python简单知识点大全
- 一、变量
- 二、字符串
- 三、比较运算符
- 四、随机数
- 4.1、随机整数
- 4.2、随机浮点数
- 4.3、随机数重现
- 五、数字类型
- 5.1、整数
- 5.2、浮点数
- 5.3、复数
- 六、数字运算
- 七、内置函数
- 八、布尔类型
- 八、逻辑运算符
- 九、短路逻辑和运算符优先级
- 十、分支和循环
- 10.1、if语句
- 10.2、while循环
- 10.3、for循环
- 十一、列表(可变有序)
- 11.1、打包解包
- 11.2、增
- 11.3、删
- 11.4、赋值
- 11.5、查看
- 11.6、排序
- 11.7、切片
- 11.8、列表推导式
- 十二、元组(不可变序列)
- 12.1、定义
- 12.2、索引、切片
- 12.3、重复
- 12.4、连接
- 12.5、成员操作符
- 12.6、枚举
- 12.7、排序
- 十三、字符串(不可变序列)
- 13.1、大小写字母换来换去
- 13.2、左中右对齐
- 13.3、查找
- 13.4、替换
- 13.5、判断
- 13.6、截取
- 13.7、拆分&拼接
- 13.8、格式化字符串
- 13.9、f-字符串
- 十四、序列
- 14.1、跟序列相关的一些方法
- 14.2、跟序列相关的一些函数
- 14.3、迭代器vs可迭代对象
- 十五、字典
- 15.1、创建字典
- 15.2、增
- 15.3、删
- 15.4、改
- 15.5、查
- 15.6、其它操作
- 15.7、嵌套
- 15.8、字典推导式
- 十六、集合(可变容器)
- 16.1、集合的创建
- 16.2、集合的唯一性
- 16.3、集合的方法
- 16.4、`仅`适用于可变集合的方法
- 16.5、可哈希
- 十七、函数
- 17.1、创建和调用函数
- 17.2、函数的参数
- 17.2.1、位置参数
- 17.2.2、关键字参数
- 17.2.3、默认参数
- 17.2.4、收集参数
- 17.2.5、解包参数
- 17.3、函数的返回值
- 17.4、作用域
- 17.5、global语句
- 17.6、嵌套函数
- 17.7、nonlocal语句
- 17.8、LEGB规则
- 17.9、闭包
- 17.10、装饰器
- 17.11、lambda表达式
- 17.12、生成器
- 17.13、递归
- 17.14.1、汉诺塔
- 17.14、函数文档、类型注释、内省
- 17.15、高阶函数
- 十八、永久存储
- 18.1、file文件
- 18.2、路径
- 18.3、with语句和上下文管理器
- 十九、异常
- 二十、类和对象
- 20.1、封装
- 20.2、继承
- 20.3、组合
- 20.4、构造函数
- 20.5、重写
- 20.6、钻石继承
- 20.7、MRO
- 20.8、“私有变量”
- 20.9、魔法方法
参考博客: Python学习-----随机数篇
一、变量
(1)变量名不能以数字开头。
(2)变量名区分大小写。
(3)变量名可以用汉字。
(4)x,y=y,x可以实现x,y值互换。
x=3
y=5
x,y=y,x
print(x,y)
二、字符串
(1)用单引号或者双引号将内容引起。
>>> "hello"
'hello'
>>> 'world'
'world'
(2)用单还是双取决于字符串中有没有不可避免的单或双引号,以免系统误会。
- 错误语法:
>>> 'Let'go'
SyntaxError: invalid syntax
- 正确语法:
>>> "Let'go"
"Let'go"
>>> '"你好,世界"'
'"你好,世界"'
>>>
(3)是在不能避免单双引号冲突时,可以用转义字符代替【加上去\即可转义】。
>>> 'he say,\'hello\''
"he say,'hello'"
(4)转义字符。
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \’ | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\o0a代表换行 |
| \other | 其它的字符以普通格式输出 |
- 行尾直接换行回车回报错,需要再加一个
\。
>>> print("nihao\nSyntaxError: EOL while scanning string literal
>>> print("nihao\n\
nihao")
nihao
nihao
(4)原始字符串:转义字符需要正常使用,不作为转义字符时,可以在前面加上r,表示原始字符串,转义不生效。
>>> print(r"D:\wenjianjiaA\wenjianjiaB\wenjianjiaC")
D:\wenjianjiaA\wenjianjiaB\wenjianjiaC
(5)长字符串:前后用三个单引号或双引号,实现跨行字符串,即不用\n即可做换行。
>>> """你好呀
我不用\n就可以换行了
怎么样"""
'你好呀\n我不用\n就可以换行了\n怎么样'
(6)字符串相加就是拼接
>>> "520"+"1314"
'5201314'
(7)字符串乘以数字,数字是几重复几次。
>>> print("hello\n"*3)
hello
hello
hello
三、比较运算符
| 运算符 | 含义 |
|---|---|
| < | 判断左边是否小于右边 |
| <= | 判断左边是否小于或等于右边 |
| > | 判断左边是否大于右边 |
| >= | 判断左边是否大于或等于右边 |
| == | 判断左右是否相等 |
| != | 判断左右两边是否不相等 |
| is | 判断两个对象的id是否相等 |
| is not | 判断两个对象的id是否不相等 |
- 如果成立返回
True,如果不成立返回False。
四、随机数
需要导入库:import random
4.1、随机整数
(1)包含上下限(闭区间)
- 获取一个下限为a,上限为b的随机整数[a,b]
random.randint(a,b)
>>> import random
>>> x=random.randint(1,10)
>>> x
4
注意:下限不可以大于上限,否则会报错
(2)包含下限,不包含上限(下闭上开)
- 获取一个下限闭区间为a,上限开区间为b的随机整数[a,b)
random.randrange(a,b)
>>> import random
>>> x=random.randrange(1,10)
>>> x
9
>>>
(3)设置步长(间隔)
- 获取一个下限闭区间为a,上限开区间为b的随机整数[a,b),同时步长为step
random.randrange(a,b,step)
- randint两边是闭区间;randrange左边是闭区间,右边是开区间。
- randint不可以设置步长;randrange可以设置步长。
4.2、随机浮点数
(1)0~1之间的浮点数
- 获取一个0~1之间的浮点数。
random.random()
>>> import random
>>> a=random.random()
>>> print(a)
0.20324845902540845
(2)随机浮点数[a,b]
- 获取一个下限为a,上限为b的浮点数(都是闭区间)。
random.uniform(a, b)
random.uniform(a, b)是允许下限大于上限的,不会报错,两边取闭区间。
import random
a=random.uniform(12,33) #获取一个12~33之间的浮点数
a=random.uniform(33,12) #获取一个12~33之间的浮点数
4.3、随机数重现
- 要实现伪随机数的攻击,需要拿到它的种子。
- 默认情况下,random使用当前系统的系统时间作为来作为随机数的种子。
random.getstate()获取随机数种子加工后,随机数生成器的内部状态。random.setstate()重新设置随机数生成器的内部状态
>>> x=random.getstate() #将随机数生成器的状态保存到变量x>>> random.randint(1,10) #使用random.randint(1,10)生成几个随机数
5
>>> random.randint(1,10)
6
>>> random.randint(1,10)
9
>>> random.randint(1,10)
5
>>> random.randint(1,10)
10>>> random.setstate(x) #重新设置随机数生成器的内部状态
>>> random.randint(1,10) #接下来生成的随机数与上面的一样
5
>>> random.randint(1,10)
6
>>> random.randint(1,10)
9
>>> random.randint(1,10)
5
>>> random.randint(1,10)
10
五、数字类型
5.1、整数
- python的整数长度不受限制,可以随时随地进行大数运算。
>>> 6/2
3.0
>>> 1213254365/134
9054137.052238805
5.2、浮点数
- python采用IEEE754的标准存储浮点数,会产生一定精度上的误差。
>>> 0.1+0.2
0.30000000000000004
>>> 0.3 == 0.1+0.2
False
- 使用
decimal模块精准技术浮点数
>>> import decimal
>>> a=decimal.Decimal('0.1')
>>> b=decimal.Decimal('0.2')
>>> print(a+b)
0.3
- 科学计数法
>>> 0.00005
5e-05
5.3、复数
>>> x = 1 + 2j
>>> x.real #获取实部的值
1.0
>>> x.imag #获取虚部的值
2.0
六、数字运算
| 操作 | 结果 |
|---|---|
| x+y | x加y的结果 |
| x-y | x减y的结果 |
| x*y | x乘于y的结果 |
| x\y | x除以y的结果 |
| x//y | x除以y的结果(地板除) |
| x%y | x除以y的余数 |
| -x | x的相反数 |
| +x | x本身 |
| abs(x) | x的绝对值 |
| int(x) | 将x转换成整数 |
| float(x) | 将x转换成浮点数 |
| complex(x) | 返回一个复数,re是实部,im是虚部 |
| c.conjugate | 返回c的共轭复数 |
| divmod(x,y) | 返回(x//y,x%y) |
| pow(x,y | 计算x的y次方 |
| x**y | 计算x的y次方 |
//:地板除,向下取整(取比目标结果小的最大整数)
>>> 3/2
1.5
>>> 3//2
1
七、内置函数
>>> dir(__builtins__)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
八、布尔类型
>>> bool(250)
True
>>> bool("假")
True
>>> bool("False")
True
>>> bool(False)
False
>>> bool(0)
False
>>> bool(0j)
False
>>> bool(0.0)
False
-
以下是结果为False的一些情况:
- 定义为
False的对象:None和False。 - 值为
0的数字类型:0、0.0、0j、Decimal(0)、Fraction(0,1)。 空的序列和集合:''、()、{}、set()、range()。
- 定义为
-
布尔类型其实是一种特殊的整数类型。
>>> 1 == True
True
>>> 0 ==False
True
>>> True + False
1
>>> True - False
1
>>> True * False
0
>>> True / False
SyntaxError: invalid character in identifier //除数不能为0
八、逻辑运算符
| 运算符 | 含义 |
|---|---|
and | 左边和右边同时为True,结果为True |
or | 左边或右边其中一个为True,结果为True |
not | 如果操作数为True,结果为False;如果操作数为False,结果为True |
- Python中任何对象都能直接进行真值测试(测试该对象的布尔类型值为True或者False),用于
if或者while语句的条件判断,也可以做为布尔逻辑运算符的操作数。
九、短路逻辑和运算符优先级
- 短路逻辑的核心思想:从左往右,只有当第一个操作数的值无法确定逻辑运算的结果时,才对第二个操作数进行求值。
>>> 3 and 4 #3为真,但是还需要一个真,才能够结果为真,需要看后面的数,后面的数是4
4
>>> 3 or 4 #3为真,总体结果为真,不需要再看后面的4
3
>>> 0 or 4 #0为假,需要再看后面的数,后面的数是4,为真
4
>>> 0 and 4 #0为假,结果为假,不需要再看后面的数
0
- Python中运算符的运算规则是:优先级高的运算符先执行,优先级低的运算符后执行,同一优先级的操作按照从左到右的顺序进行。也可以像数学四则运算那样使用小括号,括号内的运算最先执行。如下表所示按从高到低的顺序列出了运算符的优先级。同一行中的运算符具有相同优先级,此时它们的结合方向决定求值顺序。
| 运算符 | 说明 |
|---|---|
| ** | 幂 |
| +、- | 正号和负号 |
| *、/、//、% | 算术运算符 |
| +、- | 算术运算符 |
| >、>=、<、<=、==、!= | 比较运算符 |
| 优先级 | 运算符 | 描述 |
|---|---|---|
| 1 | lambda | Lambda表达式 |
| 2 | if-else | 条件表达式 |
| 3 | or | 布尔或 |
| 4 | and | 布尔与 |
| 5 | not x | 布尔非 |
| 6 | in,not in,is,is not,<,<=,>,>=,!= | 成员测试,同一性测试,比较 |
| 7 | ` | ` 按位或 |
| 8 | ^ | 按位异或 |
| 9 | & | 按位与 |
| 10 | <<,>> | 移位 |
| 11 | +,- | 加法,减法 |
| 12 | *,@,/,//,% | 乘法,矩阵乘法,除法,地板除,取余数 |
| 13 | +X,-X,~X | 正号,负号,按位翻转 |
| 14 | ** | 指数 |
| 15 | await x | Await表达式 |
| 16 | x[index],x[index:index],x(arguments…),x.attribute | 下标,切片,函数调用,属性引用 |
| 17 | (expressions…),[expressions…],{key:value…},{expressions…} | 绑定或元组显示,列表显示,字典显示,集合显示 |
十、分支和循环
10.1、if语句
- 第一种情况:判断一个条件,如果这个条件成立,就执行其包含的某条语句或某个代码块。
if condition:statement(s)
- 第二种情况:判断一个条件:
- 如果条件成立,就执行其包含的某条语句或某个代码块。
- 如果条件不成立,就执行另外的某条语句或某个代码块。
if condition:statement(s)
else:statement(s)
- 第三种情况:判断多个条件,如果第1个条件不成立,则继续判断第2个条件,如果第2个条件还不成立,则接着判断第3个条件…
if condition1:statement(s)
elif condition2:statement(s)
elif condition3:statement(s)
...
