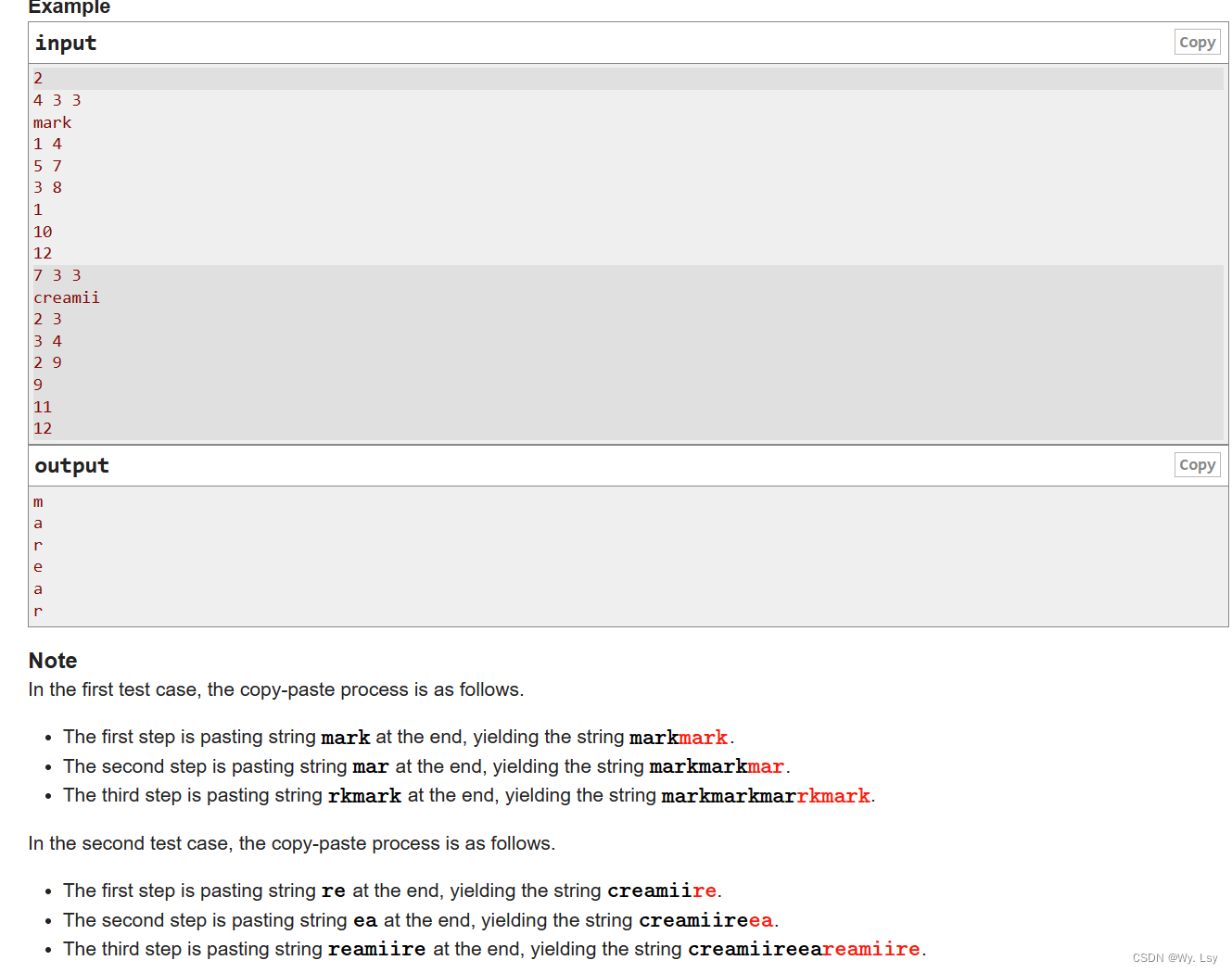
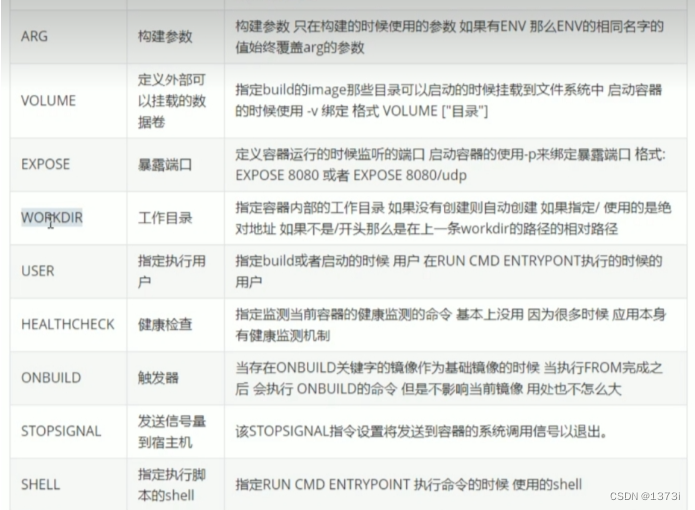
本系列教程适用于没有任何pytorch的同学(简单的python语法还是要的),从代码的表层出发挖掘代码的深层含义,理解具体的意思和内涵。pytorch的很多函数看着非常简单,但是其中包含了很多内容,不了解其中的意思就只能【看懂代码】,无法【理解代码】。
目录
- 官方定义
- demo
- 练习1——改变**embedding_dim**
- 练习2——index越界
- 练习3——sequence长度不一致
- 练习4——改变输入
官方定义
nn.embedding就是一个简单的查找表,存储固定字典和大小的嵌入。
该模块通常用于存储词嵌入并使用索引检索它们。模块的输入是索引列表,输出是相应的词嵌入。
个人理解:
- nn.embedding就是一个字典映射表,比如它的大小是128,0~127每个位置都存储着一个长度为3的数组,那么我们外部输入的值可以通过index (0~127)映射到每个对应的数组上,所以不管外部的值是如何都能在该nn.embedding中找到对应的数组。想想哈希表,就很好理解了。
- 既然是映射表,那么外部的输入的值肯定不能超过最大长度,比如128,同时下限也是。
官方的文档如下,torch.nn.embedding:

