然也非常简单且容易上手,但封装粒度很粗,隐藏了很多关键步骤,往往我们搭完了神经网络对整个的流程还一知半解。
(2)PyTorch是动态计算图,其用法更贴近 Python。并且,PyTorch 与 Python共用了许多Numpy的命令,可以降低学习的门槛,比 TensorFlow更容易上手。
(3)PyTorch的动态图机制在调试方面非常方便,如果计算图运行出错,马上可以跟踪问题。PyTorch的调试与Python的调试一样,通过断点检查就可以高效解决问题。
其余还有开源项目多、插件适配等优点,不一一列举了。
前文回顾:[数据分析大全]基于Python的数据分析大全——Numpy基础
下面继续开始本文的Numpy部分相关讲解。
二、Numpy概述
在机器学习和深度学习中,图像、声音、文本等输入数据最终都要转换为数组或矩阵。如何有效地进行数组和矩阵的运算?这就需要充分利用Numpy。
为什么是Numpy?实际上,Python本身含有列表(list)和数组(array),但对于大数据来说,这些结构是有很多不足的。由于列表的元素可以是任何对象,因此列表中所保存的是对象的指针。例如为了保存一个简单的[1,2,3],都需要有3个指针和3个整数对象。对于数值运算来说,这种结构显然比较浪费内存和 CPU等宝贵资源。
至于array对象,它可以直接保存数值,和C语言的一维数组比较类似。但是由于它不支持多维,在上面的函数也不多,因此也不适合做数值运算。
Numpy是数据科学的通用语言,而且与PyTorch关系非常密切,它是科学计算、深度学习的基石。
三、生成Numpy数组
Numpy是 Python 的外部库,不在标准库中。因此,若要使用它,需要先导入Numpy。
import numpy as np
导入 Numpy后,可通过np.+Tab键,查看可使用的函数,如果对其中一些函数的使用不是很清楚,还可以在对应函数+?,再运行,就可以很方便地看到如何使用函数的帮助信息。
输入np.然后按Tab键,将出现如下界面:
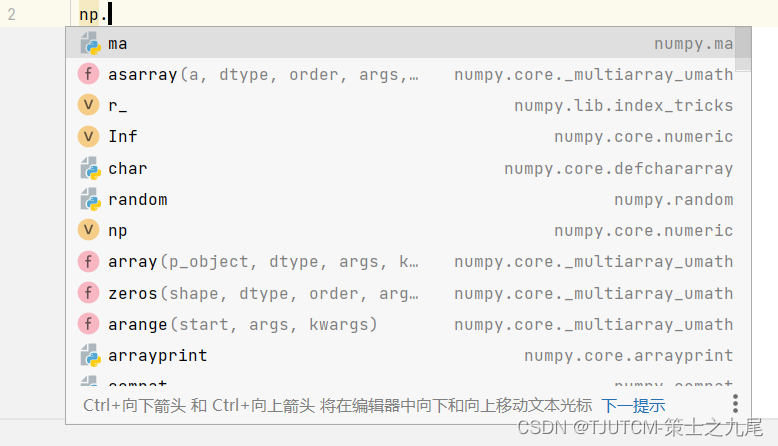
运行如下命令,便可查看函数abs的详细帮助信息。
np.abs?
Numpy 不但强大,而且还非常友好。下面将介绍Numpy的一些常用方法,尤其是与机器学习、深度学习相关的一些内容。
Numpy封装了一个新的数据类型 ndarray (N-dimensional Array),它是一个多维数组对象。该对象封装了许多常用的数学运算函数,方便我们做数据处理、数据分析等。
那么,如何生成ndarray呢?