- 第四种情况:第4种是在第3种的情况下添加一个else,表示上面所有的条件均不成立的情况下,执行某条语句或某个代码块。
if condition1:statement(s)
elif condition2:statement(s)
elif condition3:statement(s)
...
elsestatement(s)
- 条件成立时执行的语句 if condition else 条件不成立时执行的语句。
if age < 18:print('抱歉,未满18岁禁止访问')
elseprint('欢迎您来')
#上面语句写成条件表达式
print('抱歉,未满18岁禁止访问') if age <18 else print('欢迎您来')
score = 66
if 0 < score < 60:level = "D"
elif 60 <score < 80:level = "C"
elif 80 <score < 90:level = "B"
elif 90 <score < 100:level = "A"
elif score ==100:level = "S"
else:1evel="请输入0~100之间的分值^o^"
print(level)# 换成条件表达式:
score = 66
level = ('D' if 0 <= score < 60 else'C' if 60 <= score < 80 else'B' if 80 <= score < 90 else'A' if 90 <= score < 100 else'S' if score == 100 else"请输入0~100之间的分值^o^")
10.2、while循环
while condition:statement(s)
break,结束循环,跳出循环体,直接结束。continue,跳出本次循环,回到循环体的开头。else,当循环不再为真的时候,执行else里面的内容,如果是使用break语句跳出循环,此时的循环依旧为真,不会执行else里面的内容。- 无论是break语句还是continue语句,它们只能作用于一层循环体!
10.3、for循环
for 变量 in 可迭代对象:statement(s)
>>> for each in "Hello":print(each)H
e
l
l
o
range()函数:range(stop)生成0到stop的列表,不包含stop。
>>> for i in range(5):print(i)0
1
2
3
4
range(start,stop)生成start到stop的列表,包含start,不包含stop。
>>> for i in range(2,5):print(i)2
3
4
range(start,stop,step)生成start到stop的列表,包含start,不包含stop,其中每个数相差step,step可以是正数也可以是负数。
>>> for i in range(2,10,2):print(i)2
4
6
8
>>> for i in range(10,2,-2):print(i)10
8
6
4
>>> for n in range(2,10):for x in range(2,n):if n%x==0:print(n,"=",x,"*",n//x)breakelse:print(n,"是一个素数")2 是一个素数
3 是一个素数
4 = 2 * 2
5 是一个素数
6 = 2 * 3
7 是一个素数
8 = 2 * 4
9 = 3 * 3
十一、列表(可变有序)
- 列表是一种序列类型,创建后
可以随意被修改。 - 使用方括号
[]或list()创建,元素间用逗号,分隔。 - 列表中各元素类型可以不同,无长度限制
- 若仅仅将一个列表赋值给一个变量,则不创建新的列表,仅传递引用
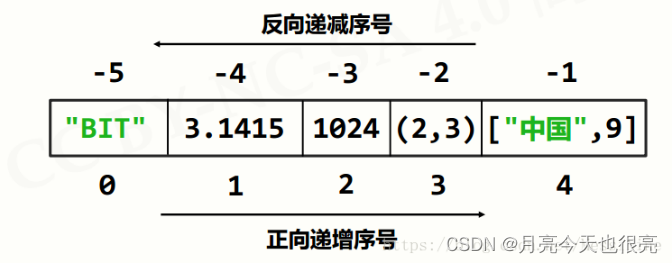
| 函数或方法 | 描述 |
|---|---|
| ls[i]=x | 替换列表ls第i元素为x |
| ls[i: j: K]=lt | 用列表lt替换ls切片后所对应元素子列表 |
| del ls[i] | 删除列表ls中第i元素 |
| del ls[i: j: k] | 删除列表ls中第i到第j以k为步长的元素 |
| ls += lt | 更新列表ls,将列表lt元素增加到列表ls中 |
| ls *= n | 更新列表ls,其元素重复n次 |
| ls.append(x) | 在列表ls最后增加一个元素x |
| ls.clear() | 删除列表ls中所有元素 |
| ls.copy | 生成一个新列表,赋值ls中所有元素 |
| ls.insert(i,x) | 在列表ls的第i位置增加元素x |
| ls.pop(i) | 将列表ls中第i位置元素取出并删除该元素 |
| ls.remove(x) | 将列表中出现的第一个元素x删除 |
| ls.reverse() | 将列表ls中的元素反转 |
11.1、打包解包
- 序列都支持解包的操作。
>>> l=[1,2,3,4] #打包
>>> a,b,c,d=l #解包,变量数量必须要与列表里面元素的数量一致
>>> a
1
>>> b
2
>>> c
3
>>> d
4#数量不一致,报错
>>> a,b,c=l
Traceback (most recent call last):File "<pyshell#63>", line 1, in <module>a,b,c=l
ValueError: too many values to unpack (expected 3)#使用【*c将其余赋值给c】
>>> a,b,*c=l
>>> a
1
>>> b
2
>>> c
[3, 4]
>>> ls = ["cat","dog","tiger",1024]
>>> ls
['cat', 'dog', 'tiger', 1024]
>>> lt = ls
>>> lt
['cat', 'dog', 'tiger', 1024]#方括号[]真正创建一个列表,赋值仅传递引用
11.2、增
- 往列表里增加元素。
- 用连接的方式:
>>> ls+["hi"]
['cat', 'dog', 'tiger', 1024, 'hi']
append:追加一个元素到列表中:
>>> ls.append(2023)
>>> ls
['cat', 'dog', 'tiger', 1024, 2023]
extend:拉伸,追加多个元素到列表中:
>>> ls.extend(["mysql","fire"])
>>> ls
['cat', 'dog', 'tiger', 1024, 2023, 'mysql', 'fire']
insert:在指定索引位置插入元素,在第二个元素的位置插入samba作为第二个元素:
>>> ls.insert(1,'samba')
>>> ls
['cat', 'samba', 'dog', 'tiger', 1024, 2023, 'mysql', 'fire']
- 使用切片操作增加元素:
>>> ls[len(ls):]=[6]
>>> ls
['dogs', 'tiger', 1024, 2023, 'mysql', 'fire', 6]
>>> ls[len(ls):]=[7,8,9]
>>> ls
['dogs', 'tiger', 1024, 2023, 'mysql', 'fire', 6, 7, 8, 9]
11.3、删
pop
>>> a=ls.pop(0) #弹出第1个元素,可以将其赋值
>>> a
'cat'
remove
>>> ls.remove('samba')
>>> ls
['dog', 'tiger', 1024, 2023, 'mysql', 'fire']#指定删除对象的名字
#直接删除,不能将其赋值
#不能指定序号,只能指定要删除对象的
del删除列表
>>> ll
['cat', 'dog', 'tiger', 1024, 2023, 'hi', 2023]
>>> del ll
>>> ll
Traceback (most recent call last):File "<pyshell#48>", line 1, in <module>ll
NameError: name 'll' is not defined
11.4、赋值
- 通过索引,重新赋值。
>>> ls
['dog', 'tiger', 1024, 2023, 'mysql', 'fire']
>>> ls[0]='dogs'
>>> ls
['dogs', 'tiger', 1024, 2023, 'mysql', 'fire']
- 通过切片给前两个元素重新赋值。
>>> ls
['dog', 'tiger', 1024, 2023, 'mysql', 'fire']
>>> ls[0]='dogs'
>>> ls
['dogs', 'tiger', 1024, 2023, 'mysql', 'fire']
11.5、查看
- 查看出现的次数。
>>> ls.count(1024)
1
- 查看指定元素的索引值。
>>> ls
['dogs', 'tiger', 1024, 2023, 'mysql', 'fire']
>>> ls.index('tiger') #最小索引值
1
>>> ls.index('tiger',1,3) #从1-3中查找【第二个元素和第三个元素之间】【不取上限】
1
11.6、排序
sort排序,对字符串排序不区分大小写。
>>> names = ['alice','Bob','coco','Harry']
>>> names.sort()
>>> names
['Bob', 'Harry', 'alice', 'coco']#按照ASCII排序,先排序首字母为大写的,再排序首字母是小写的
>>> names.sort(key=str.lower)
>>> names
['alice', 'Bob', 'coco', 'Harry']#对字符串排序不区分大小写,相当于将所有元素转换为小写,再排序
>>> names.sort(key=str.upper)
>>> names
['alice', 'Bob', 'coco', 'Harry']
#相当于将所有元素转换为大写,再排序
- 乱序
>>> li = list(range(10))
>>> li
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]#生成0-9,将其转换为列表形式
>>> import random
>>> random.shuffle(li) #随机打乱
>>> li
[5, 9, 3, 8, 1, 0, 6, 2, 7, 4]
11.7、切片
>>> ls[0]
'cat'
>>> l=len(ls)
>>> l
4
>>> ls[l-1]
1024
>>> ls[-1]
1024
>>> ls[0:3]
['cat', 'dog', 'tiger']
>>> ls[1:4]
['dog', 'tiger', 1024]
>>> ls
['cat', 'dog', 'tiger', 1024]
>>> ls[1:]
['dog', 'tiger', 1024]
>>> ls[:]
['cat', 'dog', 'tiger', 1024]
>>> ls[:3]
['cat', 'dog', 'tiger']
>>> ls[::2]
['cat', 'tiger']
>>> ls[::-2]
[1024, 'dog']
11.8、列表推导式
#原代码
>>> ll=[1,2,3,4,5]
>>> for i in range(len(ll)):ll[i]=ll[i]*2
>>> ll
[2, 4, 6, 8, 10]#列表推导式
>>> ll=[1,2,3,4,5]
>>> ll=[i*2 for i in ll]
>>> ll
[2, 4, 6, 8, 10]
- 语法:
[expression for target in iterable]
>>> x=[i for i in range(10)]
>>> x
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> x=[i+1 for i in range(10)]
>>> x
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
- 语法:
[expression for target in iterable if condition]
>>> x=[i for i in range(10) if i%2==0]
>>> x
[0, 2, 4, 6, 8]
>>> x=[i+1 for i in range(10) if i%2==0]
>>> x
[1, 3, 5, 7, 9]
- 语法:
[expression for target1 in iterablelfor target2 in iterable2...for targetN in iterableN]

- 语法:
[expression for target1 in iterablel if condition1for target2 in iterable2 if condition2...for targetN in iterableN if conditionN]
十二、元组(不可变序列)
12.1、定义
- 使用
tuple函数可以把列表转换成元组
>>> t2=() #空元组的定义
>>> print(type(t2))
<class 'tuple'>>>> t2=('xyz') #定义单个内容的元组,【不加逗号为字符串类型】
>>> print(type(t2))
<class 'str'>>>> t2=('xyz',) #定义单个内容的元组,【加逗号为元组类型】
>>> print(type(t2))
<class 'tuple'>
12.2、索引、切片
>>> users = ('root','westos','redhat')
>>> passwds = ('123','456','012')>>> print(users[0])
root
>>> print(users[:1]) #切出第一个元素
('root',)
12.3、重复
>>> print(users * 3)
('root', 'westos', 'redhat', 'root', 'westos', 'redhat', 'root', 'westos', 'redhat')
12.4、连接
>>> print(passwds+('012','230'))
('123', '456', '012', '012', '230')
12.5、成员操作符
>>> print('redhat' in users)
True
>>> print('redhat' not in users)
False
12.6、枚举
##循环遍历
>>> for user in users:print(user)root
westos
redhat
- 枚举+迭代
#循环遍历并返回索引值和value
>>> for index,user in enumerate(users):print('第%d个用户:%s'%(index+1,user))第1个用户:root
第2个用户:westos
第3个用户:redhat
- 枚举+压缩
#先对应压缩在一起,再枚举遍历输出
>>> for user,passwd in zip(users,passwds):print(user,":",passwd)root : 123
westos : 456
redhat : 012
>>> t=(1,2.3,True,'westos')#统计出现的次数
>>> print(t.count('westos'))
1#统计最小索引值
>>> print(t.index(2.3))
1
12.7、排序
- 元组不能够使用方法
sort排序。 - 使用函数
sorted排序。
>>> a=(1,6,3,2,11,5)
