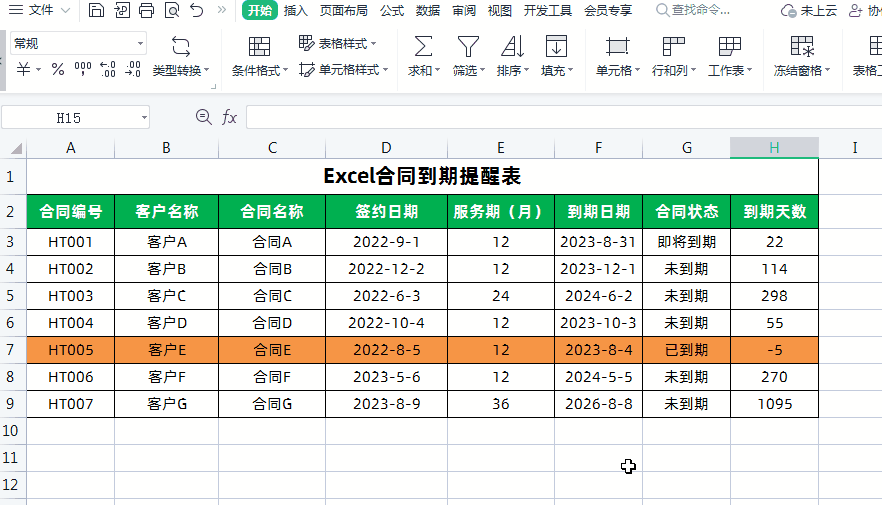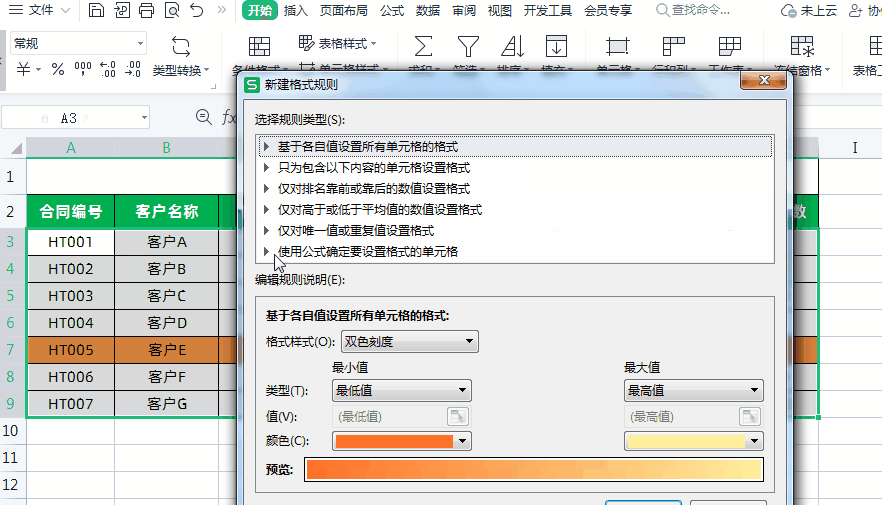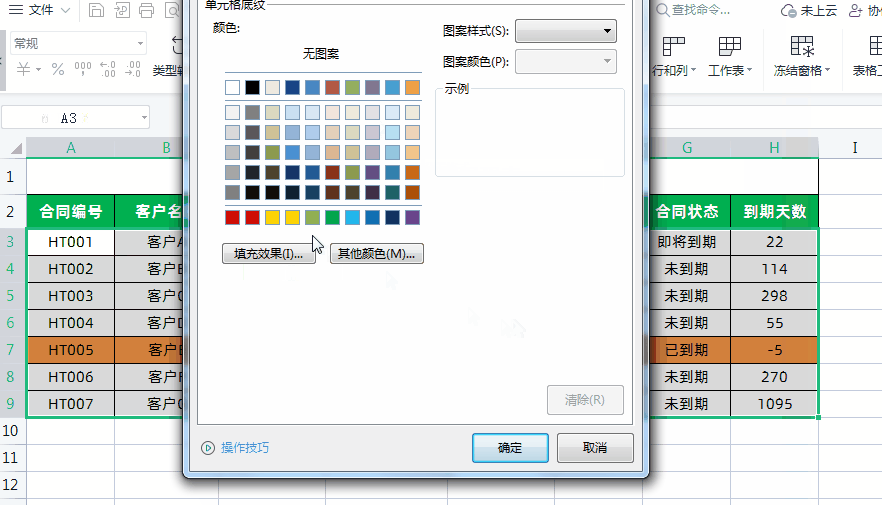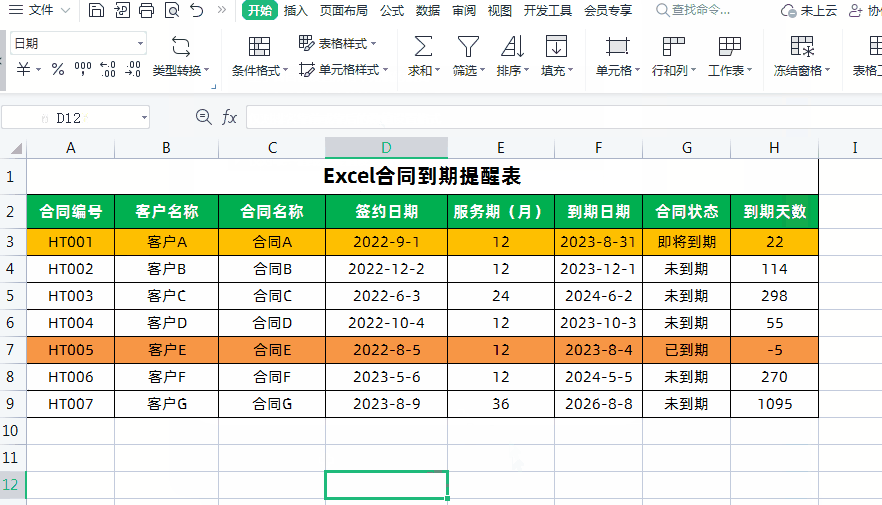
进入靶场

图片上这个人和另一道题上的人长得好像
54,【4】BUUCTF WEB GYCTF2020Ezsqli-CSDN博客
让我们上传文件
桌面有啥传啥

/var/www/html/upload/344434f245b7ac3a4fae0a6342d1f94a/123.php.jpg
成功后我就去用蚁剑连了,连不上
看了别的wp知需要上传需要再上传一个htaccess文件
将.jpg文件解析成php文件

直接上传就会这样,错误示范不要学哈
错误原因是文件类型
添加一步抓包,修改请求

改成图片这样就显示上传成功了
/var/www/html/upload/344434f245b7ac3a4fae0a6342d1f94a/.htaccess
此时用一剑连接即可得到flag