这里介绍生成ndarray的几种方式,如从已有数据中创建,利用random创建,创建特定形状的多维数组,利用arange、linspace函数生成等。
3.1 从已有数据中创建数组
直接对 Python的基础数据类型(如列表、元组等)进行转换来生成 ndarray :
(1)将列表转换成 ndarray :
import numpy as np
lstl =[3.14,2.17,0,1,2]
ndl = np.array(lst1)
print(ndl)
# [3.142.17 0. 1. 2. ]
print(type(ndl))
# <class 'nurmpy.ndarray'>
(2)嵌套列表可以转换成多维 ndarray :
import numpy as np
lst2 = [[3.14,2.17,0,1,2],[1,2,3,4,5]]
nd2 = np.array(lst2)
print(nd2)
# [[3.14 2.17 0. 1. 2. ]
# [1. 2. 3. 4. 5. ]]
print(type(nd2))
# <class " numpy.ndarray' >
如果把上面示例中的列表换成元组,也同样适用。
3.2 利用random模块生成数组
在深度学习中,我们经常需要对一些参数进行初始化,因此为了更有效地训练模型,提高模型的性能。有些初始化还需要满足一定的条件,如满足正态分布或均匀分布等。
这里介绍了几种常用的方法,如下表所示,列举了np.random模块常用的函数:
| 函数 | 描述 |
|---|---|
| np.random.random | 生成0到1之间的随机数 |
| np.random.uniform | 生成均匀分布的随机数 |
| np.random.randn | 生成标准正态的随机数 |
| np.random.randint | 生成随机的整数 |
| np.random.normal | 生成正态分布 |
| np.random.shuffle | 随机打乱顺序 |
| np.random.seed | 设置随机数种子 |
| random_sample | 生成随机的浮点数 |
下面来看一些函数的具体使用:
import numpy as npnd3 =np.random.random([3,3])
print (nd3)
#[[0.43007219 0.87135582 0.45327073]
# [0.7929617 0.06584697 0.82896613]
# [0.62518386 0.70709239 0.75959122]]
print("nd3的形状为:",nd3.shape)
# nd3的形状为:(3,3)
为了每次生成同一份数据,可以指定一个随机种子,使用shuffle函数打乱生成的随机数。
import numpy as np
np.random.seed(123)
nd4 = np.random.randn(2,3)
print(nd4)
np.random.shuffle(nd4)
print("随机打乱后数据:")print (nd4)
print(type(nd4))
输出结果:
[[-1.0856306 0.99734545 0.2829785][-1.50629471 -0.57860025 1.65143654]]
随机打乱后数据:
[[-1.50629471 -0.57860025 1.65143654][-1.0856306 0.99734545 0.2829785]]
3.3 创建特定形状的多维数组
参数初始化时,有时需要生成一些特殊矩阵,如全是0或1的数组或矩阵,这时我们可以利用np.zeros、np.ones、np.diag来实现,如下表所示:
| 函数 | 描述 |
|---|---|
| np.zeros((3,4)) | 创建3×4的元素全为0的数组 |
| np.ones((3,4)) | 创建3×4的元素全为1的数组 |
| np.empty( (2,3)) | 创建2×3的空数组,空数据中的值并不为0,而是未初始化的垃圾值 |
| np.zeros_like(ndarr) | 以 ndarr相同维度创建元素全为0数组 |
| np.ones_like(ndarr) | 以ndarr相同维度创建元素全为1数组 |
| np.empty_like(ndarr) | 以ndarr相同维度创建空数组 |
| np.eye(5) | 该函数用于创建一个5×5的矩阵,对角线为1,其余为0 |
| np.full((3,5),666) | 创建3×5的元素全为666的数组,666为指定值 |
下面通过几个示例说明:
import numpy as np
# 生成全是0的3x3矩阵
nd5 = np.zeros([3,3])
#生成与nd5形状一样的全0矩阵
#np .zeros_like(nd5)
#生成全是1的3x3矩阵
nd6 = np. ones([3,3])
#生成3阶的单位矩阵
nd7 = np.eye(3)
#生成3阶对角矩阵
nd8 = np.diag([1,2,3])
print(nd5)
#[[O. 0. 0.]
# [0. 0. 0.]
# [0. 0. 0.]]
print(nd6)
#[[1. 1. 1.]
# [1. 1. 1.]
# [1. 1. 1.]]
print(nd7)
#[[1. 0. 0.]