>>> a=sorted(a)
>>> a
[1, 2, 3, 5, 6, 11]
十三、字符串(不可变序列)
- 空字符串:
- S=str()
- S=’ ’
- S=" "
- S=‘’’ ‘’’ 可多行,可用于注释
13.1、大小写字母换来换去
capitailize()将字符串的首字母变为大写,其他字母变为小写。casefold()返回一个所有字母都是小写的字符串,除了处理英文字符,还能处理其他语言的字符。title()将字符串中每个单词的首字母都变为大写,其他字母变为小写。swapcase()将字符串中的所有字母大小写翻转。upper()将所有的字母都变成大写。lower()将所有的字母都变成小写,只能处理英文字符。
>>> s="hi Hello Word"
>>> s.capitalize()
'Hi hello word'>>> s.casefold()
'hi hello word'>>> s.title()
'Hi Hello Word'>>> s.swapcase()
'HI hELLO wORD'>>> s.upper()
'HI HELLO WORD'>>> s.lower()
'hi hello word'
13.2、左中右对齐
width用来指定整个字符串的宽带,如果指定的宽度小于或者等于字符串,则原字符串输出。fillchar,没有指定时,默认空格填充。center(width,fillchar=' ')中间对齐,空格填充。ljust(width,fillchar=' ')左对齐,空格填充。rjust(width,fillchar=' ')右对齐,空格填充。zfill(width)用0填充左侧。
>>> s.center(10)
'hi Hello Word'
>>> s.center(15)
' hi Hello Word '
>>> s.center(15,"-")
'-hi Hello Word-'>>> s.ljust(15)
'hi Hello Word '>>> s.rjust(15)
' hi Hello Word'>>> "250".zfill(5)
'00250'
>>> "-250".zfill(5)
'-0250'
13.3、查找
start和end指定查找的起始和结束位置。count(sub[,start[,end]])查找sub参数指定的子字符串,在字符串中出现的次数。find(sub[,start[,end]])查找sub参数指定的子字符串,在字符串中的索引下标值,从左往右找,若是找不到返回-1。rfind(sub[,start[,end]])查找sub参数指定的子字符串,在字符串中的索引下标值,从右往左找,若是找不到返回-1。index(sub[,start[,end]])查找sub参数指定的子字符串,在字符串中的索引下标值,从左往右找,若是找不到抛出异常。rindex(sub[,start[,end]])查找sub参数指定的子字符串,在字符串中的索引下标值,从右往左找,若是找不到抛出异常。
>>> s="上海自来水来自海上">>> s.count("海")
2
>>> s.find("海")
1
>>> s.find("hai")
-1
>>> s.find("海",3)
7>>> s.rfind("海")
7>>> s.index("海")
1
>>> s.index("hai")
Traceback (most recent call last):File "<pyshell#32>", line 1, in <module>s.index("hai")
ValueError: substring not found
13.4、替换
expandtabs([tabsize=8])使用空格来替换制表符,并且返回一个新的字符串,tabsize指定一个tab等于多少空格。replace(old,new,count=-1)返回一个将所有old参数指定的子字符串替换为new参数指定的新字符串;count参数指定的是替换的次数,默认是-1,当不指定时,替换的是全部。translate(table)返回根据table参数转化后的新字符串,table用于指定转换规则的表格。- table规则表格使用`str.maketrans(x[,y[,z]])
>>> '''print("hi,I'm from China")print("hi,I'm from China") #一个tabprint("hi,I'm from China")''' #四个空格
'print("hi,I\'m from China")\n\tprint("hi,I\'m from China")\n print("hi,I\'m from China")'>>> '''print("hi,I'm from China")print("hi,I'm from China")print("hi,I'm from China")'''.expandtabs(4) #将一个tab替换成四个空格
'print("hi,I\'m from China")\n print("hi,I\'m from China")\n print("hi,I\'m from China")'>>> "你好吗,我很好".replace("好","good")
'你good吗,我很good'>>> table=str.maketrans("ABCDEFG","1234567")
>>> "I love FishC".translate(table)
'I love 6ish3'>>> table=str.maketrans("ABCDEFG","1234567","love") #第三个参数为,忽略第三个参数包含的字符串
>>> "I love FishC".translate(table)
'I 6ish3'
13.5、判断
startswith(prefix[,strat[,end]])判断参数指定的子字符串是否出现在字符串的起始位置。endswith(stuffix[,start[,end]])判断参数指定的子字符串是否出现在字符串的结束位置。isupper()判断一个字符串中所有的字母是否都是大写字母。islower()判断一个字符串中所有的字母是否都是小写字母。istitle()判断一个字符串中的单词是否都是以大写字母开头,其余字母都是小写。isalpha()判断一个字符串中是否只是由字母构成。isascii()isspace()判断一个字符串是否为一个空白字符串。isprintable()判断一个字符串中是否所有字符都是可打印的。isdecimal()判断数字。isdigit()判断数字。isnumeric()判断数字。islnum()方法isalpha()、isdecimal()、isnumeric()、isdigit()任意一个返回的结果是True,则返回True。isidentifier()判断字符串是否是一个合法的标识符。
>>> s= "她爱pyhon"
>>> if s.startswith(("你","我","她")): #使用元组匹配多个字符串print("总有人喜爱python")总有人喜爱python
>>> s="112"
>>> s.isdecimal()
True
>>> s.isdigit()
True
>>> s.isnumeric()
True
>>> s="2²"
>>> s.isdecimal()
False
>>> s.isdigit()
True
>>> s.isnumeric()
True
>>> s="ⅠⅡⅢ"
>>> s.isdecimal()
False
>>> s.isdigit()
False
>>> s.isnumeric()
True
>>> s="一二三"
>>> s.isdecimal()
False
>>> s.isdigit()
False
>>> s.isnumeric()
True
- 判断字符串是否是python的一个保留标识符。
>>> import keyword
>>> keyword.iskeyword("if")
True
13.6、截取
- 参数chars默认为None,去除的是空白,可以指定去除其他字符。
strip(chars=None)去除字符串两侧的空白。rstrip(chars=None)去除字符串右侧的空白。lstrip(chars=None)去除字符串左侧的空白。removeprefix(prefix)指定要删除的前缀。removesuffix(suffix)指定要删除的后缀。
>>> "www.ilovefishc.com".lstrip("wcom.") #虽然传入的是一个字符串,但是是以单个字符为单位进行匹配去除的。
'ilovefishc.com'
>>> "www.ilovefishc.com".rstrip("wcom.")
'www.ilovefish'
>>> "www.ilovefishc.com".strip("wcom.")
'ilovefish'
>>>
13.7、拆分&拼接
partition(sep)将字符串以参数指定的分隔符为依据进行切割,并且将切割后的结果返回一个三元组,从左到右找分隔符。rpartition(sep)将字符串以参数指定的分隔符为依据进行切割,并且将切割后的结果返回一个三元组,从右到左找分隔符。
>>> "www.ilovefishc.com".partition(".")
('www', '.', 'ilovefishc.com')
>>> "www.ilovefishc.com".rpartition(".")
('www.ilovefishc', '.', 'com')
split(sep=None,maxsplit=-1)根据分隔符将字符串切割,默认情况下切分空格,结果放在一个列表里面;maxsplit参数,指定分隔的次数,从左往右分隔。rsplit(sep=None,maxsplit=-1)根据分隔符将字符串切割,默认情况下切分空格,结果放在一个列表里面;maxsplit参数,指定分隔的次数,从右往左分隔。
>>> "苟日新 日日新 月月新".split()
['苟日新', '日日新', '月月新']
splitlines(keepends=False)将字符串按行来进行分隔,将结果以列表的形式返回;keepends参数表示结果是否要包含换行符,False表示不包含。
>>> "苟日新\n日日新\n月月新".splitlines()
['苟日新', '日日新', '月月新']
>>> "苟日新\n日日新\n月月新".splitlines(True)
['苟日新\n', '日日新\n', '月月新']
join(iterable)
>>> ".".join(("www","baidu","com"))
'www.baidu.com'
>>> ".".join(["www","baidu","com"])
'www.baidu.com'
13.8、格式化字符串
[[fill]align][sign][#][0][width][grouping_option][.precision][type]
| 值 | 含义 |
|---|---|
< | 强制字符串在可用空间内左对齐(默认) |
> | 强制字符串在可用空间内右对齐 |
= | 强制将填充放置在符号(如果有)之后但是在数字之前的位置(这适用于以”+000000120“的形式打印字符串) |
^ | 强制字符串在可用空间内居中 |
>>> year=2023
>>> print("今年是{}年".format(year))
今年是2023年
>>> print("1+2={},2^2={}".format(1+2,2*2))
1+2=3,2^2=4>>> "{0}{0}{1}{1}".format("是","非")
'是是非非'>>> "今年是{year}年,我爱{fav}".format(year=2023,fav="python")
'今年是2023年,我爱python'
>>> "{},{},{}".format(1,"{}",2)
'1,{},2'
>>> "{},{{}},{}".format(1,2)
'1,{},2'
>>>
>>> "{:^}".format(250)
'250'
>>> "{:^10}".format(250)
' 250 '
>>> "{:>10}".format(250)
' 250'>>> "{:>10}{:<10}".format(250,520)
' 250520 '>>> "{:%>10}{:%<10}".format(250,520)
'%%%%%%%250520%%%%%%%'
>>> "{:0=10}".format(520)
'0000000520'
>>> "{:010}".format(520)
'0000000520'
| 值 | 含义 |
|---|---|
+ | 正数前面添加正号(+),负数在前面添加负号(-) |
- | 只有负数在前面添加符号(+),默认行为 |
空格 | 正数在前面添加一个空格,负数在前面添加负号(-) |
>>> "{:+}{:1}".format(520,-250)
'+520-250'
>>> "{:,}".format(1234) #使用逗号作为千位的分隔符
'1,234'
- 对于[type]设置为”f“或者”F“的浮点数来说,是限定小数点后显示多少个数位 。
- 对于[type]设置为”g“或者”G“的浮点数来说,是限定小数点前后显示多少个数。
- 对于非数字类型来说,限定的是最大字段的大小。
- 对于整数类型来说,则不允许使用[.precision]选项。
>>> "{:.2f}".format(3.1415)
'3.14'
>>> "{:.2g}".format(3.1415)
'3.1'>>> "{:.6}".format("I love python")
'I love'
>>> "{:.2}".format(520) #整数不允许使用
Traceback (most recent call last):File "<pyshell#148>", line 1, in <module>"{:.2}".format(520)
ValueError: Precision not allowed in integer format specifier
- 整数
| 值 | 含义 |
|---|---|
b | 将参数以二进制的形式输出 |
c | 将参数以Unicode的形式输出 |
d | 将参数以十进制的形式输出 |
o | 将参数以八进制的形式输出 |
x | 将参数以十六进制的形式输出 |
X | 将参数以十六进制的形式输出 |
n | 与d类似,不同之处在于它会使用当前语言环境设置的分隔符插入到恰当的位置 |
| None | 跟d一样 |
>>> "{:b}".format(80)
'1010000'
>>> "{:#b}".format(80) #使用#,会自动追加一个前缀,用于分辨不同进制,二进制的前缀是0b
'0b1010000'>>> "{:o}".format(80)
'120'
>>> "{:#o}".format(80)
'0o120'
- 浮点数
| 值 | 含义 |
|---|---|
e | 将参数以科学记数法的形式输出(以字母e来标示指数,默认精度为6) |
E | 将参数以科学记数法的形式输出(以字母E来标示指数,默认精度为6) |
f | 将参数以定点表示法的形式输出(“不是数”用nan标示,无穷用inf标示,默认精度为6) |
F | 将参数以定点表示法的形式输出(“不是数“用NAN标示,无穷用INF标示,默认精度为6) |
g | 通用格式,小数以f形式输出,大数以e的形式输出 |
G | 通用格式,小数以F形式输出,大数以E的形式输出 |
n | 跟g类似,不同之处在于它会使用当前语言环境设置的分隔符插入到恰当的位置 |
% | 以百分比的形式输出(将数字乘以100并显示为定点表示法(f)的形式,后面附带一个百分号 |
| None | 类似于g,不同之处在于当使用定点表示法时,小数点后将至少显示一位;默认精度与给定值所需的精度一致 |
13.9、f-字符串
>>> year=2023