从官方的定义来看实在是非常复杂,下面看个例子:
demo
下面是一个官方文档给出的例子:
import torch
import torch.nn as nnembedding = nn.Embedding(10, 3) # an Embedding module containing 10 tensors of size 3
input = torch.LongTensor([[1,2,4,5],[4,3,2,9]]) # a batch of 2 samples of 4 indices each
e = embedding(input)
print(e)
输出的结果:

我们一步步理解代码:
- 首先,
embedding = nn.Embedding(10, 3)即定义一个embedding模块,包含了一个长度为10的张量,每个张量的大小是3。举个例子,[-1.0556, -0.2404, -0.4578]就是一个tensor,那么如何取该tensor?使用下标index去取,注意,理解这点非常重要。 - 其次,
input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])即输入一个我们需要embedding的变量,输入的每个值最终映射到张量空间中。 - 最后,我们发现输出e变成了[2, 4, 3]的张量,那么没有学习过的同学自然是一脸懵逼。我们需要,说说怎么看张量的维度,从最外层的**[]开始,计算里面的独立个体,发现是2;接着从第二维度的[]**开始数,发现是4;依次类推就可以得到张量的维度是[2, 4, 3]。
仍然十分迷茫,但是没关系,我们看看embedding的weight:
embedding.weight
输出:

我们发现embedding.weight是个[10, 3]的向量,那么embedding.weight的值是怎么被我们input取到的呢?
比如index = 1,那么我们取[-1.0556, -0.2404, -0.4578]; index = 2, 取[ 1.3328, 2.5743, -0.7375]; index = 4, 取[-0.0584, -0.6458, 0.8236]。
这时候,聪明的小伙伴已经发现了,这不就刚好对应了e的输入为1/2/4的值吗?只是我们把输入1作为index去embedding.weight取对应的值去填充新的张量e。
所以说,我们待输入的张量[[1,2,4,5],[4,3,2,9]],在经过nn.embedding后,从[2, 4]维度变换为[2, 4, 3],其实就是[2, 4]中的每个值作为索引去nn.embedding中取对应的权重。
练习1——改变embedding_dim
embedding = nn.Embedding(10, 4) # an Embedding module containing 10 tensors of size 3
input = torch.LongTensor([[1,2,4,5],[4,3,2,9]]) # a batch of 2 samples of 4 indices each
e = embedding(input)
print(e)
输出:

很明显,当embedding是个[10, 4]的张量时,映射出的张量为[2, 4, 4]
练习2——index越界
embedding = nn.Embedding(10, 3) # an Embedding module containing 10 tensors of size 3
input = torch.LongTensor([[1,2,4,5],[4,3,2,10]]) # a batch of 2 samples of 4 indices each
e = embedding(input)
print(e)
报错:IndexError: index out of range in self
输出会报错,那是因为我们的embedding的维度是[10, 3],所以index的取值从0~9,那么我们取10肯定就出现问题了。如果出现对应的问题时,就可以大致猜到输入的值越界了。
练习3——sequence长度不一致
embedding = nn.Embedding(10, 3) # an Embedding module containing 10 tensors of size 3
input = torch.LongTensor([[1,2,4],[4,3,2,9]]) # a batch of 2 samples of 4 indices each
e = embedding(input)
print(e)
报错:ValueError: expected sequence of length 3 at dim 1 (got 4)
将第一维[1, 2, 4, 5]减去5变成[1,2,4],出现ValueError: expected sequence of length 3 at dim 1 (got 4)的问题,所以需要每个维度的长度都一致。
练习4——改变输入
embedding = nn.Embedding(10, 3) # an Embedding module containing 10 tensors of size 3
input = torch.LongTensor([[[1,2],[2,3],[4,5],[5,7]],[[4,5],[3,4],[2,3],[8,9]]]) # a batch of 2 samples of 4 indices each
e = embedding(input)
print(e)
输出:

当输入的的维度为[2,4,2]时,经过embedding得到[2,4,2,3]的张量,也是很好理解的。
喜欢的朋友可以点赞三连一下,谢谢!