# [0. 1. 0.]
# [0. 0. 1.]]
print(nd8)
# [[1 0 0]
# [0 2 0]
# [0 0 3]]
有时还可能需要把生成的数据暂时保存起来,以备后续使用。
import numpy as npnd9 =np.random.random([5,5])
np.savetxt(×=nd9, fname='./testl.txt')
nd10 = np.loadtxt('./test1.txt ')
print(ndl0)
输出结果:
[[0.41092437 0.5796943 0.13995076 0.40101756 0.62731701]
[0.32415089 0.24475928 0.69475518 0.5939024 0.63179202]
[0.44025718 0.08372648 0.71233018 0.42786349 0.2977805]
[0.49208478 0.74029639.0.35772892 0.41720995 0.65472131]
[0.37380143 0.23451288 0.98799529 0.76599595 0.77700444]]
3.4 利用arange和linspace函数生成数组
arange是numpy模块中的函数,其格式为:
arange([start,]stop[,step,],dtype=None)
其中,start与 stop 用来指定范围,step用来设定步长。在生成一个ndarray时,start 默认为0,步长 step 可为小数。Python有个内置函数range,其功能与此类似。
import numpy as npprint(np.arange (10))
#[0 1 2 3 4 5 6 7 8 9]
print(np.arange(0,10))
#[0 1 2 3 4 5 6 7 8 9]
print(np.arange(1,4,0.5))
#[ 1. 1.5 2. 2.5 3. 3.5]
print(np.arange(9,-1,-1))
#[9 8 7 6 5 4 3 2 1 0]
linspace也是numpy模块中常用的函数,其格式为:
np.linspace(start,stop,num=50,endpoint=True,retstep=False,dtype=None)
linspace可以根据输入的指定数据范围以及等份数量,自动生成一个线性等分向量。
其中, endpoint(包含终点)默认为True,等分数量num默认为50。如果将retstep设置为True,则会返回一个带步长的ndarray。
import numpy as np
print (np .linspace(0,1,10))
#[0. 0.11111111 0.222222220.33333333 0.44444444 0.55555556 0.666666670.77777778 0.88888889 1. ]
值得一提的是,这里并没有像我们预期的那样,生成0.1,0.2,…1.0这样步长为0.1的ndarray,这是因为linspace必定会包含数据起点和终点,那么其步长则为(1-0) /9 =0.11111111。如果需要产生0.1,0.2…,1.0这样的数据,只需要将数据起点0修改为0.1即可。
除了上面介绍到的arange和 linspace,Numpy还提供了logspace函数,该函数的使用方法与linspace的使用方法一样,读者不妨自己动手试一下。
四、获取元素
第三节中我们了解了生成ndarray的几种方法。那在数据生成后,如何读取我们所需要的数据呢?接下来将介绍几种常用获取数据的方法。
import numpy as np
np.random.seed(2019)
nd11 = np.random.random([10])
#获取指定位置的数据,获取第4个元素
ndl1[3]
#截取一段数据
ndl1[3:6]
#截取固定间隔数据
ndl1[1:6:2]
#倒序取数nd11[::-2]
#截取一个多维数组的一个区域内数据
ndl2=np.arange(25).reshape([5,5])
nd12[1:3,1:3]
#截取一个多维数组中,数值在一个值域之内的数据ndl2[(ndl2>3)&(ndl2<10)]
#截取多维数组中,指定的行,如读取第2,3行
nd12[[1,2]] #或nd12[1:3,:]
#截取多维数组中,指定的列,如读取第2,3列
nd12[:,1:3]
如果对上面这些获取方式还不是很清楚,没关系,下面则将通过图形的方式来进一步说明,如下图所示:
左边为表达式,右边为表达式获取的元素。注意,不同的边界,表示不同的表达式。
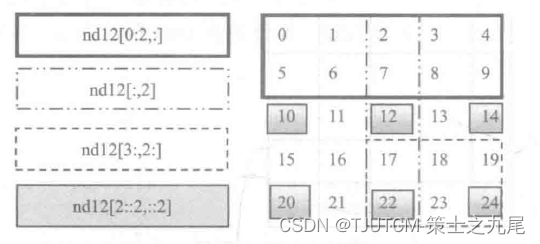
获取数组中的部分元素除了通过指定索引标签来实现外,还可以通过使用一些函数来实现,如通过random.choice函数从指定的样本中随机抽取数据。
import numpy as np
from numpy import random as nr
a=np.arange(1,25,dtype=float)
cl=nr.choice(a,size=(3,4))
#size指定输出数组形状
c2=nr.choice(a,size=(3,4), replace=False)
#replace缺省为True,即可重复抽取
#下式中参数p指定每个元素对应的抽取概率,缺省为每个元素被抽取的概率相同。
3=nr.choice(a,size=(3,4),p=a/np.sum(a))
print("随机可重复抽取")
print(c1)
print("随机但不重复抽取")
print(c2)
print("随机但按制度概率抽取")
print(c3)
打印结果:
# 随机可重复抽取
[[7. 22. 19. 21.]
[ 7. 5. 5. 5. ]
[7. 9.22. 12.]]
# 随机但不重复抽取
[[21. 9. 15. 4.]
[23. 2. 3. 7.]