>>> f"今年是{year}年"
'今年是2023年'
>>> F"今年是{year}年"
'今年是2023年'>>> f"{-520:010}"
'-000000520'
十四、序列
列表、元组和字符串的共同点:
- 都可以通过索引获取每一个元素
- 第一个元素的索引值都是0
- 都可以通过切片的方法获取一个范围
- 都有很多共同的运算符
- 序列分为可变序列和不可变序列。
14.1、跟序列相关的一些方法
+将两个序列进行拼接。*将序列进行重复。is、is not检测对象的id值是否相同,判断是否是同一个对象。in判断某个元素是否包含在序列当中,not in则相反。del用于删除一个或者多个指定对象。
# 删除整个序列
>>> x=[1,2,3]
>>> y=[1,2,3]
>>> del x,y# 删除序列中连续的几个元素
>>> y=[1,2,3]
>>> del y[1:4]
>>> y
[1]#使用切片也能够删除序列中连续的元素
>>> y=[1,2,3,4,5]
>>> y[1:4]=[]
>>> y
[1, 5]#删除序列中没有连续的元素(隔2隔删除)
>>> y=[1,2,3,4,5]
>>> del y[::2]
>>> y
[2, 4]#切片无法实现删除不连续的元素
>>> y=[1,2,3,4,5]
>>> y[::2]=[]
Traceback (most recent call last):File "<pyshell#13>", line 1, in <module>y[::2]=[]
ValueError: attempt to assign sequence of size 0 to extended slice of size 3#清空列表
>>> y=[1,2,3,4,5]
>>> y.clear()
>>> y
[]#使用del清空列表
>>> y=[1,2,3,4,5]
>>> del y[:]
>>> y
[]
14.2、跟序列相关的一些函数
list()、tuple()、str()列表、元组和字符串相互转换。min()、max()对比传入的参数,并返回最大值和最小值。min(iterable,*[,key,default])min(arg1,arg2,*args[,key])max(iterable,*[,key,default])max(arg1,arg2,*args[,key])
>>> s=[]
>>> min(s) #当传入的可迭代对象是空的时,会发生报错
Traceback (most recent call last):File "<pyshell#22>", line 1, in <module>min(s)
ValueError: min() arg is an empty sequence>>> min(s,default="没有传入合适的值")
'没有传入合适的值'>>> min(1,2,3,0,6)
0
len()、sum()
>>> sum(s)
15
>>> sum(s,start=100) #start参数指定起始值是100
115
sorted()、reversed()sorted()会返回一个全新的列表,不会对原来的列表做出改变,而sort方法会对原来的列表做出改变。
>>> s=[1,7,3,8,3]
>>> sorted(s)
[1, 3, 3, 7, 8]
>>> s
[1, 7, 3, 8, 3]
>>> s=[1,7,3,8,3]
>>> sorted(s,reverse=True)
[8, 7, 3, 3, 1]
>>> sorted(s)
[1, 3, 3, 7, 8]
>>> t=["Fish","Apple","Books","Banana","Pen"]
>>> sorted(t)
['Apple', 'Banana', 'Books', 'Fish', 'Pen']
>>> sorted(t,key=len)
['Pen', 'Fish', 'Apple', 'Books', 'Banana']
>>> t.sort(key=len)
>>> t
['Pen', 'Fish', 'Apple', 'Books', 'Banana']>>> sorted("Fish")
['F', 'h', 'i', 's']
all()判断可迭代对象中,是否所有元素的值都为真。any()判断可迭代对象中,是否存在某个元素的值为真。enumerate()enumerate()函数用于返回一个枚举对象,它的功能就是将可迭代对象中的每个元素及从0开始的序号共同构成一个二元组的列表。
>>> seasons=['Spring','Summer','Fall','Winter']
>>> enumerate(seasons) #得到的是一个枚举对象
<enumerate object at 0x000001EB04187280>
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]>>> list(enumerate(seasons,10)) #第二个参数指定值的开始
[(10, 'Spring'), (11, 'Summer'), (12, 'Fall'), (13, 'Winter')]
zip()用于创建一个聚合多个可迭代对象的迭代器。它会将作为参数传入的每个可迭代对象的每个元素依次组合成元组,即第ⅰ个元组包含来自每个参数的第ⅰ个元素。
>>> x=[1,2,3]
>>> y=[4,5,6]
>>> zipped=zip(x,y)
>>> zipped
<zip object at 0x000001EB060E6840>
>>> list(zipped)
[(1, 4), (2, 5), (3, 6)]
>>>
>>> z="Hello"
>>> zipped=zip(x,y,z)
>>> list(zipped) #当压缩的数量不一致的时候,会将多余的元素去除
[(1, 4, 'H'), (2, 5, 'e'), (3, 6, 'l')]
>>>
>>>
>>> import itertools
>>> zipped=itertools.zip_longest(x,y,z)
>>> list(zipped) #将多余的元素保留
[(1, 4, 'H'), (2, 5, 'e'), (3, 6, 'l'), (None, None, 'l'), (None, None, 'o')]
>>>
map()会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将返回运算结果的迭代器。
>>> mapped=map(ord,"HELLO") #相当于[ord(H),ord(O),ord(L),ord(L),ord(O)]
>>> list(mapped)
[72, 69, 76, 76, 79]
>>> mapped=map(pow,[2,3,10],[5,2,3]) #相当于[pow(2,5),pow(3,2),pow(10,3)]
>>> list(mapped)
[32, 9, 1000]
filter()会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将运算结果为真的元素,以迭代器的形式返回。
>>> list(filter(str.islower,"HellO")) #将是小写的字母放在结果里
['e', 'l', 'l']
14.3、迭代器vs可迭代对象
- 一个迭代器肯定是一个可迭代对象。
- 可迭代对象可以重复使用,而迭代器则是一次性的。
>>> mapped=map(ord,"HELLO")
>>> for each in mapped:print(each)72
69
76
76
79
>>> list(mapped) #第二次再想使用时,列表已经空了
[]
iter()将可迭代对象变成迭代器。
>>> x=[1,2,3,4,5]
>>> y=iter(x)
>>> type(x)
<class 'list'>
>>> type(y) #y是一个列表的迭代器
<class 'list_iterator'>
next()将迭代器中的元素逐个提权出来。
>>> next(y)
1
>>> next(y)
2
>>> next(y)
3
>>> next(y)
4
>>> next(y)
5
>>> next(y) #当迭代器中没有元素了,就会报错
Traceback (most recent call last):File "<pyshell#85>", line 1, in <module>next(y)
StopIteration
>>> z=iter(x)
>>> next(z,"元素已经提取完")
1
>>> next(z,"元素已经提取完")
2
>>> next(z,"元素已经提取完")
3
>>> next(z,"元素已经提取完")
4
>>> next(z,"元素已经提取完")
5
>>> next(z,"元素已经提取完")
'元素已经提取完'
十五、字典
- 字典是Python中唯一实现映射关系的内置类型。
- 字典没有存在重复的键,新的键值会覆盖旧的键值。
15.1、创建字典
>>> y={"吕布":"口口布","关羽":"关习习"}
>>> type(y)
<class 'dict'>
>>> y["吕布"]
'口口布'
>>> y["刘备"]="刘baby"
>>> y
{'吕布': '口口布', '关羽': '关习习', '刘备': '刘baby'}
#方法一
>>> a={'吕布': '口口布', '关羽': '关习习', '刘备': '刘baby'}
#方法二
>>> b=dict(吕布= '口口布', 关羽= '关习习', 刘备= '刘baby')
#方法三
>>> c=dict([('吕布', '口口布'),( '关羽','关习习'), ('刘备','刘baby')])
#方法四
>>> d=dict({'吕布': '口口布', '关羽': '关习习', '刘备': '刘baby'})
##方法五
>>> e=dict({'吕布': '口口布', '关羽': '关习习'},刘备= '刘baby')
#方法六
>>> f=dict(zip(["吕布","关羽","刘备"],["口口布","关习习","刘baby"]))
>>> a
{'吕布': '口口布', '关羽': '关习习', '刘备': '刘baby'}
>>> b
{'吕布': '口口布', '关羽': '关习习', '刘备': '刘baby'}
>>> c
{'吕布': '口口布', '关羽': '关习习', '刘备': '刘baby'}
>>> d
{'吕布': '口口布', '关羽': '关习习', '刘备': '刘baby'}
>>> e
{'吕布': '口口布', '关羽': '关习习', '刘备': '刘baby'}
>>> f
{'吕布': '口口布', '关羽': '关习习', '刘备': '刘baby'}>>> a==b==c==d==e==f
True
15.2、增
fromkeys(iterable[,values])第二个参数是给创建的字典所有键的键值初始化同一个值。
>>> d=dict.fromkeys("Fish",250)
>>> d
{'F': 250, 'i': 250, 's': 250, 'h': 250}
>>> c=dict.fromkeys("Fish")
>>> c
{'F': None, 'i': None, 's': None, 'h': None}
>>> d['F']=70 #给存在的键赋值
>>> d
{'F': 70, 'i': 250, 's': 250, 'h': 250}
>>> d['C']=67 #没有存在的键则会创建
>>> d
{'F': 70, 'i': 250, 's': 250, 'h': 250, 'C': 67}
15.3、删
pop(key[,default])
>>> d.pop("s") #删除后会返回值
250
>>> d
{'F': 70, 'i': 250, 'h': 250, 'C': 67}>>> d.pop("dig") #删除不存在的键会抛出异常
Traceback (most recent call last):File "<pyshell#43>", line 1, in <module>d.pop("dig")
KeyError: 'dig'>>> d.pop("dig","没有")
'没有'
popitem()python3.7之前随机删除一个键,python3.7之后删除最后加入字典的键。
>>> d.popitem()
('C', 67)
>>> d
{'F': 70, 'i': 250, 'h': 250}
del()
>>> del d['i']
>>> d
{'F': 70, 'h': 250}
clear()清空字典中的内容。
15.4、改
update([other])可以同时修改多个键值。
>>> c=dict.fromkeys("Fish")
>>> c
{'F': None, 'i': None, 's': None, 'h': None}
>>> c['s']=115
>>> c
{'F': None, 'i': None, 's': 115, 'h': None}
>>> c.update({'i':105,'h':104})
>>> c
{'F': None, 'i': 105, 's': 115, 'h': 104}
>>> c.update(F='70',C='67')
>>> c
{'F': '70', 'i': 105, 's': 115, 'h': 104, 'C': '67'}
15.5、查
get(key[,default])当找不到键时返回指定的值。
>>> c['C']
'67'
>>> c['c'] #当找不到键时会报错
Traceback (most recent call last):File "<pyshell#64>", line 1, in <module>c['c']
KeyError: 'c'>>> c.get('c','这里没有c')
'这里没有c'
setdefault(key[,default])查找一个键是否存在于字典中,如果在则返回它对应的值,如果不在则给它指定一个新的值。
>>> c.setdefault("C","code")
'67'
>>> c.setdefault("c","code")
'code'
>>> c
{'F': '70', 'i': 105, 's': 115, 'h': 104, 'C': '67', 'c': 'code'}
item()、keys()、values()分布用于获取字典的键值对、键和值的视图对象。- 视图对象即字典的动态视图,这就意味着当字典的内容发生改变的时候,视图对象的内容也会相应地跟着改变。
>>>keys=c.keys()
>>> values=c.values()
>>> items=c.items()
>>> keys
dict_keys(['F', 'i', 's', 'h', 'C', 'c'])
>>> values
dict_values(['70', 105, 115, 104, '67', 'code'])
>>> items
dict_items([('F', '70'), ('i', 105), ('s', 115), ('h', 104), ('C', '67'), ('c', 'code')])#删除c
>>> c.pop('c')
'code'#发生改变
>>> keys
dict_keys(['F', 'i', 's', 'h', 'C'])
>>> values
dict_values(['70', 105, 115, 104, '67'])
>>> items
dict_items([('F', '70'), ('i', 105), ('s', 115), ('h', 104), ('C', '67')])
>>> 15.6、其它操作
copy()浅拷贝
>>> e=c.copy()
>>> e
{'F': '70', 'i': 105, 's': 115, 'h': 104, 'C': '67'}
