Total Variation loss
适合任务
图像复原、去噪等
处理的问题
图像上的一点点噪声可能就会对复原的结果产生非常大的影响,很多复原算法都会放大噪声。因此需要在最优化问题的模型中添加一些正则项来保持图像的光滑性,图片中相邻像素值的差异可以通过降低TV loss来一定程度上解决,比如降噪,对抗checkerboard等等。
原始定义
受噪声污染的图像的总变分比无噪图像的总变分明显的大,最小化TV理论上就可以最小化噪声。图片中相邻像素值的差异可以通过降低TV loss来一定程度上解决,比如降噪,对抗checkerboard等等。总变分定义为梯度幅值的积分
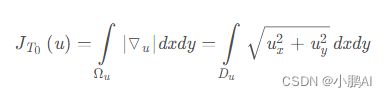

扩展定义
带阶数的TV loss 定义如下:
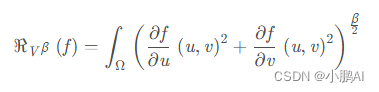
但是在图像中,连续域的积分就变成了像素离散域中求和,所以可以这么算:

即:求每一个像素和横向下一个像素的差的平方,加上纵向下一个像素的差的平方。然后开β/2次根
函数效果

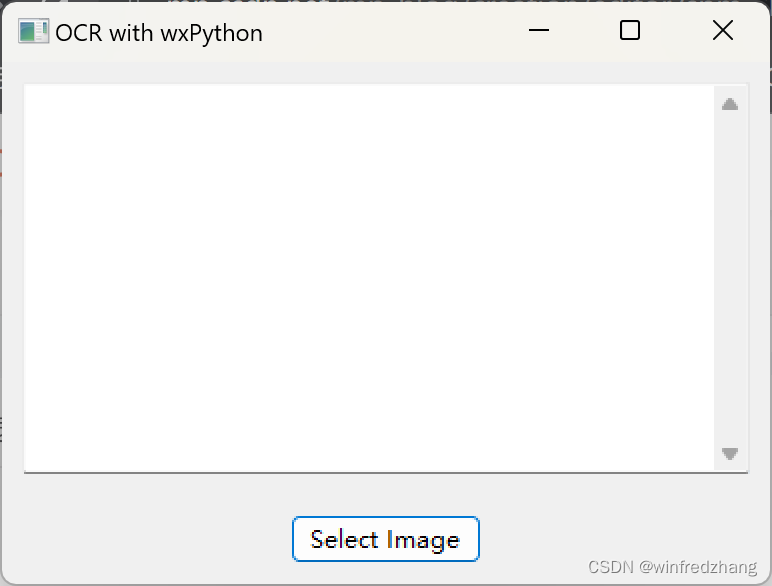
代码实现
import torch
import torch.nn as nn
from torch.autograd import Variableclass TVLoss(nn.Module):def __init__(self,TVLoss_weight=1):super(TVLoss,self).__init__()self.TVLoss_weight = TVLoss_weightdef forward(self,x):batch_size = x.size()[0]h_x = x.size()[2]w_x = x.size()[3]count_h = self._tensor_size(x[:,:,1:,:])count_w = self._tensor_size(x[:,:,:,1:])h_tv = torch.pow((x[:,:,1:,:]-x[:,:,:h_x-1,:]),2).sum()w_tv = torch.pow((x[:,:,:,1:]-x[:,:,:,:w_x-1]),2).sum()return self.TVLoss_weight*2*(h_tv/count_h+w_tv/count_w)/batch_sizedef _tensor_size(self,t):return t.size()[1]*t.size()[2]*t.size()[3]if __name__ == '__main__':x = Variable(torch.FloatTensor([[[1, 2, 3], [2, 3, 4], [3, 4, 5]], [[1, 2, 3], [2, 3, 4], [3, 4, 5]]])\.view(1, 2, 3, 3),requires_grad=True)addition = TVLoss()z = addition(x)z.backward()代码简写&分析
def total_variation(x):"""Anisotropic TV."""# 计算输入张量x在水平方向上的变差,通过计算相邻像素之间的差的绝对值,并求取水平方向上的平均值dx = torch.mean(torch.abs(x[:, :, :, :-1] - x[:, :, :, 1:]))# 计算输入张量x在垂直方向上的变差,通过计算相邻像素之间的差的绝对值,并求取垂直方向上的平均值。dy = torch.mean(torch.abs(x[:, :, :-1, :] - x[:, :, 1:, :]))# 返回水平方向和垂直方向上变差的总和作为总变差的值return dx + dy
总变差是一种用于衡量图像平滑度的指标,它量化了图像中相邻像素之间的差异程度。较小的总变差值表示图像较为平滑,而较大的总变差值表示图像较为纹理丰富或边缘明显。总变差在图像处理和计算机视觉中广泛应用,用于图像去噪、图像恢复、图像分割等任务中。