[13. 5. 6. 1.]]
# 随机但按制度概率抽取
[[15. 19. 24. 8.]
[5. 22. 5. 14.]
22. 13. 17. 1]
五、Numpy的算术运算
在机器学习和深度学习中,涉及大量的数组或矩阵运算,本节我们将重点介绍两种常用的运算。一种是对应元素相乘,又称为逐元乘法 (Element-Wise Product),运算符为np.multiply( ),或*。另一种是点积或内积元素,运算符为np.dot( )。
5.1 对应元素相乘
对应元素相乘(Element-Wise Product)是两个矩阵中对应元素乘积。np.multiply函数用于数组或矩阵对应元素相乘,输出与相乘数组或矩阵的大小一致,其格式如下:
numpy.multiply(x1,,x2,/,out=None,*,where=True,casting='same_kind',order='K',dtype-None,subok=True[,signature,extobj])
其中x1、x2之间的对应元素相乘遵守广播规则,Numpy的广播规则会在下一篇文章——Numpy基础(下)中介绍。以下我们通过一些示例来进一步说明。
A=np.array([[l,2],[-l,4]])
B=np.array([[2,0],[3,4]])
A*B
# 结果如下:
array([[2,0],[-3,16]])
# 或另一种表示方法np.multiply(A,B)#运算结果也是
array([[2,0],[-3,16]])
矩阵A和B的对应元素相乘,由下图直观表示。
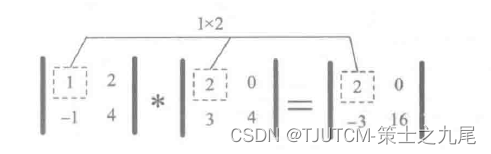
Numpy数组不仅可以和数组进行对应元素相乘,还可以和单一数值(或称为标量)进行运算。运算时,Numpy数组中的每个元素都和标量进行运算,其间会用到广播机制(下一篇文章中将会详细讲解)。
print (A*2.0)print(A/2.0)
输出结果为:
[ [2. 4.]
[-2. 8.]]
[[0.5 1.]
[-0.5 2. ]]
由此,推广后,数组通过一些激活函数后,输出与输入形状一致。
X=np.random.rand(2,3)
def softmoid(x):return 1/(1+np.exp(-x))
def relu(x):return np.maximum(0,x)
def softmax(x) :return np.exp(x)/np.sum(np.exp(X))print("输入参数x的形状:",X.shape)
print("激活函数softmoid输出形状:",softmoid(x) .shape)
print("激活函数relu输出形状:", relu(X).shape)
print("激活函数softmax输出形状:",softmax(X).shape)
输出结果:
输入参数x的形状:(2,3)
激活函数softmoid输出形状:(2,3)
激活函数relu输出形状:(2,3)
激活函数softmax输出形状:(2,3)
5.2 点积运算
点积运算(Dot Product)又称为内积,在 Numpy用np.dot表示,其一般格式为:
numpy.dot(a,b,out=None)
以下通过一个示例来说明dot的具体使用方法及注意事项。
X1=np.array([[1,2],[3,4]])
x2=np.array([[5,6,7],[8,9,10]])
x3=np.dot(X1,X2)
print(X3)
输出结果:
[[21 2427][47 5461]]
以上运算,可用下图表示。
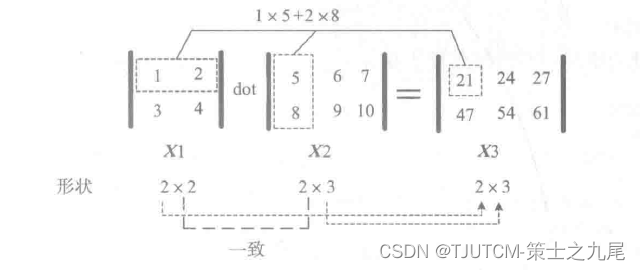
在上图中,矩阵X1和矩阵X2进行点积运算,其中X1和X2对应维度(即X1的第2个维度与X2的第1个维度)的元素个数必须保持一致。此外,矩阵X3的形状是由矩阵XI的行数与矩阵X2的列数构成的。
六、后记
本篇文章主要讲解了Numpy概述、生成Numpy数组、获取元素和Numpy的算术运算的内容。因为要写的内容太多,就拆为上下篇了。这几天会把Numpy基础的下篇也放出来的。
感谢各位读者朋友们长期以往的支持!非常感谢!!!