len()获取字典键值对的数量。in、not in判断某个键是否存在于字典中。list()将字典中所有的键转化为列表,相当于list(d.keys()),要得到所有的值的列表应该是:list(d.values)。iter()将字典的键构成一个迭代器。reversed()python3.8版本以后可以对字典的键或者值进行逆序。
>>> e=iter(c)
>>> next(e)
'F'
>>> next(e)
'i'
>>> next(e)
's'
>>> next(e)
'h'
>>> next(e)
'C'
>>> next(e)
Traceback (most recent call last):File "<pyshell#104>", line 1, in <module>next(e)
StopIteration
>>> list(reversed(c.values()))
['67', 104, 115, 105, '70']
15.7、嵌套
>>> d={"吕布":{"语文":60,"数学":70,"英语":80},"关羽":{"语文":80,"数学":90,"英语":80}}
>>> d
{'吕布': {'语文': 60, '数学': 70, '英语': 80}, '关羽': {'语文': 80, '数学': 90, '英语': 80}}
>>> d["吕布"]["数学"]
70
>>> d={"吕布":[60,70,80],"关羽":[80,90,80]}
>>> d["吕布"][1]
70
15.8、字典推导式
#推导式1
>>> d={'F':70,'i':105,'s':115,'h':104,'C':67}
>>> b={v:k for k,v in d.items()}
>>> b
{70: 'F', 105: 'i', 115: 's', 104: 'h', 67: 'C'}#推导式2
>>> c={v:k for k,v in d.items() if v>100}
>>> c
{105: 'i', 115: 's', 104: 'h'}#推导式3
>>> d={x:ord(x) for x in 'FishC'}
>>> d
{'F': 70, 'i': 105, 's': 115, 'h': 104, 'C': 67}#推导式4
>>> d={x:y for x in[1,3,5] for y in [2,4,6]}
>>> d
{1: 6, 3: 6, 5: 6}
十六、集合(可变容器)
- 集合中所有元素都应该是独一无二的,并且也是无序的。
- 集合分为可变(
set())和不可变对象(frozenset())。
16.1、集合的创建
#方法1
>>> {"Fish","Python"}
{'Python', 'Fish'}#方法2
>>> {s for s in "Python"}
{'h', 'P', 'y', 't', 'o', 'n'}#方法3
>>> set("Python")
{'h', 'P', 'y', 't', 'o', 'n'}
>>> s=set("Python")
>>> s[0] #无法通过下标进行访问
Traceback (most recent call last):File "<pyshell#8>", line 1, in <module>s[0]
TypeError: 'set' object is not subscriptable
>>> "C" in s
False
>>> "C" not in s
True
>>> for each in s:print(each)h
P
y
t
o
n
16.2、集合的唯一性
>>> set([1,1,2,3,4]) #集合去重
{1, 2, 3, 4}>>> s=[1,1,2,3,4,4,5]
>>> len(s)==len(set(s)) #存在重复元素
False
16.3、集合的方法
| 方法 | 含义 |
|---|---|
| s.copy() | 返回s集合的一个浅拷贝 |
| s.isdisjoint(other) | 如果s集合中没有与other容器存在共同的元素,那么返回True,否测返回False |
| s.issubset(other) | 如果s集合是other容器的子集(注1),那么返回True,否则返回False |
| s.issuperset(other) | 如果s集合是other容器的超集(注2),那么返回True,否则返回False |
| s.union(*others) | 返回一个新集合,其内容是s集合与others容器的并集(注3) |
| s.intersection(*others) | 返回一个新集合,其内容是s集合与others容器的交集(注4) |
| s.difference(*others) | 返回一个新集合,其内容是存在于s集合中,但不存在于ohrs容器中的元素(注5) |
| s.symmetric_difference(other) | 返回一个新集合,其内容是排除掉s集合和other容器中共有的元素后,剩余的所有元素 |
- 注1:对于两个集合A、B,如果集合A中任意一个元素都是集合B中的元素,我们就说这两个集合有包含关系,称集合A为集合B的子集(Subset)。
- 注2:对于两个集合A、B,如果集合B中任意一个元素都是集合A中的元素,我们就说这两个集合有包含关系,称集合A为集合B的超集(Superset)。
- 注3:对于两个集合A、B,把他们所有的元素合并在一起组成的集合,叫做集合A与集合B的并集(Union)。
- 注4:对于两个集合A、B,由所有属于集合A且属于集合B的元素所组成的集合,叫做集合A与集合B的交集(Intersection)。
- 注5:对于两个集合A、B,由所有属于集合A且不属于集合B的元素所组成的集合,叫做集合A与集合B的差集(Difference)。
- 注6:others参数表示支持多个容器(参数类型可以是集合,也可以是序列);other参数则表示单个容器。
>>> s=set("Fish")
>>> s
{'i', 'h', 'F', 's'}
>>> s.isdisjoint(set("Python")) #存在一个元素:h是一样的,所以没有毫不相关
False
>>> s.union({1,2,3})
{'h', 1, 2, 3, 'F', 's', 'i'}>>> s.union({11,12,13},{4,5,6}) #可以同时传入多个参数
{'h', 4, 5, 's', 6, 11, 12, 13, 'F', 'i'}
>>> s<=set("FishC") #子集
True
>>> s<set("FishC") #真子集
True
>>> s>set("FishC") #真超集
False
>>> s>=set("FishC") #超集
False
>>> s |{1,2,3} |set("python") #并集
{'h', 1, 2, 3, 's', 'y', 'o', 't', 'n', 'F', 'p', 'i'}
>>> s&set("php")&set("python") #交集
{'h'}>>> s-set("php")-set("python") #差集
{'i', 'F', 's'}
>>> s^set("python") #对称差集
{'s', 'y', 't', 'o', 'F', 'i', 'n', 'p'}
- 上述方法适用于可变集合,也适用于不可变集合。
16.4、仅适用于可变集合的方法
update(*others)使用others参数指定的值来更新集合。
>>> s=set("Python")
>>> s
{'h', 'P', 'y', 't', 'o', 'n'}
>>> s.update([1,1],"23")
>>> s
{'h', 1, 'P', 'y', '3', '2', 't', 'o', 'n'}
intersection_update(*others)difference_update(*others)symmetric_difference_update(others)- 使用交集、差集和对称差集的方式来更新集合。
>>> s
{'i', 'h', 'F', 's'}#未更新
>>> s.difference("php","python")
{'i', 'F', 's'}
>>> s
{'i', 'h', 'F', 's'}#更新
>>> s.difference_update("php","python")
>>> s
{'i', 'F', 's'}
add(elem)在集合里面添加某一个元素。
>>> s.add("45")
>>> s
{'s', 'F', 'i', '45'}
-
remove(elem)、discard(elem)删除元素,区别是:如果删除的元素不存在,remove会抛出异常,discard会静默处理。 -
pop()随机从集合中弹出一个元素。
>>> s
{'s', 'F', 'i', '45'}#抛出异常
>>> s.remove("hh")
Traceback (most recent call last):File "<pyshell#54>", line 1, in <module>s.remove("hh")
KeyError: 'hh'#静默处理
>>> s.discard("hh")#随机弹出
>>> s.pop()
's'
>>> s
{'F', 'i', '45'}
clear()清空集合。
16.5、可哈希
hash(object)获取对象的哈希值。- 如果对一个整数进行哈希,它的哈希值等于它本身。
- 如果两个对象的值是相等的,尽管它们的类型的不相等的,它们的哈希值也应该是相等的。
- python中大多数不可变对象都是可哈希的,可变对象则是不可哈希。
>>> hash(1)
1
>>> hash(1.0)
1
>>> hash(1.0001)
230584300921345
>>> hash("Python") #字符串是不可变对象
-6475281903347296222>>> hash([1,2,3]) #列表是可变对象
Traceback (most recent call last):File "<pyshell#62>", line 1, in <module>hash([1,2,3])
TypeError: unhashable type: 'list'
- 只有可哈希的对象才有资格做字典的键以及集合的元素。
十七、函数
17.1、创建和调用函数
#创建
>>> def myfun():print("hello")#调用
>>> myfun()
hello
17.2、函数的参数
- 函数的参数分为2种:形式参数和实际参数。
- 形式参数(形参):函数定义的参数
- 实际参数(实参):实际传入的值
>>> def myfun(name,times):for i in range(times):print(f"hello {name}!")>>> myfun("python",3)
hello python!
hello python!
hello python!
17.2.1、位置参数
- python中将位置固定的参数称为位置参数。
>>> def myfun(s,vt,o): #将传入的参数顺序对调return " ".join((o,vt,s))>>> myfun("I","Love","Python")
'Python Love I'
- 需要按顺序传入参数的值。
17.2.2、关键字参数
>>> myfun(o="I",vt="Love",s="Python")
'I Love Python'
help()查看函数的用法
>>> help(abs)
Help on built-in function abs in module builtins:abs(x, /) #/的左侧不能够使用位置关键字参数,只能够使用位置参数;右侧没有限制Return the absolute value of the argument.
>>> abs(4)
4
>>> abs(x=4) #使用关键字参数,发生报错
Traceback (most recent call last):File "<pyshell#57>", line 1, in <module>abs(x=4)
TypeError: abs() takes no keyword arguments
>>> def abc(a,/,b,c): #/的左侧不能够使用位置关键字参数,只能够使用位置参数;右侧没有限制print(a,b,c)>>> abc(1,2,3)
1 2 3
>>> abc(a=1,2,3)
SyntaxError: positional argument follows keyword argument
>>> def abc(a,*,b,c): #*的左侧没有限制,右侧只能是关键字参数print(a,b,c)>>> abc(1,2,3)
Traceback (most recent call last):File "<pyshell#65>", line 1, in <module>abc(1,2,3)
TypeError: abc() takes 1 positional argument but 3 were given
>>> abc(1,b=2,c=3)
1 2 3
17.2.3、默认参数
- 在函数的参数定义式指定默认值。
>>> def myfun(s,vt,o="Java"):return " ".join((o,vt,s))>>> myfun("I","Love") #当未指定参数时,使用默认值。
'Java Love I'
>>> myfun(o="I",vt="Love",s="Python")
'I Love Python'
- 在指定默认值时,需要将指定默认值的参数放在后面,否则会报错。
#报错
>>> def myfun(s="I",vt,o="Java"):return " ".join((o,vt,s))
SyntaxError: non-default argument follows default argument#未报错
>>> def myfun(vt,s="I",o="Java"):return " ".join((o,vt,s))>>> myfun("Like")
'Java Like I'
17.2.4、收集参数
>>> def myfun(*args):print("有{}个参数".format(len(args)))print("第2个参数是:{}".format(args[1]))print(args)>>> myfun(1,2,3,4,5)
有5个参数
第2个参数是:2
(1, 2, 3, 4, 5) #将多个参数打包为元组
- 如果在收集参数后面还需要指定其它参数,那么,在调用函数的时候应该使用关键字参数来指定后面的参数。
- 收集参数还可以将多个参数打包为字典。
>>> def myfun(**kwargs):print(kwargs)>>> myfun(a=1,b=2,c=3)
{'a': 1, 'b': 2, 'c': 3}
>>> def myfun(a,*b,**c):print(a,b,c)>>> myfun(1,2,3,4,x=5,y=6,z=7)
1 (2, 3, 4) {'x': 5, 'y': 6, 'z': 7}
17.2.5、解包参数
>>> def myfun(a,b,c,d):print(a,b,c,d)>>> args=(1,2,3,4)
>>> myfun(*args) #解包元组
1 2 3 4>>> kwargs={'a':1,'b':2,'c':3,'d':4}
>>> myfun(**kwargs) #解包字典
1 2 3 4
17.3、函数的返回值
- 使用
return语句返回要返回的内容。
>>> def div(x,y):return x/y>>> div(4,2)
2.0
>>> def div(x,y):if y==0:return "除数不能为0"return x/y>>> div(3,0)
'除数不能为0'
- 如果一个函数没有通过
return语句显式的返回内容,它也会在自己执行完函数体的所有语句后隐式的返回None值。
>>> def myfun():pass>>> print(myfun())
None
- 返回多个值:元组的形式返回。
>>> def myfun():return 1,2,3>>> myfun()
(1, 2, 3)
>>> def myfun():return 1,2,3>>> x,y,z=myfun()
>>> x
1
>>> y
2
>>> z
3
17.4、作用域
- 一个变量可以访问的范围。
- 局部作用域:如果一个变量定义的位置是在一个函数里面,那么它的作用域仅限于该函数。
- 全局作用域:如果是在任何函数的外部去定义一个变量,那么它的作用域是全局。
- 在局部中,局部变量会覆盖同名的全局变量。
>>> x=880
>>> def myfun():x=520 #在函数里面无法修改全局变量的值,只会创建一个同名的局部变量print(x)>>> myfun()
520
>>> x
880
17.5、global语句
- 使用
global语句可以在函数内部修改全局变量的值。
>>> x=880
>>> def myfun():global xx=520print(x)>>> myfun()
520
>>> x
520
17.6、嵌套函数
>>> def funA():x=520def funB():x=880print("In funB,x=",x)funB()print("In funA,x=",x)>>> funB() #在外部无法直接调用函数的内部函数,要在函数内部进行调用
Traceback (most recent call last):File "<pyshell#127>", line 1, in <module>funB()
NameError: name 'funB' is not defined
>>> funA()
In funB,x= 880
In funA,x= 520
- 同样,内部函数无法直接修改外部函数的变量的值。
17.7、nonlocal语句
- 使用
nonlocal语句,可以实现内部函数修改外部函数的变量的值。
>>> def funA():x=520def funB():nonlocal xx=880print("In funB,x=",x)funB()print("In funA,x=",x)>>> funA()
In funB,x= 880
In funA,x= 880
17.8、LEGB规则
L:Local,局部作用域E:Enclosed,嵌套函数的外层函数作用域G:Global,全局作用域B:Build-In,内置作用域
17.9、闭包
1、利用嵌套函数的外层作用域具有记忆能力这个特性
2、将内层函数作为返回值给返回
>>> def funA():x=880def funB():print(x)return funB>>> funA()
<function funA.<locals>.funB at 0x0000029A922941F0>
>>> funA()()
880>>> a=funA()
>>> a
<function funA.<locals>.funB at 0x0000029A92294550>
>>> a()
880>>> def power(exp):def exp_of(base):return base ** expreturn exp_of>>> square=power(2)
>>> cube=power(3)>>> square(2) #2的2次方
4
>>> square(3) #3的2次方
9
>>> cube(2) #2的3次方
8
>>> cube(3) #3的3次方
27
17.10、装饰器
>>> def myfun():print("调用函数myfun")>>> def report(fun):print("开始调用函数")myfun()print("调用函数结束")>>> report(myfun)
开始调用函数
调用函数myfun
调用函数结束
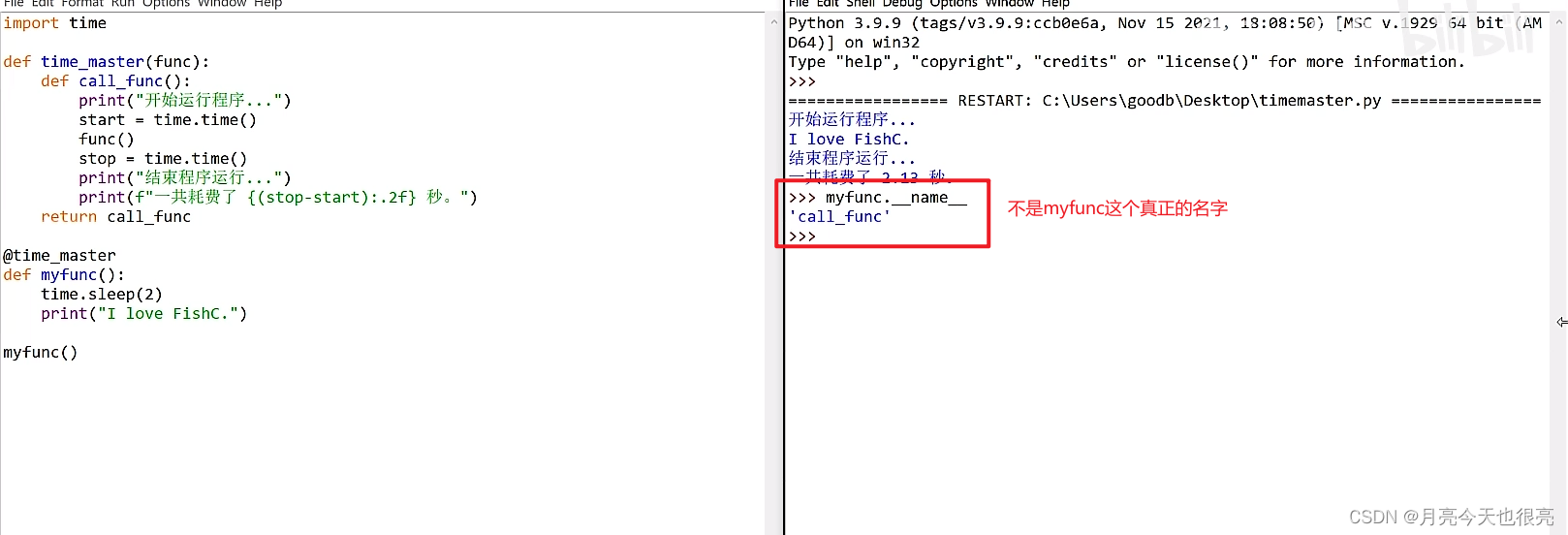
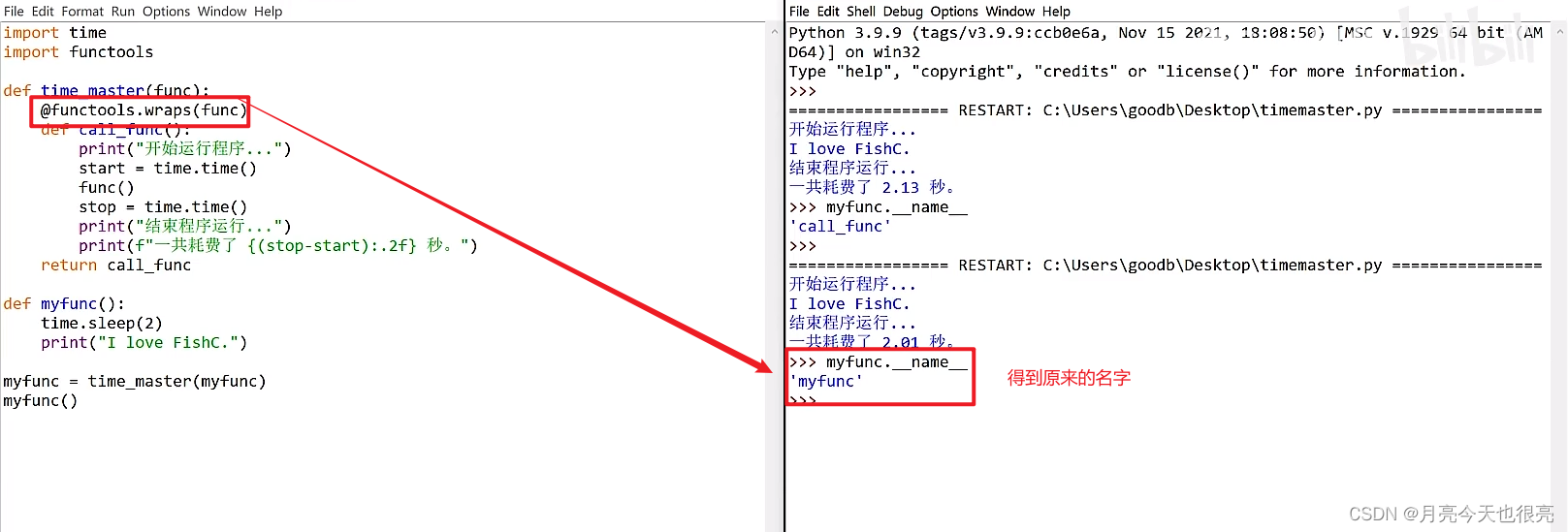
import time
def time_master(func):def call_func():print("开始运行程序,,,")start = time.time()func()stop = time.time()print("结束程序运行..")print(f"一共耗费了{(stop-start):.2f}秒。")return call_func@time_master #使用装饰器
def myfunc():time.sleep(2)print("I love FishC.")myfunc() #调用myfunc()
#运行结果:
开始运行程序,,,
I love FishC.
结束程序运行..
一共耗费了2.01秒。#没有使用装饰器如下:
def myfunc():time.sleep(2)print("I love FishC.")myfunc=time_master(myfunc)
myfunc()def add(func):def inner():x=func()return x+1return inner
def cube(func):def inner():x=func()return x*x*xreturn inner
def square(func):def inner():x=func()return x*xreturn inner@add
@cube
@square
def test():return 2
print(test())#结果:先执行square,再cube、再add
65
import time
def logger(msg):def time_master(func):def call_func():start=time.time()func()stop=time.time()print(f"[{msg}]一共耗费了{(stop-start):.2f}")return call_funcreturn time_master
@logger(msg="A") #装饰器也可以传入参数
def funA():time.sleep(1)print("正在调用funA...")@logger(msg="B")
def funB():time.sleep(1)print("正在调用funB...")funA()
funB()
#结果:
正在调用funA...
[A]一共耗费了1.01
正在调用funB...
[B]一共耗费了1.05#没有使用装饰器的结果如下:
def funB():time.sleep(1)print("正在调用funB...")funA=logger(msg='A')(funA)
funB=logger(msg='B')(funB)
funA()
funB()
17.11、lambda表达式
lambda arg1,arg2,arg3,..argN : expression
>>> def squareX(x):return x*x>>> squareX(3)
9
>>> squareX
<function squareX at 0x0000020F73E54280>>>> squareY=lambda y:y*y
>>> squareY(3)
9
>>> squareY
<function <lambda> at 0x0000020F73E545E0>
>>> mapped=map(lambda x:ord(x)+10,"FishC")
>>> list(mapped)
[80, 115, 125, 114, 77]
17.12、生成器
- 生成器表达式
>>> def counter():i=0while i<=5:yield ii+=1>>> for i in counter():print(i)0
1
2
3
4
5
>>>
>>> c=counter()
>>> c
<generator object counter at 0x0000020F73E69120>
>>> next(c)
0
>>> next(c)
1
>>> next(c)
2
>>> next(c)
3
>>> next(c)
4
>>> next(c)
5
>>> next(c)
Traceback (most recent call last):File "<pyshell#73>", line 1, in <module>next(c)
StopIteration
#斐波那契数列生成器
>>> def fib():back1,back2=0,1while True:yield back1back1,back2=back2,back1+back2>>> f=fib()
>>> next(f)
0
>>> next(f)
1
>>> next(f)
1
>>> next(f)
2
>>> next(f)
3
>>> next(f)
5
>>> next(f)
8
>>> t=(i ** 2 for i in range(10))
>>> next(t)
0
>>> next(t)
1
>>> next(t)
4
>>> next(t)
9
>>> next(t)
16
>>> for i in t:print(i)25
36
49
64
81
17.13、递归
- 递归就是函数调用自身的过程。
#阶乘#使用迭代
>>> def factIter(n):result=nfor i in range(1,n):result*=ireturn result>>> factIter(5)
120#使用递归
>>> def factRecur(n):if n==1:return 1else:return n*factRecur(n-1)>>> factRecur(5)
120
#斐波那契数列#使用迭代
>>> def fibIter(n):a=1b=1c=1while n>2:c=a+ba=bb=cn-=1return c>>> fibIter(12)
144#使用递归
>>> def fibRecur(n):if n==1 or n==2:return 1else:return fibRecur(n-1)+fibRecur(n-2)>>> fibRecur(12)
144
17.14.1、汉诺塔
- 有A、B、C三根柱子,在A上有64个从下到上依次增大的圆盘。
- 需要借助B将A上的所有圆盘移动到C上。
- 一次只能够移动一个圆盘。
- 小的圆盘必须在大的圆盘的上面。
>>> def hanoi(n,x,y,z):if n==1:print(x,'-->',z) #如果只有 1 层,直接将圆盘从 x 移动到 zelse:hanoi(n-1,x,z,y) #将 x 上的 n-1 个圆盘移动到 yprint(x,'-->',z) #将最底下的圆盘从 x 移动到 zhanoi(n-1,y,x,z) #将 y 上的 n-1 个圆盘移动到 z>>> hanoi(3,'A','B','C')
A --> C
A --> B
C --> B
A --> C
B --> A
B --> C
A --> C
17.14、函数文档、类型注释、内省
- 函数文档
>>> def exchange(dollar,rate=6.32):"""功能:汇率转换,美元 -> 人民币参数:- dollar 美元数量- rate 汇率,默认值是 6.32返回值:- 人民币的数量"""return dollar*rate>>> exchange(20)
126.4
>>> help(exchange)
Help on function exchange in module __main__:exchange(dollar, rate=6.32)功能:汇率转换,美元 -> 人民币参数:- dollar 美元数量- rate 汇率,默认值是 6.32返回值:- 人民币的数量
- 类型注释
>>> def times(s:str,n:int) -> str: #函数的作者希望传入的参数s为字符串类型,n为整型,则返回值为字符串类型return s*n>>> times("Hello",5)
'HelloHelloHelloHelloHello'>>> times(5,5) #若是传入的参数s为整型,也会执行,不会报错
25
- 内省
>>> times.__name__ #查看函数的名字
'times'
>>> times.__annotations__ #查看函数的类型注释
{'s': <class 'str'>, 'n': <class 'int'>, 'return': <class 'str'>}
>>> exchange.__doc__ #查看函数文档
'\n\t功能:汇率转换,美元 -> 人民币\n\t参数:\n\t- dollar 美元数量\n\t- rate 汇率,默认值是 6.32\n\t返回值:\n\t- 人民币的数量\n\t
17.15、高阶函数
- 当一个函数接收另一个函数作为参数的时候,那么这个函数就被称为高阶函数。
>>> def add(x,y):return x+y>>> import functools
>>> functools.reduce(add,[1,2,3,4,5])
15#相当于:
>>> add(add(add(add(1,2),3),4),5)
15#使用lambda表达式
>>> functools.reduce(lambda x,y:x*y,range(1,11))
3628800
- 偏函数:是指对指定的函数做二次包装。
>>> square=functools.partial(pow,exp=2)
>>> square(2)
4
>>> square(9)
81
@wraps装饰器:
十八、永久存储
18.1、file文件
1、 file参数
| 方法 | 含义 |
|---|---|
| f.close() | 关闭文件对象 |
| f.flush() | 将文件对像中的缓存数据写入到文件中(不一定有效) |
| f.read(size=-1,/) | 从文件对缘中读取指定数量的字符(或者遇到EOF停止);当未指定该参数,或该参数为负值的时候,读取剩余的所有字符 |
| f.readable() | 判断该文件对象是否支持读取(如果返回的值为False,则调用read()方法会导致OSError异常) |
| f.readline(size=-1,/) | 从文件对像中读取一行字符串(包括换行符),如果指定了size参数,则表示读取size个字符 |
| f.seek(offset,whence=0,/) | 修改文件指针的位置,从whence参数指定的位置(0代表文件起始位置,1代表当前位置,2代表文件末尾)偏移offset个字节,返回值是新的索引位置 |
| f.seekable() | 判断该文件对象是香支持修改文件指针的位置(如果返回的值为False,则调用seek(),tell(),truncate()方法都会导致OSError异常) |
| f.tell() | 返回当前文件指针在文件对象中的位置 |
| f.truncate(pos=None,/) | 将文件对像截取到pos的位置,默认是截取到文件指针当前指定的位置 |
| f.write(text,/) | 将字符串写入到文件对象中,并返回写入的字符数量(字符串的长度) |
| f.writable() | 判断该文件对象是否支持写入(如果返回的值为False,则调用write()方法会导致OSError异常) |
| f.writelines(lines,/) | 将一系列字符串写入到文件对象中(不会自动添加换行符,所以通常是人为地加在每个字符串的末尾) |
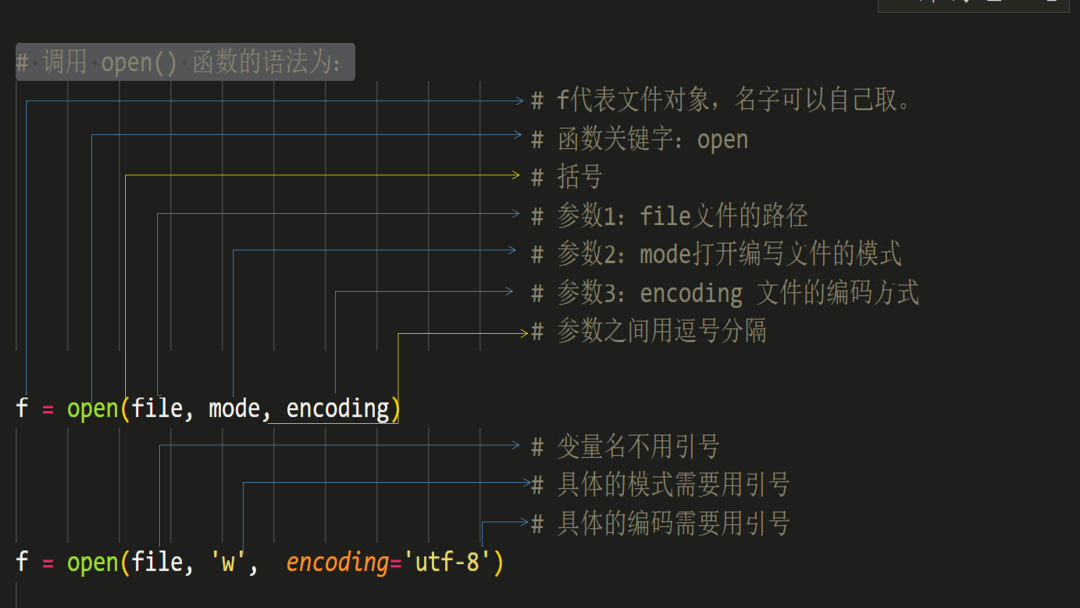
>>> f=open(r"D:/test.txt","w")
>>> f.write("I love python.")
14
>>> f.writelines(["I love python\n","I love Java."]) #此时文件的内容还没有写入到文件test.txt中,而是在缓冲区,需要将文件关闭才可以写入
>>> f.close()
>>> 
>>> f=open(r"D:/test.txt","r+")
>>> f.readable() #可读取
True
>>> f.writable() #可写入
True
>>> for each in f: #读取print(each)I love python.I love pythonI love Java.
>>> f.read() #没有读到文件内容,是因为指针以及到了文件末尾
''
>>> f.tell() #查看指针位置
41
>>> f.seek(0) #将指针位置定位到开头
0
>>> f.read() #重新读取
'I love python.I love python\nI love Java.'
可能出现的错误:
>>> f=open(r"D:/test.txt","w")
>>> f.close() #将文件打开,没有做什么事情就关闭

–>文件内容被清空。
2、mode参数
mode 是顺位第二的参数,使用时可以省略参数名称。例如,以下两个是完全相同的:
with open('test.txt', mode='w') as f:
with open('test.txt', 'w') as f:
-
四种基本 mode:
r:只读。默认值。如果文件不存在,抛出 FileNotFoundError 异常。w:创建文件,写入。如果文件已存在,则清空该文件。x:创建文件。如果文件已存在,抛出 FileExistsError 异常。a:创建文件,追加。如果文件已存在,则在文件末尾追加内容。
-
以下两种 mode 需要与四种基本 mode 一起使用:
t:以本文(text)模式读写。默认值(r 和 rt 完全相同,w 和 wt 完全相同,等等)。b:以二进制(binary)模式读写。对于非文本文件(图片、音频等),或想复制移动文件,可以使用 b 模式。
-
当 mode 参数缺省时,默认是
rt模式。 -
此外还有一个 mode:
+:更新文件,可读可写。- 该为mode 需要与上述 4+2 种 mode 一起使用。
- 例如:
r+:可读可写,指针位于文件开始(指向第 0 个字符,读写将从第 1 个字符开始)。w+:可读可写,创建一个空文件(如果文件已存在,则清空该文件),指针位于文件开始。x+:可读可写,创建一个空文件(如果文件已存在,抛出 FileExistsError 异常),指针位于文件开始。a+:可读可写,指针位于文件末尾。
18.2、路径
pwd()获取当前目录的路径
>>> from pathlib import Path #需要导入模块
>>> Path.cwd()
WindowsPath('D:/A/Holiday/python2')>>> p=Path('D:/A/Holiday/python2') #生成路径对象
>>> p
WindowsPath('D:/A/Holiday/python2')>>> q=p/"test.py" #路径拼接
>>> q
WindowsPath('D:/A/Holiday/python2/test.py')
is_dir()判断一个路径是否为一个文件夹。is_file()判断一个路径是否为一个文件。
>>> q.is_file()
True
exists()判断一个路径是否存在。
>>> q.exists()
True
>>> Path("C:/404").exists()
False
name获取路径的最后一个部分。
>>> q.name
'test.py'
stem获取文件名。
>>> q.stem
'test'
suffix获取文件后缀。
>>> q.suffix
'.py'
parent获取父级目录。
>>> q.parent
WindowsPath('D:/A/Holiday/python2')
parents获取逻辑祖先路径构成的序列。
>>> q.parents
<WindowsPath.parents>#支持迭代
>>> ps=p.parents
>>> for each in ps:print(each)D:\A\Holiday
D:\A
D:\#支持索引
>>> ps[0]
WindowsPath('D:/A/Holiday')
>>> ps[1]
WindowsPath('D:/A')
>>> ps[2]
WindowsPath('D:/')
parts将路径的各个组件拆分成元组。stat()查询文件或文件夹的信息。
>>> q.parts
('D:\\', 'A', 'Holiday', 'python2', 'test.py')>>> q.stat()
os.stat_result(st_mode=33206, st_ino=12103423998600354, st_dev=2420028616, st_nlink=1, st_uid=0, st_gid=0, st_size=134, st_atime=1690611084, st_mtime=1689255518, st_ctime=1689134952)
>>> q.stat().st_size #文件或者文件夹的尺寸
134
resolve()将相对路径转换为绝对路径。iterdir()获取当前路径下所有子文件和子文件夹。
>>> p.iterdir()
<generator object Path.iterdir at 0x0000027E388E36D0>
>>> for each in p.iterdir():print(each)D:\A\Holiday\python2\test.py
D:\A\Holiday\python2\test.txt>>> [x for x in p.iterdir() if x.is_file()]
[WindowsPath('D:/A/Holiday/python2/test.py'), WindowsPath('D:/A/Holiday/python2/test.txt')]
mkdir()创建文件夹。
>>> n= p / 'test' #如果要创建的文件夹已经存在,则会报错
>>> n.mkdir()>>> n.mkdir()
Traceback (most recent call last):File "<pyshell#161>", line 1, in <module>n.mkdir()File "D:\python\python3.8\lib\pathlib.py", line 1279, in mkdirself._accessor.mkdir(self, mode)
FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。: 'D:\\A\\Holiday\\python2\\test'>>> n.mkdir(exist_ok=True) #忽略报错信息
>>> n=p / "test/A/B/C"
>>> n.mkdir(exist_ok=True) #如果路径中存在多个不存在的父级目录也会报错。
Traceback (most recent call last):File "<pyshell#165>", line 1, in <module>n.mkdir(exist_ok=True)File "D:\python\python3.8\lib\pathlib.py", line 1279, in mkdirself._accessor.mkdir(self, mode)
FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'D:\\A\\Holiday\\python2\\test\\A\\B\\C'>>> n.mkdir(parents=True,exist_ok=True) #将parents的参数设置为True,则可成功创建
>>>
open()打开文件。rename()修改文件或文件夹的名字。
>>> q
WindowsPath('D:/A/Holiday/python2/test.py')
>>> q.rename('D:/A/Holiday/python2/NewTest.py')
WindowsPath('D:/A/Holiday/python2/NewTest.py')
replace()替换指定的文件或文件夹。
>>> q
WindowsPath('D:/A/Holiday/python2/NewTest.py')
>>> n
WindowsPath('D:/A/Holiday/python2/test/A/B/C/Test.py')
>>> q.replace(n)
WindowsPath('D:/A/Holiday/python2/test/A/B/C/Test.py')

rmdir()、unlink()删除文件夹、删除文件。
>>> n.parent
WindowsPath('D:/A/Holiday/python2/test/A/B/C')>>> n.parent.rmdir() #由于目录不是空的无法删除
Traceback (most recent call last):File "<pyshell#191>", line 1, in <module>n.parent.rmdir()File "D:\python\python3.8\lib\pathlib.py", line 1327, in rmdirself._accessor.rmdir(self)
OSError: [WinError 145] 目录不是空的。: 'D:\\A\\Holiday\\python2\\test\\A\\B\\C'>>> n.unlink() #先将里面的文件删除
>>> n.parent.rmdir() #再删除该目录
glob()查找。
>>> q
WindowsPath('D:/A/Holiday/python2/NewTest.py')
>>> q.parent.glob("*.txt")
<generator object Path.glob at 0x0000027E388E3900>
>>> list(q.parent.glob("*.txt")) #当前目录的所有txt文件
[WindowsPath('D:/A/Holiday/python2/1.txt'), WindowsPath('D:/A/Holiday/python2/2.txt'), WindowsPath('D:/A/Holiday/python2/3.txt'), WindowsPath('D:/A/Holiday/python2/test.txt')]>>> list(q.parent.glob("*/*.txt")) #当前目录的下一级目录的所有txt文件>>> list(q.parent.glob("**/*.txt")) #在当前目录以及该目录下面的所有子目录中查找txt文件
[WindowsPath('D:/A/Holiday/python2/1.txt'), WindowsPath('D:/A/Holiday/python2/2.txt'), WindowsPath('D:/A/Holiday/python2/3.txt'), WindowsPath('D:/A/Holiday/python2/test.txt')]
18.3、with语句和上下文管理器
#情况一:
>>> f=open("D:/A/Holiday/python2/test.txt","w")
>>> f.write("I Love Python")
13
>>> f.close()#情况二:
>>> with open("D:/A/Holiday/python2/test.txt","w") as f:f.write("I Love Python")13
-
情况一和二是等效的。
-
pickle运行将字符串、列表、字典等python对象保存为文件的形式。 -
写(
pickle.dump()):保存的文件后缀名是pkl
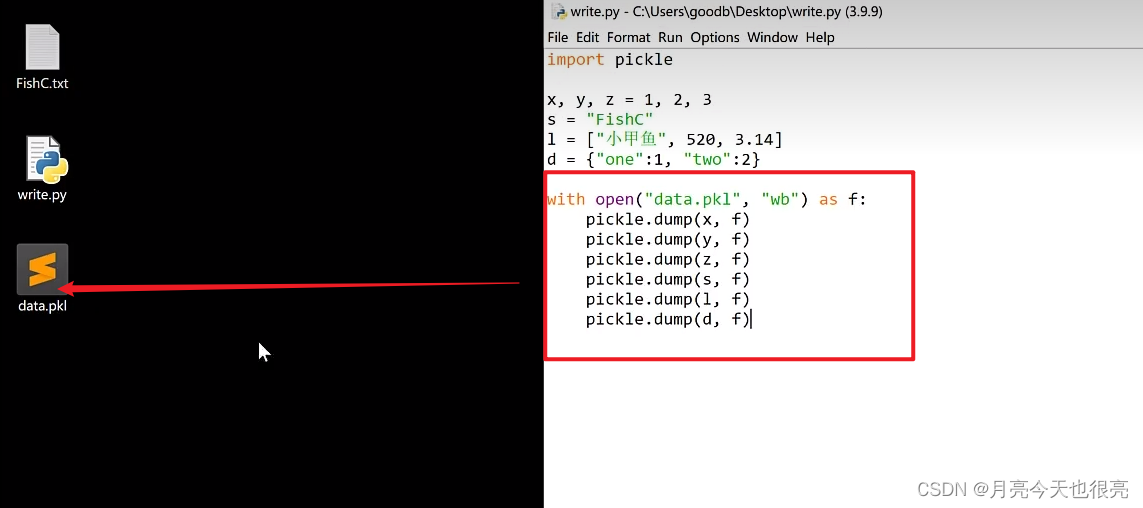
-
读(
pickle.load()):
-
简化读与写:

十九、异常
try:检测范围
except [expression [as identifier]]:异常处理代码
>>> try:1/0
except:print("error")error
>>> try:1/1
except:print("error")1.0
>>> try:520+"1314"
except ZeroDivisionError: #只会捕获ZeroDivisionErro的错误,其它错误捕获捕获print("error")Traceback (most recent call last):File "<pyshell#8>", line 2, in <module>520+"1314"
TypeError: unsupported operand type(s) for +: 'int' and 'str'
>>>
>>> try:1/0
except ZeroDivisionError as e: #提取异常的原因print(e)division by zero
>>> try:1/0520+"1314"
except (ZeroDivisionError,ValueError,TypeError): #将可能出现的异常用元组包裹起来pass#多个except语句
>>> try:1/0520+"1314"
except ZeroDivisionError:print("除数不能为0!")
except ValueError:print("值不正确!")
except TypeError:print("类型不正确")除数不能为0!
try-except-else当try语句里面没有检测出任何异常的情况下,则会执行else里面的语句。
#出现异常
>>> try:1/0
except:print("Error")
else:print("Right")Error#没有异常
>>> try:1/1
except:print("Error")
else:print("Right")1.0
Right
try-except-finally无论异常是否发生,都必须执行的内容。
>>> try:1/1
except:print("Error")
else:print("Right")
finally:print("OK")1.0
Right
OK
>>> try:1/0
except:print("Error")
else:print("Right")
finally:print("OK")Error
OK
#没有使用except语句
>>> try:while True:pass
finally:print("Good")Good
Traceback (most recent call last):File "<pyshell#38>", line 3, in <module>pass
KeyboardInterrupt
try:检测范围
except [expression [as identifier]]:异常处理代码
[except [expression [as identifier]]:异常处理代码]*
[else:没有触发异常时执行的代码]
[finally:收尾工作执行的代码]
try检测范围
finally:收尾工作执行的代码
#嵌套异常
>>> try:try:520+"1314"except:print("Inner")1/0
except:print("Outter")
finally:print("Over")Inner
Outter
Over
#内部异常被跳过
>>> try:1/0try:520+"1314"except:print("Inner")
except:print("Outter")
finally:print("Over")Outter
Over
raise语句,直接抛出异常,不能够直接抛出不存在的异常。
>>> raise ValueError("值不正确")
Traceback (most recent call last):File "<pyshell#52>", line 1, in <module>raise ValueError("值不正确")
ValueError: 值不正确
>>> try:1/0
except:raise ValueError("这样可不行~")Traceback (most recent call last):File "<pyshell#61>", line 2, in <module>1/0
ZeroDivisionError: division by zeroDuring handling of the above exception, another exception occurred:Traceback (most recent call last):File "<pyshell#61>", line 4, in <module>raise ValueError("这样可不行~")
ValueError: 这样可不行~
#异常链
>>> raise ValueError("值不正确") from ZeroDivisionError
ZeroDivisionErrorThe above exception was the direct cause of the following exception:Traceback (most recent call last):File "<pyshell#53>", line 1, in <module>raise ValueError("值不正确") from ZeroDivisionError
ValueError: 值不正确
assert语句与raise语句功能类似,但是只能够引发一个叫做AssertionError的异常。
>>> s="Hello"
>>> assert s=="Hello" #相等,什么也没有发生
>>> assert s!="Hello" #不相等,抛出异常
Traceback (most recent call last):File "<pyshell#56>", line 1, in <module>assert s!="Hello"
AssertionError
- 利用异常来实现
goto
>>> try:while True:while True:for i in range(10):if i>3:raiseprint(i)print("被跳过~")print("被跳过~")print("被跳过~")
except:print("跳到这里来了~")0
1
2
3
跳到这里来了~
二十、类和对象
20.1、封装
>>> class Turtle:head=1 #属性eyes=2legs=4shell=Truedef crawl(self): #方法print("我爬~")def run(self):print("我跑~")def bite(self):print("我咬~")def eat(self):print("我吃~")def sleep(self):print("Zzzz...")>>> t1=Turtle()
>>> t1.head
1
>>> t1.crawl()
我爬~
>>>
>>> t2=Turtle()
>>> t2.head=2
>>> t2.head
2
>>> t1.head
1
>>>
>>> t1.mount=1 #新增一个属性
>>> dir(t1)
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'bite', 'crawl', 'eat', 'eyes', 'head', 'legs', 'mount', 'run', 'shell', 'sleep']
#t1多增加一个属性mount>>> dir(t2)
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'bite', 'crawl', 'eat', 'eyes', 'head', 'legs', 'run', 'shell', 'sleep']
#t2没有多增加一个属性mount
>>>
20.2、继承
- 通过继承创建的新类称之为子类,而被继承的类被称之为父类、基类或者超类。
>>> class A:x=520def hello(self):print("Hello,I'm A")>>> class B(A):pass>>> b=B()
>>> b.x
520
>>> b.hello()
Hello,I'm A
>>> class B(A):x=880def hello(self):print("Hello,I'm B")>>> b=B()
>>> b.x
880
>>> b.hello()
Hello,I'm B
isinstance()判断一个对象是否属于某个类。issubclass()用于检测一个类是否为某个类的子类。
>>> isinstance(b,B)
True
>>> isinstance(b,A)
True>>> issubclass(A,B)
False
>>> issubclass(B,A)
True
- python支持多重继承:一个子类可以同时继承多个父类。
>>> class A:x=520def hello(self):print("Hello,I'm A")>>> class B(A):x=880y=250def hello(self):print("Hello,I'm B")>>> class C(A,B): #继承多个父类的时候,访问的顺序是从左到右的pass>>> c=C()
>>> c.x
520
>>> c.hello()
Hello,I'm A
>>> class C(B,A):pass>>> c=C()
>>> c.x
880
>>> c.hello()
Hello,I'm B
20.3、组合
>>> class Turtle:def say(self):print("我说~")>>> class Cat:def say(self):print("喵喵喵")>>> class Dog:def say(self):print("汪汪汪")>>> class Garden:t=Turtle()c=Cat()d=Dog()def say(self):self.t.say()self.c.say()self.d.say()>>> g=Garden()
>>> g.say()
我说~
喵喵喵
汪汪汪
20.4、构造函数
- 使用到
_init_()函数
>>> class C:def __init__(self,x,y):self.x=xself.y=ydef add(self):return self.x+self.ydef mul(self):return self.x * self.y>>> c=C(2,3)
>>> c.add()
5
>>> c.mul()
6
>>> c.__dict__
{'x': 2, 'y': 3}
20.5、重写
#调用未绑定的父类方法,有时候可能会造成钻石继承的问题
>>> class D:def __init__(self,x,y,z):C.__init__(self,x,y)self.z=zdef add(self):return C.add(self)+self.zdef mul(self):return C.mul(self)*self.z>>> d=D(2,3,4)
>>> d.add()
9
>>> d.mul()
24
20.6、钻石继承
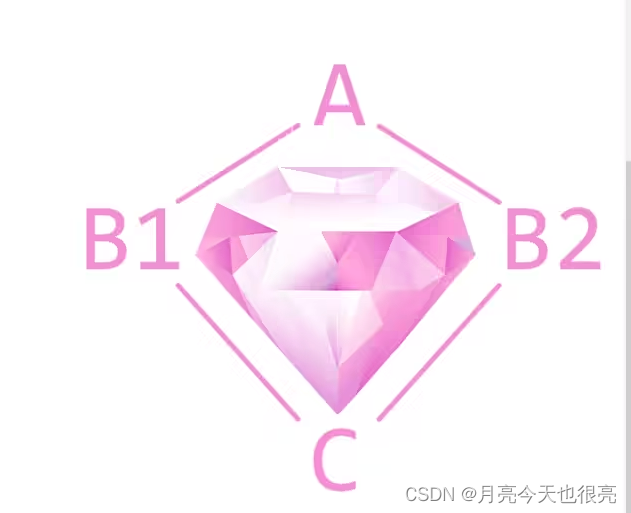
>>> class A:def __init__(self):print("Hello,I'm A.")>>> class B1(A):def __init__(self):A.__init__(self)print("Hello,I'm B1.")>>> class B2(A):def __init__(self):A.__init__(self)print("Hello,I'm B2.")>>> class C(B1,B2):def __init__(self):B1.__init__(self)B2.__init__(self)print("Hello,I'm C.")>>> c=C() #可以看到A被打印了两遍
Hello,I'm A.
Hello,I'm B1.
Hello,I'm A.
Hello,I'm B2.
Hello,I'm C.
>>>
- 使用
super()函数避免钻石继承的问题。
>>> class B1(A):def __init__(self):super().__init__()print("Hello,I'm B1.")>>> class B2(A):def __init__(self):super().__init__()print("Hello,I'm B2.")>>> class C(B1,B2):def __init__(self):super().__init__()print("Hello,I'm C.")>>> c=C()
Hello,I'm A.
Hello,I'm B2.
Hello,I'm B1.
Hello,I'm C.
20.7、MRO
Method Resolution Order方法解析顺序。
>>> C.mro()
[<class '__main__.C'>, <class '__main__.B1'>, <class '__main__.B2'>, <class '__main__.A'>, <class 'object'>]
>>> B1.mro()
[<class '__main__.B1'>, <class '__main__.A'>, <class 'object'>]>>> C.__mro__
(<class '__main__.C'>, <class '__main__.B1'>, <class '__main__.B2'>, <class '__main__.A'>, <class 'object'>)
>>> B1.__mro__
(<class '__main__.B1'>, <class '__main__.A'>, <class 'object'>)
20.8、“私有变量”
就是指通过某种手段,使得对象中的属性或方法无法被外部所访问。
>>> class C:def __init__(self,x):self.__x=xdef set_x(self,x):self.__x=xdef get_x(self):print(self.__x)>>> c=C(250)
>>> c.__x #无法直接获取
Traceback (most recent call last):File "<pyshell#9>", line 1, in <module>c.__x
AttributeError: 'C' object has no attribute '__x'>>> c.get_x()
250
>>> c.set_x(520)
>>> c.get_x()
520#若是一定要直接获取,使用__dict__查看
>>> c.__dict__
{'_C__x': 520} #名字被改编
>>> c._C__x
520
>>> c._C__x=222
>>> c.__dict__
{'_C__x': 222}
>>> class D:def __func(self):print("Hello.")>>> d=D()
>>> d.__func() #无法直接访问
Traceback (most recent call last):File "<pyshell#23>", line 1, in <module>d.__func()
AttributeError: 'D' object has no attribute '__func'>>> d._D__func() #硬是要访问,使用改编后的名字进行访问
Hello.
>>> c.__y=250 #动态添加私有变量
>>> c.__dict__
{'_C__x': 222, '__y': 250} #动态添加的私有变量名字没有被改编
- _单个下划线开头的变量:仅供内部使用的变量
- 单个下划线结尾的变量_: 用于避免于Python关键字冲突的变量,如
class_
>>> class C:__slots__=['x','y'] #该类允许存在的属性def __init__(self,x):self.x=x>>> c=C(250)
>>> c.x
250
>>> c.y=520
>>> c.y
520
>>> c.z=666 #z不允许添加
Traceback (most recent call last):File "<pyshell#40>", line 1, in <module>c.z=666
AttributeError: 'C' object has no attribute 'z'
- 继承自父类的
__slots__属性是不会在子类中生效的。
20.9、魔法方法
-
__init__(self[,...]) -
__add(self,other)__
>>> class S(str):def __add__(self,other): #相当于s1.__add__(s2)return len(self)+len(other)>>> s1=S("Hello")
>>> s12=S("Python")
>>> s1+s12
11>>> s1+"Python"
11
>>> "Hello"+s12
'HelloPython'
__radd__(self,ohter)当两个对象相加的时候,如果左侧的对象和右侧的对象不同类型,并且左侧的对象没有定义__add__()方法,或者其__add__()返回Notlmplemented,那么Python就会去右侧的对象中找查找是否有__radd__()方法的定义。
>>> class S1(str):def __add__(self,other):return NotImplemented>>> class S2(str):def __radd__(self,other):return len(self)+len(other)>>> s1=S1("APP")
>>> s2=S2("BAA")
>>> s1+s2
6
__iadd__(self,other)__相当于x+=y
>>> class S1(str):def __iadd__(self,other):return len(self)+len(other)>>> class S2(str):def __radd__(self,other):return len(self)+len(other)>>> s1=S1("APPle")
>>> s2=S2("BAA")
>>> s1+=s2
>>> s1
8
>>> type(s1)
<class 'int'>
>>>
>>> s2+=s2
>>> s2
'BAABAA'
>>> type(s2)
<class 'str'>
-
__int(self)__
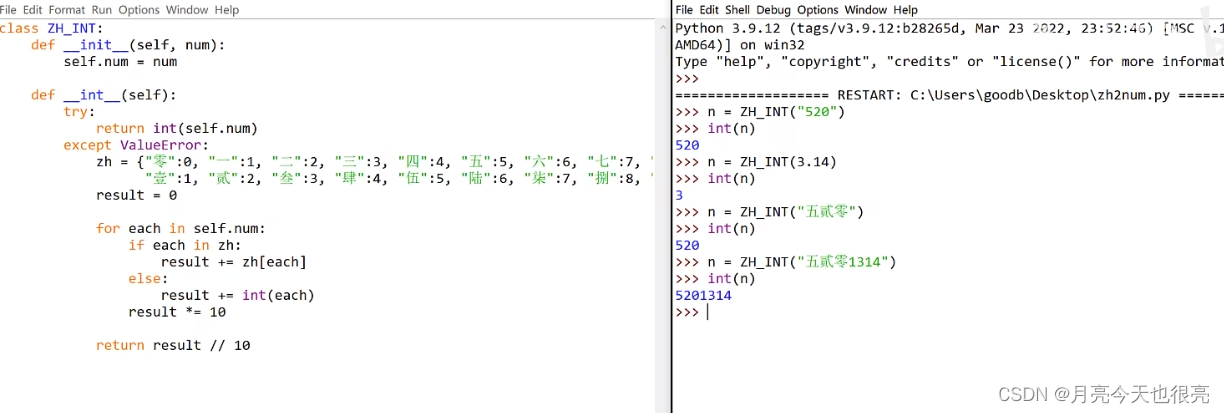
-
hasattr()
>>> class C:def __init__(self,name,age):self.name=nameself.__age=age>>> c=C("Lili",18)
>>> hasattr(c,"name") #检测c对象是否有name属性
True
getattr()获取某个对象的属性值。
>>> getattr(c,"name")
'Lili'
>>> getattr(c,"_C__age")
18
settattr()设置对象中指定属性的值。
>>> setattr(c,"_C__age",19)
>>> getattr(c,"_C__age")
19
delattr()
>>> delattr(c,"_C__age")
>>> hasattr(c,"_C__age")
False